Shell(4)------shell如何处理批量数据命令
shell如何处理批量数据命令
插播!插播!插播!亲爱的朋友们,我们的shell课程上线啦!感兴趣的小伙伴可以去下面的链接学习哦~
Shell入门——基础知识+实战_在线视频教程-CSDN程序员研修院
当我们面临大量数据的清洗和转换时,shell脚本成为了不可或缺的助手。通过这个强大的工具,我们可以高效地完成各种任务,例如合并多个文件、提取日志文件中的关键信息等。shell脚本的使用不仅提高了工作效率,还大大减少了重复操作,避免了潜在的错误。
与传统的编程语言相比,shell脚本在处理批量数据方面具有显著的优势。它基于命令行操作,能够迅速地执行命令,避免复杂的逻辑判断,从而实现更高的处理速度。此外,shell脚本非常适合集成到现有的工作流程中,与各种工具和环境无缝衔接。
在这里,我将为大家简要介绍四个非常实用的命令:grep、cut、awk ?和 ?sed。这些命令在查找、分析和处理日志、数据方面具有极高的价值,可以帮助我们快速地获取所需的数据。
1. grep
grep是一款功能强大的文本搜索工具,它能够在单个或多个文件中查找指定的文本模式,并输出匹配的行。在实际应用中,使用grep命令可以方便地查找日志文件中的特定信息,如错误提示、关键字等。
首先,了解一下grep命令的基本语法格式:
grep [选项参数] [内容] [文件]其中,选项参数包括了许多实用的功能,例如:
- ?`-v`:反向匹配文本,即匹配不包含指定字符串的行。
接下来,我们通过一个实例来进一步了解grep命令的使用。假设我们有一个名为1.txt的文件,内容如下:
?
printf("helloworld\n");
a=printf1;
PRINTF("helloworld\n");现在,我们想要查找不包含`printf`的行,并将其打印到终端。这时,可以使用grep ?-v命令来实现:
grep -v 'printf' 1.txt执行该命令后,终端输出结果为:
![]()
在文本查找过程中,我们常常需要了解查找到的行的行号,以便更准确地定位和分析问题。为此,我们可以利用`grep`命令的一个实用参数——`-n`。这个参数可以在匹配的行前加上行号,帮助我们更好地理解和处理查找结果。
对上一个名为1.txt的文件,现在我们希望输出其中包含`printf`的所有行,并在每行前加上行号。那么,我们可以这样使用`grep`命令:
grep -n 'printf' 1.txt执行这个命令后,输出结果将包括所有包含`printf`字符的行以及对应的行号,如下所示:

在文本查找与匹配的过程中,我们常常会遇到一些问题。例如,当我们使用普通的查找方法寻找包含“printf”的单词时,可能会同时输出包含“printf1”的文本。那么,如何进行精确查找呢?
在这里,我们可以借助w参数来实现精确匹配,-w参数表示只匹配整个单词,而不是子字符串。如果我们想在输出结果中仅包含“printf”这个单词,而不包含“print1”,就可以使用以下命令:
grep -w 'printf'这个命令将会精确查找文本中包含“printf”的单词,而忽略其他包含“print”的子字符串。执行这个命令后,输出的结果将只包含精确匹配的“printf”字符。
![]()
在许多命令行工具中,有一个常用的参数叫做 ?"-i",它具有特殊的功能。这个参数的代表意义是“忽略大小写”。它的作用在于,无论输入的字符串是大写、小写还是混合大小写,都会被视为相同的字符串,从而进行处理。这种特性在某些情况下非常有用,尤其是当你需要对文本进行搜索或匹配时。
就以grep命令为例,如果不添加任何参数,它会在搜索时区分大小写。这意味着,如果你在寻找一个大写单词,而文本中存在与之相同的小写单词,那么grep命令将无法匹配到大写单词。但是,当你添加了 ?"-i"参数后,这种情况就会发生变化。grep命令将不再区分大小写,因此,大写、小写或混合大小写的字符串都可以被正确匹配。
这里我们可以使用1.txt查找printf,且搜索时不区分大小写。
grep -i "printf" 1.txt这个命令的意思是在1.txt文件中搜索不区分大小写的“printf”单词。执行这个命令后,输出的结果将会包含所有包含“printf”的行,无论是大写、小写还是混合大小写。

在文本查找与匹配过程中,有一个特殊的字符值得我们关注,那就是^符号。它具有独特的功能,可以精确地匹配字符串的开头位置,也就是行首。这意味着,当我们需要查找某个特定字符串在文本中的位置时,^符号为我们提供了一个高效的手段。接下来,我将通过一个具体的示例来详细介绍如何使用^符号进行文本查找。
还是对名为1.txt的文本文件,其中包含了一段使用printf函数的代码。这段代码在文件中出现了两次,一次位于行首,另一次则不在行首。为了解决这个问题,我们可以利用grep命令和^符号来查找开头为printf的字符串所在行。
我们可以输入以下命令:
grep '^printf' 1.txt执行此命令后,终端将输出开头为printf的字符串及其所在行。
![]()
最后,我想讲解的是参数是-E,“-E”是grep命令中的一个选项,用于启用扩展正则表达式。在启用此选项后,grep命令将遵循正则表达式的语法规则进行匹配。在扩展正则表达式中,部分特殊字符与语法规则具有特定含义,例如“|”表示逻辑或操作。还是借用1.txt来给大家举例:
printf("helloworld\n");
a=printf1;
PRINTF("helloworld\n");
echo ?"welcome"如果想查找有printf或echo的单词,我们使用“|”就可以匹配到,执行以下命令后,grep将输出匹配到的行:
Grep -E "printf|echo"?1.txt此时的输出结果为:

关于grep命令的一些常用参数以及其基础使用方式,本次暂且讲述至此。
2. cut
接下来,我们将深入了解另一个批量处理数据的命令——cut命令。在众多命令行工具中,cut命令独具匠心,它通常用于提取文本文件中的特定列数据,以特定的分隔符为标志。这种命令的主要应用场景是对文本文件进行提取和切割,从而简化数据的查找、筛选和分析等过程。下面,我们将详细介绍cut命令的用法和应用实例。
首先,让我们了解一下cut命令的基本语法:
Cut [选项参数] [文件]其中,选项参数可以根据实际需求进行设置,以满足不同的需求。接下来,我们将详细介绍cut命令的一些常用选项。
倘若有一个文件2.txt,它的内容如下:
11:22:33:44
aa:bb:cc:dd
AA:BB:CC:DD首先,我们来谈谈-d选项。这个选项的作用是指定分隔符。在cut命令中,当我们想要根据特定的分隔符来分割文本内容时,就可以使用这个选项。它的使用方法很简单,只需在cut命令后加上“-d”选项,紧接着是要使用的分隔符。例如,如果我们想要以逗号作为分隔符来分割文本,可以这样输入命令:cut ?-d ?","。
但需要注意的是,-d选项不能单独使用,它需要与其他选项结合,最常见的搭配就是与-f选项一起使用。
接下来,我们来看看-f选项。这个选项的作用是指定截取区域,也就是我们要从文本中提取哪些列。它的使用方法也很简单,只需在cut命令后加上“-f”选项,紧接着是要提取的列数或列范围。例如,如果我们想要从文本中提取第1列和第3列,可以这样输入命令:cut ?-f 1,3。
以刚才的例子来说,如果我们想要以':'作为分隔符,提取2.txt文件中的第1列和第3列,可以使用以下命令:cut ?-d ?':' ?-f 1,3 2.txt。这样,以制表符为分隔符的2.txt文件的第1列和第3列数据就会输出到终端。

-f选项后面还可以跟上列的范围,用“-”连接两个数字,例如说我们想输出第一列到第三列,那我们可以这么做:
cut -d ':' -f 1-3 ?2.txt
如果文本有多行,而我们想要选取从第二行到最后一行的部分,那么我们并不需要去数最后一行是第几行。此时,有一个简单的方法可以满足我们的需求。
cut -d ':' -f ?1-??2.txt
此时输出的结果就是第二行到最后一行的数据。
除了使用分隔符进行文本分割,我们还可以利用字符为单位进行分割。在命令行工具中,cut命令的"-c"选项为我们提供了这种能力。它允许我们指定要提取的字符范围或数量。比如,我们想要从2.txt文件中提取第1、3、5个字符,只需要执行以下命令:
cut -c 1,3,5 2.txt执行后,我们将会得到以下的输出:

可见输出的就是第1,3,5列的字符。
3. awk
接下来,我们将深入了解一种名为awk的批量数据处理命令。awk是一种文本处理工具,能够对数据文件进行列操作。该命令使用频繁,具备极高的灵活性。除基本形式外,awk还提供诸多高级功能与选项,以实现更为复杂的文本处理任务,如条件过滤、数据排序、数据转换及数据格式化等。其语法格式如下:
awk ?'条件{执行动作}'文件名
awk ?[选项] ?'条件1 ?{执行动作}... ?'文件名在介绍awk之前,需提及printf命令。printf用于格式化输出,不会自动换行,通常使用%符号作为格式化指令。其中%,ns表示输出字符串型,n代表字符数量;%i表示输出整型,n代表数字数量;%nf表示输出浮点型,n代表小数点后位数。
相较而言,print命令可输出字符串和变量,输出结果为字符串或变量值,并在结尾自动添加换行符。printf命令需搭配格式化字符串和变量进行输出,而print命令可直接输出字符串和变量。以下举一实例进行说明:
在awk命令中,$1~$9不再表示参数传递时的第一个至第九个参数,而是分别代表第一列至第九列数据。
为便于演示,我们先创建一个名为3.txt的新文本,内容如下:
Tom 25 177cm
John 30 180cm
Lucy 28 165cm该文件中,每行包含三列数据,分别为人名、年龄和身高,列间以空格分隔。接下来,我们将以此文件为例进行具体操作。
在处理文件3.txt时,printf首先提取第一列和第二列的数据,并确保按照预定的格式进行展示。这里,s和i分别代表字符和数字的输出。显而易见,如果没有指定特定的格式,输出过程将无法进行。
若未指定输出格式,print命令会采用空格作为默认的分隔符,将第一列和第二列的数据串联起来。最后,它会在结尾处添加一个换行符,确保输出的整洁和易读。

除了使用 "{print}" 命令来输出数据外,还可以使用其他的 awk 命令来进行更复杂的数据操作。例如在awk中,同样可以使用某个选项参数来指定分隔符,-F参数就发挥这个作用,我们还是用之前的2.txt来举例简单介绍。
还是以冒号为分隔符,输出2.txt第3列数据。
awk -F ':' '{print $3}' 2.txt
可见此时输出的就是第三列的数据
另外在awk中,BEGIN 是 awk 的关键字之一,用于在 awk 命令执行之前执行一些操作。BEGIN 关键字后面跟着一对大括号,大括号中的代码块会在 awk 命令执行之前执行。在 BEGIN 块中,可以定义变量、执行计算、输出信息等操作。下面我们还是举个例子说明BEGIN的用法,还是将3.txt作为例子,我们可以使用 awk 命令来读取文件并输出文件中每一行的数据,同时输出文件的标题信息。因此在输出文件每一行的数据之前,我们就先得把标题输出出来。这时可以用到BEGIN关键字。

在该命令中,"BEGIN ?{print ?"Name ?Age ?Height"}"表示在 ?awk命令执行之初,预先输出标题信息,"{print ?$1,$2,$3}"则代表输出第一、二、三行的数据。
在awk程序中,通过设置FS变量可以指定当前分隔符。在BEGIN阶段定义分隔符,即可与上述示例一样,以冒号为分隔符,输出2.txt文件的第3列数据。以下是具体操作方法:
awk 'BEGIN {FS=":"} {print $3}' 2.txt
"BEGIN {FS=","}" 表示在程序执行之前将 FS 的值设置为逗号,输出结果与之前的例子相同。
awk中还存在一个关键字——END,用于在awk命令执行后执行特定操作,主要涉及打印最终统计结果、输出汇总信息、执行清理操作等后处理任务。END关键字后紧跟一对大括号,其中的代码块会在awk命令执行后执行。以下仍以例子3.txt为例说明END的用法:
若想使用awk命令读取文件并统计文件中年龄总和,可以如此操作:第二列$2存储了年龄数据,通过sum+=$2计算年龄总和,并在程序执行完毕后输出结果。
awk '{sum+=$2} END {print "Sum:" sum}' 3.txt![]()
此时就计算出来了年龄的总和。
在awk命令中,内置变量NR代表当前处理的记录行号。NR在awk命令中的运用广泛,可用于记录行号、统计记录数量、筛选记录等操作。以下以3.txt文件为例进行简要说明:
我们可以使用awk命令读取文件并输出每行数据及对应的行号。此外,"$0"表示当前文本的全部内容。
awk '{print NR". "$0}' 3.txt
此时便输出了当前文本的行号和文本内容。
除了记录行号,NR 还可以用于记录文件的总行数。例如下面的命令可以输出文件的总行数:
![]()
如此而来,我们上面用END关键字计算了年龄的总和,现在就可以通过NR内置变量计算平均年龄:
awk '{sum+=$2} END {print "Sum: "sum"\nAvg: "sum/NR}' 3.txt
4. sed
最后,我们将阐述sed命令。sed是一款源自 ?Unix/Linux系统的流式文本编辑器,主要针对文件执行替换、删除、插入及追加等操作,广泛应用于文本处理和脚本编写。其语法结构如下:
sed [选项参数] [动作] 文件名sed命令可接受多个命令,各命令间以分号或换行符分隔。
以下介绍sed命令的若干常用选项与操作:
在sed命令中,`-n`选项表示禁止输出。默认情况下,sed命令会将处理后的每一行输出至标准输出,而`-n`选项可抑制此默认行为,仅在命令处理后的行才输出。
若欲读取文件并输出文件中每一行数据,可使用 `p`选项。"p"表示将处理后的每一行输出至屏幕。例如,如下命令可输出`3.txt`文件中的每一行数据:
sed 'p' 3.txt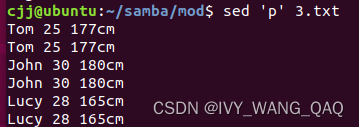
显然,sed命令在默认情况下呈现了两个相同的结果,这是因为该命令会将每行内容输出两次,一次是处理后的结果,另一次是原始行内容。若仅希望展示经过命令处理的行,可添加"-n"选项。通常,"-n"与p一同使用,以实现该目的。在此命令中,"-n"选项意味着禁止默认输出行为,"p"则表示将处理后的每一行输出到屏幕上。

此外,在sed命令中,"d"代表删除操作,可用于删除指定行或与指定模式匹配的所有行。此命令在文本处理中具有重要意义,可助力删除不必要的行或错误字符,从而便于处理正确数据。以下以3.txt为例,说明d命令的使用:若要删除文件中的第二行记录,可执行如下操作:

可以看到,文件中的第二行记录已经被删除了。除了删除指定的行,"d" 命令还可以与模式匹配结合使用,用于删除所有与模式匹配的行。例如如果我们想删除包含John的行:

还需指出,我们进行的删除操作并非实际删除,而仅仅是将其隐藏。若要实际删除文本内容,需加入-i参数。此处暂不进行演示,后续将继续讲解。
除删除操作外,还设有a和i两项,分别用于在行下方插入新内容和在行上方插入内容。下面将逐一举例说明:
若想在第三行插入其他人物信息,可以这样操作:

倘若我们想在第一行前插入标题信息,可以这样做:

在文本处理中,sed命令的应用可谓灵活多变。当我们希望将文本的某一行的内容替换为特定内容时,可以运用sed命令中的"c"选项,它代表替换操作。以下是将第二行内容替换为其他内容的示例:

在sed命令中,存在一种替换操作,其语法结构如下:
sed 's/old/new/' file.txt此命令将文件中的old字符串替换为new字符串。
若要将文本中的Lucy内容替换为我们期望的内容,可以采取以下方式:

由此,我们将Lucy的名字替换为King,这种替换方式更具通用性和灵活性。
实际上,上述操作并未对文本内容进行实质性修改。若要对源文件进行修改,必须使用-i参数,它可直接修改文件中的内容。例如,在上面的替换内容中,若打开3.txt发现源文件未发生变化,可以尝试添加-i参数以查看是否可以修改,如下:
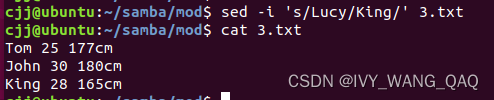
可见,文件已成功修改。在先前的讨论中,我们了解到在 ?sed命令中,"-n"选项表示禁绝对默认输出行为,仅在命令处理后的行才予以输出。此外,"-n"选项还可与搜索模式结合使用,以便查找包含指定模式的行。我们可以运用 ?sed命令读取文件并搜索包含 ?"John" ?的行,示例如下:
![]()
该命令中,我们指定了"/John/"作为搜索模式,用于查找包含"John"的行。参数"p"则负责将匹配到的行输出到屏幕上。从输出结果中可以看到,只有包含"John"的那一行被打印出来。在sed命令中,我们还可以利用"-e"选项来添加多个命令。这个选项允许我们将多个命令通过分号或换行符进行分隔,从而实现一连串的操作。例如,我们可以将替换文本和搜索输出合并为单个命令,以便同时进行查找和替换操作:
sed -i 's/Lucy/King/' 3.txt??
sed -n '/John/p' 3.txt
sed ?-e ?-i 's/Lucy/King/'??-e '/John/p' 3.txt
通过对本文的学习,我们希望读者能够掌握shell处理批量数据的基本方法,并在实际工作中运用这些知识。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!