【书生·浦语】大模型实战营——第六次作业
发布时间:2024年01月23日
使用OpenCompass 评测 InterLM2-chat-chat-7B 模型在C-Eval数据集上的性能
环境配置
1. 创建虚拟环境
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base
source activate opencompass
git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
2. 数据集准备
# 解压评测数据集到 data/ 处
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
3. 查看支持的数据集和模型
# 列出所有跟 internlm 及 ceval 相关的配置
python tools/list_configs.py internlm ceval测试
? ? ? ? 评测不同的模型主要是设置正确的参数。可以通过命令行的形式一个一个指定,也可以通过config文件实现。本文选择了config文件的形式,首先创建configs/eval_internlm2_chat.py:
from mmengine.config import read_base
from opencompass.models import HuggingFaceCausalLM
from opencompass.partitioners import NaivePartitioner
from opencompass.runners import LocalRunner
from opencompass.tasks import OpenICLEvalTask, OpenICLInferTask
with read_base():
# choose a list of datasets
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
datasets = [*ceval_datasets]
_meta_template = dict(
round=[
dict(role='HUMAN', begin='[UNUSED_TOKEN_146]user\n', end='[UNUSED_TOKEN_145]\n'),
dict(role='SYSTEM', begin='[UNUSED_TOKEN_146]system\n', end='[UNUSED_TOKEN_145]\n'),
dict(role='BOT', begin='[UNUSED_TOKEN_146]assistant\n', end='[UNUSED_TOKEN_145]\n', generate=True),
],
eos_token_id=92542
)
models = [
dict(
type=HuggingFaceCausalLM,
abbr='internlm2-chat-7b',
path="/share/model_repos/internlm2-chat-7b",
tokenizer_path='/share/model_repos/internlm2-chat-7b',
model_kwargs=dict(
trust_remote_code=True,
device_map='auto',
),
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
trust_remote_code=True,
),
max_out_len=100,
max_seq_len=2048,
batch_size=128,
meta_template=_meta_template,
run_cfg=dict(num_gpus=1, num_procs=1),
end_str='[UNUSED_TOKEN_145]',
)
]
infer = dict(
partitioner=dict(type=NaivePartitioner),
runner=dict(
type=LocalRunner,
max_num_workers=2,
task=dict(type=OpenICLInferTask)),
)
eval = dict(
partitioner=dict(type=NaivePartitioner),
runner=dict(
type=LocalRunner,
max_num_workers=2,
task=dict(type=OpenICLEvalTask)),
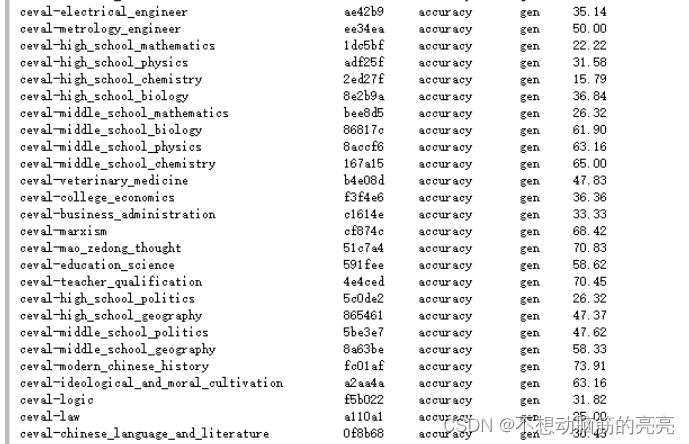
)测试结果:


部分结果:
文章来源:https://blog.csdn.net/wudongliang971012/article/details/135756496
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 1.8 day6 IO进程线程
- UEC++ 捡电池初级案例 day16
- yolov8 瑞芯微 RKNN 的 C++部署,部署工程难度小、模型推理速度快
- vue3自定义按钮点击变颜色实现(多选功能)
- 自学(网络安全)黑客——高效学习2024
- burpsuite的安装与介绍
- YOLOv5改进 | 2023注意力篇 | MSDA多尺度空洞注意力(附多位置添加教程)
- 万能代码!
- LeetCode刷题--- 二叉搜索树中第K小的元素
- Godot游戏引擎有啥优势