LLM评估(一)| 大模型评估的四种方法
? ? ? ?一年多前,随着Stable Diffusion和ChatGPT的发布,生成式人工智能成为主流,发展速度快得令人难以置信。几乎每周都会有新的模型发布,并声称可以超越目前SOTA模型。但我们怎么知道它们是否真的好呢?在缺乏基本事实的情况下,我们如何比较和排序生成模型,即“正确”的解决方案?最后,如果LLM通过检索增强生成或RAG系统使用外部数据,我们如何判断它是否正确使用了这些数据?
? ? ? ?在本文中,我们将探讨生成人工智能的评估方法,包括文本生成和大型语言模型。
一、评估生成的内容
? ? ? ?首先让我们了解一下生成模型和判别模型之间的区别:生成模型生成新的数据样本(无论是文本、图像、音频、视频、潜在表示,还是表格数据)都与模型的训练数据相似。然而,判别模型通过训练数据学习决策边界,使我们能够解决分类、回归和其他任务。
二、GenAI评估挑战
? ? ? ?由于生成模型的任务性质,评估生成模型本质上比判别模型更具挑战性。判别模型的性能相对简单,可以使用适合任务的指标来测量,例如分类任务的精度、回归任务的均方误差或对象检测任务的交集。
? ? ? ?相比之下,生成模型旨在产生新的、以前看不见的内容,评估这些生成样本的质量、一致性、多样性和有用性更为复杂。例如,文本生成模型可能会生成语法正确的句子,但它可能缺乏多样性,并重复生成类似的句子。相反,它可能会产生不符合逻辑或上下文意义的不同输出。
? ? ? ?此外,语言模型可能会生成语法和上下文都正确的文本,但对用户没有帮助(或者,在最坏的情况下,是冒犯性的或有害的),这样的模型不应该被认为是高质量的。
? ? ? ?最后,检索增强生成或RAG系统可能会生成结构良好的内容,这些内容听起来合理,对用户有帮助,但不是基于模型应该检索的外部数据。因此,用户可能会收到幻觉般的答案,而不是基于数据的答案。
三、LLM评估方法
? ? ? ? 那么我们该如何评估大型语言模型呢?大多数方法可分为以下四种:
🎯?特定任务指标(Task-Specific Metrics)
🔬 研究机构发布的基准(Research Benchmarks)
🤖 LLM自我评估(LLM Self-Evaluation)
👤 人工评估(Human Evaluation)
? ? ? ?每种方法都有其优点和缺点,它们在实施难度和相关成本方面也有所不同。而且,也不存在“一刀切”的评估协议。然而,了解这些对评估语言模型有很大帮助。
3.1 🎯 任务特定指标
? ? ? ?自然语言处理是一个比今天的LLM古老得多的领域。过去,已经提出了许多解决方案来解决常见的文本处理任务,例如文本摘要或从一种语言到另一种语言的机器翻译。为了评估这些解决方案,设计了特定的指标,如今,这些指标仍然可以用于评估LLM。
a)摘要
? ? ? ?评估文本摘要的一个主流的评估指标是ROUGE(Recall-Oriented Understudy for Gisting Evaluation),ROUGE将模型生成的文本摘要与人工编写的“groundtruth”参考摘要进行比较。让我们看看它在实践中是如何工作的。先看一下下面这段简短的对话:
Anna: Hey, have you seen my copy of “The Silent Stars”? I can’t seem to find it anywhere.
Ben: “The?Silent Stars”? Isn’t that the one with the blue and gold cover?
Anna: Yes, that’s the one! I’ve been searching for it all morning. I thought I left it on the coffee table.
Ben: Oh, I think I might have taken it to the park yesterday. Wanted some fresh air and a good read. Sorry, I should’ve asked.
Anna: No worries. Did you like it?
Ben: I only got through the first few chapters, but it’s intriguing. The way the author describes the universe… it’s poetic.
Anna: I’m glad you think so. It’s one of my favorites. Just remember to return it when you’re done.
Ben: Promise I will. And next time, I’ll make sure to ask before borrowing.
Anna: Deal. And maybe we can discuss it once you’re done. It’s always fun to share thoughts on a good book.
Ben: Sounds like?a plan!
? ? ? ? 现在,我们试着给出一个对话的参考摘要:
Anna realizes Ben borrowed her favorite book without asking, and they agree to discuss it once he’s finished reading.
? ? ? ? 以下是从GPT-4获得的摘要:
Anna searches for her favorite book “The Silent Stars,” and Ben admits he borrowed it without asking, leading to a plan to discuss it later.
? ? ? ?最简单的ROUGE指标是ROUGE-1召回率和ROUGE-1精度。为了计算它们,我们计算两个摘要之间匹配的unigram(单词)的数量。
? ? ? ?ROUGE-1 Recall是指unigram匹配的数量除以参考摘要中的unigram总数。在我们的例子中,匹配的unigram是:Anna, Ben, borrowed, her, favorite, book, without, asking, and, to, discuss, it——12个匹配。参考文献摘要中的unigram总数为19。因此ROUGE-1召回量为12/19=0.63。
? ? ? ?类似地,ROUGE-1 Precision是unigram匹配的数量除以模型摘要中的总unigram,此处为12/23=0.52。
? ? ? ?就像常规召回和精度一样,ROUGE指标可以使用调和平均值进行组合,以获得f1分数:2×(0.63×0.52)/(0.63+0.52)=0.57。
? ? ? ?让我们使用rouge软件包检查一下我们计算的正确性。
from rouge import Rouge?hypothesis = """Anna searches for her favorite book 'The Silent Stars', and Ben admitshe borrowed it without asking, leading to a plan to discuss it later"""reference = """Anna realizes Ben borrowed her favorite book without asking, and theyagree to discuss it once he's finished reading"""?rouge = Rouge()scores = rouge.get_scores(hypothesis, reference)?print(scores[0]["rouge-1"])
{'r': 0.631578947368421, 'p': 0.5217391304347826, 'f': 0.571428566473923}? ? ? ?到现在为止,都还不错。但是,细心的读者会注意到ROUGE-1度量的问题。它只测量生成的摘要和参考摘要之间的unigram重叠,一个完美的ROUGE-1分数意味着两个摘要中的所有单词都是相同的。然而,这并不一定意味着生成的摘要是连贯的或有意义的。
? ? ? ?让我们考虑一个假设的参考摘要:
Climate change is a significant threat to global biodiversity.
? ? ? 以下生成的摘要很混乱,不能传达连贯的信息,然后它的ROUGE-1(回忆和精度为1)是完美的。
Change biodiversity is climate to a threat global significant.
? ? ? ?我们再考虑一下下面的句子,它与原来的信息完全矛盾。
Climate change is NOT a significant threat to global biodiversity.
? ? ? ?然而,它的精度和召回率都是0.9。
? ? ? ROUGE-1分数的问题在于它们忽略了语序,而在大多数语言中,语序对意义很重要。缓解这种情况的一种方法是,不计算unigram(单个单词)匹配,而是计算n-gram的匹配,即单词序列。
? ? ? 例如,计算bigrams(n=2的n-grams)来评估之前的对话摘要,我们使用ROUGE-2来计算一下召回。两个总结之间匹配的bigram是:“her favorite”, “favorite book”, “without asking”, “to discuss”和?“discuss it”。匹配上5个,给定参考文献摘要中有18个bigrams,我们得到ROUGE-2召回是5/18=0.28。
print(scores[0]["rouge-2"])?# 输出{'r': 0.2777777777777778, 'p': 0.20833333333333334, 'f': 0.23809523319727902
? ? ? 虽然ROUGE-1会忽略单词顺序,但ROUGE-2和ROUGE-n度量通常会走向另一个极端:它们专注于n-gram的精确匹配,强调特定的单词序列及其顺序。还有一种更优化的解决方案,比如ROUGE-L。
? ? ? ROUGE-L基于生成的摘要和参考摘要之间的最长公共子序列(LCS)。LCS是两个文本中以相同的顺序出现,但不一定连续的一个单词序列。这使得ROUGE-L对单词的确切顺序不那么敏感,它可以捕捉文本的重要信息,即使措辞不完全相同。下面是计算结果:
print(scores[0]["rouge-l"])?# 输出{'r': 0.47368421052631576, 'p': 0.391304347826087, 'f': 0.42857142361678}
? ? ? ?摘要评估到此为止,让我们讨论另一个常见的语言任务:机器翻译。
b)机器翻译
? ? ? ?如果你使用LLM将文本从一种语言翻译成另一种语言,那么可以使用BLEU(Bilingual Evaluation Understudy)分数进行评估,它衡量机器翻译与一组高质量人工翻译的接近程度。
? ? ? ?想想英国著名的穿山甲“The quick brown fox jumps over the lazy dog”。让我们把它翻译成波兰语。假设模型产生的机器翻译是
Szybki lis skacze nad leniwym psem.
? ? ?假设人类参考翻译是
Szybki br?zowy lis przeskakuje nad leniwym psem.
? ? ? ?通常,BLEU计算中会使用多个参考翻译来说明不同的短语可能是同样正确的翻译,但为了简单起见,我们只使用一个。
machine = "Szybki lis skacze nad leniwym psem".split(" ")golden = "Szybki br?zowy lis przeskakuje nad leniwym psem".split(" ")
? ? ? ?为了获得BLEU分数,我们将从计算几个n-gram的精度开始,其方式与ROUGE所做的方式非常相似。让我们来计算BLUE-3,这意味着使用高达3阶的n-gram。
? ? ? 对于unigram,我们检查参考翻译中预测单词的百分比,BLEU分数是5/6=0.83。对于bigram,它是2/5=0.4(只有“nad-leniwym”和“leniwym-psm”匹配)。对于3-gram,BLEU分数是0.25。
? ? ? ?接下来,我们计算这四个n-gram精度的几何平均值:
geom_avg_precision = (0.83 * 0.4 * 0.25) ** (1/3)pyth? ? ? ?最后得到0.436。当模型生成的翻译比参考翻译更短时,会进行惩罚,目的是防止翻译过短,这会影响精度分数。简短惩罚计算如下:
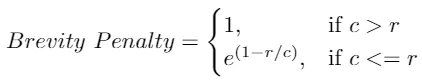
? ? ? ? 其中r是参考翻译的长度,c是机器翻译的长度。
breviy_penalty = np.exp(1 - len(golden)/len(machine))? ? ? ?在我们的案例中,由于模型翻译比参考翻译文本更短,因此惩罚总计为0.846。
? ? ? ?最终的BLEU分数是n-gram精度的几何平均值乘以简洁惩罚。
bleu = geom_avg_precision * breviy_penalty? ? ? ?对于我们的例子,最后得到的是0.369。我们可以使用nltk库中的BLEU分数实现来验证这些计算的正确性。
bleu_nltk = nltk.translate.bleu_score.sentence_bleu([golden], machine, weights=(1./3., 1./3. , 1./3.))
结果相同。
? ? ? ?尽管BLEU可以说是最简单、最受欢迎的,但它并不是评估机器翻译的唯一指标。NIST(National Institute of Standards and Technology)的指标提高了BLEU分数,它通过对频率较低的n-gram给予更多的权重来关注翻译的信息性,这被认为对评估翻译质量更重要。NIST还对过长的翻译进行长度惩罚。其他流行的翻译指标还有METEOR(https://en.wikipedia.org/wiki/METEOR)和CIDEr(https://arxiv.org/abs/1411.5726)
c)任务特定指标:结论
? ? ? ?使用特定任务的指标,如用于摘要的ROUGE或用于翻译的BLEU来评估LLM,具有非常可扩展和高效的显著优势:可以快速自动地评估生成的文本的大部分。然而,这些度量只能捕捉语言质量的某些方面,并且仅适用于特定任务。对于需要理解细微差别、风格、文化背景或习语的任务,它们往往不能很好地发挥作用。
? ? ? ?出于这些和其他原因,目前评估新LLM最流行的方法是根据研究基准对其进行评分。让我们看看它是如何工作的!
3.2 🔬 研究基准
? ? ? ?简而言之,基准是LLM可以通过编程运行的大量问题和答案,输出通常是一个百分比分数,表示模型答对了多少问题。
目前有很多不同基准测试,比如数学、逻辑和推理、写作、编码等等。
a)流行的基准
? ? ? ?其中最流行的是大规模多任务语言理解(MMLU)。MMLU专注于零样本和少样本评估,使其更类似于我们评估人类的方式。它涵盖了STEM、人文学科、社会科学等57个领域,主要评估知识和解决问题的技能。
? ? ? ?另一个常用的基准是GSM8k,这是一组小学数学单词问题,需要想出一个由基本算术计算组成的多步骤过程。
? ? ? 代码生成LLM通常根据HumanEval(一个手工编写的编程问题的数据集)进行评分。每个问题都包括一个函数签名和一个docstring,任务是编写函数的主体,使其通过相应的单元测试。
? ? ? LLM在这些基准和其他基准的表现可以跟踪排行榜,比如HuggingFace上的 Open LLM Leaderboard(https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)。基准在各种任务中快速、廉价的评估方面做得很好。这是否意味着LLM评估已经解决?正如你可能已经猜到的,答案是否定的。
b)数据污染
? ? ? ?鉴于大多数LLM都是根据从互联网上收集的大量数据集进行预训练的,因此一些流行的基准存在包括模型在训练中已经看到的数据的风险。
? ? ? ?事实证明,情况确实如此。在某些用例下,发现多达五分之一的基准测试数据与模型的训练集重叠。因此,模型可以完美地回答基准测试的问题,因为他们已经知道了这些问题,这使得基准测试几乎毫无用处。
? ? ? ?LLM研究界自然意识到了这个问题,已经开发了许多方法来检测基准的受污染部分并将其从测试集中移除。
? ? ? 然而,正如(https://arxiv.org/abs/2311.04850)这篇最近发表的著名论文所表明的那样,这些方法还不够好。作者设法训练了一个130亿参数的小模型,该模型似乎超过了GPT-4。据传,目前最先进的GPT-4在应用行业标准去污方法的同时使用了1万亿个参数。
? ? ? ?听起来不可能,因为事实并非如此。事实证明,测试数据的简单变化,如转述或翻译,可以很容易地绕过这些净化措施,产生一个与测试基准过度拟合的模型。
c)基准:结论
? ? ? ?那么,基准是否完全不可靠?我认为他们不是,有三个论点来支持:
-
基线比较:基准为比较不同的模型提供了一个标准化的基线。即使受到污染,它们也可以深入了解各种模型在类似条件下的表现;
-
随时间推移的相对性能:基准允许评估随时间推移或不同方法之间的相对性能改进,即使绝对性能可能因数据污染而膨胀;
-
确定总体趋势:基准可以帮助确定模型性能的总体趋势,例如某些类型任务的优势或其他类型任务的劣势。
? ? ? ?话虽如此,我认为当前的基准并不能为我们提供模型性能的绝对可靠衡量标准,也不允许我们在特定应用的竞品模型之间进行选择。如果我们将在不同数据集上预训练的两个模型与特定基准进行比较,则后者尤其正确。
? ? ? ? 让我们转向LLM评估的另一种方法:LLM本身。
3.3 🤖 LLM自我评估
? ? ? ?大型语言模型可以自我评估!这个想法很简单。您查询您的模型并得到回复。然后,将查询和响应提供给另一个LLM,同时提供一个手工设计的提示,要求模型在查询的上下文中评估响应。
? ? ? ?评估器LLM可以是您正在评估的同一模型的新实例,也可以是完全不同的LLM。例如,您可能需要评估LLaMA的输出,以确保它们不包含仇恨言论。你可以直接将这些回复传递给GPT4,同时提示它:“下面的文本是仇恨的吗?”。或者,如果您使用LLM在两种语言之间进行翻译,您可以使用原始文本和LLM提供的翻译来查询评估者LLM,询问该翻译是否正确。
a)相对任务难度
? ? ? ?模型如何自我评估?例如,如果它不能产生正确的反应,它怎么能知道它不正确呢?如果它知道,难道它一开始就不应该想出一个正确的答案吗?这个解释与任务的相对难度有关。虽然该模型无法预测自己的错误(因为这与预测实际的地面实况相同),但它可以很容易地预测自己的loss或无符号误差。换句话说,该模型能够预测它的偏离程度,但不能预测它的方向。这是因为预测损失比预测误差容易得多。
? ? ? ?这种情况与大型语言模型类似。确定一个给定的文本是否包含仇恨言论的任务比生成一个没有仇恨言论的文本要容易得多。评估所提供翻译的质量比从头开始翻译更容易。
b)评估RAG
? ? ? ?LLM自我评价对于增强检索生成(RAG)系统尤其有用。在RAG中,将用户查询与外部数据集进行比较,以查看该数据集是否包含与查询相关的任何信息。然后,将重试的信息与查询一起传递给LLM,使其能够生成数据通知的答案。RAG允许构建LLM,访问特定领域或专有数据集,同时减少幻觉。
? ? ? ?例如,如果我问ChaptGPT“Where did I do my master’s degree?”,它无法知道。然而,如果我使用我的PDF简历文件建立了一个RAG系统,它会检索到相关的行。LLM的输入大致如下所示:
Context: MSc Econometrics, Erasmus University Rotterdam
Query: Where did I do my master’s degree?
? ? ? ? 有了这些信息,模型回答这个问题就没有问题了。
? ? ? ?RAG系统对外部数据的使用需要额外的检查,以验证这些数据是否被正确有效地使用。具体而言,我们希望确保:
-
模型提供的响应与用户提交的查询相关;
-
RAG检索的外部数据部分与用户查询相关;
-
该模型产生的反应是基于检索到的数据,而不是其自身的幻觉或在预训练期间获得的一般知识。
? ? ? ?TrueLens(https://github.com/truera/trulens)是一个用于RAG评估的开源工具。它将我上面列出的三个概念形式化为响应、查询和上下文(即检索到的外部数据)之间的成对比较。
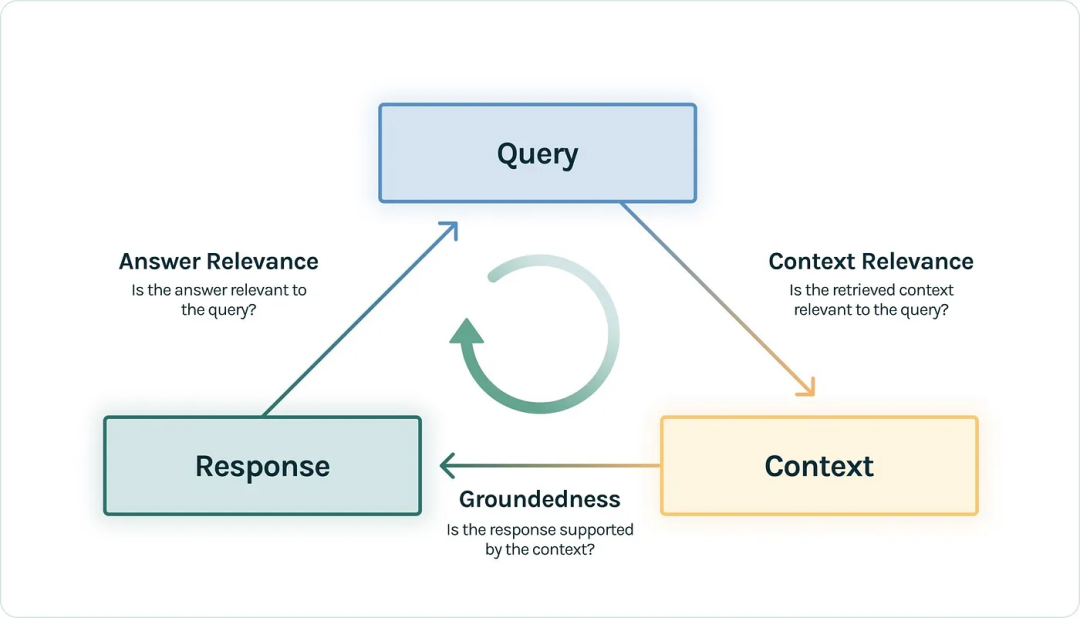
? ? ? ?TrueLens定义了以下性能指标:
- Answer Relevance (Response ? ?Query):
? ? ? ?答案与查询相关吗?
- Context Relevance (Query ?? Context):
? ? ? ? 检索到的上下文与用户查询相关吗?
- Groundedness (Response ?? Context)::
????????上下文是否支持响应?
? ? ? ?对于大型语言模型来说,这三项任务都足够简单。考虑到查询和响应,很容易判断后者是否与前者相关。这就是TrueLens使用LLM进行自我评估的原因。
c)自我评价:结论
? ? ? LLM自我评价可以快速且易于实施。对于每个查询,只需将其传递给一个LLM,收集响应,然后将两者传递给另一个适当提示的LLM进行评估。
? ? ? ?然而,这种方法也有几个缺点。首先,LLM评估者非常敏感。根据您使用的模型和提示方式,您可能会得到截然不同的结果。
? ? ? ?其次,它受到评估任务难度的限制。如果你感兴趣的任务是逐步解决数学问题,同时为每一步提供推理,那么评估其正确性是非常重要的。如果它违反了我们关于评估任务比原始任务更简单的假设,那么自我评估就不会起作用。
? ? ? 最后,自我评价的运行成本可能很高。如果你使用OpenAI API使用GPT4作为评估器,你可能会产生巨额账单。如果你自己托管一个开源评估器模型,你需要一台足够大的机器来拟合模型并运行推理。
? ? ? ?接下来,我们将讨论LLM评估的最后一组方法:人的评估。
3.4 👤 人工评价
? ? ? ?在LLM无法自我评估的情况下,例如之前的多步骤数学推理示例,或翻译为资源极低的语言,我们必须求助于人工评估。
? ? ? ?在我们介绍的所有评估方法中,人工评估通常是最可靠的,但可以说是实施最慢、最昂贵的(尤其是当你需要专业人员来评估复杂任务时)。
? ? ? ?在小范围内,您可以自己进行人类评估。对大部分人来说,这是为特定应用程序选择LLM的第一步:我们只需使用相同的查询查询不同的模型,并检查我们得到的答案。通过让朋友和同事评估几个例子,可以将其扩展一点,但可扩展性很快就达到了极限。
a)众包人力评估
? ? ? ?LMSYS和加州大学伯克利分校SkyLab的研究人员提出了一个有趣的想法:通过一种大型语言模型的战场来众包人类评估。
? ? ? 这个名为Chatbot Arena的项目允许人类向两个匿名模型(例如,ChatGPT、Claude、Llama)提出任何问题,并投票选出更好的模型。当人类决定每一场“battle”的获胜者时,模型会根据其ELO分数在排行榜上进行排名。
b)人工评价:结论
? ? ? 收集人工评估既缓慢又昂贵。然而,如果你正在构建一个特殊任务的LLM应用程序,那么让专家手工评估可能是了解系统真正性能的最佳策略。
? ? ? 像Chatbot Arena这样的众包项目是根据不同LLM的总体质量对其进行排名的好方法。不幸的是,我们不知道人类评估者到底对模型提出了什么要求。因此,如果你心中有一项特定的任务,你希望你的模型擅长,那么选择竞技场领导者可能不一定是最佳选择。
四、结论
? ? ? ?我们介绍了评估大型语言模型的四种方法:
4.1 🎯 任务特定指标
? ? ? ?快速、便宜、简单。使用ROUGE(用于摘要)或BLEU(用于翻译)等指标来评估LLM,使我们能够快速自动地评估生成的文本的大部分。然而,这些度量只能捕捉语言质量的某些方面,并且仅适用于特定任务。对于需要理解细微差别、风格、文化背景或习语的任务,它们往往不能很好地发挥作用。
4.2 🔬 研究基准
? ? ? ?这些庞大的问题和答案涵盖了广泛的主题,使我们能够快速、廉价地对LLM进行评分。不幸的是,它们经常被污染:基准测试集包含与LLM训练集中使用的数据相同的数据,这使得就测量绝对性能而言,基准测试不可靠。
4.3 🤖 LLM自我评估
? ? ? ?LLM自我评估快速且易于实现,但运行成本可能很高。当评估任务比原始任务本身更容易时,这是一个很好的方法。自我评估特别适用于RAG系统,以验证检索到的数据是否正确有效地使用。然而,LLM评估者对模型和提示的选择非常敏感。他们还受到原始任务难度的限制:关于数学问题的逐步推理不容易用LLM进行评估。
4.4 👤 人工评价
? ? ? ?可以说是最可靠的,但实施起来最慢、最昂贵,尤其是当需要高技能的人类专家时。试图收集人类评估是非常有趣的,但只能根据他们的一般技能提供模型排名。这使得它们在特定于任务的模型选择中不那么有用。
参考文献:
[1]?https://towardsdatascience.com/evaluating-large-language-models-a145b801dce0
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- oracle连接封装
- 非隔离BUCK恒流控制芯片SM7307产品特点与典型应用
- 策略模式【结合Spring框架实践】
- AI生成漫画或者小说推文——自动根据角色画绘本如何保持角色生成一致性的问题
- 搭配购买——并查集+01背包(洛谷P1455)土豆片的算法之路
- C程序训练:阶乘与溢出
- 瑞兔回宫,青龙下凡。
- IPC之十六:D-Bus的标准接口、自省机制和服务接口的具体实现方法
- 初始JavaScript详解【精选】
- 【rar转zip】如何把RAR文件改成ZIP格式