resNet
网络结构
网络结构亮点
1.网络结构突破1000层,但BN成功避免了梯度消失或梯度爆炸的问题(丢弃了droupout)
梯度消失/爆炸:a=g(w*x+b),对于激活函数sigmoid,若每一层w>E,则最终z=w*x+b会过大,从而导致梯度下降的步长变得很小,训练难度大大上升
2.但残差网络成功避免了退化问题(层数越多,效果越差)
网络细节 34/50/101/152
1.34对比50/101/152(1*1卷积核用于降维和升维)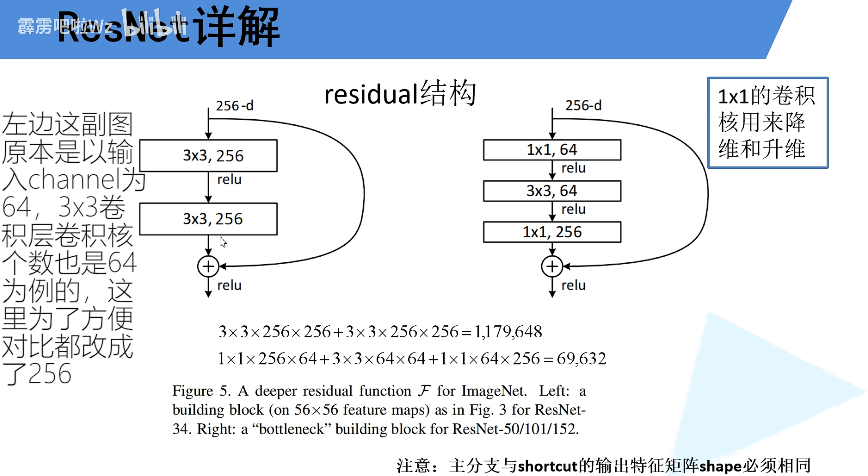
2.residual的网络结构中某些部分采用虚线,是由于为了保证输入和输出的特征shape保持一致,需要进行一些处理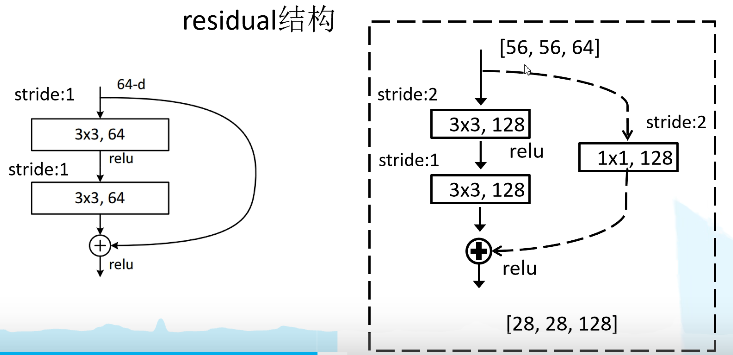
BN层详解
BN层作用
对于一个拥有d维的输入X,对它的每一个维度进行标准化处理,μ和σ是在正向传播的过程中学习得到的,而β和γ是在反向传播的过程中学习得到的,γ的初始值是1,β的初始值是0
计算示例: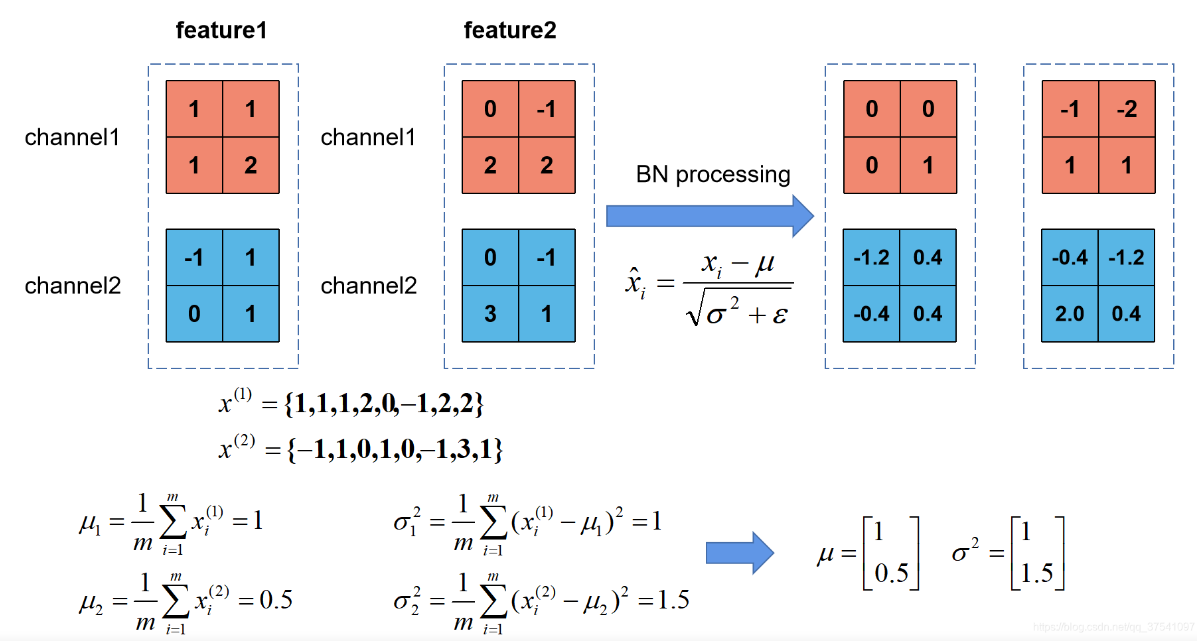
注意事项
1.训练时的training参数设置为True,验证时设置为False,在Pytorch中可以通过创建模型的model.train()和model.eval()控制
2.batch size尽可能设置大一些
3.BN层可以认为是自带了b,所以在它之前的卷积层并不需要添加偏差b
迁移学习
1.迁移学习的时候一定需要注意别人模型的预处理方式
2.迁移学习的优点
(1)能快速出结果
(2)对于小数据集,优势大;
*原先小数据集,我们使用一个较大的网络进行学习,容易过拟合,效果不佳
*但通过迁移学习的预训练权重,我们可以得到一个好的效果
3.常见的学习方式
*方法一的效果更好,能够得到准确的效果
*方法二修改原模型的最后一层,也使得我们不能在最后一层载入我们的模型,但是效果也不错
*方法三可以载入全部的预训练权重,但需要根据我们需要的输出添加最后一层
训练策略–调参
1.学习率的选择
https://blog.csdn.net/qq_38406029/article/details/115057088
2.早停机制
https://blog.csdn.net/t18438605018/article/details/123646329
https://blog.csdn.net/qq_37430422/article/details/103638681
3.修改损失函数的方式
https://zhuanlan.zhihu.com/p/338716541
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!