Mysql常用操作,谈谈排序与分页
系列文章目录
文章目录

对数据库稍有使用经验的人,排序与分页是非常常见的需求。MySQL作为一款常用的关系型数据库,对于排序和分页也提供了相应的语法和底层实现,但是实际上我也见到过很多人抱怨:排序分页后性能大减。这是为什么,又该如何解决呢?今天我们就来细说Mysql数据库的排序与分页
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 mysql 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、使用的语法
1. 排序 - order by
ORDER BY语句用于对查询结果进行排序,常见的语法为:
SELECT * FROM table_name ORDER BY column_name [ASC|DESC];
其中的 [ASC|DESC] 代表是要升序还是降序,如果不填,则默认为ASC - 升序。
① 多字段排序
而如果需要按照多个列进行排序,可以在ORDER BY子句中指定多个列,例如:
SELECT * FROM table_name ORDER BY column1, column2 [ASC|DESC];
举个例子,如果我们想把用户查出来,我们需要按照姓名(name)首字母的字母顺序进行升序查出,如果姓名相同,则按照年龄(age)进行降序,则可以使用以下SQL:
SELECT * FROM user ORDER BY name ASC, age DESC;
② NULL值处理
当然,在排序过程中,NULL值的处理是一个重要的问题。MySQL默认情况下将NULL值认定为最小,所以如果是升序的话,其NULL值排在首位,而使用降序时,其排在最后。
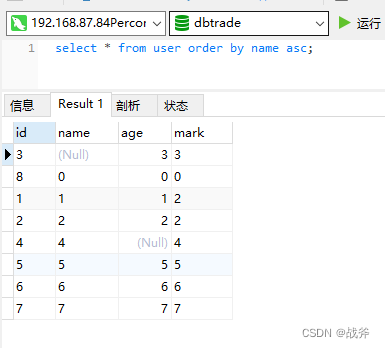
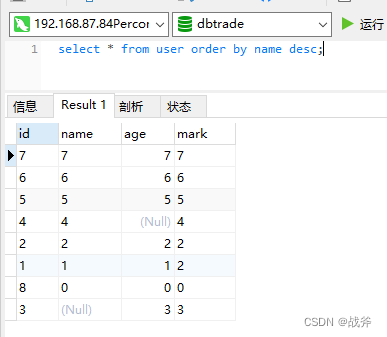
如果需要将NULL值排在前面,可以使用IS NULL或IS NOT NULL进行判断。还是以上面为例:
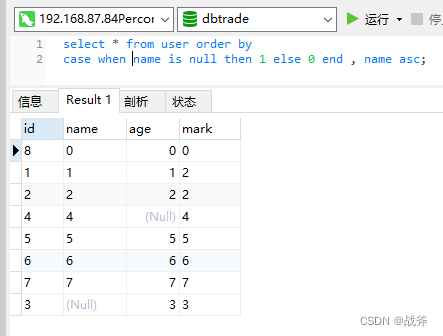
这种在原排序字段前,使用 case when XXX is null then Y else Z end 的句式,本质上就是增加一个虚拟字段并先按虚拟字段排序。在我们的SQL中,判断如果 name 字段为 NULL, 则设定该虚拟字段为1,否则虚拟字段为0,然后因为MYSQL默认的升序,这样当 name 字段为 NULL 时,虚拟字段为1,就会被排到最后了。
③ 自定义排序规则
如果你希望按照指定逻辑进行排序,而不是以数据库自己的升序或降序排序,你可以使用上面我们说的 CASE 表达式来实现
SELECT *
FROM your_table
ORDER BY
CASE
WHEN name IS NULL THEN 0 -- 姓名为NULL的记录排在最前面
ELSE 1
END,
name,
CASE
WHEN age IS NULL THEN 0 -- 在姓名相同的记录中,年龄为NULL的记录排在最前面
ELSE 1
END,
age DESC;
如果函数支持,你也可以使用对应的函数来进行处理,假如我们想以name字段的第二个字符进行升序排序,可以使用SUBSTRING函数来获取name字段的第二个字符,如下:
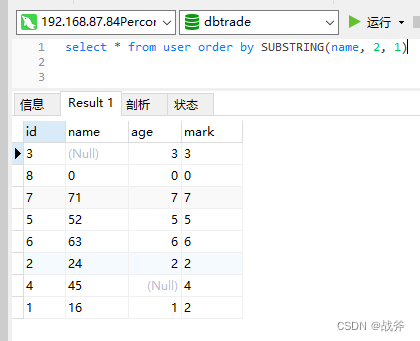
这里,我们使用SUBSTRING函数来截取name字段的第二个字符。第一个参数是字段名,第二个参数是起始位置(从1开始),第三个参数是截取的字符数。
2. 分页 - limit
对于分页的实现,MySQL提供了LIMIT语句,可以限制查询结果的行数,例如:
SELECT * FROM table_name LIMIT offset, count;
其中 offset 为起始行的偏移量,你可以理解为需要跳过的行数,count表示要返回的行数。offset 如果不填则默认是0, 也即不跳过任何数据。
-- 返回表中的前5行记录:
SELECT *
FROM your_table
LIMIT 5;
-- 返回表中的第6到第10行记录
SELECT *
FROM your_table
LIMIT 5, 5;
请注意,LIMIT语句中的索引是从0开始的,而不是从1开始。因此,LIMIT 5, 5表示跳过前5行,即从第6行开始,返回5行记录。
二、实现机制
1. 排序的实现
Mysql会根绝字段以及表的情况,采用不同的排序手段,最常见的是下面这几种:
文件排序
MySQL会使用磁盘临时文件来存储查询结果,并通过排序算法对文件中的数据进行排序。其原理是将排序字段的数据写入临时文件中,并使用外部排序算法对文件中的数据进行排序。外部排序算法通常包括多路归并排序等,它们将文件分成多个块进行排序和合并,最终得到有序的结果。比如我们现在的name字段并不是索引,当我们使用这样一个排序语句时,其采用的就是 filesort ,即文件排序:
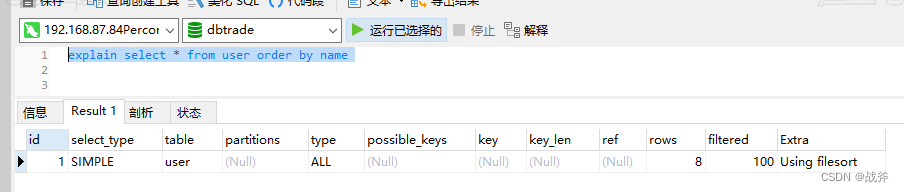
索引排序:
如果查询结果可以使用索引进行排序,则可以通过索引直接按照排序顺序返回结果,而不需要进行额外的排序操作。下面我们为name字段加上一个索引,并指定只查询name字段,我们就能看到使用了索引排序,如下:

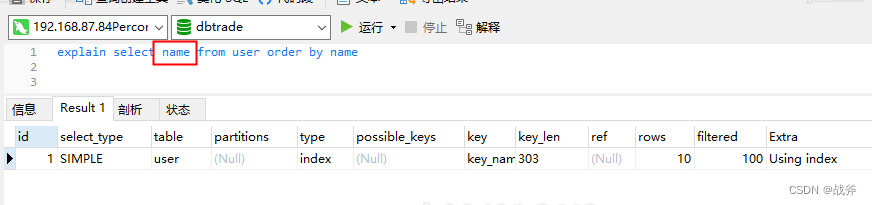
这里指定只查询name字段,是使用了覆盖索引的特性,如果我们还是使用 * 来查所有字段,那么用的还是文件排序,
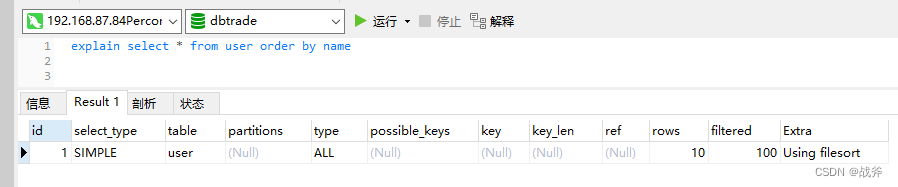
这是因为innoDB的非聚簇索引的特性,name并不是主键,所以如果你要查其他字段,使用完索引后,还得回到主键来进行查询。在数据量比较小的情况下,Mysql觉得不如直接通过主键全查,然后内存排序来的快
临时表排序
当MySQL无法直接利用索引的有序信息,MySQL会在内存中创建一个临时表,将查询结果放入临时表中,并通过排序算法对临时表进行排序。比如

一般来说,文件排序直接在磁盘上进行排序,而临时表排序在内存中进行排序,所以文件排序一般是最慢的 ,当然,最快的肯定还是索引排序,所以我们对于常用的排序字段最好是要有索引。
2. 分页的实现
MySQL首先会执行查询语句,获取满足条件的全部结果集,为了实现分页,MySQL会对返回的结果集进行处理。它会根据LIMIT子句指定的每页行数,以及OFFSET子句指定的偏移量,确定要返回的起始行和结束行。MySQL会通过扫描结果集中的行,跳过OFFSET指定的偏移量行,然后返回LIMIT指定的行数。
需要注意的是,当MySQL执行分页查询时,如果结果集很大,可能会导致性能问题,因为MySQL需要扫描整个结果集并计算偏移量。假如我们有百万级别的数据,都是显示5条数据,以下两个语句却会有很大的时间差异
select * from user order by name limit 5
select * from user order by name limit 1000000 , 5
三、弊端与解决方案
1. 排序对性能的影响
排序操作需要耗费大量的CPU和内存资源,如果排序的数据量较大,会导致性能下降。尤其是在排序的列上没有创建索引的情况下,排序操作会更加耗时。如果一定要执行排序,可以考虑以下解决方案:
- 创建合适的索引,通过索引来加速排序操作,如果你要查的是多个字段,那么索引也可以是
组合索引,尽量覆盖到这些字段 - 内存调优,可以对sort_buffer_size和tmp_table_size等参数进行调整,这些参数可以减少临时表的创建和磁盘操作,提高排序性能。
- LIMIT优化,如果只需要获取前几行结果,可以使用LIMIT子句来限制返回的行数,这样MySQL只需对限定的行进行排序,而不是对整个结果集排序。这可以减少排序所需的资源和时间。
2. 分页不稳定及性能问题
① 分页不稳定
所谓分页不稳定,在我们这里表现为即使没有改动数据,但在翻页的时候,不同的页仍然出现了重复数据或者遗漏数据的情况。而这主要是排序不稳定引起的
通俗的说,当使用ORDER BY进行排序时,如果排序字段中有相同的值,会导致分页查询的结果不稳定。在相同值的情况下,MySQL的排序算法并没有固定的顺序,可能会导致不同的查询结果。产生这种现象的原因,主要还是我们上面提到了排序 + limit 的优化导致的,当同时执行排序与limit时,实际上mysql不会对所有数据排序后再分页,而是使用堆排序进行TopK的查找。而堆排序就是不稳定的,那最终导致了分页不稳定。
解决方案其实很简单,就是让排序不会有相同的值,比如我们想以name排序,但name可能有重名的,我们想保持稳定,可以在后面加上主键的排序
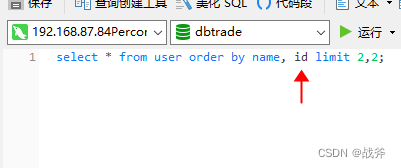
② 性能问题
分页操作同样会对性能产生一定的影响。我们在前面说过,MySQL包含了Server层、存储引擎层。而limit其实就是在Server层执行的分页,正因如此,MySQL就会读取并排序整个结果集,然后返回指定范围的数据,导致对于大型表或复杂查询可能会耗费较多的时间和资源。为了优化LIMIT分页查询的性能,可以考虑以下几个方面:
- 尽量减少返回数据的量,减少要分页的数据集
- 排序优化,尽量使用索引乃至主键进行排序后再分页
- 使用where替代分页,以唯一索引排序时,可以不使用limit,而是记录上一页的末尾id,然后以此形成where子句查询下一页
四、总结
通过本文的介绍,我们了解了MySQL数据库的排序与分页的语法和底层实现方式,并探讨了在何种情况下对性能有较大影响。针对性能问题,我们也提出了相应的解决方案。在实际的开发中,合理使用排序和分页操作,可以提升数据库查询的性能,我们将在后续对Mysql做更细致的分析。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 完美解决报错Please verify that the package.json has a valid “main“ entry处理方法
- centos7 arm服务器编译安装gcc 8.2
- C语言程序设计期末例题复习
- Python数据挖掘与机器学习实践技术应用
- 企业公司门户网站案例展示页设计(html+css静态实现,响应式布局,带源码)
- Android集成OpenSSL实现加解密-集成
- 【vmware】虚拟机固定ip和网络配置
- 前端怎么调用 chatgpt 的能力
- Ubuntu下安装ONNX、ONNX-TensorRT、Protobuf和TensorRT
- python爬虫进阶篇:scrapy爬虫框架的依赖库搭建和项目创建