Spark原理——总体介绍
总体介绍
-
编写小案例 (wordcount)
@Test def wordCount(): Unit = { // 1. 创建 sc 对象 val conf = new SparkConf().setMaster("local[6]").setAppName("wordCount_source") val sc = new SparkContext(conf) // 2. 创建数据集 val textRDD = sc.parallelize(Seq("hadoop spark", "hadoop flume", "spark sqoop")) // 3.数据处理 // 3.1、拆词 val splitRDD = textRDD.flatMap(_.split(" ")) // 3.2、赋予初始词频 val tupleRDD = splitRDD.map((_, 1)) // 3.3、聚合统计词频 val reduceRDD = tupleRDD.reduceByKey(_ + _) // 3.4、将结果转换为字符串 val strRDD = reduceRDD.map(item => s"${item._1},${item._2}") // 4.结果获取 strRDD.collect().foreach(println(_)) // 5.关闭 sc sc.stop() } // 一个_ 指代一个参数**
-
集群组成
在 Spark 部分的底层执行逻辑开始之前,还是要先认识一下 Spark 的部署情况,根据部署情祝,从而理解如何调度
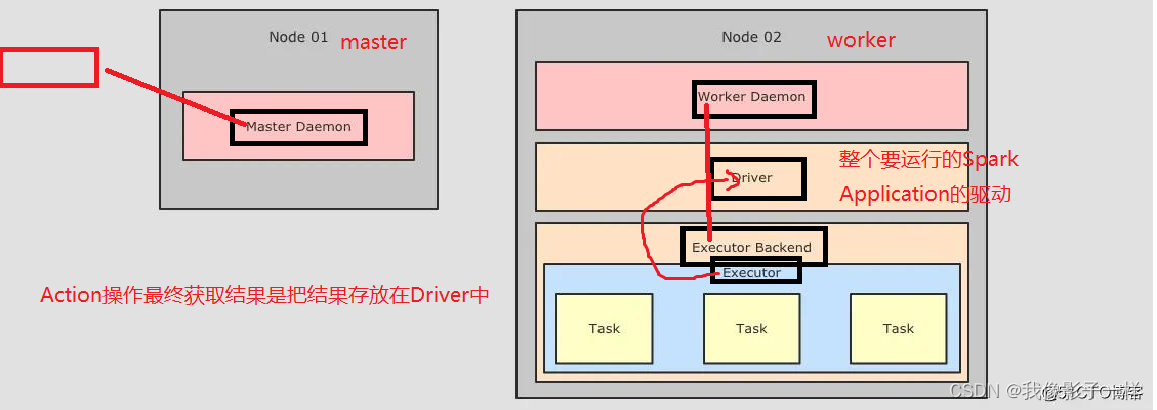
针对上图,首先可以看到整体上在集群中运行的角色有如下几个:
-
Master Daemon
负责管理 Master 节点,协调资源的获取,以及连接 Worker 节点来运行 Executor ,是 Spark 集群中的协调节点
-
Worker Daemon
Workers 也称之为叫 Slaves, 是 Spark 集群中的计算节点,用于和 Master 交互并管理 Executor.
当一个 Spark Job 提交后,会创建 SparkContext, 后 Worker 会启动对应的 Executor, -
Executor Backend
上面有提到 Worker 用于控制 Executor 的启停,其实 Worker 是通过 Executor Backend 来进行控制的,Executor
Backend 是一个进程是一个 JVM 实例持有一个 Executor 对象
-
-
逻辑执行图
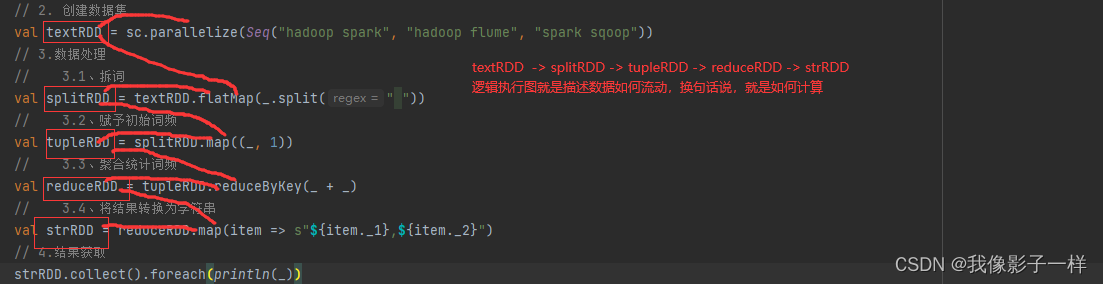

对于上面代码中的 reduceRDD 如果使用 toDebugString 打印调试信息的话,会显式如下内容

根据这段内容,大致能得到这样的一张逻辑执行图

其实 RDD 并设有什么严格的逻辑执行图和物理执行图的概念,这里也只是借用这个概念,从而让整个RDD的原理可以解释,好理解
对于 RDD 的逻辑执行图,起始于第一个入口 RDD 的创建,结束于 Actio 算子执行之前,主要的过程就是生成一组互相有依赖关系
的 RDD,其并不会真的执行,只是表示 RDD 之间的关系,数据的流转过程 -
物理执行图
当触发 Action 执行的时候, 这一组互相依赖的 RDD 要被处理, 所以要转化为可运行的物理执行图, 调度到集群中执行.
因为大部分 RDD 是不真正存放数据的, 只是数据从中流转, 所以, 不能直接在集群中运行 RDD, 要有一种 Pipeline 的思想, 需要将这组 RDD 转为 Stage 和 Task, 从而运行 Task, 优化整体执行速度.
以上的逻辑执行图会生成如下的物理执行图, 这一切发生在 Action 操作被执行时.
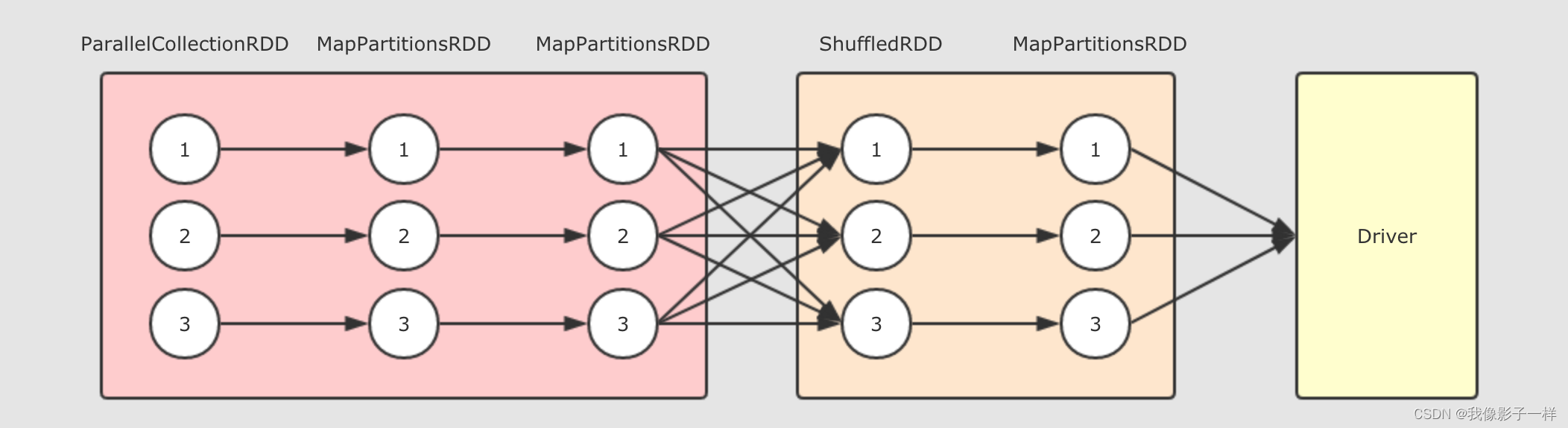
从上图可以总结如下几个点
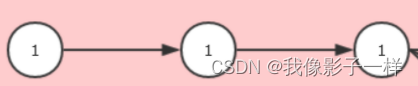
- 在第一个
Stage中, 每一个这样的执行流程是一个Task, 也就是在同一个 Stage 中的所有 RDD 的对应分区, 在同一个 Task 中执行 - Stage 的划分是由 Shuffle 操作来确定的, 有 Shuffle 的地方, Stage 断开
- 在第一个
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据分享】2019-2023年我国区县逐年新房房价数据(Excel/Shp格式)
- C#无标题栏窗体拖动代码
- xtu oj 1171 Coins
- Jmeter、postman、python 三大主流技术如何操作数据库?
- 2024年个人目标制定清单~有没有适合你的那一款
- django框架、断言、请求与响应
- 商城常见面试题
- 度限制最小生成树和第K最短路算法
- Python实现多种图像锐化方法:拉普拉斯算子和Sobel算子
- Leetcode—670.最大交换【中等】