爬取去哪网旅游攻略信息
发布时间:2024年01月08日
代码展现:
import requests
import parsel
import csv
import time
f = open('旅游去哪攻略.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['标题','浏览量','日期','天数','人物','人均价格','玩法'])
for page in range(1,5):
url = f'https://travel.qunar.com/travelbook/list.htm?page={page}&order=hot_heat'
headers = {
'Cookie': 'QN1=0000f180306c5a8fd1604d35; QN300=s%3Dbing; QN99=4383; qunar-assist{%22version%22:%2220211215173359.925%22%2C%22show%22:false%2C%22audio%22:false%2C%22speed%22:%22middle%22%2C%22zomm%22:1%2C%22cursor%22:false%2C%22pointer%22:false%2C%22bigtext%22:false%2C%22overead%22:false%2C%22readscreen%22:false%2C%22theme%22:%22default%22}; QunarGlobal=10.68.76.77_2234d452_18ce6a55a1c_3f52|1704686636774; QN205=s%3Dbing; QN277=s%3Dbing; csrfToken=BlDdq9XhjNUjJAscPT4v8cy32cW9i8oB; QN601=8db3942458d11f928c6b2dd8c1aa2279; QN163=0; _i=ueHd8ZkXXXVXomXy-xZtrutbuUoX; _vi=-FhfAqdNLwBmA7eEf04ekxQMaabajPL5jFd9ieQfDCRjLTXWWK7LdR_IvNWGcF29uIil1Zdss74CLcjh9nkEXxxColSCvCaRdcM203OwfiovKYZg9z51kh2199uQrg1Tzx1FNh2Gufhwxf-x7L65h_yAbVYUi9bptgoqjAor959u; QN269=F267AAA1ADDA11EE8FF326DBBC301320; QN48=3919f823-181d-40ef-9953-1539bcb491a3; fid=d2b33715-a247-4127-91d0-9b501fbc4863; Hm_lvt_c56a2b5278263aa647778d304009eafc=1704686638; viewbook=7824809|7826165|7826165|7825949|7825196; JSESSIONID=A4FAADF972AB80EA863A36B7828EE793; ariaDefaultTheme=undefined; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1704686730; QN271=34057a3a-f730-4fdc-92f1-a9672688d3f6; QN267=0896993248d1fd56b2',
'Referer': 'https://travel.qunar.com/?from=header',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
html_data = response.text
selector_data = parsel.Selector(html_data)
link_list = selector_data.css('.b_strategy_list .list_item .tit a::attr(href)').getall()
origin_title = selector_data.css('.b_strategy_list .list_item .tit a::text').getall()
time.sleep(5)
for link in link_list:
href = 'https://travel.qunar.com/travelbook/note'+link.replace('/youji','')
new_html_data = requests.get(url=href,headers=headers)
new_html_data.encoding = new_html_data.apparent_encoding
data = parsel.Selector(new_html_data.text)
title = data.css('.user_info #booktitle::text').get()
view_count = data.css('.e_line2 .clrfix .date .view_count::text').get()
date = data.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()
days = data.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()
character = data.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()
price = data.css('#js_mainleft > div.b_foreword > ul > li.f_item.howmuch > p > span.data::text').get()
play_list = data.css('#js_mainleft > div.b_foreword > ul > li.f_item.how > p > span.data >span::text').getall()
play = ' '.join(play_list)
print(title, view_count, date, days, character, price, play)
csv_writer.writerow([title,view_count,date,days,character,price,play])结果展现:
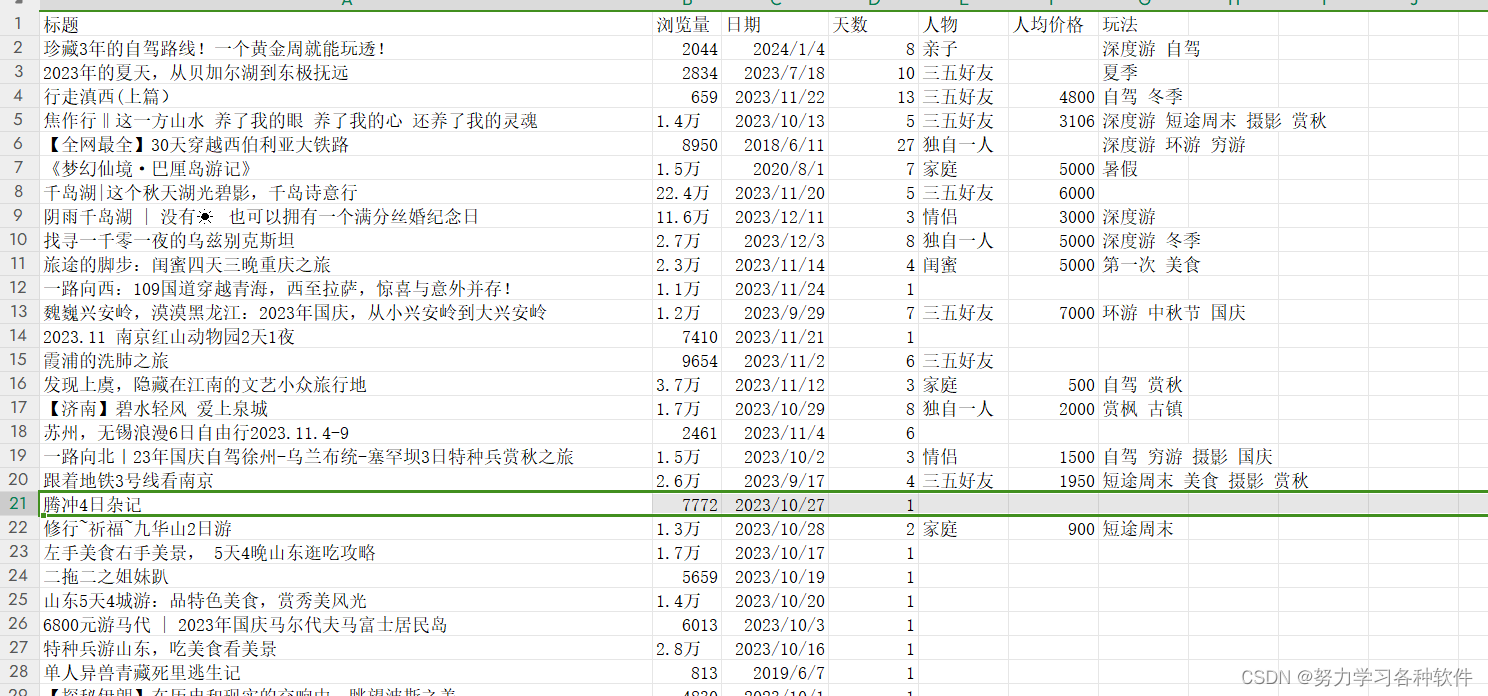 总结:
总结:
1.进一步熟悉了用css选择器去解析代码,这是两个静态网页信息提取
2.学到了如何快速提取列表中的全部元素,当作一个字符串的方法
c=['自驾游',?'旅行团',' 暴走']
a=' '.join(c)
print(a)
结果为
自驾游 旅行团 暴走
文章来源:https://blog.csdn.net/m0_57265868/article/details/135454917
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Rust 基础语法
- SpringBoot 把PageHelper分页信息返回给前端
- python实现一个图片查看器——可拖动、缩放和颜色画笔
- Linux磁盘管理
- 二叉树与堆的深度解析:数据结构中的关键概念及应用
- 安科瑞能耗监测系统在今麦郎挂面厂项目的设计与应用——安科瑞赵嘉敏
- Linux系统编程(二):标准 I/O 库(下)
- 画图案例分享
- Unity中Shader测试常用的UGUI可交互功能的脚本基本使用
- 【Docker】Docker学习④ - Docker镜像与制作