JVM:常见的面试题和答案
1. 什么是JVM?
答案: Java虚拟机(JVM)是Java平台的一部分,是一个虚拟计算机,负责在运行时执行Java字节码。它提供了Java程序运行的环境,包括内存管理、垃圾回收、即时编译等功能,使得Java程序可以在不同的平台上实现一次编写,到处运行的特性。
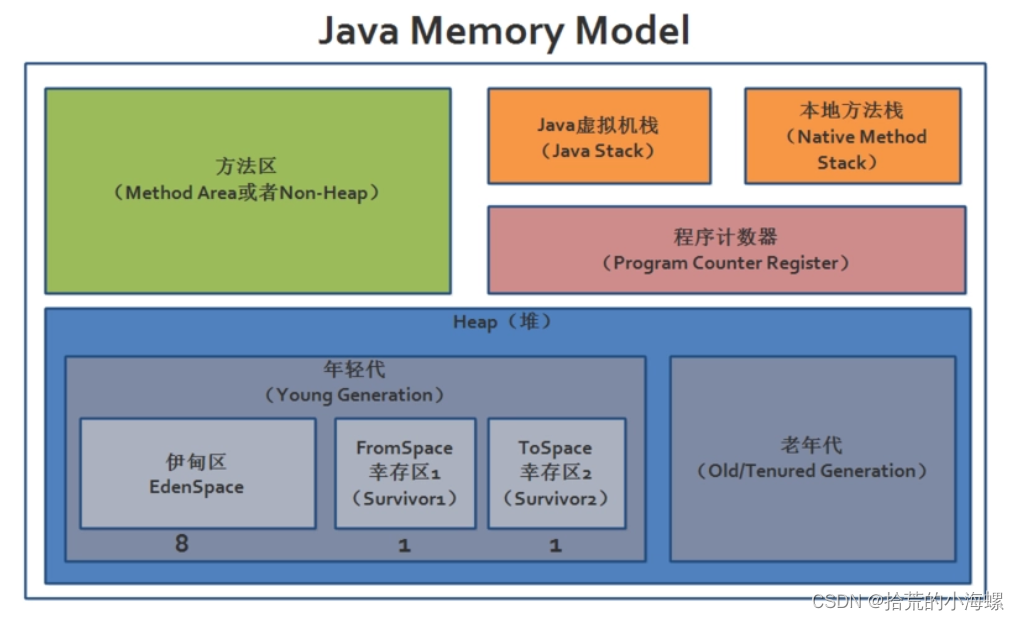
- 程序计数器(Program Counter Register):当前线程所执行的字节码的行号指示器,字节码解析器的工作是通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成;
- Java 虚拟机栈(Java Virtual Machine Stacks):用于存储局部变量表、操作数栈、动态链接、方法出口等信息;
- 本地方法栈(Native Method Stack):与虚拟机栈的作用是一样的,只不过虚拟机栈是服务 Java 方法的,而本地方法栈是为虚拟机调用 Native 方法服务的;
- Java 堆(Java Heap):Java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存;
- 方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
2. Java内存模型(JMM)是什么?
答案: Java内存模型是一种规范,定义了Java虚拟机如何协调多线程访问共享内存的规则。它确保线程之间的可见性、有序性和一致性。JMM包括主内存和每个线程的工作内存,通过内存屏障和同步操作来协调线程之间的交互。这是为了保证在多线程环境中程序的正确性。
3. 什么是垃圾回收?Java中有哪些垃圾回收算法?
答案: 垃圾回收是指自动识别和释放不再被程序使用的内存的过程。在Java中,垃圾回收器负责管理和清理不再被引用的对象。常见的垃圾回收算法有以下几点:
- 标记-清除算法(Mark and Sweep): 首先标记不再使用的对象,然后清除(删除)它们。
- 复制算法(Copying): 将存活的对象复制到新的内存区域,然后清除旧区域。
- 标记-整理算法(Mark and Compact): 首先标记不再使用的对象,然后将存活的对象移到一侧,并清除未使用的内存。
- 分代算法(Generational): 将内存划分为不同的代,年轻代和老年代,根据对象的生命周期分别采用不同的垃圾回收算法
4. 什么是Java堆和栈?
答案: Java堆是Java虚拟机管理的最大一块内存区域,用于存储对象实例。栈则是每个线程私有的,用于存储局部变量和方法调用信息。主要区别在于,堆是用于存储对象的动态分配内存区域,而栈是用于存储基本数据类型和对象引用的内存区域。堆的内存空间由垃圾回收器负责管理,而栈的内存空间由线程自动管理。
5. 什么是类加载器?Java中有哪些类加载器?
答案: 类加载器是Java虚拟机的一部分,负责将类的字节码加载到内存中,并转换成Java对象。常见的类加载器有启动类加载器(Bootstrap ClassLoader)、扩展类加载器(Extension ClassLoader)、应用程序类加载器(Application ClassLoader)和自定义类加载器。这些类加载器形成了层次结构,按照双亲委派模型,父类加载器负责委托给子类加载器进行类加载。
6. 垃圾回收的目的是什么?
答:垃圾回收的主要目的是:
- 释放不再被引用的内存对象,以避免内存泄漏。
- 提高内存资源的有效利用,减少内存碎片化。
- 减少程序员手动管理内存的工作,提高开发效率。
- 增加应用程序的稳定性和可靠性,减少内存相关的错误
7. 队列和栈是什么?有什么区别?
- 队列和栈都是被用来预存储数据的。
- 队列允许先进先出检索元素,但也有例外的情况,Deque 接口允许从两端检索元素。
- 栈和队列很相似,但它运行对元素进行后进先出进行检索
8. Java中都有哪些引用类型?
- 强引用:发生 gc 的时候不会被回收。
- 软引用:有用但不是必须的对象,在发生内存溢出之前会被回收。
- 弱引用:有用但不是必须的对象,在下一次GC时会被回收。
- 虚引用(幽灵引用/幻影引用):无法通过虚引用获得对象,用 PhantomReference 实现虚引用,虚引用的用途是在 gc 时返回一个通知。
9. Java11的默认垃圾收集器是什么?
答:Java9之后,官方JDK默认使用的垃圾收集器是G1。
10. 常见的垃圾收集器有哪些?
常见的垃圾收集器包括:
- 串行垃圾收集器:‐XX:+UseSerialGC
- 并行垃圾收集器:‐XX:+UseParallelGC
- CMS垃圾收集器:‐XX:+UseConcMarkSweepG
- G1垃圾收集器:‐XX:+UseG1GC
11. 说一下类装载的执行过程?
类装载分为以下 5 个步骤:
- 加载:根据查找路径找到相应的 class 文件然后导入;
- 检查:检查加载的 class 文件的正确性;
- 准备:给类中的静态变量分配内存空间;
- 解析:虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用就理解为一个标示,而在直接引用直接指向内存中的地址;
- 初始化:对静态变量和静态代码块执行初始化工作。
12. JVM 调优的工具有哪些?
答:
常用调优工具分为两类,jdk自带监控工具:jconsole和jvisualvm,第三方有:MAT(Memory AnalyzerTool)、GChisto。
- jconsole:Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存, 线程和类等的监控
- jvisualvm:jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。
- MAT:Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Javaheap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
- GChisto:一款专业分析gc日志的工具
13. 堆和栈的有什么区别
答:栈是运行时单位,代表着逻辑,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;堆是存储单位,代表着数据,可被多个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续,会有碎片。
- 功能不同
栈内存用来存储局部变量和方法调用,而堆内存用来存储Java中的对象。无论是成员变量,局部变量, 还是类变量,它们指向的对象都存储在堆内存中。 - 共享性不同
栈内存是线程私有的。
堆内存是所有线程共有的。 - 异常错误不同
如果栈内存或者堆内存不足都会抛出异常。
栈空间不足:java.lang.StackOverFlowError。堆空间不足:java.lang.OutOfMemoryError。 - 空间大小
栈的空间大小远远小于堆的
14. JDK常用的调优命令有哪些?
答Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo
- jps:JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat:JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap:JVM Memory Map命令用于生成heap dump文件
- jhat:JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看
- jstack:用于生成java虚拟机当前时刻的线程快照。
- jinfo:JVM Con?guration info 这个命令作用是实时查看和调整虚拟机运行参数
15. Minor GC与Full GC分别在什么时候发生?
答:新生代内存不够用时候发生MGC也叫YGC,JVM内存不够的时候发生FGC
16. JVM选项-XX:+UseCompressedOops有什么作用? 为什么要使用?
答:当你将你的应用从 32 位的 JVM 迁移到 64 位的 JVM 时,由于对象的指针从 32 位增加到了 64 位,因此堆内存会突然增加,差不多要翻倍。这也会对 CPU 缓存(容量比内存小很多)的数据产生不利的影响。因为,迁移到 64 位的 JVM 主要动机在于可以指定最大堆大小,通过压缩 OOP 可以节省一定的内存。通过 -XX:+UseCompressedOops 选项,JVM 会使用 32 位的 OOP,而不是 64 位 的 OOP。
17. 什么是双亲委派模型?
答:在介绍双亲委派模型之前先说下类加载器。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立在 JVM 中的唯一性,每一个类加载器,都有一个独立的类名称空间。类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象。
类加载器分类:
-
启动类加载器(Bootstrap ClassLoader),是虚拟机自身的一部分,用来加载Java_HOME/lib/目录中的,或者被 -Xbootclasspath 参数所指定的路径中并且被虚拟机识别的类库;
-
其他类加载器:
-
扩展类加载器(Extension ClassLoader):负责加载\lib\ext目录或Java. ext. dirs系统变量指定的路径中的所有类库;
-
应用程序类加载器(Application ClassLoader)。负责加载用户类路径(classpath)上的指定类库,我们可以直接使用这个类加载器。一般情况,如果我们没有自定义类加载器默认就是用这个加载器。
双亲委派模型:如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类。
18. JVM性能调优的目标是什么?
答:JVM性能调优的主要目标包括:
- 提高应用程序的响应性能。
- 最小化垃圾回收的停顿时间。
- 减少内存占用,避免内存泄漏。
- 最大程度地利用硬件资源,提高吞吐量。
- 优化应用程序的整体性能和稳定性。
19. 如何选择适合应用程序的垃圾回收器?
答:选择垃圾回收器应考虑以下因素:
- 应用程序的性能需求:低停顿时间、高吞吐量等。
- 堆内存大小:小堆和大堆需要不同的回收器。
- 硬件资源:多核CPU、内存大小等。
- Java版本和JVM实现:不同版本和实现支持不同的回收器。
- 应用程序的特性:长时间运行、短时间运行、大对象等。
- 通常,可以开始使用默认的垃圾回收器,然后根据性能需求进行调优和选择。
20. 如何调整堆大小以优化性能?
答:可以使用-Xmx和-Xms标志来调整堆大小。其中:
- -Xmx用于设置堆的最大大小,例如-Xmx2g表示将堆的最大大小设置为2GB。
- -Xms用于设置堆的初始大小,例如-Xms512m表示将堆的初始大小设置为512MB。
调整堆大小的目标是确保堆足够大,以容纳应用程序的内存需求,同时避免浪费过多内存。
21. 请描述G1(Garbage-First) GC的工作原理。
答:G1 GC是一种面向大堆内存的垃圾回收器,其工作原理包括以下步骤:
- 首先,它将堆划分为多个区域,包括伊甸园区、幸存者区、老年代等。
- 然后,它会并发地标记不再使用的对象。
- 接着,它会根据各个区域的垃圾量优先回收垃圾。这个过程通常不会导致大的停顿。
- 最后,它会进行一次小的"Stop-the-World"事件,以处理剩余的垃圾。
22. 32 位 JVM 和 64 位 JVM 的最大堆内存分别是多数?
答:理论上说上 32 位的 JVM 堆内存可以到达 2^32, 即 4GB,但实际上会比这个小很多。不同操作系统之间不同,如 Windows 系统大约 1.5GB,Solaris 大约3GB。64 位 JVM 允许指定最大的堆内存,理论上可以达到 2^64,这是一个非常大的数字,实际上你可以指定堆内存大小到 100GB。甚至有的 JVM,如 Azul,堆内存到 1000G 都是可能的。
23. JRE、JDK、JVM 及 JIT 之间有什么不同?
-
JRE 代表 Java 运行时(Java run-time),是运行 Java 引用所必须的。
-
JDK 代表 Java 开发工具(Java development kit),是 Java 程序的开发工具,如 Java编译器,它也包含 JRE。
-
JVM 代表 Java 虚拟机(Java virtual machine),它的责任是运行 Java 应用。
-
JIT 代表即时编译(Just In Time compilation),当代码执行的次数超过一定的阈值时,会将 Java 字节码转换为本地代码,如,主要的热点代码会被准换为本地代码,这样有利大幅度提高 Java 应用的性能。
24. 常用的JVM启动参数有哪些?
答:截止目前(2020年3月),JVM可配置参数已经达到1000多个,其中GC和内存配置相关的JVM参数就有600多个。但在绝大部分业务场景下,常用的JVM配置参数也就10来个。
例如:
# JVM启动参数不换行
# 设置堆内存
‐Xmx4g ‐Xms4g
# 指定GC算法
‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50
# 指定GC并行线程数
‐XX:ParallelGCThreads=4
# 打印GC日志
‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps
# 指定GC日志文件
‐Xloggc:gc.log
# 指定Meta区的最大值
‐XX:MaxMetaspaceSize=2g
# 设置单个线程栈的大小
‐Xss1m
# 指定堆内存溢出时自动进行Dump
‐XX:+HeapDumpOnOutOfMemoryError
‐XX:HeapDumpPath=/usr/local/
此外,还有一些常用的属性配置:
# 指定默认的连接超时时间
‐Dsun.net.client.defaultConnectTimeout=2000
‐Dsun.net.client.defaultReadTimeout=2000
# 指定时区
‐Duser.timezone=GMT+08
# 设置默认的文件编码为UTF‐8
‐Dfile.encoding=UTF‐8
# 指定随机数熵源(Entropy Source)
‐Djava.security.egd=file:/dev/./urandom
25. 设置堆内存XMX应该考虑哪些因素?
答:需要根据系统的配置来确定,要给操作系统和JVM本身留下一定的剩余空间。推荐配置系统或容器里可用内存的 70-80% 最好。
比如说系统有 8G 物理内存,系统自己可能会用掉一点,大概还有 7.5G 可以用,那么建议配置‐Xmx6g
说明:7.5G*0.8 = 6G,如果知道系统里有明确使用堆外内存的地方,还需要进一步降低这个值。
26. 怎样开启GC日志?
答:一般来说,JDK8及以下版本通过以下参数来开启GC日志:
‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps ‐Xloggc:
如果是在JDK9及以上的版本,则格式略有不同
‐Xlog:gc*=info:file=gc.log:time:filecount=0
27. 请指定使用G1垃圾收集器来启动HelloWorld程序
java ‐XX:+UseG1GC
‐Xms4g
‐Xmx4g
‐Xloggc:gc.log
‐XX:+PrintGCDetails
‐XX:+PrintGCDateStamps HelloWorld
28. 什么是内存溢出错误(OutOfMemoryError)?有哪些常见的内存溢出错误类型?
答:内存溢出错误(OutOfMemoryError)是一种Java程序运行时错误,表示程序试图分配更多内存,但没有足够的内存可供使用。内存溢出错误是由于程序中创建的对象太多,而Java虚拟机(JVM)的堆内存不足以容纳这些对象而引起的。常见的内存溢出错误类型包括:
- java.lang.OutOfMemoryError: Java heap space:表示堆内存溢出。
- java.lang.OutOfMemoryError: PermGen space(在旧版本的JVM中):表示永久代内存溢出。
- java.lang.OutOfMemoryError: Metaspace(在新版本的JVM中):表示元空间内存溢出。
- java.lang.OutOfMemoryError: GC overhead limit exceeded:表示垃圾回收开销过大。
29. 如何分析线程转储(Thread Dump)?
答:分析线程转储(Thread Dump)是诊断多线程应用程序问题的关键步骤之一。以下是一般的线程转储分析步骤:获取线程转储:在应用程序运行时,可以使用工具(如jstack命令,VisualVM等)来生成线程转储。通常,您可以通过以下方式获取线程转储:
-
使用jstack命令:运行jstack ,其中是目标Java进程的进程ID。
-
使用监控工具:如果您使用监控工具(如VisualVM、JConsole等),通常可以通过工具界面生成线程转储。
在发生问题时生成线程转储:如果应用程序出现性能问题或死锁,您可以使用操作系统工具来生成线程转储,例如在Unix/Linux系统上可以使用kill -3 命令。 -
查看线程状态:打开生成的线程转储文件(通常是文本文件),查看线程列表。了解每个线程的状态,例如RUNNABLE(运行中)、WAITING(等待中)、BLOCKED(阻塞中)等。
-
分析堆栈跟踪:对于每个线程,查看其堆栈跟踪以了解线程执行的代码路径。堆栈跟踪通常包含了方法和类名,帮助您确定问题代码的位置。
-
查找共享资源和锁信息:如果线程转储包含锁信息,查看哪些线程正在等待获取哪些锁,以及哪些线程已经持有锁。这有助于识别死锁或资源争用问题。
-
识别问题线程:找出占用CPU高或处于异常状态的线程,以及哪些线程可能导致了性能问题或死锁。
-
使用性能分析工具:如果需要更深入的分析,您可以使用性能分析工具(如VisualVM、JProfiler、YourKit等)来可视化和交互式地分析线程转储数据。这些工具通常提供更强大的分析功能,有助于更轻松地识别问题。
-
解决问题:根据分析的结果,采取必要的措施来解决线程问题。这可能包括优化代码、解决死锁、减少线程争用等。
-
监控和预防:定期监控应用程序的线程情况,以及线程转储文件,以便在早期发现和解决问题。采取预防措施,如合理的锁策略、避免死锁、资源池管理等,以减少线程问题的发生。
线程转储分析通常需要一定的经验和技能,特别是在处理复杂的多线程应用程序时。性能分析工具可以大大简化这个过程,并提供更多的可视化信息,有助于更快地定位和解决问题。
30. 什么是CPU占用高(High CPU Usage)问题?如何排查?
答:CPU占用高(High CPU Usage)问题是指应用程序或进程占用了大量的CPU资源,导致系统负载升高、性能下降或系统变得不响应。要排查高CPU占用问题,可以采取以下步骤:
-
监控CPU使用率:使用系统监控工具(如top、htop、Windows任务管理器)来检查哪个进程或线程占用了大量的CPU资源。
-
查看线程转储:如果CPU占用问题与多线程应用程序相关,生成线程转储并查看问题线程的堆栈跟踪,以了解问题的代码路径。
-
分析代码:确定占用CPU的代码部分。查看哪些方法或循环消耗了大量的CPU时间。
-
检查循环:查看是否存在无限循环或非预期的循环条件,这可能导致CPU占用问题。
-
检查阻塞操作:查看是否存在长时间的阻塞操作,例如等待网络或文件系统操作,这可能导致CPU资源浪费。
-
使用性能分析工具:使用性能分析工具(如VisualVM、JProfiler、YourKit)来更详细地分析CPU占用问题。这些工具可以提供更多的可视化数据和分析功能。
-
优化代码:根据分析结果采取必要的措施来优化代码,减少CPU占用。这可能包括改进算法、减少不必要的计算或循环、并行化任务等。
-
避免不必要的轮询:如果应用程序中存在轮询机制,尽量避免过于频繁的轮询,采用事件驱动或异步机制。
-
增加硬件资源:如果必要,增加CPU核心数量或升级硬件来缓解CPU占用问题。
通过以上步骤,您可以确定高CPU占用问题的原因,并采取适当的措施来解决问题,从而提高应用程序的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!