Python从入门到精通 第六章(函数和代码复用)
一、函数的基本使用
1、函数的作用
(1)所谓函数,就是把具有独立功能的代码块组织为一个小模块,在需要的时候调用。
(2)函数的使用包含两个步骤:
①定义函数 —— 封装独立的功能。
②调用函数 —— 享受封装的成果。
(3)在开发程序时,使用函数可以提高编写的效率以及实现代码的重用。
2、函数的定义和调用
(1)定义函数的格式如下:
def <函数名>(<参数列表>):
????????<函数体>
return <返回值列表>
①def是英文define的缩写。
②函数名称应该能够表达函数封装代码的功能,方便后续的调用。
③函数名称的命名应该符合标识符的命名规则:可以由字母、下划线和数字组成,不能以数字开头,不能与关键字重名。
(2)通过“函数名()”即可完成对函数的调用。
name = "小明"
# 解释器知道这里定义了一个函数
def say_hello():
print("hello 1")
print("hello 2")
print("hello 3")
print(name)
# 定义好函数之后,只表示这个函数封装了一段代码而已,只有在调用函数时,之前定义的函数才会被执行
# 如果不主动调用函数,函数是不会主动执行的
# 函数执行完成之后,会重新回到之前的程序中,继续执行后续的代码
say_hello()
print(name)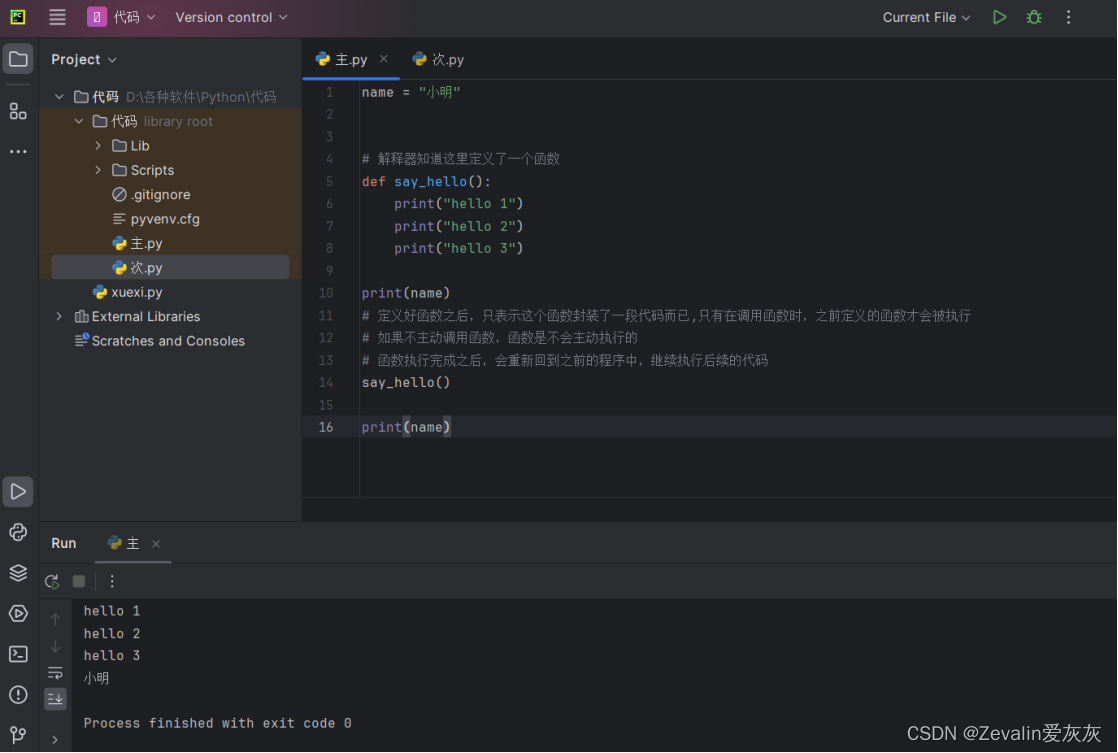
(3)不能将函数调用放在函数定义的上方,因为在使用函数名调用函数之前,必须要保证Python已经知道函数的存在。
3、函数参数的使用
(1)在函数名的后面的小括号内部填写参数,多个参数之间使用“,”分隔。
(2)参数的作用:
①在函数内部,把参数当做变量使用,进行需要的数据处理。
②函数调用时,按照函数定义的参数顺序,把希望在函数内部处理的数据,通过参数传递。
(3)形参和实参:
①形参:定义函数时,小括号中的参数,是用来接收参数用的,在函数内部作为变量使用。
②实参:调用函数时,小括号中的参数,是用来把数据传递到函数内部用的。
def sum_2_num(num1, num2):
result = num1 + num2
print("%d + %d = %d" % (num1, num2, result))
sum_2_num(50, 20)
(4)函数的参数传递:
①可选参数传递:
[1]函数的参数在定义时可以指定默认值,当函数被调用时,如果没有传入对应的参数值,则使用函数定义时的默认值替代。(必须保证带有默认值的缺省参数在参数列表末尾)
def <函数名>(<非可选参数列表>,<可选参数>=<默认值>)
????????<函数体>
return <返回值列表>
[2]缺省参数,需要使用最常见的值作为默认值。如果一个参数的值不能确定,则不应该设置默认值,具体的数值在调用函数时,由外界传递。
def print_info(name, gender=True):
"""
:param name: 班上同学的姓名
:param gender: True 男生 False 女生
"""
gender_text = "男生"
if not gender:
gender_text = "女生"
print("%s 是 %s" % (name, gender_text))
# 假设班上的同学,男生居多!
# 提示:在指定缺省参数的默认值时,应该使用最常见的值作为默认值!
print_info("小明")
print_info("老王")
print_info("小美", False)②参数名称传递:
[1]函数调用时,默认采用按照位置顺序的方式传递给函数。
[2]Python支持函数按照参数名称方式传递函数,语法形式如下:
<函数名>(<参数名>=<实际值>)
[3]在调用函数时,如果有多个缺省参数,需要指定参数名,这样解释器才能够知道参数的对应关系。
def print_info(name, title="", gender=True):
"""
:param title: 职位
:param name: 班上同学的姓名
:param gender: True 男生 False 女生
"""
gender_text = "男生"
if not gender:
gender_text = "女生"
print("[%s]%s 是 %s" % (title, name, gender_text))
# 假设班上的同学,男生居多!
# 提示:在指定缺省参数的默认值时,应该使用最常见的值作为默认值!
print_info("小明")
print_info("老王")
print_info("小美", gender=False) # 需要加“gender=”,否则False将按照默认参数的先后顺序赋给title(5)多值参数:
①有时可能需要一个函数能够处理的参数个数是不确定的,这个时候就可以使用多值参数。
②Python中有两种多值参数:参数名前增加一个“*”可以接收元组;参数名前增加两个“*”可以接收字典。
③一般在给多值参数命名时,习惯使用以下两个名字:
*args —— 存放元组参数,前面有一个“*”
**kwargs —— 存放字典参数,前面有两个“*”
其中args是arguments的缩写,有变量的含义;kw是keyword的缩写,kwargs可以记忆键值对参数。
def demo(num, *nums, **person):
print(num)
print(nums)
print(person)
# demo(1)
demo(1, 2, 3, 4, 5, name="小明", age=18) # num:1, *nums:2, 3, 4, 5, name="小明", age=18
def sum_numbers(*args):
"""将传递的所有数字累加并且返回累加结果"""
num = 0
print(args)
# 循环遍历
for n in args:
num += n
return num
result = sum_numbers(1, 2, 3, 4, 5)
print(result)④在调用带有多值参数的函数时,如果希望将一个元组变量直接传递给args、将一个字典变量直接传递给kwargs,可以使用拆包简化参数的传递,拆包的方式是:在元组变量前增加一个“*”,在字典变量前,增加两个“*”。
def demo(*args, **kwargs):
print(args)
print(kwargs)
# 元组变量/字典变量
gl_nums = (1, 2, 3)
gl_dict = {"name": "小明", "age": 18}
# demo(gl_nums, gl_dict)
# 拆包语法,简化元组变量/字典变量的传递
demo(*gl_nums, **gl_dict) # 不加*的话,会把元组(gl_nums, gl_dict)赋给args,从而达不到预期效果
demo(1, 2, 3, name="小明", age=18)4、函数的返回值
(1)在程序开发中,有时候会希望一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理。
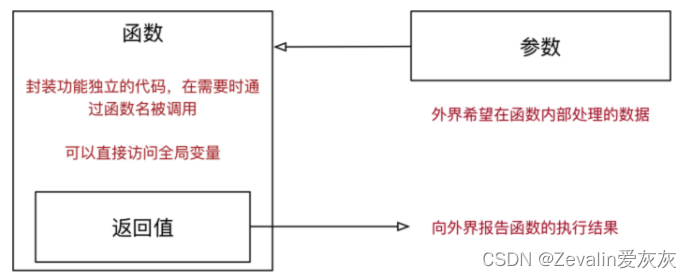
(2)返回值是函数完成工作后,最后给调用者的一个结果,在函数中使用return关键字可以返回结果。调用函数一方,可以使用变量来接收函数的返回结果。
def sum_2_num(num1, num2):
"""对两个数字的求和"""
return num1 + num2
# 调用函数,并使用 result 变量接收计算结果
result = sum_2_num(10, 20)
print("计算结果是 %d" % result)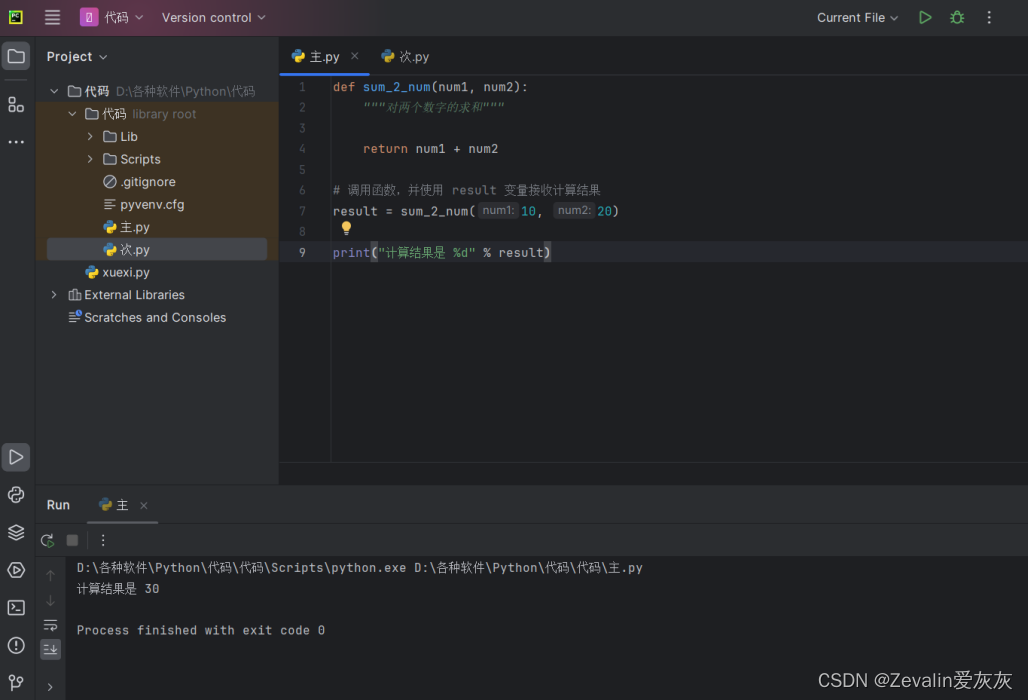
(3)return表示返回,后续的代码都不会被执行。
(4)函数根据有没有参数以及有没有返回值,可以相互组合,一共有4种组合形式:
①无参数,无返回值:
此类函数不接收参数,也没有返回值,应用场景如下:
[1]只是单纯地做一件事情,例如显示菜单
[2]在函数内部针对全局变量进行操作,例如:新建名片,最终结果记录在全局变量中
注意:
● 如果全局变量的数据类型是一个可变类型,在函数内部可以使用方法修改全局变量的内容?—— 变量的引用不会改变
● 在函数内部,使用赋值语句才会修改变量的引用(换句话说,在函数内部直接使用赋值语句,不会修改全局变量的内容)
②无参数,有返回值:
此类函数不接收参数,但是有返回值,应用场景如下:
● 采集数据,例如温度计,返回结果就是当前的温度,而不需要传递任何的参数
③有参数,无返回值:
此类函数接收参数,没有返回值,应用场景如下:
● 函数内部的代码保持不变,针对不同的参数处理不同的数据
● 例如名片管理系统针对找到的名片做修改、删除操作
④有参数,有返回值:
此类函数接收参数,同时有返回值,应用场景如下:
● 函数内部的代码保持不变,针对不同的参数处理不同的数据,并且返回期望的处理结果
● 例如名片管理系统使用字典默认值和提示信息提示用户输入内容
??○ 如果输入,返回输入内容
??○ 如果没有输入,返回字典默认值
(5)一个函数执行后可以返回多个结果:
def measure():
"""测量温度和湿度"""
print("测量开始...")
temp = 39
wetness = 50
print("测量结束...")
# 元组-可以包含多个数据,因此可以使用元组让函数一次返回多个值
# 如果函数返回的类型是元组,小括号可以省略
# return (temp, wetness)
return temp, wetness
# 元组
result = measure()
print(result)
# 需要单独的处理温度或者湿度 - 不方便
print(result[0])
print(result[1])
# 如果函数返回的类型是元组,同时希望单独的处理元组中的元素
# 可以使用多个变量,一次接收函数的返回结果
# 注意:使用多个变量接收结果时,变量的个数应该和元组中元素的个数保持一致
gl_temp, gl_wetness = measure()
print(gl_temp)
print(gl_wetness)5、函数的嵌套调用
(1)一个函数里面又调用了另外一个函数,这就是函数嵌套调用。
(2)如果函数test2中,调用了另外一个函数test1,那么执行到调用test1函数时,会先把函数test1中的任务都执行完,才会回到test2中调用函数test1的位置,继续执行后续的代码。
def test1():
print("*" * 50)
print("test 1")
print("*" * 50)
def test2():
print("-" * 50)
print("test 2")
test1()
print("-" * 50)
test2()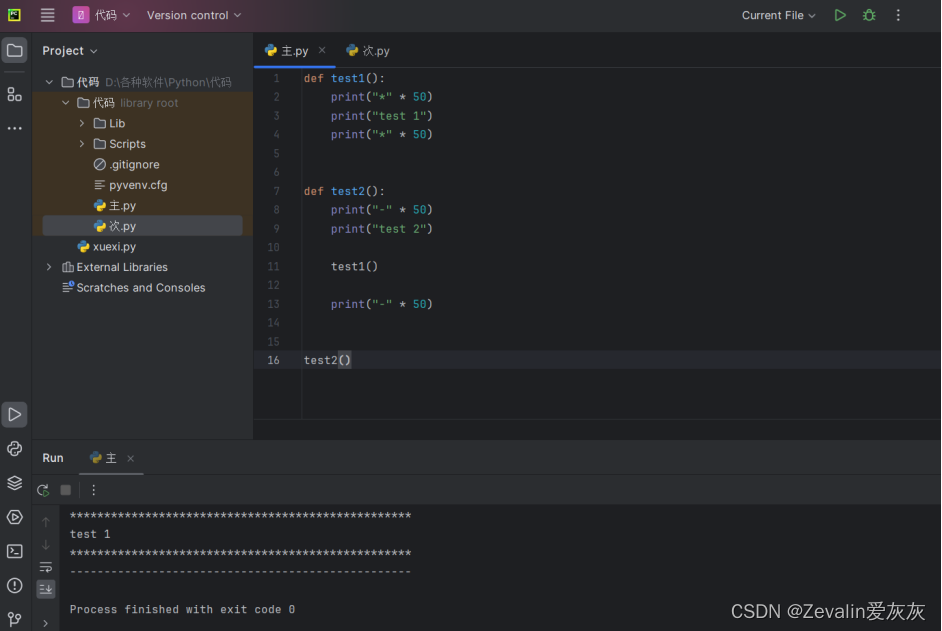
6、使用模块中的函数
(1)模块就好比是工具包,要想使用这个工具包中的工具,就需要导入import这个模块。
①每一个以扩展名py结尾的Python源代码文件都是一个模块。
②在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具。
③模块名也是一个标识符:标识符可以由字母、下划线和数字组成,不能以数字开头,不能与关键字重名。(如果在给Python文件起名时,以数字开头是无法在PyCharm中通过导入这个模块的)
(2)可以在一个Python文件中定义变量或者函数,然后在另外一个文件中使用import导入这个模块,导入之后,就可以使用“模块名.变量 / 模块名.函数的方式,使用这个模块中定义的变量或者函数。
(3)模块可以让曾经编写过的代码方便地被复用。
(4)举例:
①新建 fenmokuai.py 文件,并且编写以下代码:
def test():
print("*" * 50)
print("test 1")
print("*" * 50)
name = "ffffffff"②新建 主.py 文件,并编写以下代码,执行之:
import fenmokuai
fenmokuai.test()
print(fenmokuai.name)7、函数的文档注释
(1)在开发中,如果希望给函数添加注释,应该在定义函数的下方,使用连续的三对引号,在连续的三对引号之间编写对函数的说明文字,这样在函数调用位置使用快捷键CTRL+Q就可以查看函数的说明信息。
(2)因为函数体相对比较独立,函数定义的上方,应该和其他代码(包括注释)保留两个空行。(这是为了提高可读性,与语法无关)
8、函数的类型
(1)在Python中,可以通过type获得函数类型。
(2)函数采用其定义的名字表达,具体为function,这是一种Python的内置类型。
(3)调用函数时,其类型为返回值类型。
二、变量的作用域
1、局部变量
(1)局部变量指在函数内部定义并使用的变量,仅在函数内部有效,当函数退出时变量将不再存在。
(2)不同的函数可以定义相同的名字的局部变量,它们彼此之间不会产生影响。
(3)例:
def multiply(x,y = 10):
z = x * y
return z
s = multiply(99, 2)
print(s)
# print(z) 此时z已经被销毁,不能再使用(4)局部变量的生命周期:
①所谓生命周期就是变量从被创建 到被系统回收的过程。
②局部变量在函数执行时才会被创建。
③函数执行结束后局部变量被系统回收。
④局部变量在生命周期内,可以用来存储函数内部临时使用到的数据。
2、全局变量
(1)全局变量指在函数之外定义的变量,在程序执行全过程有效。
(2)全局变量在函数内部使用时需要提前使用关键字global声明,语法形式如下:
global <全局变量>
(3)例:
n = 2 # n是全局变量
def multiply_1(x, y = 10):
global n # 声明n为全局变量
n = n - 1 # 对全局变量n进行修改,全局变量n会被改为1
return x * y * n # 使用全局变量n
def multiply_2(x, y = 10):
n = x * y # 创建了同名新变量n,那么该函数中接下来使用的都是这个新的n,并且对这个n做任何修改都不会影响全局变量n
return n # n不是全局变量,而是局部变量,返回后该n被销毁
def test_3(x, y = 10):
return n # 函数中没有新建过变量n,往函数外部找,找到全局变量n并使用它
print(multiply_1(2005,803))
(4)函数需要处理变量时会首先查找函数内部是否存在指定名称的局部变量,如果有则直接使用,如果没有,查找函数外部是否存在指定名称的全局变量,如果有则直接使用,如果还没有则程序报错。
(5)为了避免局部变量和全局变量出现混淆,在定义全局变量时,有些公司会有一些开发要求,例如:全局变量名前应该增加“g_”或者“gl_”的前缀。
三、变量的引用
1、引用的概念
(1)在Python中,变量和数据是分开存储的,数据保存在内存中的一个位置,变量中保存着数据在内存中的地址,变量中记录数据的地址,就叫做引用。
(2)使用id()函数可以查看变量中保存数据所在的内存地址。
(3)如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用,变量不再对之前的数据引用,改为对新赋值的数据引用。
2、变量引用的示例
在Python中,变量的名字类似于便签纸贴在数据上
(1)定义一个整数变量a,并且赋值为1

(2)将变量a赋值为2

(3)定义一个整数变量b,并且将变量a的值赋值给b

3、函数的参数和返回值的传递
在Python中,函数的实参/返回值都是靠引用来传递的。
def test(num):
print("在函数内部 %d 对应的内存地址是 %d" % (num, id(num)))
# 1> 定义一个字符串变量
result = "hello"
print("函数要返回数据的内存地址是 %d" % id(result))
# 2> 将字符串变量返回,返回的是数据的引用,而不是数据本身
return result
# 1. 定义一个数字的变量
a = 10
# 数据的地址本质上就是一个数字
print("a 变量保存数据的内存地址是 %d" % id(a))
# 2. 调用 test 函数,本质上传递的是实参保存数据的引用,而不是实参保存的数据!
# 注意:如果函数有返回值,但是没有定义变量接收,程序不会报错,但是无法获得返回结果
r = test(a)
print("%s 的内存地址是 %d" % (r, id(r)))4、不可变和可变的参数
(1)在函数内部,针对参数使用赋值语句,不会影响调用函数时传递的实参变量,无论传递的参数是可变还是不可变,只要针对参数使用赋值语句,会在函数内部修改局部变量的引用,不会影响到外部变量的引用;如果传递的参数是可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据。
①例1:
def demo(num, num_list):
print("函数内部的代码")
# 在函数内部,针对参数使用赋值语句,不会修改到外部的实参变量
num = 100
num_list = [1, 2, 3]
print(num)
print(num_list)
print("函数执行完成")
gl_num = 99
gl_list = [4, 5, 6]
demo(gl_num, gl_list)
print(gl_num)
print(gl_list)
print(multiply_2(2005,803))
print(test_3(2005,803))②例2:
def demo(num_list):
print("函数内部的代码")
# 使用方法修改列表的内容
num_list.append(9)
print(num_list)
print("函数执行完成")
gl_list = [1, 2, 3]
demo(gl_list)
print(gl_list)(2)可变和不可变类型:
①不可变类型,内存中的数据不允许被修改:
[1]数字类型 int, bool, float, complex, long(2.x)
[2]字符串 str
[3]元组 tuple
②可变类型,内存中的数据可以被修改:
[1]列表 list
[2]字典 dict
demo_list = [1, 2, 3]
print("定义列表后的内存地址 %d" % id(demo_list))
demo_list.append(999)
demo_list.pop(0)
demo_list.remove(2)
demo_list[0] = 10
print("修改数据后的内存地址 %d" % id(demo_list)) # 不变
demo_list = [1, 2, 3]
print("换个新列表后的内存地址 %d" % id(demo_list)) # 变
demo_dict = {"name": "小明"} # 注意:字典的 key 只能使用不可变类型的数据
print("定义字典后的内存地址 %d" % id(demo_dict))
demo_dict["age"] = 18
demo_dict.pop("name")
demo_dict["name"] = "老王"
print("修改数据后的内存地址 %d" % id(demo_dict)) # 不变
demo_dict = {"name": "小明"}
print("换个新字典后的内存地址 %d" % id(demo_dict)) # 变
(3)可变类型的数据变化,是通过方法来实现的,如果给一个可变类型的变量,赋值了一个新的数据,引用会修改,变量不再对之前的数据引用,改为对新赋值的数据引用。
(4)值得注意的是,在Python中,列表变量调用“+=”本质上是在执行列表变量的extend方法,所以也不会修改变量的引用。
def demo(num, num_list):
print("函数开始")
# num = num + num
num += num
# 列表变量使用 += 不会做相加再赋值的操作 !
# 本质上是在调用列表的 extend 方法
num_list += num_list
# num_list.extend(num_list)
# num_list = num_list + num_list
# 现在这条语句倒是真的做了赋值操作,因此不会影响外部变量(这条语句出现之前调用列表的方法,还是可以影响外部变量,出现之后就只能影响局部变量了)
print(num)
print(num_list)
print("函数完成")
gl_num = 9
gl_list = [1, 2, 3]
demo(gl_num, gl_list)
print(gl_num)
print(gl_list)5、在函数内部修改全局变量的值
(1)在函数内部,可以通过全局变量的引用获取对应的数据,但是不允许直接修改全局变量的引用,即使用赋值语句修改全局变量的值(这么做的结果就是创建一个新的同名局部变量)。
# 全局变量
num = 10
def demo1():
# 希望修改全局变量的值
# 在 python 中,是不允许直接修改全局变量的值
# 如果使用赋值语句,会在函数内部,定义一个局部变量
num = 99
print("demo1 ==> %d" % num)
def demo2():
print("demo2 ==> %d" % num)
demo1() # 99
demo2() # 10(2)如果在函数中需要修改全局变量,需要使用global进行声明。
# 全局变量
num = 10
def demo1():
# 希望修改全局变量的值 - 使用 global 声明一下变量即可
# global 关键字会告诉解释器后面的变量是一个全局变量
# 再使用赋值语句时,就不会创建局部变量
global num
num = 99
print("demo1 ==> %d" % num)
def demo2():
print("demo2 ==> %d" % num)
demo1() # 99
demo2() # 99(3)为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义在其它函数的上方。
# 注意:在开发时,应该把模块中的所有全局变量定义在所有函数上方,就可以保证所有的函数都能够正常地访问到每一个全局变量了
num = 10
# 再定义一个全局变量
title = "黑马程序员"
# 再定义一个全局变量
name = "小明"
def demo():
print("%d" % num)
print("%s" % title)
print("%s" % name)
# # 再定义一个全局变量
# title = "黑马程序员"
demo()
# # 再定义一个全局变量
# name = "小明" (函数执行后再定义,那么函数执行时是不知道这个全局变量的)四、函数的递归
1、递归的定义
函数内部可以调用其它函数,也可以调用自己。
2、代码特点
(1)函数内部的代码是相同的,只是针对参数不同,处理的结果不同。
(2)当参数满足一个条件时,函数不再执行。这个通常被称为递归的出口,如果没有出口会出现死循环。
3、举例
(1)例1:
def sum_number(num):
print(num)
# 递归的出口,当参数满足某个条件时,不再执行函数
if num == 1:
return
# 自己调用自己
sum_number(num - 1)
sum_number(3)(2)例2:
# 定义一个函数 sum_numbers
# 能够接收一个 num 的整数参数
# 计算 1 + 2 + ... num 的结果
def sum_numbers(num):
# 1. 出口
if num == 1:
return 1
# 2. 数字的累加 num + (1...num -1)
# 假设 sum_numbers 能够正确的处理 1...num - 1
temp = sum_numbers(num - 1)
# 两个数字的相加
return num + temp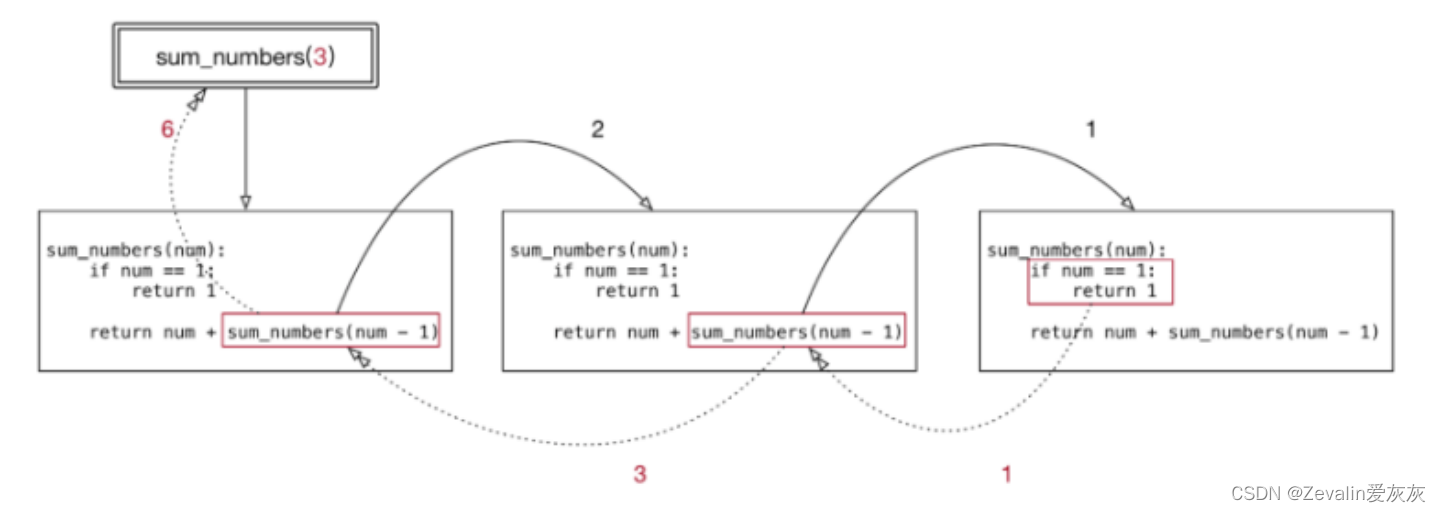
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- kafka入门(七):kafka实现高吞吐量
- 基于Android studio的新闻客户端
- 医院信息化云HIS平台源码 基于电子病历的医院信息化标准建设
- 找不到msvcr120.dll怎样修复,分享4种修复方法
- Spark报错:顶级Product编程
- python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-热门标签推荐显示实现
- 用BEVformer来卷自动驾驶-2
- 绿色数据中心认定!2023年度四川省国家绿色数据中心申报条件范围、时间程序要求
- Gauss消去法(C++)
- 【算法】力扣【动态规划,LCS】1143. 最长公共子序列