系列十三、集合
一、集合
1.1、概述
????????集合与数组类似,只不过集合中的数据量可以动态的变化。
1.2、体系图
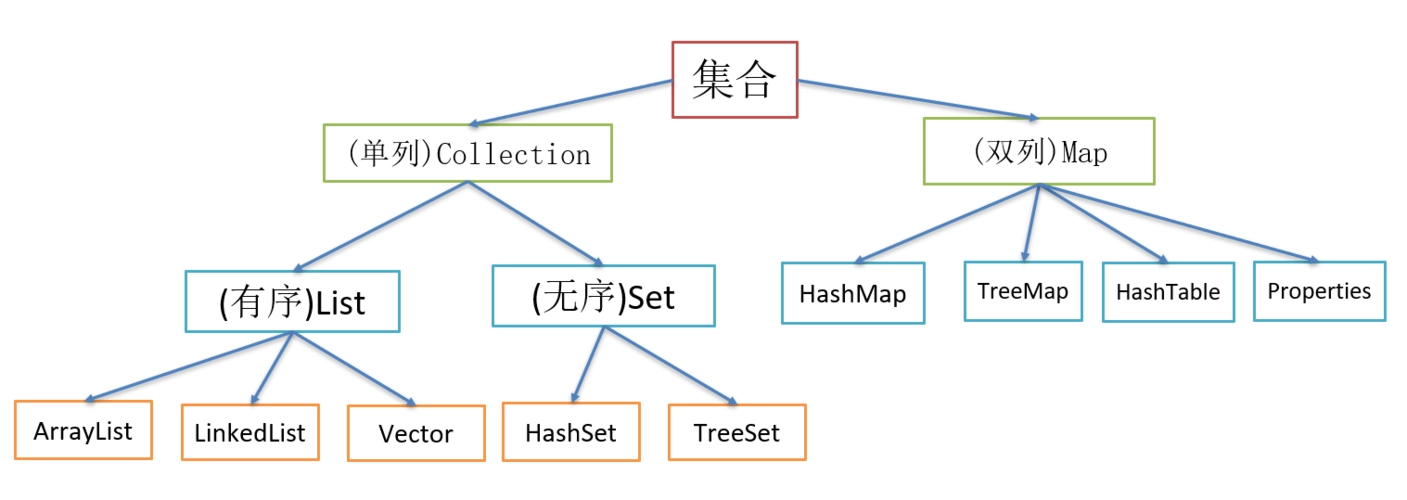
1.3、List集合
1.3.1、特点
????????存放的数据可以重复且有序。
1.3.2、常见操作
/**
* List集合常见操作
*
*/
@Test
public void listOperateTest() {
List<String> cityList = new ArrayList<>(4);
// 添加元素
cityList.add("beijing");
cityList.add("shanghai");
cityList.add("guangzhou");
cityList.add("shenzhen");
// 获取集合中的某一个元素
System.out.println("============================");
String element = cityList.get(0);
System.out.println("element = " + element);
// 获取集合中的所有元素
System.out.println("============================");
System.out.println("所有元素:" + cityList);
// 集合的长度
System.out.println("============================");
System.out.println("集合的长度:" + cityList.size());
// 判断某个元素是否在集合中
System.out.println("============================");
boolean exist = cityList.contains("beijing");
System.out.println("元素是否存在于集合中:" + exist);
// 删除集合中的某个元素
System.out.println("============================");
System.out.println("删除之前:" + cityList);
boolean remove = cityList.remove("beijing");
System.out.println("删除结果:" + remove);
System.out.println("删除之后:" + cityList);
}
1.3.3、ArrayList vs LinkedList
(1)ArrayList底层是数组,LinkedList底层是链表;
(2)ArrayList查询快、增删慢;LinkedList增删快、查询慢;
1.4、Set集合
1.4.1、特点
? ? ? ? 存放的数据不能重复,无序。
1.4.2、常见操作
/**
* Set集合常见操作
*/
@Test
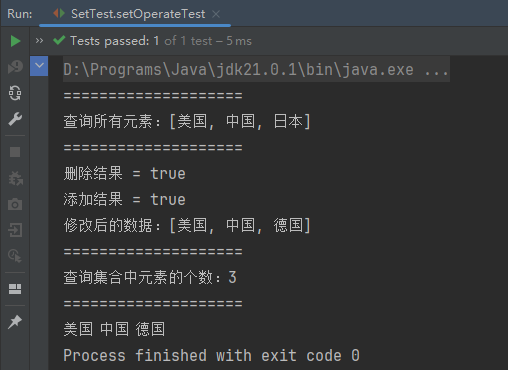
public void setOperateTest() {
HashSet<String> countrySet = new HashSet<>(4);
// 添加元素
countrySet.add("中国");
countrySet.add("中国");
countrySet.add("美国");
countrySet.add("日本");
// 查询所有元素
System.out.println("====================");
System.out.println("查询所有元素:" + countrySet);
// 修改[删除]数据
System.out.println("====================");
boolean removeResult = countrySet.remove("日本");
System.out.println("删除结果 = " + removeResult);
boolean addResult = countrySet.add("德国");
System.out.println("添加结果 = " + addResult);
System.out.println("修改后的数据:" + countrySet);
// 查询集合中元素的个数
System.out.println("====================");
System.out.println("查询集合中元素的个数:" + countrySet.size());
// 遍历Set
System.out.println("====================");
for (String country : countrySet) {
System.out.print(country + "\t");
}
}
1.4.3、HashSet vs TreeSet
? ? ? ? HashSet的底层是哈希表、TreeSet的底层是二叉树。
1.5、Map集合
1.5.1、概述
? ? ? ? 前面介绍的List、Set集合是单列集合,而Map是双列集合。
1.5.2、常见操作
/**
* Map常见操作
*/
@Test
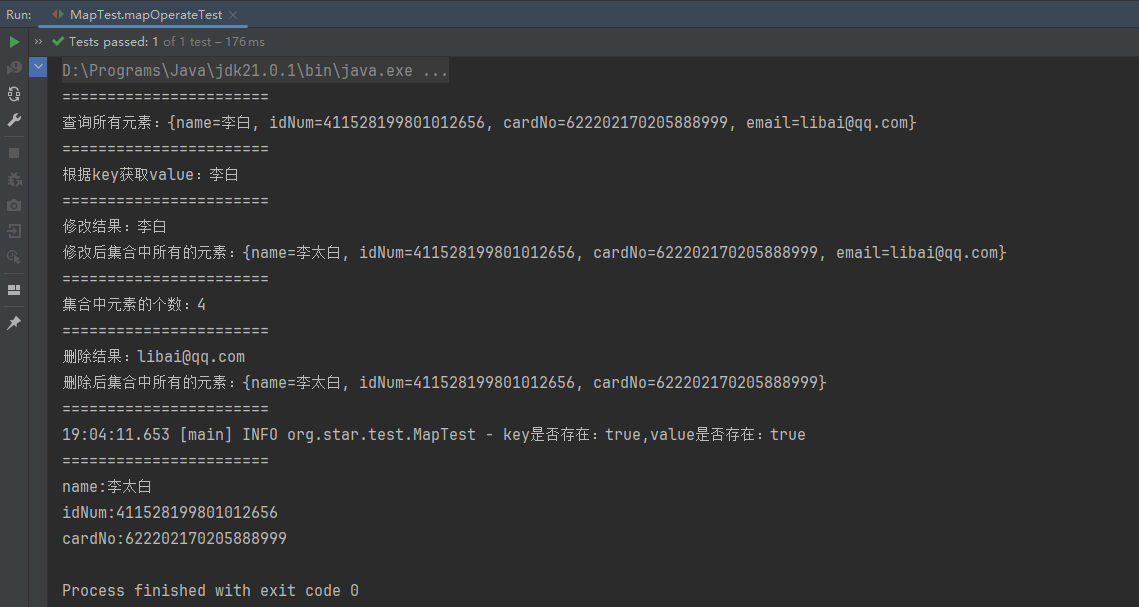
public void mapOperateTest() {
Map<String, Object> map = new HashMap<>();
// 添加元素:key-value、key必须唯一,不能重复!
map.put("name", "李白");
map.put("idNum", "411528199801012656");
map.put("cardNo", "622202170205888999");
map.put("email", "libai@qq.com");
// 查询所有元素
System.out.println("=======================");
System.out.println("查询所有元素:" + map);
// 根据key获取value
System.out.println("=======================");
Object value = map.get("name");
System.out.println("根据key获取value:" + value);
// 修改元素
System.out.println("=======================");
Object updateResult = map.put("name", "李太白");
System.out.println("修改结果:" + updateResult);
System.out.println("修改后集合中所有的元素:" + map);
// 集合中元素的个数
System.out.println("=======================");
int size = map.size();
System.out.println("集合中元素的个数:" + size);
// 删除元素
System.out.println("=======================");
Object removeResult = map.remove("email");
System.out.println("删除结果:" + removeResult);
System.out.println("删除后集合中所有的元素:" + map);
// 判断某个元素是否在集合中
System.out.println("=======================");
boolean keyExist = map.containsKey("idNum");
boolean valueExist = map.containsValue("411528199801012656");
log.info("key是否存在:{},value是否存在:{}", keyExist, valueExist);
// 遍历集合
System.out.println("=======================");
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}?
?二、集合相关的面试题
2.1、说一说Java中常见的集合
????????Java中提供了大量的集合类,主要分为两大类,即:单列集合和双列集合,下面详细介绍:
第一个是Collection 属于单列集合,第二个是Map 属于双列集合。
在Collection中有两个子接口List和Set。在我们平常开发的过程中用的比较多像list接口中的实现类ArrarList和LinkedList。 在Set接口中有实现类HashSet和TreeSet。
在map接口中有很多的实现类,平时比较常见的是HashMap、TreeMap,还有一个线程安全的map:ConcurrentHashMap
2.2、List集合是如何扩容的
2.2.1、源码(部分)
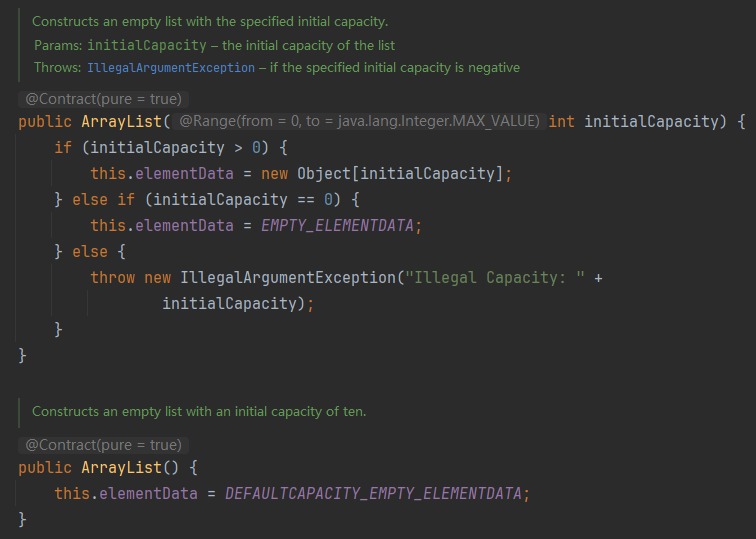
2.2.2、详解
? ? ? ??ArrayList是一个数组结构的存储容器,默认情况下数组的长度是10个,当然我们也可以在构建ArrayList对象的时候指定初始长度,那么随着程序不断的往集合中添加元素,当添加的元素达到10个的时候,ArrayList里面就没有足够的容量来存储新的元素了,那么这个时候ArrayList就会触发自动扩容,扩容的流程大致如下:
(1)创建一个新的数组,那么这个数组的长度是原来的1.5倍;
(2)使用Arrays.copyOf()方法将老的数据拷贝到新的数组里面,接着再把当前需要添加的元素添加到当前数组里面,从而完成动态扩容的一个过程;
2.3、HashMap是如何扩容的
2.3.1、源码(部分)
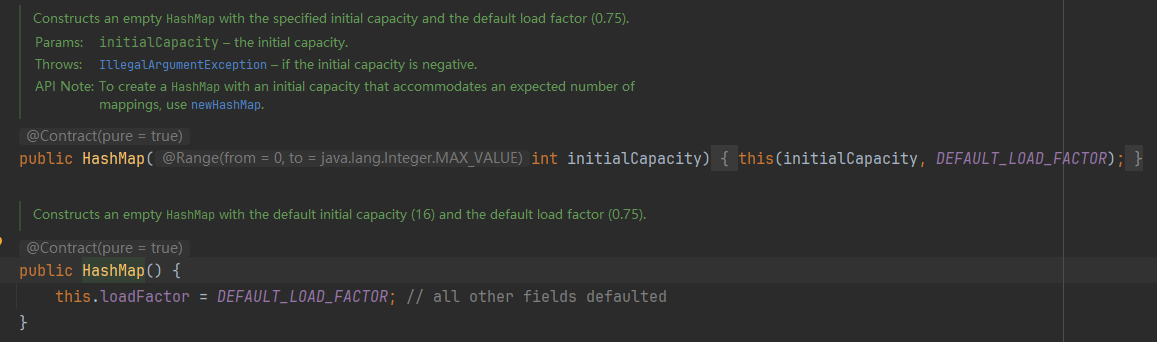
2.3.2、详解
? ? ? ? 当我们在创建一个集合对象的时候,实际上就是在内存里面一次性申请了一块内存空间,而这个内存空间的大小是在创建集合对象的时候指定的,对于Map集合而言,默认的初始大小为16,在实际开发中,随着不断的往集合中添加元素,会导致集合的容量不够,这个时候就会触发集合的自动扩容,那么具体是怎么扩容的呢?当集合中的元素达到某个阈值的时候,Map集合就会进行动态扩容,阈值的计算公式为:16 * 0.75 = 12,即默认情况下,当Map集合中的元素达到12的时候,将会触发Map容器的自动扩容机制,从而更好的满足存储更多数据的需求,也即当Map中元素的个数达到12的时候,将会触发第一次扩容,扩容后容器的容量变为原来的2倍,即32;第二次扩容的临界值为:32 * 0.75 = 24,即当Map集合中元素的个数达到24的时候,将会触发第二次扩容;其他依次类推...
????????所以,当我们在创建集合对象的时候,要充分考虑集合中所存储元素的个数,防止容器频繁的扩容,影响系统的性能。
2.3.3、为什么扩容因子是0.75
? ? ? ? 扩容因子表示hash表中元素的填充程度,扩容因子的值越大,那么就意味着触发扩容元素的个数会更多,虽然它的整体空间利用率比较高,但是hash冲突的概率也会随之增加,反过来说扩容因子的值越小,那么触发扩容元素的个数也就越小,hash冲突的概率也越小,但是对于内存空间的浪费就比较多了,而且还会增加扩容的频率,影响系统的性能,因此扩容因子值的设置,不宜过大也不宜过小。0.75这个值的来源和统计学里面的【泊松分布】有关系,HashMap里面是采用链式寻址的方式去解决hash冲突的,而为了避免链表过长带来的一个时间复杂度增加的情况,所以当链表的长度大于等于7的时候就会转化成红黑树,从而提升检索的效率,当扩容因子在0.75的时候,链表长度达到8的可能性几乎为0,也就是说负载因子设置为0.75比较好的达到了空间成本和时间成本的一个平衡。
2.4、HashSet是如何保证元素不重复的
2.4.1、概述
? ? ? ? 前面的内容介绍了HashSet,它和其他单列集合一个显著的区别就是元素不重复,那么它是如何实现元素不重复的呢?
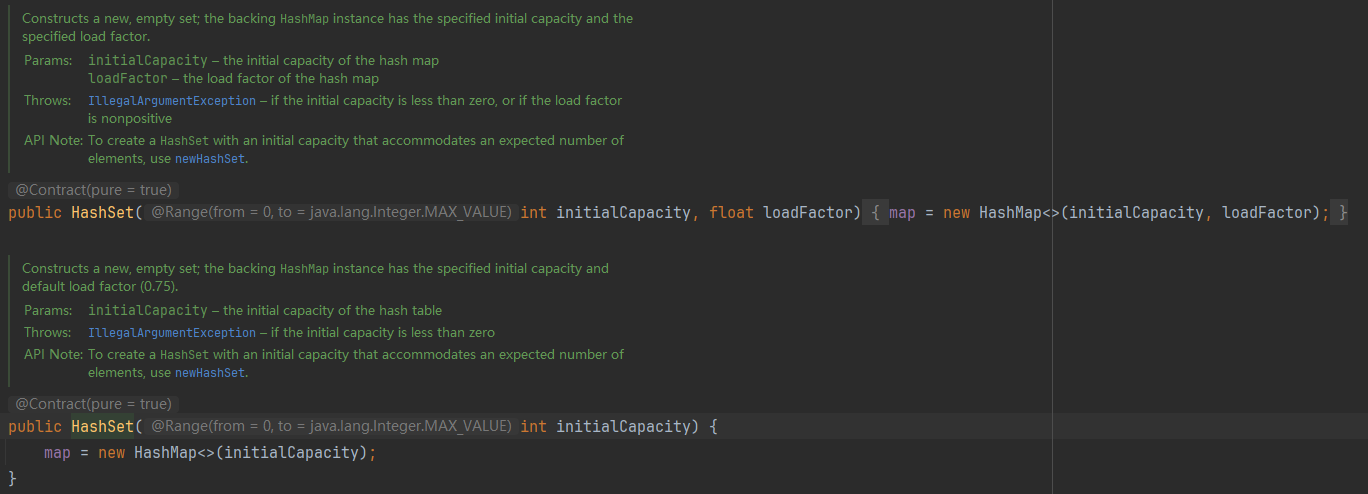
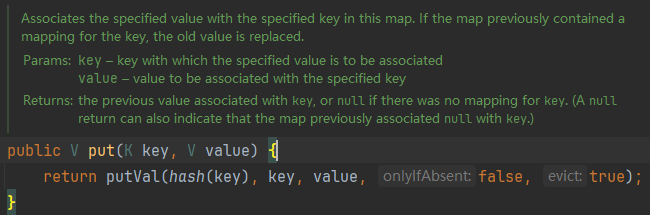
2.4.2、源码(部分)
构造方法:
add方法:
?
?
? ? ? ?
?

2.4.3、分析
? ? ? ? 从源码可以看出,HashSet的内部其实是利用了HashMap来实现的,内部持有一个HashMap的引用,操作HashSet实际上底层是操作这个map,HashMap的key是唯一的,从上面的源码可以看出HashSet添加进去的值其实是作为HashMap的key,所以HashSet中的元素不会重复。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript 中 callee 与 caller 的作用
- 【计算机组成原理】总结篇
- gcc扩展选项__attribute__((interrupt))——指定中断处理函数属性
- Vue3选项式API和组合式API详解
- 机器学习 -- 朴素贝叶斯分类器
- [音视频 ffmpeg] 复用推流
- AWVS/Acunetix Premium v24.1.24高级版漏洞扫描器
- 3.2 MAPPING THREADS TO MULTIDIMENSIONAL DATA
- CMake入门教程【高级篇】qmake转cmake
- Linux环境配置