MapReduce编程:Join应用
发布时间:2023年12月22日
1. Reduce Join
Map
端的主要工作:为来自不同表或文件的
key/value
对,打标签以区别不同来源的记录。然后用连接字段作为key
,其余部分和新加的标志作为
value
,最后进行输出。
Reduce
端的主要工作:在
Reduce
端以连接字段作为
key
的分组已经完成,只需要在每一个分组当中将那些来源于不同文件的记录(在Map
阶段已经打标志)分开,最后进行合并就可以。
缺点
:
这种方式中,合并的操作是在
Reduce
阶段完成,
Reduce
端的处理压力太大
, Map节点的运算负载则很低,资源利用率不高,且在
Reduce
阶段极易产生数据倾斜
。
案例
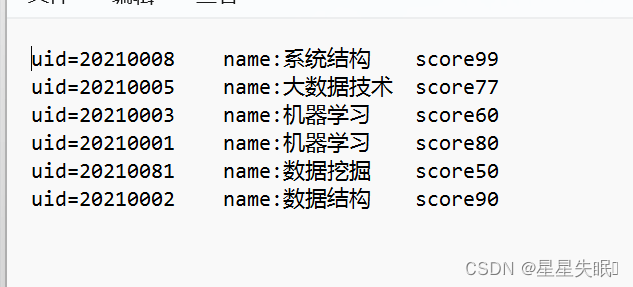
score.txt

name.txt

输出:
解题思路:
map输出key value是什么?
Map
输出
Key
:编号
Map
输出
Value: Bean
对象


reduce输出key value是什么?
Reduce
输出
key
:
Bean
对象
Reduce
输出
value:
空
ScoreBeann
package com.nefu.zhangna.reducejoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class ScoreBeann implements Writable {
private String uid;
private String sid;
private int score;
private String name;
private String flag;
public ScoreBeann() {
}
public String getUid(){
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(uid);
out.writeUTF(sid);
out.writeInt(score);
out.writeUTF(name);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.uid=in.readUTF();
this.sid=in.readUTF();
this.score=in.readInt();
this.name=in.readUTF();
this.flag=in.readUTF();
}
@Override
public String toString(){
return "uid="+this.uid+"\t"+"name:"+this.name+"\t"+"score"+this.score;
}
}
ScoreMapper
package com.nefu.zhangna.reducejoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ScoreMapper extends Mapper<LongWritable, Text,Text, ScoreBeann>{
private Text outk=new Text();
private ScoreBeann outv=new ScoreBeann();
private String filename;
@Override
protected void setup(Context context){
FileSplit split=(FileSplit) context.getInputSplit();
filename=split.getPath().getName();
}
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String line=value.toString();
if (filename.contains("score")){
String[] sp=line.split("\t");
outk.set(sp[1]);
outv.setSid(sp[1]);
outv.setUid(sp[0]);
outv.setName("");
outv.setScore(Integer.parseInt(sp[2]));
outv.setFlag("score");
}else {
String[] sp1=line.split("\t");
outk.set(sp1[0]);
outv.setUid("");
outv.setName(sp1[1]);
outv.setScore(0);
outv.setSid(sp1[0]);
outv.setFlag("name");
}
context.write(outk,outv);
}
}
ScoreReducer
package com.nefu.zhangna.reducejoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class ScoreReducer extends Reducer<Text, ScoreBeann,ScoreBeann,NullWritable> {
@Override
protected void reduce(Text key,Iterable<ScoreBeann> values,Context context) throws IOException, InterruptedException {
ArrayList<ScoreBeann> scoreBeanns=new ArrayList<ScoreBeann>();
ScoreBeann namebean=new ScoreBeann();
for (ScoreBeann value:values){
if("score".equals(value.getFlag())){
ScoreBeann tmpbean=new ScoreBeann();
try {
BeanUtils.copyProperties(tmpbean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
scoreBeanns.add(tmpbean);
}else {
try {
BeanUtils.copyProperties(namebean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
for(ScoreBeann scoreBeann:scoreBeanns){
scoreBeann.setName(namebean.getName());
context.write(scoreBeann,NullWritable.get());
}
}
}
ScoreDriver
package com.nefu.zhangna.maxcount;
import com.nefu.zhangna.reducejoin.ScoreBeann;
import com.nefu.zhangna.reducejoin.ScoreMapper;
import com.nefu.zhangna.reducejoin.ScoreReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
public class ScoreDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
job.setJarByClass(ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(ScoreBeann.class);
job.setOutputKeyClass(ScoreBeann.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\cluster\\input"));
FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\score"));
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
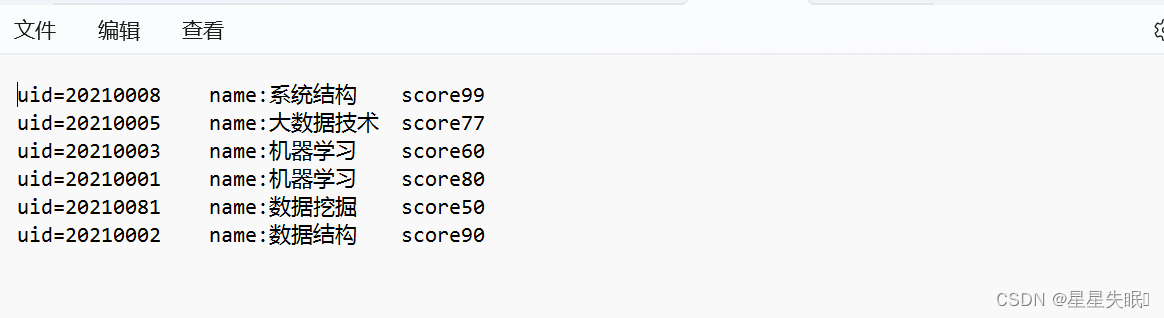
缺点
:
这种方式中,合并的操作是在
Reduce
阶段完成,
Reduce
端的处理压力太大
, Map节点的运算负载则很低,资源利用率不高,且在
Reduce
阶段极易产生数据倾斜
。
2. Map Join
1)
使用场景
Map Join
适用于一张表十分小、一张表很大的场景。
2)
优点
思考
:
在
Reduce
端处理过多的表,非常容易产生数据倾斜。怎么办
?
在
Map
端缓存多张表,提前处理业务逻辑,这样增加
Map
端业务,减少
Reduce
端数
据的压力,尽可能的减少数据倾斜
文章来源:https://blog.csdn.net/zn2021220822/article/details/135150336
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Python】判断语句
- 《HTML5网页设计》——HTML5基础
- 策略+工厂模式实现支付(支付宝)
- 大小鼠行为刺激-ZL-034B大小鼠跳台仪/多通道跳台记录仪
- 不要再混淆TypeScript的类型别名和接口了
- Docker Volume - 目录挂载以及文件共享
- python实现最小二叉堆---最小堆结构
- 排序补充(C语言版)
- 通过conda search cuda找不到想要的信息,更换channel
- Kubernetes (十五) 认证与授权