思码逸关钦杰:聊聊研效管理中的数据操纵
3月25日,思码逸咨询总监、研发过程提效专家关钦杰在 QECon 质效城市论坛【深圳站】分享了主题为《聊聊研效管理中的数据操纵》的演讲。
以下内容根据关钦杰老师分享内容整理:
在生活中,当我们去描述客观事实的时候,我们经常要用数据说话,比如,盐少许,就不如说盐 2 克更加科学精准。但是反过来我们也会发现,有时候数据不变,但说法不一样,结果和信息也会发生偏差。
我们今天也来聊一个相对轻松有趣的话题:研效管理过程当中数据操纵有哪些?我们有哪些反操纵的方法?数据本身不会说谎,但如何去呈现,传递的信息和结果可能会发生很大的一个反差。
相关性不等于因果关系
首先是一个有意思的例子,现实生活当中我们经常说“鱼和熊掌不可兼得”,那我们来看这幅图,横轴代表品质,纵轴代表颜值,大家觉得这两组数据放在一起,它有相关性吗?显然是没有相关性的。
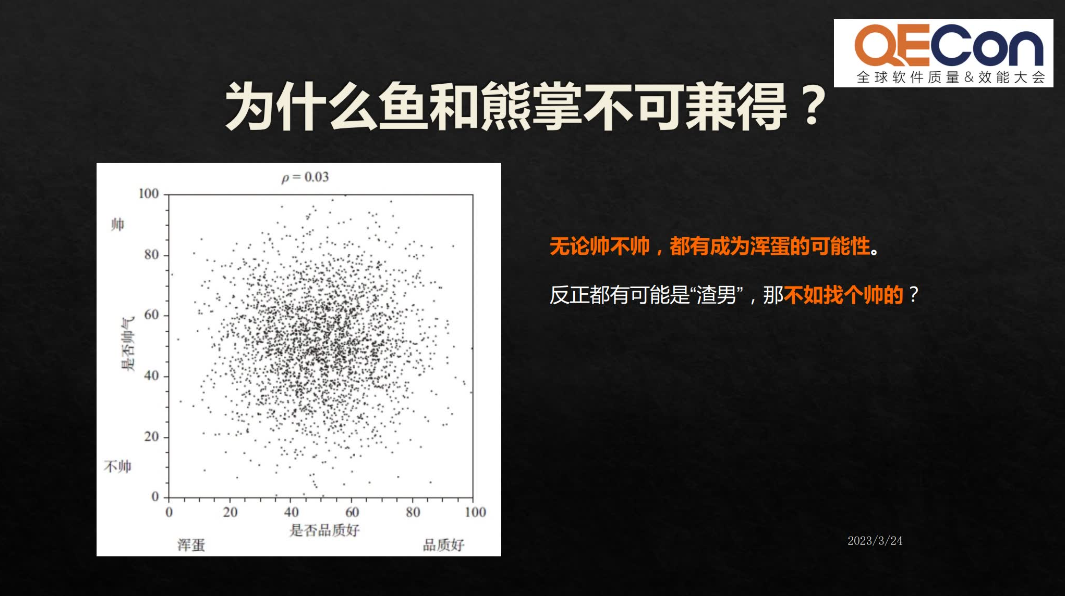
既然长得帅和品质好,没有相关性,那在单身的男女去找伴侣的时候,肯定要找一个又帅品格又好的。但扎心的现实是什么呢?我们去看这组数据。
在现实当中,我们不愿意和又丑又渣的人约会,就会剔除一部分样本。同时双方都有选择的权利,也有人可能会不愿意和你约会,又剔除了一部分数据之后,数据发生了变化——颜值和品质之间出现了负相关,也就是说越帅的人,具有“海王”体质的可能性相对高。这就是伯克森悖论。
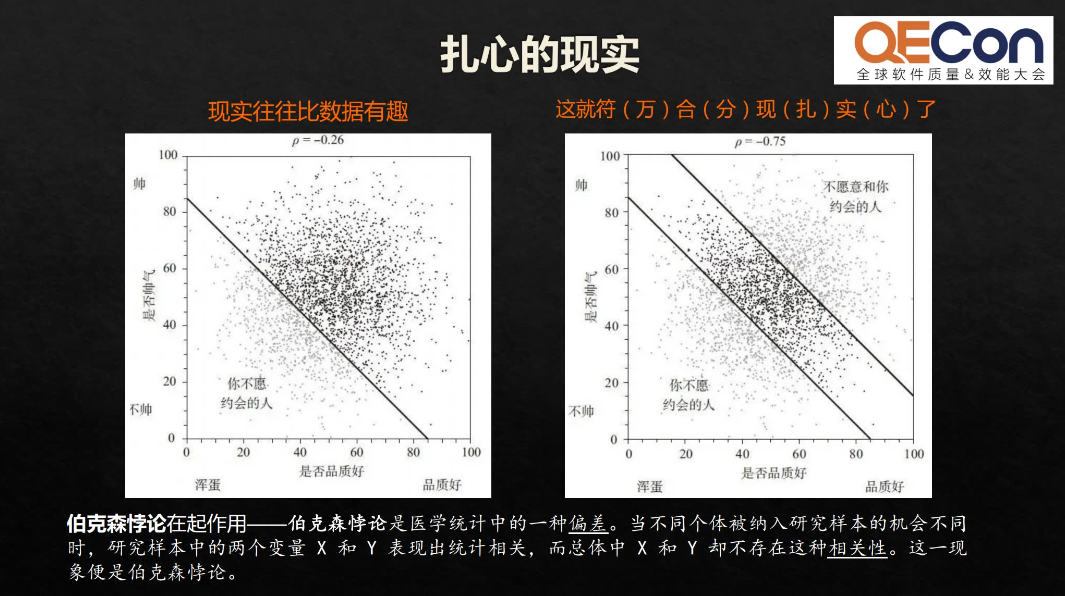
伯克森悖论是说当我们去把所有的样本总和放在一起看的时候,你会发现这些数据之间不具备相关性。但是当机会不同的时候,它会造成一种机会上的相关性。选择机会不一样,会造成相关性也发生很大的变化。伯克森悖论时刻提醒我们,我们的直观感觉总是建立在我们能够注意到的现象之上的,但真实世界包含了很多被我们忽视的现象,要了解真实的情况,就需要把忽视掉的情况都考虑到。
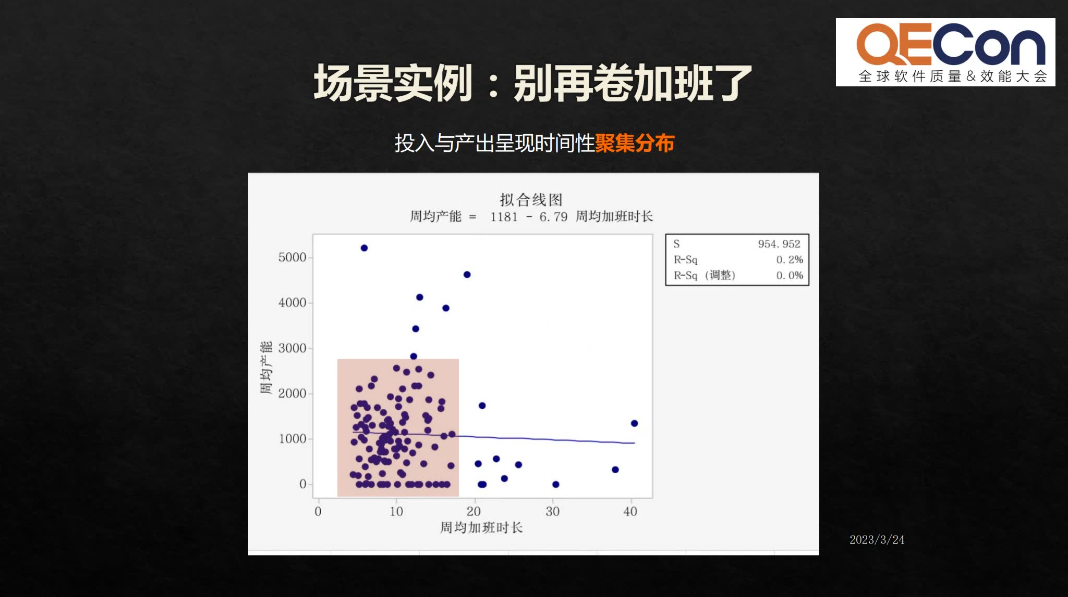
接下来是实际研发管理中的一个实例,我们用了两组数据,一组是每周的加班时长,统计加班时长跟产出之间是否相关。结果显示,加班时长和产出之间并没有非常强的正相关关系。在标注出的红色区间中,一定的加班时长范围内产出量呈现聚集性分布。这说明卷更长的加班时间,对产出的影响可能是不大的。
另一组数据也是大家比较关心的两个参数,一个是生育率,一个是房价。调查发现房价和生育率之间是很明显的负相关。对此,大家有两种解读。第一种解读是说,房价太高了,大家买不起房子所以就不生小孩;第二种解读是,在很多一二线城市,聚集了一些高收入的人群,他们的收入足以负担房价,但因为职业工作忙碌的原因,在30岁之前生小孩的概率非常低,因而也导致了这种负相关。
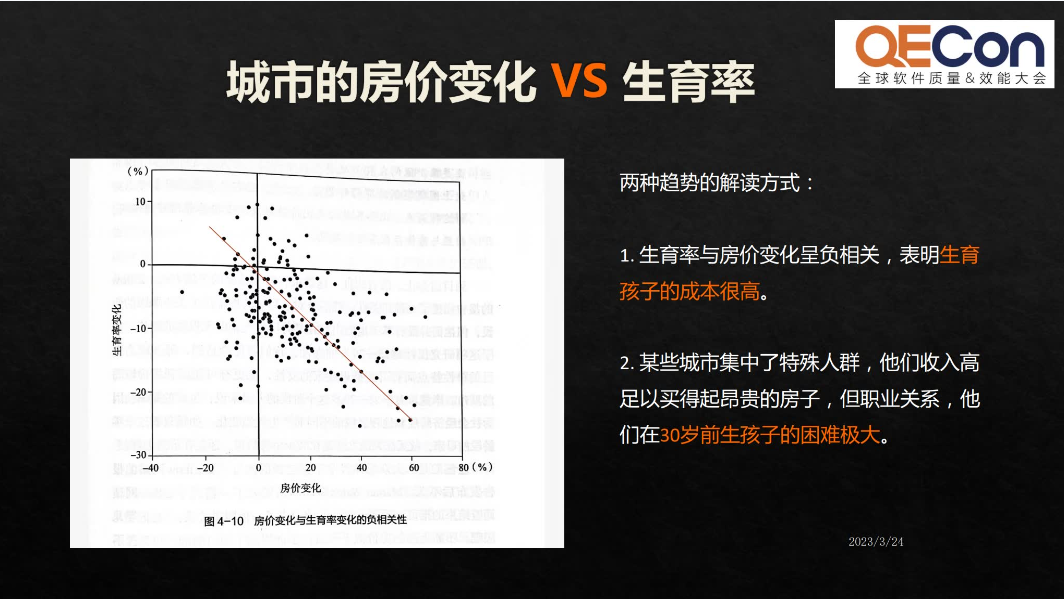
这也就告诉我们,相关性不一定等于因果关系。
在一些场景实例中,需求量与代码量也并不一定呈正相关,那可能会出现产品抱怨需求交付慢、研发委屈天天加班的情况,我们会问:研发的工作量都去哪了?这时,我们可以通过数据去做下钻分析:通过 commit message,将每一个commit对应到一个任务上去,这样可以清晰地看到每一个 commit 的目的和工作量,研发团队实际上在需求变更上花费了大量的工作量,而这些返工工作量也挤压了完成新需求开发的工作量。类似的下钻分析可以让我们更清楚地知道如何进行需求管理,让需求更稳更快地交付。
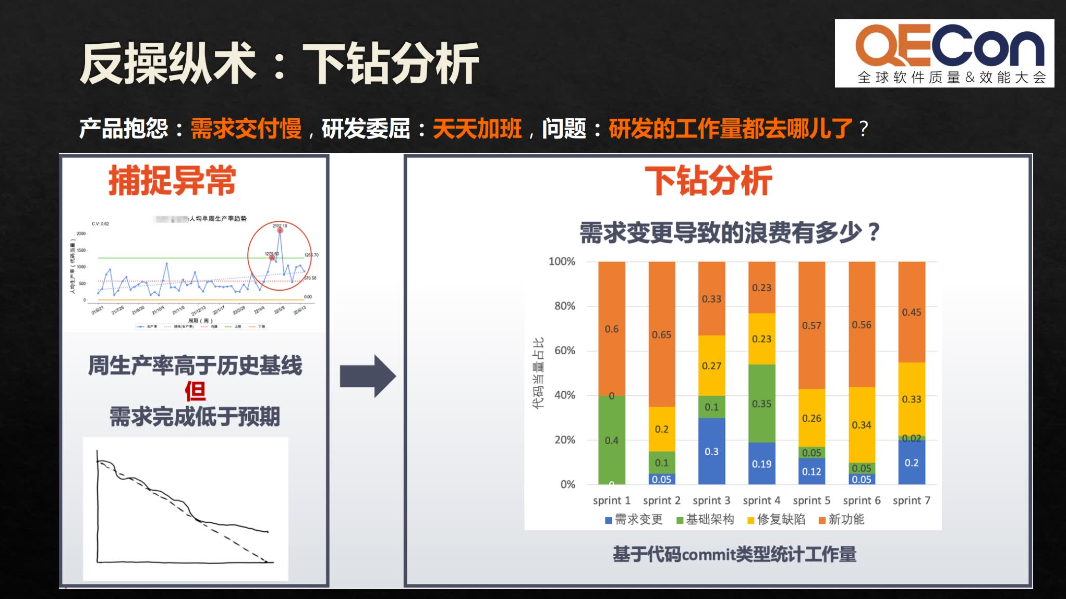
因此,在实际的工作当中,当我们去看到一组数据的时候,不要马上为这组数据它是正相关还是负相关而欢呼,因为有相关性的两组数据,并不一定有因果关系。
百分比陷阱
谷歌曾经遭到公众质疑,认为谷歌搜索返回的结果当中有假新闻和虚假信息。对此,谷歌的一名副总裁回应说,日常搜索中确实有一小部分查询会返回误导性的内容,但是占比很小,只有约0.25%。乍一听,这个数字很小,问题好像也并不严重。但谷歌每天要处理50亿次搜索,0.25%意味着,每天有1200多万次搜索会返回虚假信息,足以造成较大的负面影响,并不是一个小问题。
谷歌副总裁的说法其实是在利用百分比的方式弱化问题。百分比对同一个数据,在表述上也是“可大可小”的,完全看你想强调什么。比如某个地方的消费税,从购买价格的4%提高到了6%,可以说是增长了2个百分点,也可以说是增长了50%,因为花同样的钱,要交的税比原来确实多了50%。
但这两种说法,给人的感觉完全不一样,如果我想让人觉得增税幅度微不足道,就可以说只增加了2个百分点。如果我想让人觉得增税幅度很大,就可以说税率增加了50%。这也就意味着,需求交付率可能是一个伪指标。为什么呢?我们需要问两个问题:
第一,需求的大小可比吗?
我们的需求交付率是多少?迭代的百分比是多少?这个百分比是可以比较的吗?未必,因为需求的复杂度不一样,拆分的颗粒度不一样,不见得交付了10个需求就比5个需求的工作量大。
第二,前置时长平均值可信吗?我们经常会看到说需求的交付前置周期,前置时长是多少天?需求的平均交付时长是13.5天,但我们把数据标准从均值改为80分位/85分位数,会发现大多数需求交付周期长达21天,比13.5天多了差不多50%,是非常大的差异。
为什么这两个数据之间有这么大的差异?我们来看一下场景实例。这是不同的产品线和不同时期需求的实际规模,也就是对应到我们所说的代码当量。
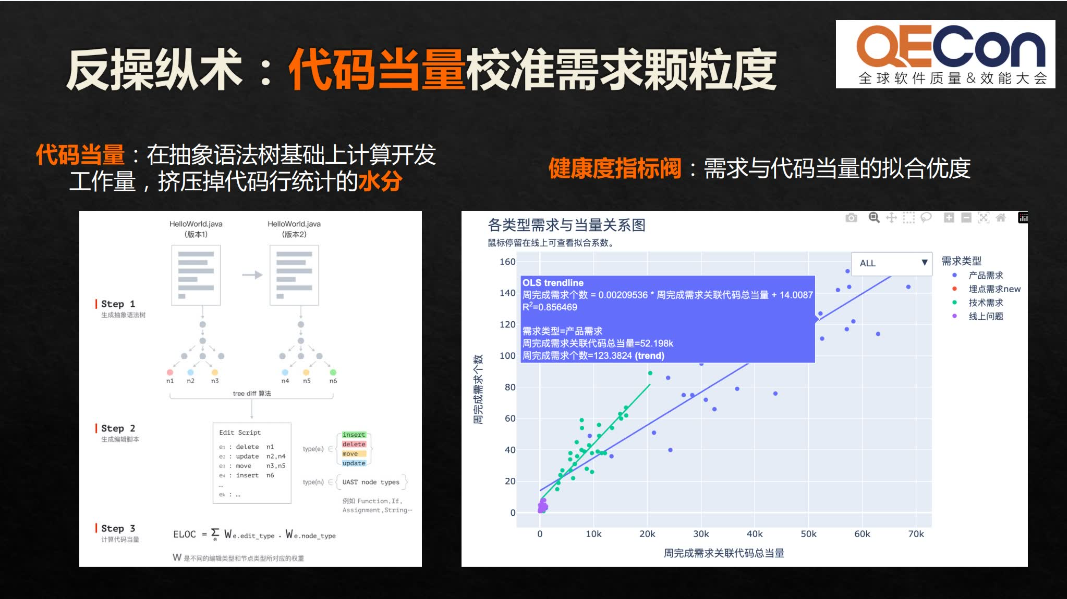
我们用代码当量去校准需求的颗粒度。代码当量是在抽象语法树基础上计算开发工作量,可以挤压掉代码行统计水分,有效地去除编码过程中的不良习惯和噪音,比如空行注释等等不良的操作习惯。我们在这里将代码当量作为一个类等比的单位。即大家有统一认知的、更加接近实际开发工作量的单位,可以用来校准需求的颗粒度。
第一个维度是稳定性。当需求颗粒度在450当量以内时,不会受到太多需求变更的干扰,交付的速率相对来说更高,稳定性相对高。第二个维度是质量。需求颗粒度大于2500当量,重点缺陷密度呈现指数增长。
所以在这个过程中,我们需要给组织提供一个可以校准的方法,然后再利用历史数据得到一个最优区间,帮助我们去指导需求的颗粒度拆分。在拆分后落到实际研发的过程中,我们如何去规划也取决于估算标准故事点是否合理,需要我们对历史结果进行校准。
警惕数据删失
在前面的部分我们讲到,百分比和均值都有一定的陷阱,再去看数据时,需要多当心,深入地思考。那么我们还可以做哪些下钻分析?接下来我们来看第三个典型的数据操纵——警惕数据的删失。
在《拆穿数据胡扯》这本书中有一个有趣的例子,是关于死亡年龄与音乐类型的曲线,即从事的音乐类型与寿命之间的相关性。我们看到,从事传统音乐类型(如布鲁斯、爵士乐、福音音乐等)的音乐人似乎是比较安全的,而新风格的音乐表演(如朋克、金属,尤其是说唱和嘻哈)看起来非常危险。
而实际上是:
-
导致这些数据有误导性的原因是右删失——在研究结束时仍然活着的人被从研究中删除了。
-
说唱和嘻哈属于新的音乐类型,最多40多年的历史,大多数音乐人从20几岁开始从业,所以大多数人都健在。
-
相比之下,爵士乐、蓝调、乡村等音乐已经存在一个多世纪了,所以多数人活到了80岁甚至更久。
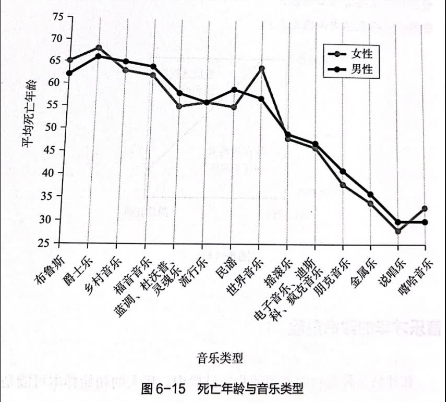
由于这个数据中剔除了健在的人,只把去世的人的数据拿进来了,所以导致这个数据看起来非常恐怖,不完整的数据统计周期会导致数据样本有这样大的偏差。
在场景实例中,也有样本范围选择偏倚的问题,比如可能会遇到,近一年半生产率呈现下降趋势,而近半年生产率呈现上升趋势。如何去反操纵呢?我们给出的反操纵术关键词是:不以高低论英雄。而是向外看水平,与行业相比,处于什么样的水平;向内看变化,与历史比,发生什么变化。
以上,我们引用了一些比较有趣的例子,大家可以结合现实中的实例去进行数据洞察以及反操纵的思考。
总结
-
抽样偏差可能使无关数据间呈现相关性。
首先我们要解决抽样偏差的问题,如果要通过大样本分析得到清晰数据,我们需要解决抽样偏差和样本偏差本身的一些问题,抽样偏差有时候会使无关的数据呈现出某种相关性。
-
相关性不等于因果关系
-
为核心指标建立衡量健康度的指标阀
-
不要光看均值,要结合大多数看
-
不以高低论英雄,向外看水平,向内看变化
数据从来都不会说谎,但也不会说出全部真相。在这个时代我们去谈研发数字化的建设,更便捷地、更快速地获取了大量的数据的情况下,这些数据怎么呈现、怎么展示、怎么保证它的健康度,是我们未来很长一段时间需要不断去关注和思考的一个重要问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt实现Excel表操作
- 【Zotero】如何在Zotero中手动编辑或手动插入文献信息
- 总结项目中oauth2模块的配置流程及实际业务oauth2认证记录(Spring Security)
- 商用密码应用安全评估实施方案(50页PPT)
- 总计近700页的超全面的前端面试、笔试大全
- 解决IDE中Java compiler JDK的版本总是被修改
- Unity报错:[SteamVR] Not Initialized (109)的解决方法
- 【STM32】STM32学习笔记-MPU6050简介(32)
- js数据操作——根据tree树形结构数据查找value对应的label值——js基础积累
- 智慧校园2.0物联网管理平台建设方案:PPT全文22页,附下载