进程(一) 进程概念
文章目录
什么是进程呢?
运行起来的程序吗?
课本概念: 程序的一个执行实例,正在执行的程序等。
内核观点: 担当分配系统资源(CPU时间,内存)的实体。
对于我们所写的代码,在进行编译链接之后形成的.exe(可执行程序文件),这个可执行程序本质上是一个文件,是放在磁盘上的。当我们运行这个可执行程序时,本质上是将这个程序加载到内存当中了,因为只有加载到内存后,CPU才能对其进行逐行的语句执行,而一旦将这个程序加载到内存后,我们就不应该将这个程序再叫做程序了,严格意义上将应该将其称之为进程。
其实在我们的程序加载到内存之前操作系统早已经加载到内存中,而程序是操作系统将其进行加载拷贝到内存当中的。
描述进程-PCB
pcb全程为process control block
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_struct。
我们知道在操作系统中会同时存在多个进程
那么操作系统如何管理呢?
结合前面的知识,我们知道 应该先描述,再组织。操作系统是用C语言写的,所以操作系统要想管理进程,那么就必须用C语言来描述进程,通过进程的各种重要属性来描述进程,我们很容易想到结构体。这么多进程,结构体里面可以放一些结构体指针将他们链接起来,那么对进程的管理就转变成了对链表的增删查改。
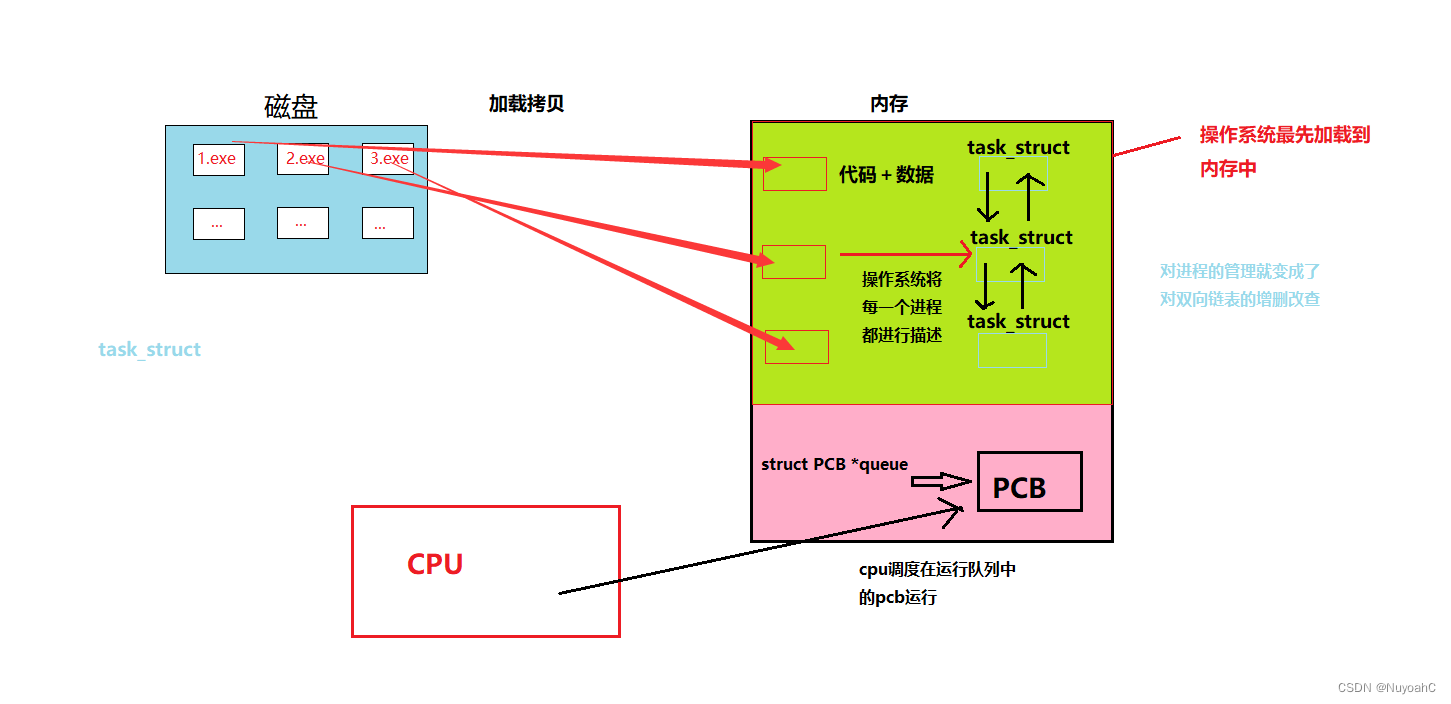
所以进程=可执行程序+内核数据结构(PCB)
task_struct-PCB的一种
在Linux中描述进程的结构体叫做task_struct。
task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。
task_struct内容分类
task_struct就是Linux当中的进程控制块,task_struct当中主要包含以下信息:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器(pc): 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟总和,时间限制,记账号等。
- 其他信息。
查看进程
通过系统目录查看
根目录下有一个proc的系统文件夹。

文件夹当中包含大量进程信息,其中有些子目录的目录名为数字。
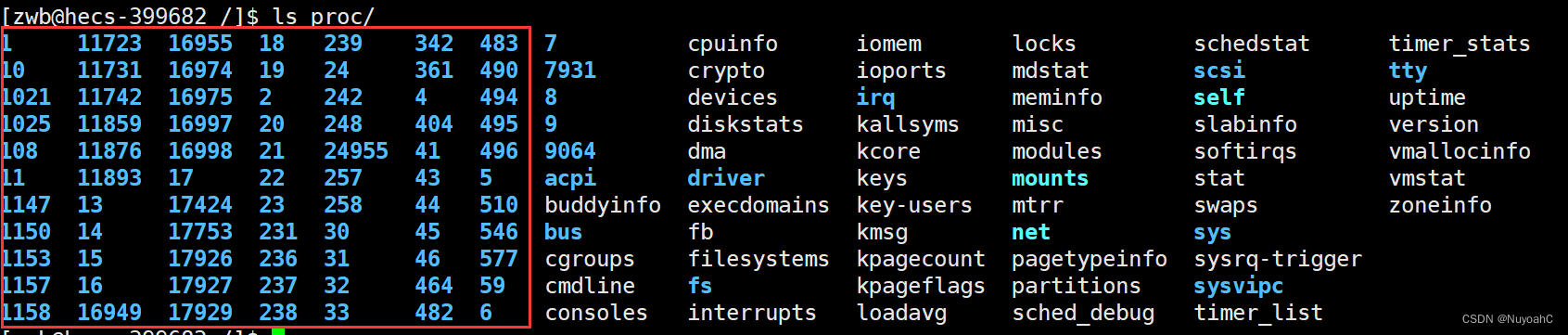
这些数字其实是某一进程的PID,对应文件夹当中记录着对应进程的各种信息。
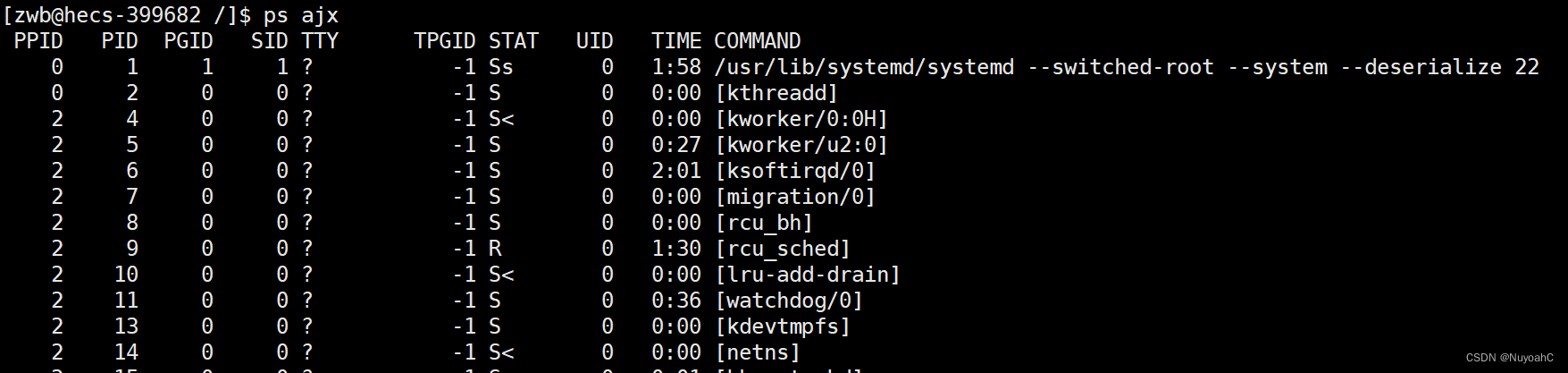
通过ps命令查看
ps aux
通过系统调用获取进程的PID和PPID
通过使用系统调用函数,getpid和getppid即可分别获取进程的PID和PPID。
我们可以通过一段代码来进行测试。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("我是一个进程,我的pid是: %d, ppid: %d\n", getpid(), getppid()); // 这个函数只调用了一次
sleep(1);
}
retrun 0;
}
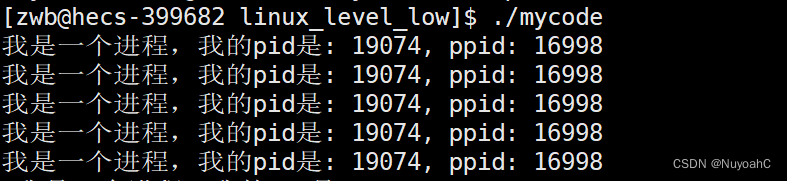
我们可以通过ps命令查看该进程的信息,即可发现通过ps命令得到的进程的PID和PPID与使用系统调用函数getpid和getppid所获取的值相同。
通过系统调用创建进程- fork()函数
fork函数创建子进程
fork是一个系统调用级别的函数,其功能就是创建一个子进程。
运行以下代码:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
fork();
while(1)
{
printf("我是一个进程,我的pid是: %d, ppid: %d\n", getpid(), getppid()); // 这个函数只调用了一次
sleep(1); // for test
}
return 0;
}
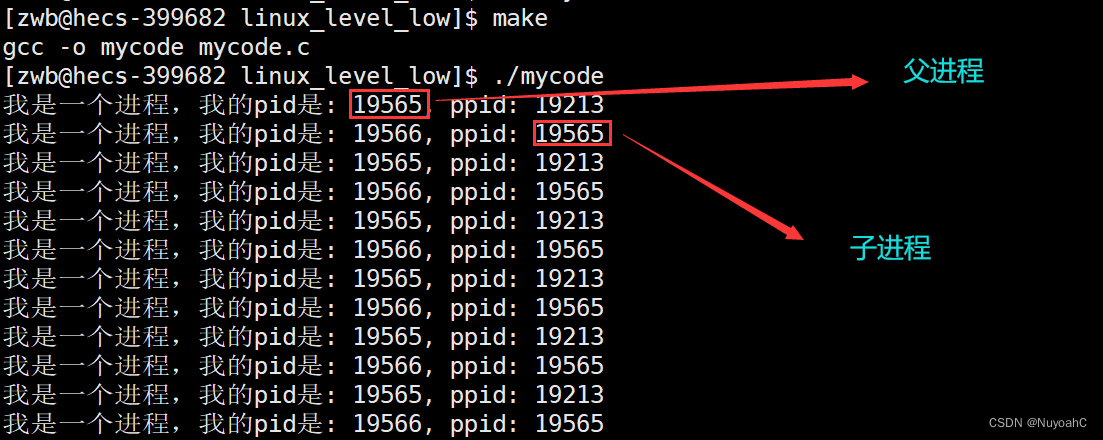
运行结果是循环打印两行数据,第一行数据是该进程的PID和PPID,第二行数据是代码中fork函数创建的子进程的PID和PPID。我们可以发现fork函数创建的进程的PPID就是proc进程的PID,也就是说proc进程与fork函数创建的进程之间是父子关系。
每一个进程,操作系统就会为其创建PCB,fork函数创建的进程也是如此。
fork()函数
fork函数做了什么?
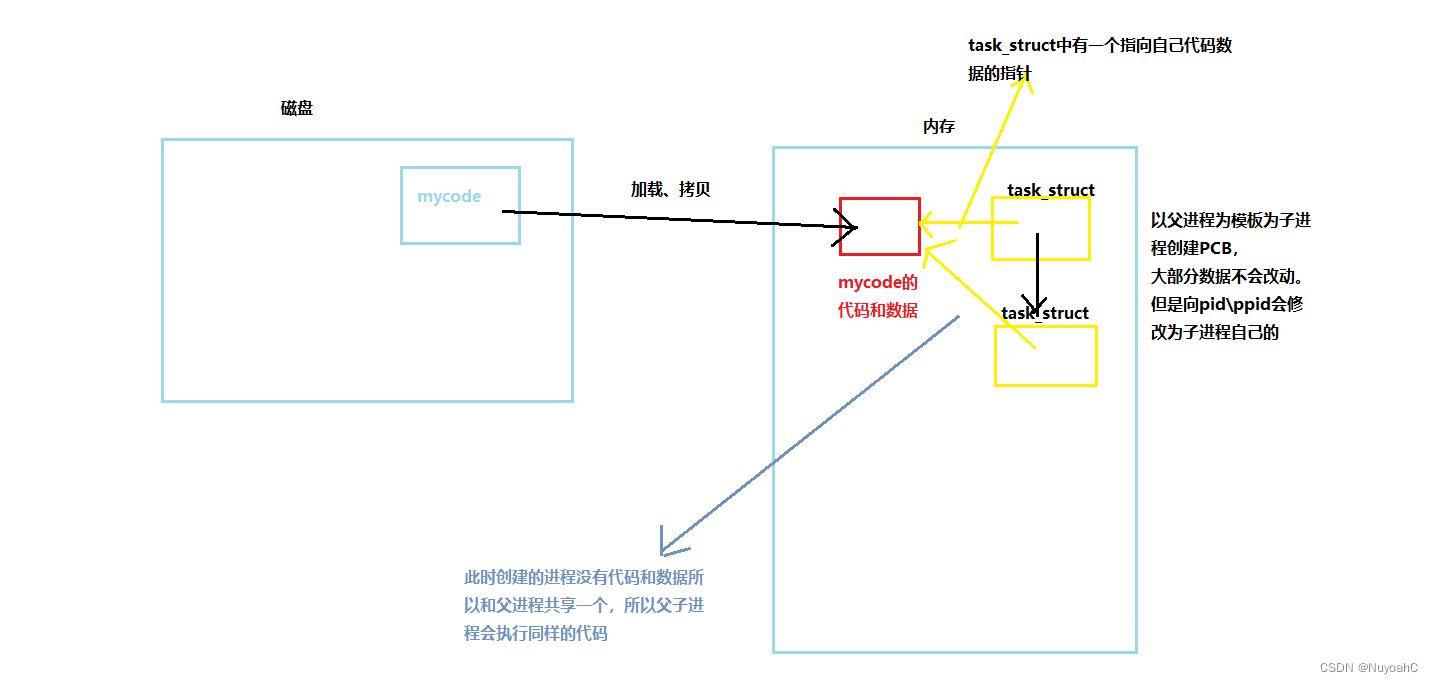
上面谈到父进程跟子进程会共享代码和数据,会执行相同的代码,那么fork之前的代码呢,子进程能看到吗?
答案是可以看到。
为什么子进程不从头开始执行呢?
因为我们的程序从上往下按照顺序去执行pc/eip寄存器执行fork完毕,eip指向的是fork后续的代码,而eip也会被子进程继承。所以只执行从fork之后的代码。
fork之后,父子进程谁先运行
创建完成子进程之后,系统的其他进程,父进程,子进程接下来是要被CPU调度执行的,当父子进程的PCB都被创建并在运行队列中排队的时候,哪一个进程先运行是不确定的,因为哪一个进程的PCB先被CPU选择调度,哪个进程就先运行,然后谁会先被调度是由各自PCB中的调度信息(比如说 时间片,优先级等)+调度器算法共同决定的,所以谁先运行是没有明确答案的。
fork函数的返回值:
1、如果子进程创建成功,在父进程中返回子进程的PID,而在子进程中返回0。
2、如果子进程创建失败,则在父进程中返回 -1。
既然父进程和子进程获取到fork函数的返回值不同,那么我们就可以据此来让父子进程执行不同的代码,从而做不同的事。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("我是一个父进程,我的pid: %d\n", getpid());
pid_t id = fork();
// fork之后,用if进行分流
if(id < 0) return 1;
else if(id == 0)
{
// child
while(1)
{
printf("我是子进程: pid: %d, ppid:%d, ret: %d, 我正在执行下载任务, &id: %p\n", getpid(), getppid(), id, &id);
sleep(1);
}
}
else
{
// parent
while(1)
{
printf("我是父进程: pid: %d, ppid:%d, ret: %d, 我正在执行播放任务, &id: %p\n", getpid(), getppid(), id, &id);
sleep(1);
}
}
}
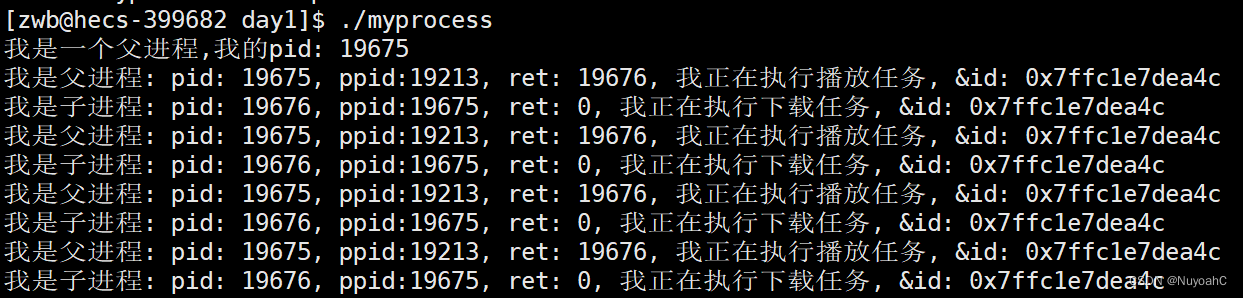
fork创建出子进程后,子进程会进入到 else if 语句的循环打印当中,而父进程会进入到 else 语句的循环打印当中。
为什么fork会有两个返回值?
Q:如果一个函数执行到了return语句,那么他的工作结束了吗?
A:是的,结束了。

子进程跟父进程代码和数据会共享,那么return之前,子进程已经被创建出来了,而return 语句也是代码,所以return 语句也会被子进程共享,所以父进程子进程被调度都会执行return 语句,从而造成了fork函数有两个返回值。
fork的两个返回值
Q:为什么fork的两个返回值,会给父进程返回子进程的pid,给子进程返回0呢?
在现实生活中一个爹可以对应多个子女,BUT儿子只能对应一个爹,需要管理子女所以需要得到子女的信息(也就是子进程的pid),而对于子女来说只需要管理好自己就可以(所以不需要得到任何信息,即返回0)
Q:如何理解同一个变量会有不同的值?
A:如果启动一个qq,启动微信,启动浏览器,kill掉微信,qq还在、浏览器还在
如果父子进程,父进程被杀掉,子进程还在吗?子进程被杀掉,父进程还在嘛? 答案是:还在
结合以上两点,我们可以推出,进程之间运行的时候是具有独立性的,
进程的独立性,首先是表现在有各自的PCB,进程之间不会相互影响 !而代码又是只读的,不会影响!但是数据父子进程是会修改的!代码共享,数据各个进程必须想办法各自私有一份。
但是一般如果不对数据进行写入的话,数据是不会发生拷贝的,只有当写入时,才会进行拷贝,也就是写时拷贝。
总上,我们得出了一个结论这个我们以为的同一个地址,一定不是简单的物理地址。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JS中的模板字符串(ES6中的模板字面量语法),什么是模板字符串、怎么使用,附代码演示
- innovus:如何使用Stretch Wire拉伸wire宽度
- JAVA反序列化之URLDNS链分析
- xtu oj 1171 Coins
- C语言——双向链表的实现
- RT-DETR手把手教程:一种新颖的自适应空间相关性金字塔注意力
- 数据结构——二叉树(先序、中序、后序及层次四种遍历(C语言版))超详细~ (???) Q_Q
- java使用Runnable进行多线程
- C语言—数据类型
- Tapdata 亮相 2023 谷歌出海创业加速器展示日活动,实时数据点亮企业创新之路