Java 并发编程中的无锁实现
5 并发编程中的无锁实现
CAS 与 voltaile
public class d1_AccountCAS implements Account{
private AtomicInteger balance;
public d1_AccountCAS(Integer balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return balance.get();
}
@Override
public void withdraw(Integer amount) {
while (true) {
// 原先值
int prev = balance.get();
// 当前值
int next = prev - amount;
// 比较并修改
if (balance.compareAndSet(prev, next)) {
break;
}
}
// 可以简化为下面的方法
// balance.addAndGet(-1 * amount);
}
public static void main(String[] args) {
Account.demo(new d1_AccountCAS(10000));
}
}
interface Account {
// 获取余额
Integer getBalance();
// 取款
void withdraw(Integer amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(Account account) {
List<Thread> ts = new ArrayList<>();
long start = System.nanoTime();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(10);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance()
+ " cost: " + (end-start)/1000_000 + " ms");
}
}
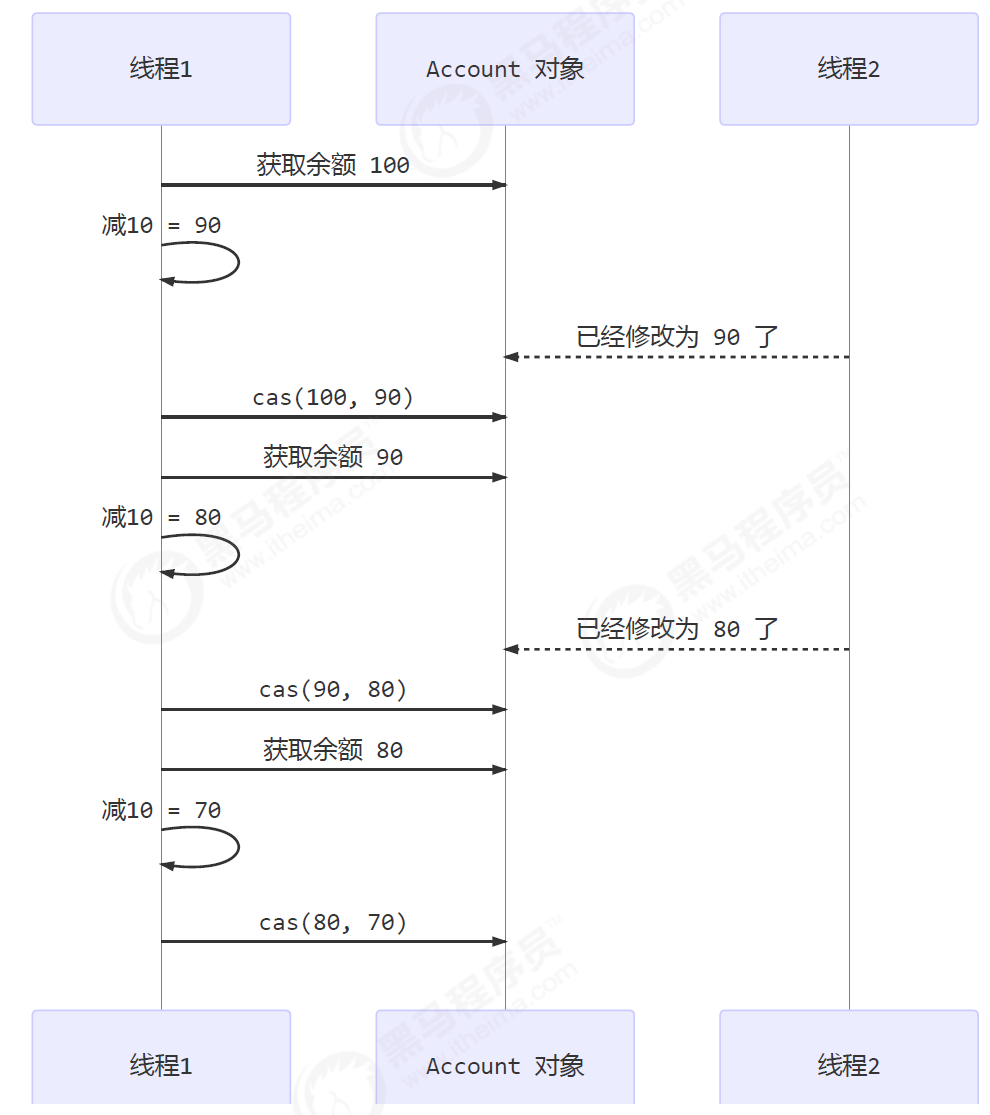
compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
- 其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
- 在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
CAS 的特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下
-
CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
-
synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
-
CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
-
因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
-
但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
-
原子整数
Atomic 系列类型也可以不用锁保证线程安全
J.U.C 并发包提供了:
-
AtomicBoolean
-
AtomicInteger
-
AtomicLong
以 AtomicInteger 为例
/**
* get 在前获取的计算前的结果
* get 在后获取的计算后的结果
*/
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++
System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i
System.out.println(i.incrementAndGet());
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i
System.out.println(i.decrementAndGet());
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i--
System.out.println(i.getAndDecrement());
// 获取并加值(i = 0, 结果 i = 5, 返回 0)
System.out.println(i.getAndAdd(5));
// 加值并获取(i = 5, 结果 i = 0, 返回 0)
System.out.println(i.addAndGet(-5));
// 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
// lambda 里面可以做任何操作,例如加减乘除等待。。
System.out.println(i.getAndUpdate(p -> p - 2));
// 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.updateAndGet(p -> p + 2));
// 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
// getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
原子引用
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference
class DecimalAccountSafeCas implements DecimalAccount {
AtomicReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return ref.get();
}
@Override
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal prev = ref.get();
BigDecimal next = prev.subtract(amount);
if (ref.compareAndSet(prev, next)) {
break;
}
}
}
}
ABA 问题及解决
compareAndSet (CAS) 仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
AtomicStampedReference
AtomicStampedReference 对象需要提供引用类型,和初始版本号
每次进行更改的时候还需要传入 原始版本号 和 新版本号(这里是原始版本号+1)
@Slf4j(topic = "c.d2_ABA")
public class d2_ABA {
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
String prev = ref.getReference();
int stamp = ref.getStamp(); // 获取版本号
log.debug("stamp: {}", stamp);
other();
Thread.sleep(1000);
log.debug("stamp: {}", stamp);
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp+1));
}
private static void other() throws InterruptedException {
new Thread(()->{
int stamp = ref.getStamp();
log.debug("stamp: {}", stamp);
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B", stamp, stamp + 1));
}, "t1").start();
Thread.sleep(500);
new Thread(()->{
int stamp = ref.getStamp();
log.debug("stamp: {}", stamp);
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A", stamp, stamp + 1));
}, "t2").start();
}
}
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A ->C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
AtomicMarkableReference
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference
初始需要指定初始值,还需要提供标记的类型
// 初始化:
AtomicMarkableReference<data_type> ref = new AtomicMarkableReference<>(init_value, true);
// 更改:需要指定之前的状态和更改状态
ref.compareAndSet(prev_value, next_value, true, false)
原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
有时候我们不是单纯的想修改一个数,而是修改一个数组里面的值
public class d3_AtomicArray {
/**
参数1,提供数组、可以是线程不安全数组或线程安全数组
参数2,获取数组长度的方法
参数3,自增方法,回传 array, index
参数4,打印数组的方法
*/
// supplier 提供者 无中生有 ()->结果
// function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果
// consumer 消费者 一个参数没结果 (参数)->void, BiConsumer (参数1,参数2)->
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer ) {
List<Thread> ts = new ArrayList<>();
T array = arraySupplier.get();
int length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每个线程对数组作 10000 次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j%length);
}
}));
}
ts.forEach(t -> t.start()); // 启动所有线程
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); // 等所有线程结束
printConsumer.accept(array);
}
public static void main(String[] args) {
demo(
()->new int[10],
array-> array.length,
(array, index) -> array[index]++,
array-> System.out.println(Arrays.toString(array))
);
// 原子数组的使用
demo(
() -> new AtomicIntegerArray(10),
array -> array.length(),
(array, index) -> array.getAndIncrement(index),
array-> System.out.println(array)
);
// 输出
/**
* [6290, 6313, 6296, 6271, 6231, 6298, 6289, 6272, 6295, 6330]
* [10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
*/
}
}
字段更新器
- AtomicReferenceFieldUpdater // 域 字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
用于保护类中的成员变量
public class d4_AtomicField {
public static void main(String[] args) {
Student student = new Student();
AtomicReferenceFieldUpdater updater = AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
boolean flag = updater.compareAndSet(student, null, "rainsun");
System.out.println(flag);
System.out.println(student);
// true
// Student{name='rainsun'}
}
}
class Student{
volatile String name;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
原子累加器
public class d5_AtomicAdder {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
demo(() -> new LongAdder(), adder -> adder.increment());
}
for (int i = 0; i < 5; i++) {
demo(() -> new AtomicLong(), adder -> adder.getAndIncrement());
}
}
private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
long start = System.nanoTime();
List<Thread> ts = new ArrayList<>();
// 4 个线程,每人累加 50 万
for (int i = 0; i < 40; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start)/1000_000);
}
}
比较 AtomicLong 与 LongAdder:LongAdder花费的时间短很多
20000000 cost:65
20000000 cost:14
20000000 cost:15
20000000 cost:36
20000000 cost:15
20000000 cost:373
20000000 cost:356
20000000 cost:295
20000000 cost:390
20000000 cost:404
性能提升的原因:在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。
这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
LongAdder原理
LongAdder 类有几个关键域:
// 累加单元数组, 懒惰初始化
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域
transient volatile long base;
// 在 cells 创建或扩容时, 置为 1, 表示加锁
transient volatile int cellsBusy;
LongAdder 的 Cell 累加单元实现:
// 防止缓存行伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}
缓存行伪共享
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
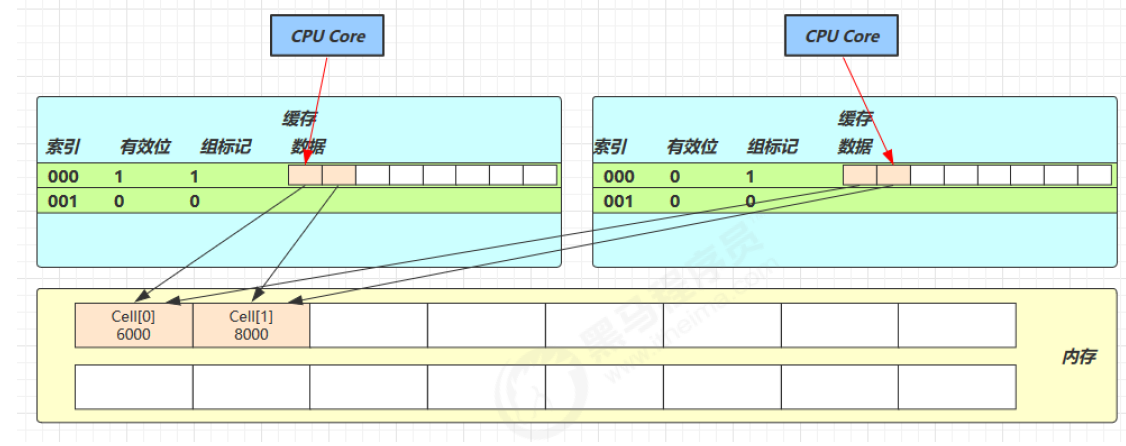
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0 要修改 Cell[0]
Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python设置PyCharm的模板在创建新Python文件时自动插入预定义的代码,包括作者的注释。
- MR实战:网址去重
- linux环境下从一个服务器复制文件到另一个服务器
- YOLOv8训练自己的数据集
- 毛戈平公司上市终止:产品依赖代工,研发投入低,毛戈平夫妇套现
- 基于ssm的《数据库系统原理》课程平台的设计与实现论文
- 宝塔面板部署MySQL并结合内网穿透实现公网远程访问本地数据库
- 《volatile使用与学习总结:2023-12-17》多层面分析学习java关键字--volatile
- 代码随想录算法训练营第三十五天| 860.柠檬水找零、406.根据身高重建队列、452.用最少数量的箭引爆气球
- 基于Java SSM框架实现新闻推送系统项目【项目源码】计算机毕业设计