【论文阅读笔记】ISINet: An Instance-Based Approach for Surgical Instrument Segmentation
1. 论文介绍
ISINet: An Instance-Based Approach for Surgical Instrument Segmentation
ISINet:一种基于实例的手术器械分割方法
2020 MICCAI
【Paper】 【Code】
2.摘要
我们研究了机器人辅助手术场景中手术器械的语义分割任务。我们提出了基于实例的手术器械分割网络(ISINet),一种从基于实例的分割角度解决这一任务的方法。我们的方法包括一个时间的一致性模块,考虑到以前被忽视的问题和固有的时间信息。我们在任务的现有基准,内窥镜视觉2017机器人仪器分割数据集和2018年版本的数据集上验证了我们的方法,我们扩展了仪器分割的细粒度版本的注释。我们的研究结果表明,ISINet的性能明显优于最先进的方法,我们的基线版本复制了以前方法的交集(IoU),我们的完整模型将IoU复制了三倍。
Keywords:Instance-Based基于实例、Surgical Instrument Segmentation手术器械分割
3. Introduction
手术器械或其类型的分割经常用作计算机辅助手术系统开发的中间任务,例如器械跟踪,姿态估计和手术阶段估计,其反过来能够从手术室优化到手术个性化设计,尤其术前计划。手术场景中的器械分割任务首次在Endoscopic Vision 2015器械分割和跟踪数据集中引入。然而,目的不是区分仪器类型,而是从背景中提取器械并标记其部件。数据集的注释是使用半自动方法获得的,导致真值图和图像之间的不对齐。Endoscopic Vision 2017机器人器械分割(EndoVis 2017)数据集包含10个机器人辅助手术图像序列,每个序列由225帧组成。八个序列组成训练数据,两个序列组成测试数据。图像序列每帧最多显示5个仪器,属于7种仪器类型。在该数据集中,修改了任务,以包括仪器类型以及仪器部件的注释。到目前为止,这个数据集仍然是唯一现有的实验框架,以研究这种精细版本的仪器分割问题。尽管在构建该数据集方面付出了努力,但它仍然没有反映出普遍的问题,主要是由于数据量有限,不切实际的手术内容(视频来自课程而非实战),并且原始视频的稀疏采样限制了时间一致性。内窥镜视觉2018机器人场景分割数据集,包含器官和纱布和缝线等非机器人手术器械等解剖对象,增加了手术图像分割的复杂性。与2017年的数据集相比,这些图像来自外科手术,因此在背景、器械运动、角度和比例方面具有很大的变化性。尽管有额外的注释,但工具类别被简化为包含所有工具类型的通用工具类别。因此,2018年数据集不能用于2017年精细版本的仪器分割任务。
用于手术器械的分割的最新方法遵循逐像素语义分割范例,其中独立地预测图像中的每个像素的类。大多数方法修改神经网络U-Net,其中一些方法试图通过使用边界,深度感知,后处理策略,显着图或姿势估计来考虑可以区分整个仪器的细节。然而,这些技术具有标签一致性问题,其中单个仪器可以被分配多个仪器类型,也就是说,对象内的类标签缺乏空间一致性。用于此任务的最新模型的第二个限制是难以确保仪器在时间上的标签一致性,也就是说,通常仪器类别是逐帧预测的,而不考虑来自先前帧的分割标签。MF-TAPNet是第一种包含时间优先级以增强分割的方法。该先验被用作注意力机制,并且使用先前帧的光流来计算。使用时间线索的其他方法主要针对手术器械数据集开发,这些数据集侧重于器械跟踪而不是器械分割。采用时间信息来改进分割或用于数据增强目的。本文方法不是使用时间信息来改进分割,而是采用跨帧预测中的冗余来纠正错误标记的仪器,即确保时间一致性。
时间一致性:同一时间前后的标签应该是一样的;
空间一致性:在图像分割中,图像中的某个点和其周围邻域中的点具有相同类别属性的概率较大,这一特性称为图像的空间一致特性。
4.网络结构详解
基于实例的学习:不需要训练数据,把整个数据集作为一个类,预测的时候与已知实例进行对比。
实例分割:不同于语义分割,它更细化同一类的不同物体。
与逐像素分割方法(为图像中的每个像素预测一个类)不同,基于实例的方法为整个对象实例生成一个类标签。基于实例的手术器械分割网络(ISINet),建立在Mask R-CNN基础上。通过将预测层修改为在EndoVis 2017和2018数据集中发现的类的数量,使这种架构适应于细粒度的仪器分割问题,并开发了一个模块,以促进跨连续帧的每实例类预测的时间一致性。(其实这里论文里并没有说清楚加在Mask R-CNN中的什么位置,甚至结构图都没有画一个,看完代码再详解。)时间一致性模块分两步:首先,在匹配步骤中,对于每个图像序列,识别并跟踪序列中的器械实例,然后,在分配步骤中,考虑每个实例的所有预测并为实例分配整体器械类型预测。
这里要强调几点,它是基于视频的,即使输入的是图像,也是一个序列的连续帧,要保证帧间识别一致性,即类别的一致性和实例的一致性。按类别分(Class Consistency):指的是模型能够在连续的视频帧中准确地识别出物体所属的类别,并且这个识别结果在时间序列上是一致的。例如,在手术器械分割的场景中,无论手术钳子如何移动或旋转,它始终被正确识别为“手术钳”。分每一个实例物体(Instance Consistency):不仅要识别出物体的类别,还需要区分开同类别中的不同个体,即实例。实例一致性意味着模型能够追踪视频中同一对象的具体实例,并在多帧之间保持其标识的一致性。在同一视频序列中,即使有多个相同类型的工具存在,模型也能够识别并区分每个独立的工具实例。例如,如果有两把手术钳在同一视频中,模型应该能够分辨并独立追踪每把钳子。
所以才要保持时间一致性的模块,即如下操作。
首先,对于从帧t = 1到最终帧T的序列I中的图像,通过候选提取模型(M),特别是Mask R-CNN,获得每个帧t的n个分数(S)、对象候选(O)和类预测(C)的集合。其中n是对应于置信度得分高于0.75的所有预测。

计算一个序列中所有连续帧的后向光流(OF),即从帧t到t-1。为此,使用FlowNet2(F)在MPI Sintel数据集上进行预训练,并使用PyTorch实现。
(光流(Optical Flow)是指在视觉场景中,由于物体的运动、相机的移动或者两者的结合,导致图像对象在连续两帧视频图像之间的表观运动。换句话说,它描述了一个场景中物体在不同时间点所在位置的变化。计算光流的目的是估计图像序列中每个像素点随时间变化的运动轨迹。这样可以得到一个向量场,其中每个向量表示对应像素点从前一帧图像到当前帧图像之间的位移。)

匹配步骤。 对于给定帧t的候选匹配步骤,从f个先前帧中检索候选
{
{
O
i
,
t
}
i
=
1
n
}
t
=
t
?
f
t
\{\{O_{i,t}\}^n_{i=1}\}^t_{t=t-f}
{{Oi,t?}i=1n?}t=t?ft?、得分
{
{
S
i
,
t
}
i
=
1
n
}
t
=
t
?
f
t
\{\{S_{i,t}\}^n_{i=1}\}^t_{t=t-f}
{{Si,t?}i=1n?}t=t?ft?和类
{
{
C
i
,
t
}
i
=
1
n
}
t
=
t
?
f
t
\{\{C_{i,t}\}^n_{i=1}\}^t_{t=t-f}
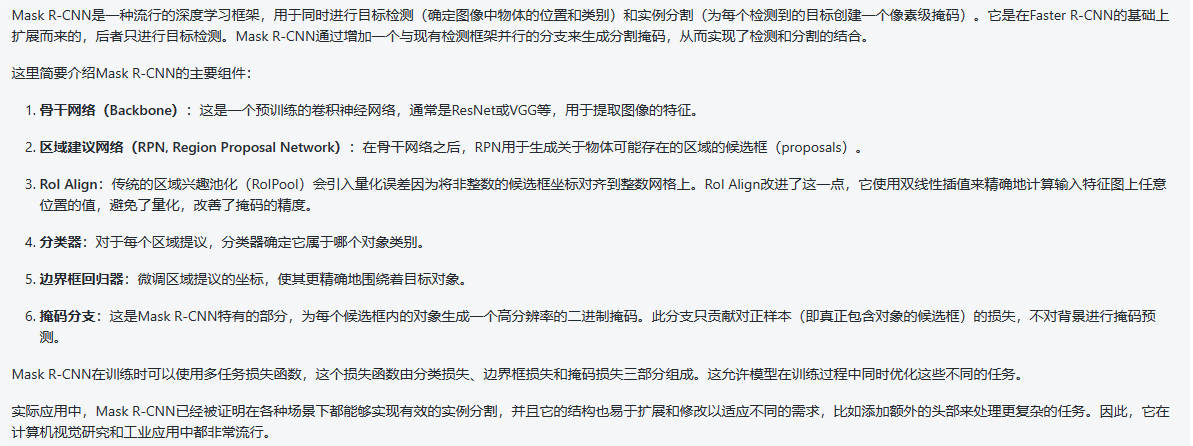
{{Ci,t?}i=1n?}t=t?ft?预测。使用光流迭代地将每个候选从先前帧扭曲到当前帧t。例如,要将帧t-2扭曲为帧t,可以从帧t-2到t-1,从t-1到t应用以下等式:
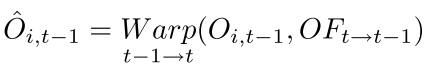
一旦我们获得变形对象候选者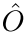 ,就通过在每个可能的候选者对之间的交集(IoU)度量中找到互反配对,来匹配来自f帧和当前帧t的每个变形对象候选者,从而在时间上跟踪乐器实例。此外,只考虑IoU大于阈值U的互惠配对。匹配步骤的最终结果是沿着帧t-f到t的m个实例的集合O,实例Ok不需要存在于所有帧中。
,就通过在每个可能的候选者对之间的交集(IoU)度量中找到互反配对,来匹配来自f帧和当前帧t的每个变形对象候选者,从而在时间上跟踪乐器实例。此外,只考虑IoU大于阈值U的互惠配对。匹配步骤的最终结果是沿着帧t-f到t的m个实例的集合O,实例Ok不需要存在于所有帧中。

分配步骤。 该步骤的目的是通过考虑前f帧的预测来更新当前帧中每个实例的类预测。为此,使用一个函数A,它同时考虑每个实例k的类和得分。
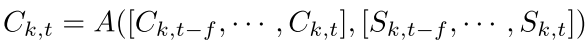
对序列中的每个帧t和集合中的所有序列重复匹配和分配步骤。分别为2017年和2018年的数据集设置f为6,U为0和0.5,并将A定义为输入类的众数,并通过其得分进行加权。训练Mask R-CNN,使用官方实现。
在NVIDIA TITAN-X Pascal GPU上进行训练,直到实现的1x时间表收敛,学习率为0.0025,权重衰减为1e ?4,每批4张图像。此外,对于所有实验,使用在MS-COCO数据集上预训练的ResNet-50主干。
人话版:
匹配步骤(Matching Step)
在匹配步骤中,系统首先需要识别并追踪视频序列里每帧图像中的手术器械实例。该过程涉及到以下操作:
- 对于序列中的每一帧,使用一个候选提取模型(例如,Mask R-CNN)来检测图像中的手术器械,并为它们生成对应的掩码、得分和类别预测。
- 这些预测仅包括那些置信度超过特定阈值(例如0.75)的预测结果。
- 随后,利用光流等技术计算连续帧之间的运动信息,从而帮助确定哪些器械实例是同一个,即使在随后的帧中位置有所改变。
简而言之,通过这一步骤,系统能够构建起实例在视频序列中随时间变化的轨迹,即使存在运动、遮挡或其他复杂情况。
分配步骤(Assignment Step)
完成了匹配步骤后,接下来进行分配步骤。在这一步中,系统会做出整体的判断:
- 系统会考虑所有对某个具体实例的预测。由于匹配步骤已经追踪了实例随时间的变化,因此现在拥有了关于该实例在整个视频序列中的全面信息。
- 接下来,系统需要对这些预测结果进行合成,为每个追踪到的实例分配一个最终的标签。这可能涉及到合并不同帧的分类信息,同时解决如置信度不一致等问题,从而形成对每个实例的“大局”认识。
- 最终,每个实例将被赋予一个整体的器械类型预测,反映了系统对其在整个序列中身份的综合判断。
5.实验与结果
1.新增EndoVis2018标注
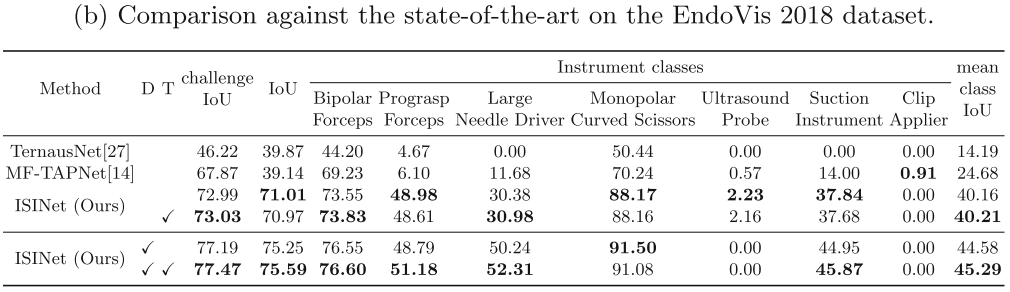
为手术场景中的器械类型分割任务提供了额外的器械类型数据。为此在专家的帮助下手动扩展EndoVis 2018的注释。最初,该数据集的仪器被注释为通用仪器类,并标记了它们的部件(轴,手腕和钳口)。为了使该数据集可用于细粒度仪器分割的研究,即区分仪器类型,进一步用其类型注释数据集中的每个仪器。基于该数据集2017年版本和DaVinci系统目录中列出的类别,确定了9种手术工具类型:双极Forstrip(马里兰州和有孔)、Prograss Forstrip、大号针驱动器、单极弯剪、超声探头、吸引器、施夹钳和吻合器。然而,由于示例数量有限,避免评估吻合器类。对于数据集的15个图像序列,每个序列由149帧组成,手动从场景中的其他对象中提取每个仪器,并将其分配给上述10种类型之一。通过考虑其框架及其完整的图像序列来标记每个仪器,以确保在模糊或部分遮挡的情况下正确标记。将仪器部件注释作为对基于分组的分割方法有用的附加信息来维护。此外,确保实例标签注释在整个序列的帧中是一致的,以使数据集适合于训练基于实例的分割方法。注释与原始场景分割任务和MS-COCO标准数据集格式兼容。
最终:有个label表明不同类别的名称和id;然后有train和val,带有两个子文件夹image和annotations,annotations为gt图,像素点对应label类别。
2.结果
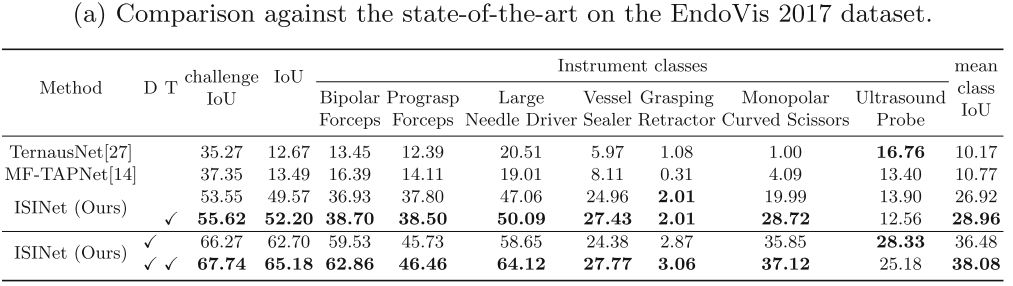
评价指标:预测P,真值G,帧数N,类别C。


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mysql :Failed to obtain JDBC Connection
- Java IDEA JUnit 单元测试
- 算法练习Day18 (Leetcode/Python-二叉树)
- Vue: node-sass 无法为当前环境找到绑定, Windows64-bit, 重新安装node-sass失败
- 百度Apollo | 实车自动驾驶:感知、决策、执行的无缝融合
- 【QT】return 和 break 是 C++ 中两个不同的关键字,它们在程序中有不同的用途。
- Python Bokeh库详解:交互式数据可视化
- 数据结构实战:利用JavaScript和Python实现链表
- 蓝桥杯python比赛历届真题99道经典练习题 (71-76)
- 写个定时任务也这么多BUG?