7、DETR:基于Transformer的端到端目标检测
目录
一、论文题目
End-to-End Object Detection with Transformers![]() https://arxiv.org/abs/2005.12872
https://arxiv.org/abs/2005.12872
二、背景与动机
????????在计算机视觉领域,目标检测一直是一个核心问题。传统的目标检测方法,如Faster R-CNN和SSD,依赖于一系列复杂的预处理步骤,包括锚框生成、非极大值抑制(NMS)等。这些步骤通常需要精心的设计和调整,同时也引入了额外的计算复杂度。
????????随着Transformer模型在自然语言处理(NLP)领域的成功,其背后的注意力机制被发现对于处理序列数据非常有效。注意力机制的核心优势在于能够捕捉数据之间的长距离依赖性,这在处理图像时也非常有用。因此,研究者们开始探索Transformer在计算机视觉任务中的应用。
????????DETR(Detection Transformer)是一个创新的目标检测模型,它将Transformer模型整合到目标检测流程中,并提出了一种端到端的检测方法,摒弃了传统的预处理步骤。
三、创新与卖点
DETR的主要卖点在于其简洁而高效的设计。它通过以下几点实现了对目标检测的重新思考:
-
端到端学习:DETR彻底改变了目标检测的传统流程,实现了真正的端到端训练,将图像特征提取、目标定位和分类任务全部整合在Transformer中,提升了模型的整体优化效果。
-
无锚框设计:不同于以往的目标检测器需要预先定义一系列大小不一的锚框进行匹配,DETR直接预测出有限数量(例如100个)的物体候选框及其对应的类别概率,大大简化了检测过程。
-
集合预测与解码器-编码器结构:DETR采用Transformer中的编码器-解码器结构,其中编码器负责捕获全局上下文信息,解码器则生成一组潜在的目标框。独特的“集合预测”机制允许模型以并行的方式预测所有目标,无需繁琐的排序或筛选操作。
-
注意力机制:DETR利用Transformer中的自注意力机制,使得模型能够更好地理解图像中各个部分之间的关系,进一步提升目标检测的精度和鲁棒性。
四、具体实现细节
模型架构
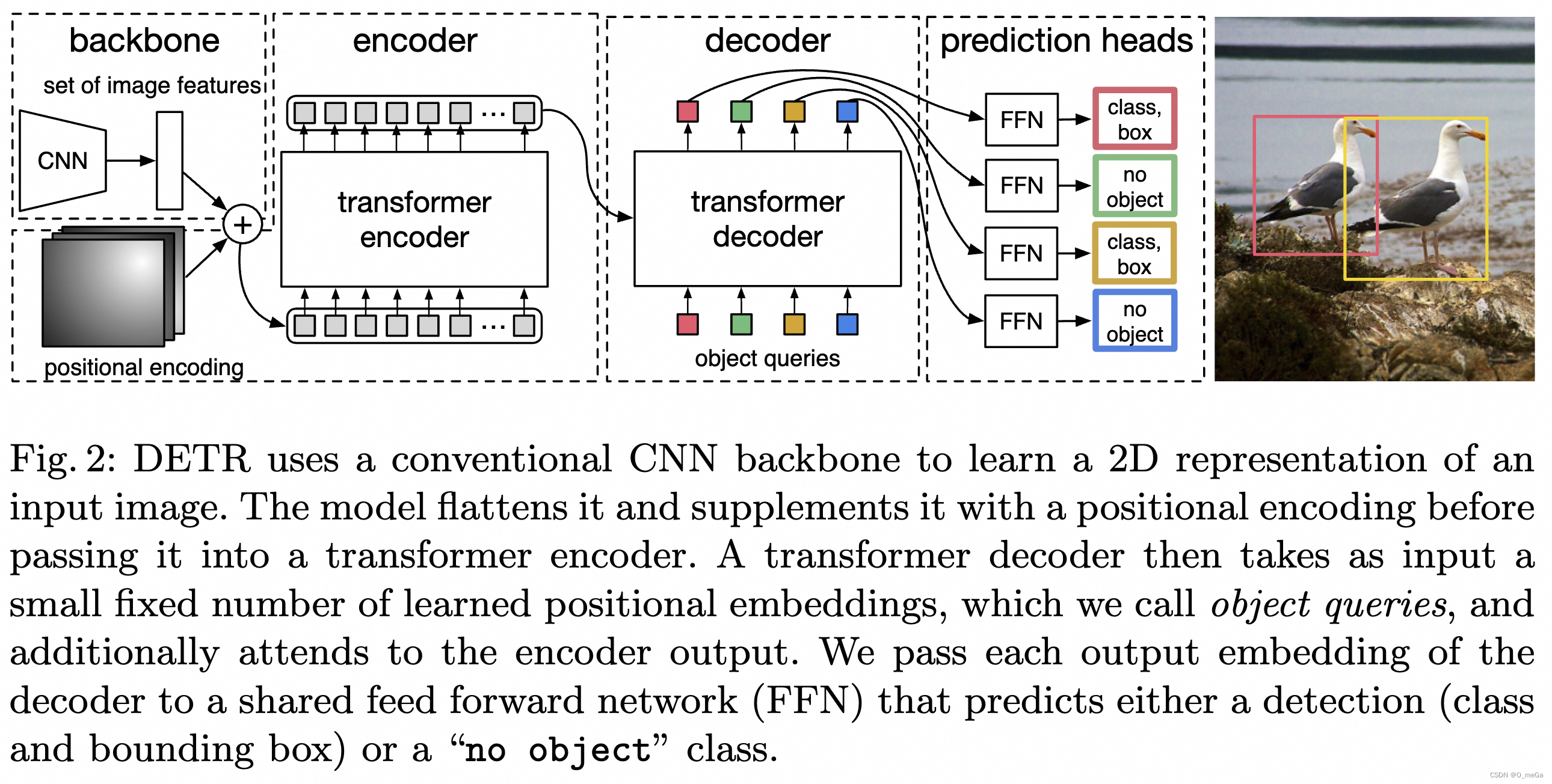
DETR的架构分为三个部分:CNN Backbone、Transformer和FFN(Feed Forward Network)。
-
CNN Backbone: 用于提取图像的特征。这些特征随后被展平并传递给Transformer模型。
-
Transformer: 包括编码器和解码器。编码器使用自注意力处理图像特征,解码器接收位置编码(learnable positional encodings)和来自编码器的特征表示,并通过自注意力机制和交叉注意力机制,生成一组固定长度的向量序列。每个向量代表一个潜在的目标框及其对应类别的预测。
-
FFN和输出层: FFN对每个解码器输出进行处理,输出层则生成最终的边界框和类别标签。
????????模型训练时,使用的损失函数是匈牙利损失和边界框回归损失的组合。匈牙利损失确保了预测和真实标签之间的有效匹配,而边界框回归损失则优化了框的精确位置。
一下内容引自这里:DETR目标检测新范式带来的思考 - 知乎
Transformer
CNN提取的特征拉直(flatten)后加入位置编码(positional encoding)得到序列特征,作为Transformer encoder的输入。Transformer中的attention机制具有全局感受野,能够实现全局上下文的关系建模,其中encoder和decoder均由多个encoder、decoder层堆叠而成。每个encoder层中包含self-attention机制,每个decoder中包含self-attention和cross-attention。
object queries
transformer解码器中的序列是object queries。每个query对应图像中的一个物体实例( 包含背景实例 ?),它通过cross-attention从编码器输出的序列中对特定物体实例的特征做聚合,又通过self-attention建模该物体实例域其他物体实例之间的关系。最终,FFN基于特征聚合后的object queries做分类的检测框的回归。

????????值得一提的是,object queries是可学习的embedding,与当前输入图像的内容无关(不由当前图像内容计算得到)。论文中对不同object query在COCO数据集上输出检测框的位置做了统计(如上图所示),可以看不同object query是具有一定位置倾向性的。对object queries的理解可以有多个角度。首先,它随机初始化,并随着网络的训练而更新,因此隐式建模了整个训练集上的统计信息。其次,在目标检测中每个object query可以看作是一种可学习的动态anchor,可以发现,不同于Faster RCNN, RetinaNet等方法在特征的每个像素上构建稠密的anchor不同,detr只用少量稀疏的anchor(object queries)做预测,这也启发了后续的一系列工作。
将目标检测问题看做Set Prediction问题
DETR中将目标检测问题看做Set Prediction问题,即将图像中所有感兴趣的物体看作是一个集和,要实现的目标是预测出这一集和。也就是说在DETR的视角下,目标检测不再是单独预测多个感兴趣的物体,而是从全局上将检测出所有目标所构成的整体作为目标。对应的,DETR站在全局的视角,用二分图匹配算法(匈牙利算法)计算prediction与ground truth之间的最佳匹配,从而实现label assignment。以上过程中需要定义什么是最佳匹配,也就是对所有可能的匹配做排序,DETR将一种匹配下模型的总定位和分类损失作为评判标准,损失越低,匹配越佳。注意,该匹配过程是不回传梯度的。DETR这种从全局的视角来实现label assignment的范式也启发了后续的一系列工作。
简易代码
import torch
import torch.nn as nn
from torchvision.models import resnet50
from torch.nn.functional import cross_entropy, softmax
class DETR(nn.Module):
def __init__(self, num_classes, num_queries, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6):
super(DETR, self).__init__()
# CNN Backbone: 使用 ResNet50,移除最后的分类层和池化层。
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
# 将 CNN 特征映射到 Transformer 的维度
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# Transformer: 使用 PyTorch 的 nn.Transformer
self.transformer = nn.Transformer(d_model=hidden_dim, nhead=nheads, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers)
# 类别预测:每个查询预测所有类别的概率
self.class_pred = nn.Linear(hidden_dim, num_classes)
# 边界框预测:每个查询预测一个边界框
self.bbox_pred = nn.Linear(hidden_dim, 4)
# 对象查询:固定数目的查询向量
self.query_embed = nn.Embedding(num_queries, hidden_dim)
def forward(self, images):
# 获取 CNN 特征
features = self.backbone(images)
# 调整特征维度匹配 Transformer 的输入要求
h, _, _, _ = features.shape
features = self.conv(features)
features = features.flatten(2).permute(2, 0, 1)
# 对象查询向量
queries = self.query_embed.weight.unsqueeze(1).repeat(1, h, 1)
# 通过 Transformer 进行特征和查询的交互
transformer_out = self.transformer(features, queries)
# 预测类别和边界框
class_logits = self.class_pred(transformer_out)
bbox_logits = self.bbox_pred(transformer_out).sigmoid()
return class_logits, bbox_logits
# 实例化模型
num_classes = 91 # COCO 数据集的类别数目
num_queries = 100 # 根据任务需求设定的查询数目
model = DETR(num_classes, num_queries)
# 输入图像张量 (batch_size, channels, height, width)
images = torch.rand(2, 3, 800, 800) # 示例图像张量
# 预测
class_logits, bbox_logits = model(images)
# 计算损失(需要实际标签才能完成)
# class_loss = cross_entropy(class_logits, labels)
# bbox_loss = ... # 边界框损失计算
# total_loss = class_loss + bbox_loss????????请注意,这个示例代码没有包含完整的 DETR 模型的所有细节,例如边界框损失的计算和匈牙利匹配算法。此外,为了训练 DETR 模型,还需要定义适当的数据加载器、优化器、学习率调度器以及训练循环。这个示例仅用于说明 DETR 架构的基本组件和数据流。?
五、结论与展望
????????DETR提供了一种全新的视角来解决目标检测问题。它通过利用Transformer强大的编码能力和端到端的优势,显著简化了检测流程,同时在准确率上与传统方法保持竞争力。尽管在速度上可能不如一些专门为实时应用设计的检测模型,DETR的架构为未来的研究和应用提供了一个有趣的新方向。
六、一些资料
官方源码![]() https://github.com/facebookresearch/detrDETR目标检测新范式带来的思考 - 知乎公众号:将门创投2020年,Transformer在计算机视觉领域大放异彩。Detection Transformer (DETR) [1]就是Transformer在目标检测领域的成功应用。利用Transformer中attention机制能够有效建模图像中的长程关系(long…
https://github.com/facebookresearch/detrDETR目标检测新范式带来的思考 - 知乎公众号:将门创投2020年,Transformer在计算机视觉领域大放异彩。Detection Transformer (DETR) [1]就是Transformer在目标检测领域的成功应用。利用Transformer中attention机制能够有效建模图像中的长程关系(long…![]() https://zhuanlan.zhihu.com/p/398940573
https://zhuanlan.zhihu.com/p/398940573
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FasterNet 与 RT-DTER 的 碰撞,打造 Faster-DTER 目标检测网络 | 《Run, Don’t Walk: Chasing Higher FLOPS for Faster 》
- qs.stringify 使用arrayFormat属性 + allowDots的数据处理 - 附示例
- TikTok未来十年:平台发展的前瞻性思考
- Iterator(迭代器) 和 list
- 为什么喜欢用土耳其区Netflix账号
- Java基础IO总结
- 信息安全导论参考答案之李冬冬 主编
- SOLIDWORKS插件SolidKits.BOMs工具之属性修改
- C语言使用蔡勒公式判断日期的星期
- 神经网络:表述(Neural Networks: Representation)