Pytorch的讲解及实战·MNIST数据集手写数字识别
目录
④使用jupyter notebook 但是使用不了torch的解决方法
①torchvision.transforms.Resize
③torchvision.transforms.CenterCrop
④torchvision.transforms.RandomCrop
⑤torchvision.transforms.RandomHorizontalFlip
⑥torchvision.transforms.RandomVerticalFlip
⑦torchvision.transforms.ToTensor
⑧torchvision.transforms.ToPILImage
⑨torchvision.transforms.Normalize
一、前言与pytorch的下载
1、前言
对于神经网络的相关知识大家可以先学习学习小编的这篇博客:
数学建模之神经网络相关理论知识_神经网络误差建模-CSDN博客
2、下载pytorch
①创建虚拟环境
打开anaconda prompt,输入以下指令,创建虚拟环境
conda create -n pytorch #虚拟环境名字为pytorch
conda activate pytorch #激活pytorch环境
②下载pytorch(cpu版)
进入pytorch官网https://pytorch.org/

复制Run this Command右边的这句话,再pytorch环境下运行,不过这样下载太慢了,建议换成清华镜像源或者豆瓣镜像源下载
③测试pytorch是否下载成功
在终端上输入:
python
import torch
torch.__version__
④使用jupyter notebook 但是使用不了torch的解决方法
conda install nb_conda
随后jupyter notebook的目录变成这样了,多一个“conda”

二、pytorch的使用
1、Tensor的数据类型
①torch.FloatTensor
用于生成数据类型为float型的tensor

②torch.IntTensor
torch.IntTensor用于生成数据类型为整型的Tensor

③torch.rand
用于生成数据类型为浮点型且维度指定的随机Tensor,和在NumPy中使用numpy.rand生成随机数的方法类似,随机生成的浮点数据在0~1区间均匀分布。

④torch.randn
用于生成数据类型为浮点型且维度指定的随机Tensor,和在NumPy中使用numpy.randn生成随机数的方法类似,随机生成的浮点数据符合标准正太分布。

⑤torch.range
用于生成数据类型为浮点型且起始范围和结束范围的Tensor,所以传递给torch.range的参数有三个,分别为起始值,结束值,步长,其中步长用于指定从起始值到结束值每步的数据间隔。

⑥torch.zeros
用于生成数据类型为浮点型且维度指定的Tensor,不过这个浮点型的Tensor中的元素值全部为0。

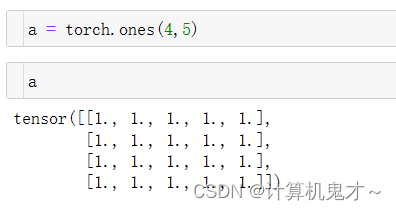
⑦torch.ones
用于生成数据类型为浮点型且维度指定的Tensor,不过这个浮点型的Tensor中的元素值全部为1。
2、Tensor的运算
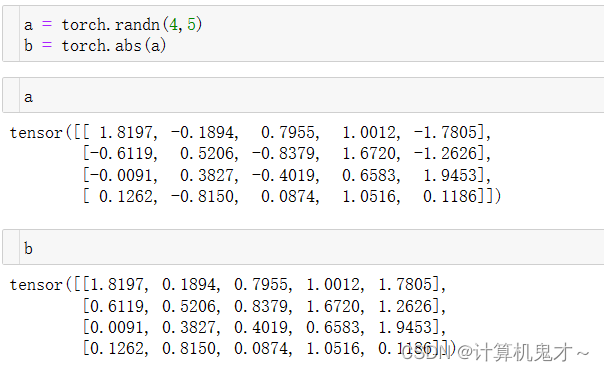
①torch.abs
将参数传递到torch.abs后返回输入参数的绝对值作为输出,输入参数必须是一个Tensor数据类型的变量。
②torch.add
将参数传递到 torch.add后返回输入参数的求和结 果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以一 个是Tensor数据类型的变量,另一个是标量。

③torch.clamp
对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出。所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的上边界和裁剪的下边界,具体的裁剪过程是:使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素就被重写成裁剪的下边界的值;同理,如果元素的值大于裁剪的上边界的值,该元素就被重写成裁剪的上边界。

④torch.div
将参数传递到torch.div后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor数据类型的变量, 也可以是Tensor数据类型的变量和标量的组合。

⑤torch.mul
将参数传递到 torch.mul后返回输入参数求积的结 果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可 以是Tensor数据类型的变量和标量的组合。

⑥torch.pow
将参数传递到torch.pow后返回输入参数的求幂结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量(几次方)的组合。

⑦torch.mm
将参数传递到 torch.mm后返回输入参数的求积结果作为输出,不过这个求积的方式和之前的torch.mul运算方式不太一样,torch.mm运用矩阵之间的乘法规则进行计算,所以被传入的参数会 被当作矩阵进行处理,参数的维度自然也要满足矩阵乘法的前提条件, 即前一个矩阵的行数必须和后一个矩阵的列数相等,否则不能进行计算。

3、tensor的自动梯度
torch.autograd包的主要功能是完成神经网络后向传播中的链式求 导,手动实现链式求导的代码会给我们带来很大的困扰,而 torch.autograd 包中丰富的类减少了这些不必要的麻烦。实现自动梯度功 能的过程大致为:先通过输入的Tensor数据类型的变量在神经网络的前 向传播过程中生成一张计算图,然后根据这个计算图和输出结果准确计 算出每个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。
在实践中完成自动梯度需要用到torch.autograd包中的Variable类对 我们定义的Tensor数据类型变量进行封装,在封装后,计算图中的各个节点就是一个Variable对象,这样才能应用自动梯度的功能。
4、torch搭建神经网络层次
①torch.nn.Sequential:
Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络中具体功能相关的类,来完成对神经网络模型的搭建,并且参数会按照我们定义好的序列自动传递下去。我们可以将嵌套在容器中的各个部分看作各种不同的模块,这些模块可以自由组合。模块的加入 般有两种方式 种是 在以上代码中使用的直接嵌套,另种是以Orderdict 有序字典的方式进行传入,这两种方式的唯一的区别是,使用Orderdict搭建的模型的每个模块都有自定义的名字而Sequential默认使用从开始的数字序列作为每个模块的名字。
②torch.nn.Conv2d
用于搭建卷积神经网络的卷积层,主要参数是:输入通道数、输出通道数、卷积核大小、卷积核移动步长和padding的值(用于对边界像素的填充)
③ torch.nn.MaxPool2d
实现卷积神经网络的最大池化层,主要参数是:池化窗口的大小,池化窗口移动步长和padding的值。
④ torch.nn.Dropout
用于防止卷积神经网络在训练过程中发生过拟合,原理是以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的。
⑤torch.nn.Linear
torch.nn.Linear类用于定义模型的线性层, 即完成前面提到的不同的层之间的线性变换。torch.nn.Linear类接收的参 数有三个,分别是输入特征数、输出特征数和是否使用偏置,设置是否 使用偏置的参数是一个布尔值,默认为True,即使用偏置。在实际使用 的过程中,我们只需将输入的特征数和输出的特征数传递给 torch.nn.Linear类,就会自动生成对应维度的权重参数和偏置,对于生成 的权重参数和偏置,我们的模型默认使用了一种比之前的简单随机方式 更好的参数初始化方法。
⑥torch.nn.ReLU
torch.nn.ReLU类属于非线性激活分类,在定义时默认不需要传入参数。当然,在 torch.nn包中还有许多非线性激活 函数类可供选择,比如之前讲到的PReLU、LeakyReLU、Tanh、 Sigmoid、Softmax等。
⑦torch.optim
pytorch的torch.optim包中提供了非常多的可实现参数自动优化的类,比如SGD、AdaGrad、RMSProp、Adam等, 这些类都可以被直接调用,使用起来也非常方便。(例如:torch.optim.Adam类中输入的是被优化的参数和学习速率的初始值,如果没有输入学习速率的初始值,那么默认使用0.001 这个值。因为我们需要优化的是模型中的全部参数,所以传递给 torch.optim.Adam类的参数是models.parameters)
5、损失函数
没必要弄清楚下面集中损失函数到底是怎么构建的,只需要知道损失函数是什么就行了,可以看这篇博客了解一下:
损失函数(lossfunction)的全面介绍(简单易懂版)-CSDN博客
①torch.nn.MSELoss
torch.nn.MSELoss类使用均方误差函数对损失值进行计算,在定义类的对象时不用传入任何参数,但在使用实例 时需要输入两个维度一样的参数方可进行计算。
②torch.nn.L1Loss
torch.nn.L1Loss类使用平均绝对误差函数对 损失值进行计算,同样,在定义类的对象时不用传入任何参数,但在使 用实例时需要输入两个维度一样的参数进行计算。
③torch.nn.CrossEntropyLoss
torch.nn.CrossEntropyLoss类用 于计算交叉熵,在定义类的对象时不用传入任何参数,在使用实例时需要输入两个满足交叉熵的计算条件的参数
6、torchvision.transforms
①torchvision.transforms.Resize
用于对载入的图片数据按我 们需求的大小进行缩放。传递给这个类的参数可以是一个整型数据,也 可以是一个类似于(h,w)的序列,其中,h代表高度,w代表宽度,但 是如果使用的是一个整型数据,那么表示缩放的宽度和高度都是这个整 型数据的值。
②torchvision.transforms.Scale
用于对载入的图片数据按我们 需求的大小进行缩放,用法和torchvision.transforms.Resize类似。
③torchvision.transforms.CenterCrop
用于对载入的图片以图 片中心为参考点,按我们需要的大小进行裁剪。传递给这个类的参数可 以是一个整型数据,也可以是一个类似于(h,w)的序列。
④torchvision.transforms.RandomCrop
用于对载入的图片按我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。
⑤torchvision.transforms.RandomHorizontalFlip
用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自 定义随机概率,如果没有定义,则使用默认的概率值0.5。
⑥torchvision.transforms.RandomVerticalFlip
用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
⑦torchvision.transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片的数据转换成Tensor数据类型的变量,让PyTorch能够对其进行计算和处理。
⑧torchvision.transforms.ToPILImage
用于将Tensor变量的数据转换成PIL图片数据,主要是为了方便图片内容的显示。
⑨torchvision.transforms.Normalize
用均值和标准差归一化张量图像,一般将std与mean均设置为[0.5,0.5,0.5]
三、实际操作
1、导入库
import torch
from torchvision import datasets, transforms
from torch.autograd import Variable
import torchvision
import matplotlib.pyplot as plt2、导入pytorch中的mnist数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.repeat(3,1,1)),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
#ToTensor()能够把灰度范围从0-255变换到0-1之间,
# 而后面的transform.Normalize()则把0-1变换到(-1,1).
# 具体地说,对每个通道而言,Normalize执行以下操作:
# image=(image-mean)/std
# 其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-#0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1.
data_train=datasets.MNIST(root="D:/jupyter_notebook/pytorch/train/",
train =True,
transform = transform,
download = True
)
data_test=datasets.MNIST(root="D:/jupyter_notebook/pytorch/test/",
train =False,
transform = transform,
download=True
)
data_loader_train =torch.utils.data.DataLoader(dataset = data_train,
batch_size = 64,
shuffle = True #打乱数据
)
data_loader_test =torch.utils.data.DataLoader(dataset = data_test,
batch_size = 64,
shuffle = True #打乱数据
)3、展示数据集规模及些许图片
images,labels = next(iter(data_loader_train))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std + mean
print([labels[i] for i in range(64)] )
plt.imshow(img)
#展示数据集与测试集大小
print("train_data:",data_train.train_data.size())
print("train_labels:",data_train.train_labels.size())
print("test_data:",data_test.test_data.size())
print("test_labels:",data_test.test_labels.size())
规模大小如下图:


4、构建模型
class Model(torch.nn.Module):
def __init__ (self):
super(Model , self).__init__ ()
self.convl=torch.nn.Sequential(
torch.nn.Conv2d (3,64,kernel_size=3,stride=1,padding=1) ,
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,kernel_size=3, stride=1,padding=1),
torch.nn.ReLU() ,
torch.nn.MaxPool2d(stride=2,kernel_size=2))
self.dense=torch.nn.Sequential(
torch.nn.Linear(14*14*128,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p= 0.5),
torch.nn.Linear(1024, 10))
def forward(self, x) :
x = self.convl(x)
x = x . view(-1 , 14*14*128)
x = self. dense(x)
return x
model = Model()
cost= torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
print(model)该神经网络结构如下图:

为什么这样构建?我们来梳理一下:
先看conv1序列:
(0)conv2d卷积层用于特征提取,用一个模板去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取
(1)激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义
(2)、(3)与上面类似
(4)池化层:经过池化后的图像基本上没什么差别,但是图像的尺寸减少了一半, 所以池化层是可以帮助我们剔除一些冗余像素或减少后面计算量。
再看dense序列
(0)Linear层即全连接层,起到概括图片局部高级特征的作用,输入一个25088*1的列向量,输出一个1024*1的列向量,可以这么理解它的作用:例如7可以拆分为上部分的“-”以及下部分的“1”,2可以拆分为上部分的弧与下部分的“-”,根据经过conv1处理后的图片,判断出图片有无这1024个局部高级特征,例如短横、小弯曲等等
(1)激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义
(2)Dropout用于防止卷积神经网络在训练过程中发生过拟合,原理是以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的
(3)Linear层:输入一个1024*1的列向量,输出一个10*1的列向量,分别代表了利用1024个局部高级特征,测算出训练或者测试时的图片对应数字0、1、2、3、4、5、6、7、8、9共十个数字下的得分函数,分值越高,可能性越大,那么需要左乘一个10*1024的权重矩阵。
5、训练
n_epochs = 5
for epoch in range (n_epochs):
runnig_loss = 0.0
running_correct = 0.0
print("Epoch {}/{}".format(epoch,n_epochs))
print("-"*10)
i=0
for data in data_loader_train:
i=i+1
X_train, y_train = data
X_train, y_train = Variable(X_train), Variable(y_train)
outputs = model(X_train)
_,pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = cost(outputs, y_train)
loss.backward()
optimizer.step()
runnnig_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
print("times:{}".format(i))
testing_correct = 0
for data in data_loader_test:
X_test, y_test = data
X_test, y_test = Variable(X_test), Variable(y_test)
outputs = model(X_test)
_, pred = torch.max(outputs.data,1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:.4f},Train Accuracy is:{:.4f}%, Test Accuracy is:{:.4f}".format(runnig_loss/len(data_train),100*running_correct/len(data_train),100*testing_correct/len(data_test)))
第五个epoch训练结果如图:

准确率还有98.7%,属实是不错了
6、测试
data2_loader_test= torch.utils.data.DataLoader(dataset=data_test,
batch_size = 4 ,
shuffle = True)
X_test2, y_test2= next (iter(data2_loader_test))
inputs = Variable(X_test2)
pred = model(inputs)
_,pred = torch.max(pred, 1)
print ( "Predict Label is :",[i for i in pred.data])
print ("Real Label is :", [ i for i in y_test2])
img = torchvision.utils.make_grid(X_test2)
img = img.numpy().transpose(1,2,0)
std= [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
plt.imshow (img)测试结果如下图:

好的,本实验到此结束啦,实验的目的从来不只是为了识别这么几个数字,更重要的是,利用这个实验学会搭建出一个完整的神经网络,了解各个层的作用,了解pytorch各个函数的实际用途
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024最新独立站建站教程!WordPress 搭建独立站的方法和步骤
- Unity中URP下深度图的线性转化
- 快速排序(三)——hoare法
- 基于arcgis js api 4.x开发点聚合效果
- WhatsApp 操作技巧之新号防封运营攻略!
- 强大的音乐乐谱控件库
- 代码随想录算法训练营Day6 | 344.反转字符串、541.反转字符串||、替换数字、151.反转字符串中的单词、右旋字符串
- 智能寻迹避障清障机器人设计(第七章)
- 第七章 Jsp
- (六)数码管动态刷新