图神经网络X项目|基于图神经网络的电商行为的预测(5%)
发布时间:2024年01月22日
文章目录
Jupyter Notebook 学习人工智能的好帮手
数据集
数据集下载
数据集调用
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv("yoochoose-clicks.dat",header=None)
df.columns = ['session_id','timestamp','item_id','category']
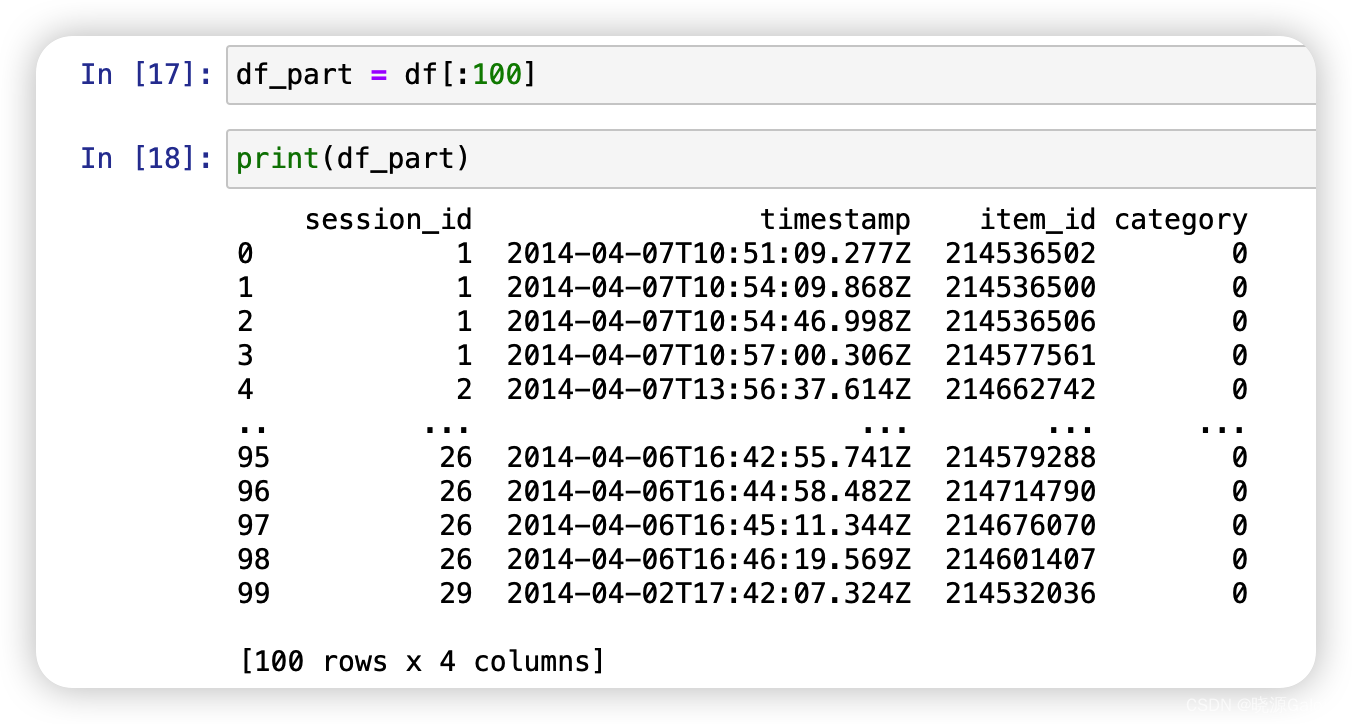
print(df)
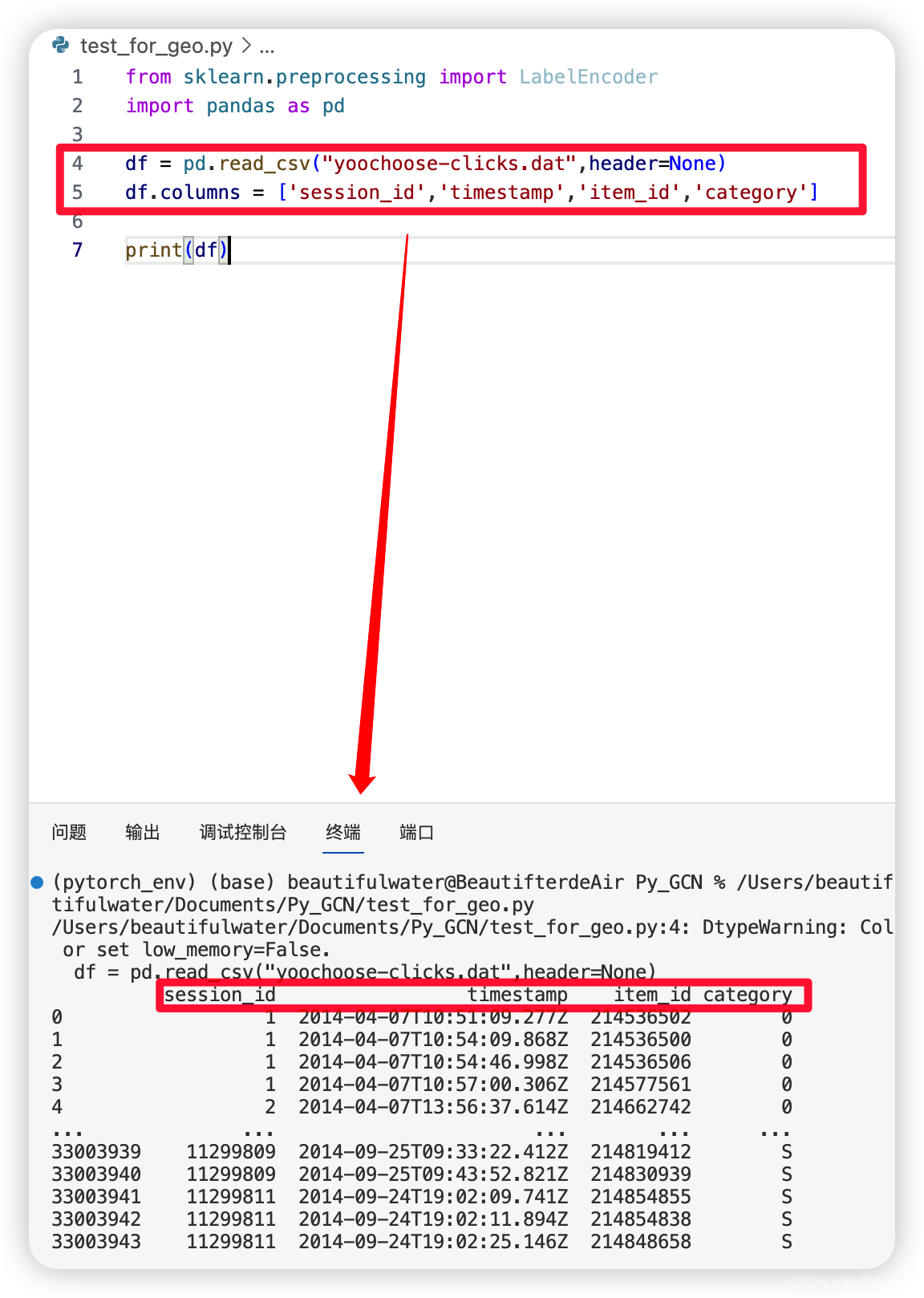
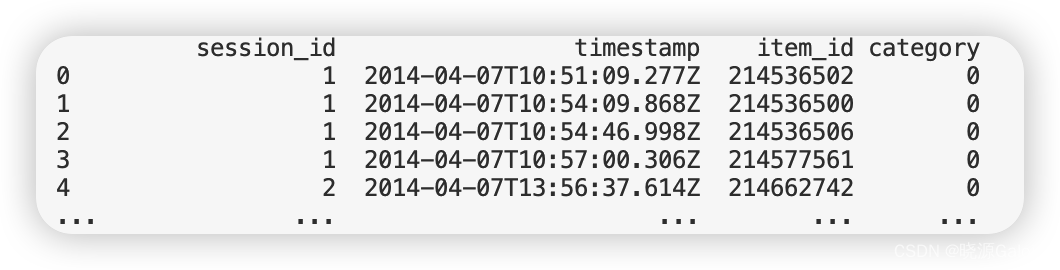
其中,session_id表示的是某次会话的编号,而item_id表示的是某次会话下的某个操作,category代表购买情况,其中0代表未购入,1代表购入。
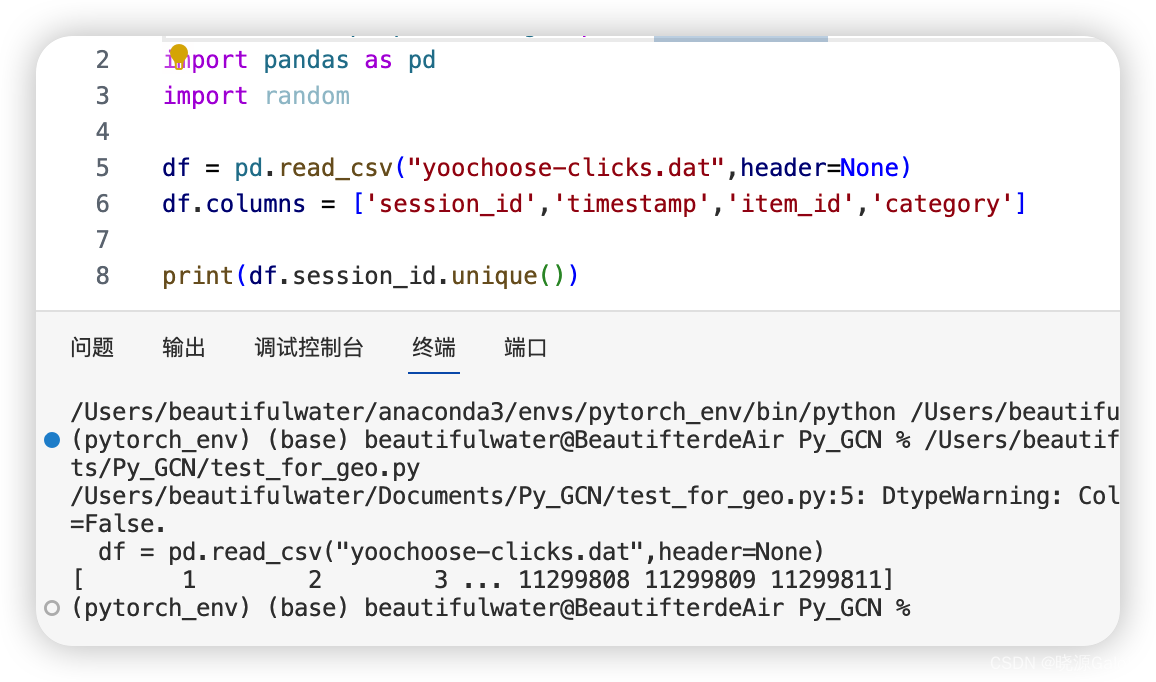
数据集应用技巧——获取不重复的编号
可以对某一个关键字采用unique()。
数据集应用技巧——随机采样
应用场景:数据集过多,抽取部分数据进行观察。
工具:采用random中的choice进行提取(numpy库也有random包,也有choice方法)。
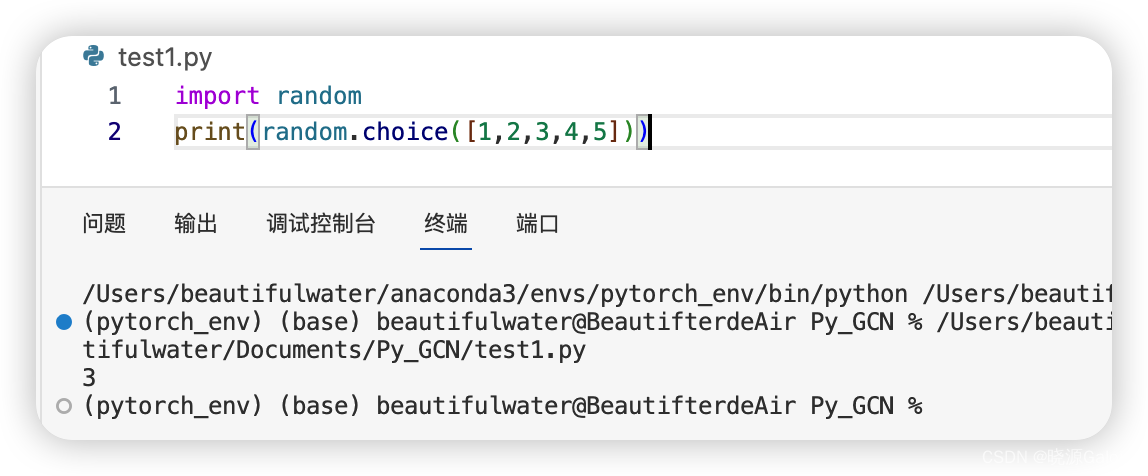
choice可以选取出列表/集合中的其中一项
数据集应用技巧——抽取前N项进行模拟测试
应用场景:可用于熟悉操作。
工具:使用分片进行操作。
分片的具体操作可见于分片链接
数据集构建

第二步,刚开始这些点并没有图的编号(有session_id,但并不是一个方便建图的编号),于是可以采取按某一个关键字进行排序的方法,按大小给图上的节点进行重新编号。

后几步,开始制作边集。
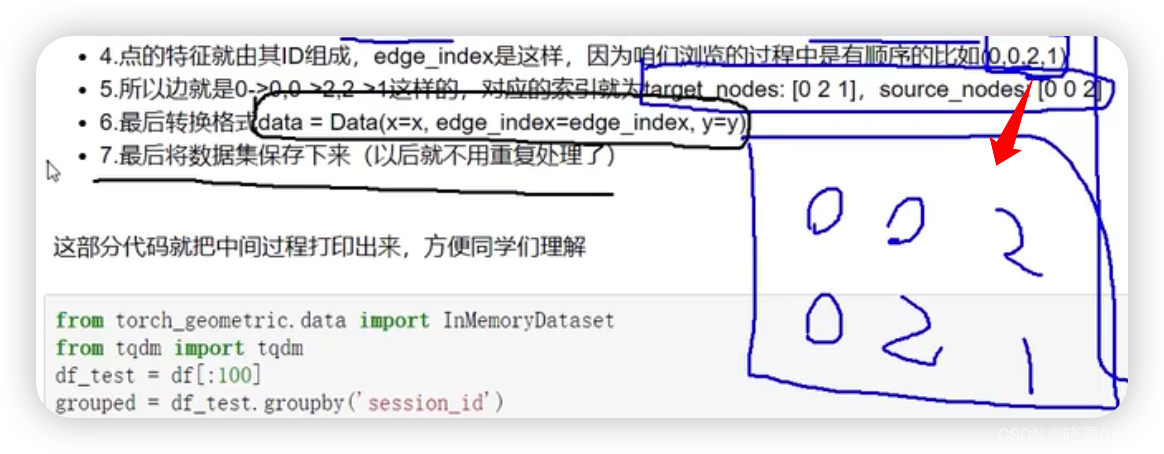
考虑复用性的话,记得将构造出来的数据集进行保存。
技巧一——查看数据集构建进度
应用场景:可以可视化进度
文章来源:https://blog.csdn.net/Fangyechy/article/details/135749841
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python - Bert-VITS2 语音推理服务部署
- 【PTA】L1-050 倒数第N个字符串——MZH
- 哪种猫粮比较好?超能打的5款主食冻干测评
- 制造企业如何打破“信息孤岛”,跑赢从制造到“智造”的破局之路?
- 原型与原型链
- 算法复习笔记
- 得实云打印助力CRM和电商平台高效无代码集成
- 华为机试真题实战应用【算法代码篇】-垃圾信息拦截(附C++和JAVA代码实现)
- 瑞金冈面乡陈坑村:打米果 迎新年
- 搬运5款知名度不高,但十分好用的软件