Servlet-Filter 执行顺序测试
Servlet-Filter 执行顺序测试
对于 web.xml 文件注册过滤器这里就不多说了,就是谁声明的早,谁先被调用。因为在上面的过滤器信息最先被扫描到。
模型抽象
为了便于在实践中使用,结合部分底层原理,我们可以对 Filter 链的执行做一下抽象。
我们有一个初始容量为 0 的队列,该队列中有一个 insertPos(以下简写为 ips,初始值为-1) 的属性,用来指示上一个 isMatchAfter 值为 false 的 filter 的添加位置(下标)。当尝试 addMappingForUrlPattern 时,判断当前 Filter 的 isMatchAfter 的属性值:
- 若 isMatchAfter 值为 true,则直接将元素添加至队尾;
- 若 isMatchAfter 值为 false,则将该元素添加到下标为 insertPos + 1 的位置,即插入到上一个 isMatchAfter 为 false 的 filter 的下一个位置,随后将 ips ++;
我们举例说明这个模型的使用:
以 true, true, false, false 为例,那么假如的顺序为:
- 加入链尾。
01, ips 为 -1; - 加入链尾。
01 -> 02,ips 为 -1; - 加入到 ips + 1 = 0 的位置。
03 -> 01 -> 02,ips 为 0; - 加入到 ips + 1 = 1 位置。
03 -> 04 -> 01 -> 02,ips 为 1;
若顺序为 false, false, true, true:
- 加入 ips + 1 = 0的位置。
01,ips 为 0; - 加入到 ips + 1 = 1 位置。
01 -> 02,ips 为 1; - 加入链尾。
01 -> 02 -> 03; - 加入链尾。
01 -> 02 -> 03 -> 04;
所以按照模型,在 web.xml 中注册的 filter 默认 isMatchAfter 的值就全部为 true 或者 false。
测试环境
tomcat 10.1.17;servlet-api: Jakarta-servlet-api: 6.0.0, Jakarta-annotaion: 2.0.0;Java 17;
使用 @WebFilter 注解
结论
如果使用注解,那么 Filter 的顺序就取决于文件的组织形式,即按照文件夹的排列的顺序来定义 filter 的顺序。
而 Idea 的文件的组织形式都是按照文件名进行排序的,所以如果用模型来解释,以这种方式注册的 filter,isMatchAfter 的值都为 true 或者 false。谁先被扫描到,谁就先加入队列。
过程
同一文件夹内
若文件的组织如下图所示:

@WebFilter(value = "/*", filterName = "03")
@Slf4j
public class _01 implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
log.info("01 filter....");
chain.doFilter(request, response);
}
}
@WebFilter(value = "/*", filterName = "02")
@Slf4j
public class _02 implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
log.info("02 filter....");
chain.doFilter(request, response);
}
}
@Slf4j
@WebFilter(value = "/*", filterName = "01")
public class _03 implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
log.info("03 filter....");
chain.doFilter(request, response);
}
}
执行结果为(经过多次请求地址 localhost:8080,仍然为这一结果):
2023-12-22 11:29:22.871 INFO [http-nio-8080-exec-1] c.y.w.fiter._01 01 filter....
2023-12-22 11:29:22.874 INFO [http-nio-8080-exec-1] c.y.w.fiter._02 02 filter....
2023-12-22 11:29:22.874 INFO [http-nio-8080-exec-1] c.y.w.fiter._03 03 filter....
2023-12-22 11:29:23.516 INFO [http-nio-8080-exec-2] c.y.w.fiter._01 01 filter....
2023-12-22 11:29:23.516 INFO [http-nio-8080-exec-2] c.y.w.fiter._02 02 filter....
2023-12-22 11:29:23.516 INFO [http-nio-8080-exec-2] c.y.w.fiter._03 03 filter....
2023-12-22 11:29:23.732 INFO [http-nio-8080-exec-3] c.y.w.fiter._01 01 filter....
2023-12-22 11:29:23.732 INFO [http-nio-8080-exec-3] c.y.w.fiter._02 02 filter....
2023-12-22 11:29:23.732 INFO [http-nio-8080-exec-3] c.y.w.fiter._03 03 filter....
不同文件夹下
文件夹的组织如下:
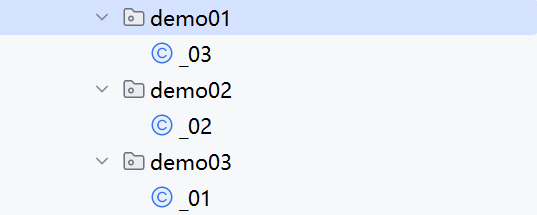
类信息不变。
执行结果为:

如果我们把类名进行修改,但是类信息不变,如下:
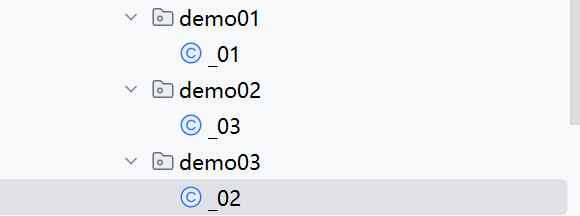
执行结果为:

可以看到,仍然是按照从上到下的顺序进行执行的,所以,由以上实验可以得到 WebFilter 定义的注解与类名和 filterName 属性都无关。
总结
可见,在 idea 测试环境下,若把所有的 Filter 组织在一个文件夹下,那么 Filter 的执行顺序是与类名有关的。因为,idea 的文件组织是默认按照名称进行排序的(与 windows 的默认文件排序方式无关)。
也就是说,过滤器的执行顺序只与谁先被扫描到(谁先被加入到过滤器链条)有关(Servlet-api 底层的定义的是 LinkedHashSet 结构来存储过滤器链的)。所以,我们不推荐使用注解的方法定义过滤器链。
ServletContext 动态注册 Filter
对于这种情况,网上有很多种说法,最可信的(看起来对的)说法是,按照加入 ServletContext 的顺序为执行顺序,这种说法是很有道理的。因为不论是扫描 xml 文件加入 Filter 还是扫描文件夹假如 Filter,最后都将这个过滤链加入了 ServletContext。
倘若我们嫌分析源码麻烦,那么做一个实验去验证是最为经济的做法了。
我们对上次的实验的类进行保留,只是去除 WebFilter 注解。然后尝试进行动态注册。
结论
addMappingForUrlPatterns方法的调用决定了过滤器的顺序:- 当
isMatchAfter全部为 true 时,方法的调用顺序决定了过滤器的执行顺序,并且为正相关(先调用先执行); - 当
isMatchAfter全部为 false 时,与上一种情况相同; - 当有一个 filter 的 isMatchAfter 属性为 true 或者 false 的时候,
- 当
不同文件夹下
对照实验
我们设置的测试代码为:
@Slf4j
@WebListener
public class ContainerInitializer implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent sce) {
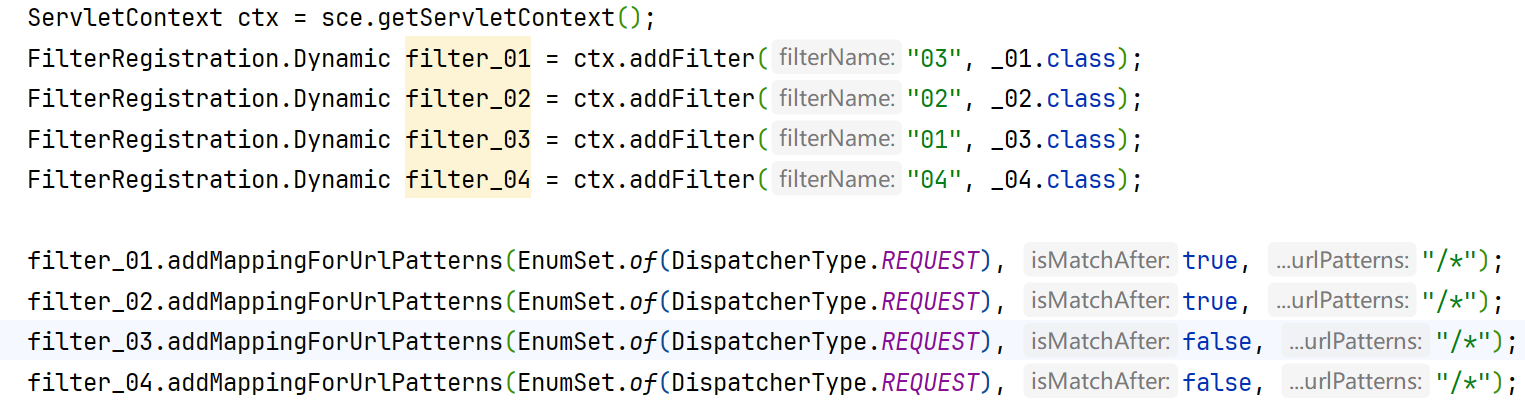
ServletContext ctx = sce.getServletContext();
FilterRegistration.Dynamic filter_01 = ctx.addFilter("01", _01.class);
FilterRegistration.Dynamic filter_02 = ctx.addFilter("02", _02.class);
FilterRegistration.Dynamic filter_03 = ctx.addFilter("03", _03.class);
filter_01.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
filter_02.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
filter_03.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
}
}
最后的执行结果为,重复四次实验(访问 localhost:8080):

可以看到,顺序为我们注册到 ServletContext 的顺序。请忽略后续的 log 的 message 信息,这是无关紧要的。
改变 addFilter 顺序
现在我们调换 addFilter 的顺序,从 _01 -> _02 -> _03 调整为 _02 -> _01 -> _03。其余不变,即:
FilterRegistration.Dynamic filter_02 = ctx.addFilter("02", _02.class);
FilterRegistration.Dynamic filter_01 = ctx.addFilter("01", _01.class);
FilterRegistration.Dynamic filter_03 = ctx.addFilter("03", _03.class);
// nothing changed
执行结果为:
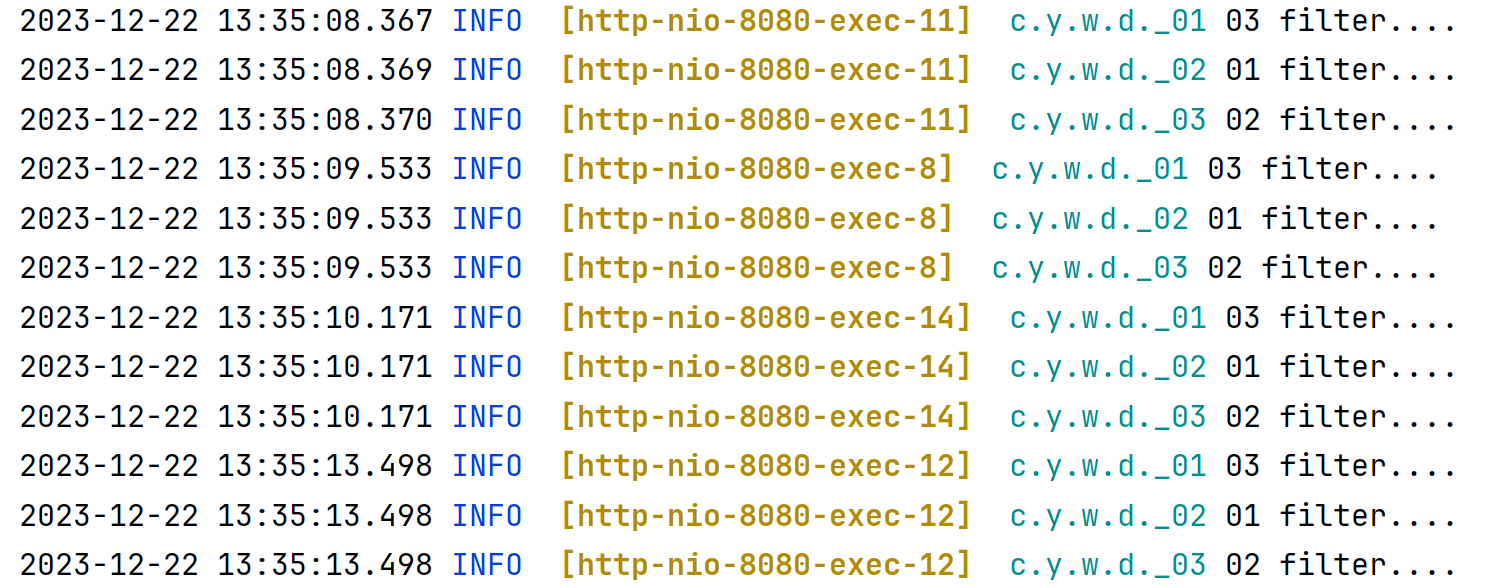
发现结果不变,说明改变,addFilter 顺序行为并不能改变注册顺序。
改变 filterName
尝试改变 filterName 来试图调整顺序,即:
FilterRegistration.Dynamic filter_01 = ctx.addFilter("03", _01.class);
FilterRegistration.Dynamic filter_02 = ctx.addFilter("02", _02.class);
FilterRegistration.Dynamic filter_03 = ctx.addFilter("01", _03.class);
执行结果为:
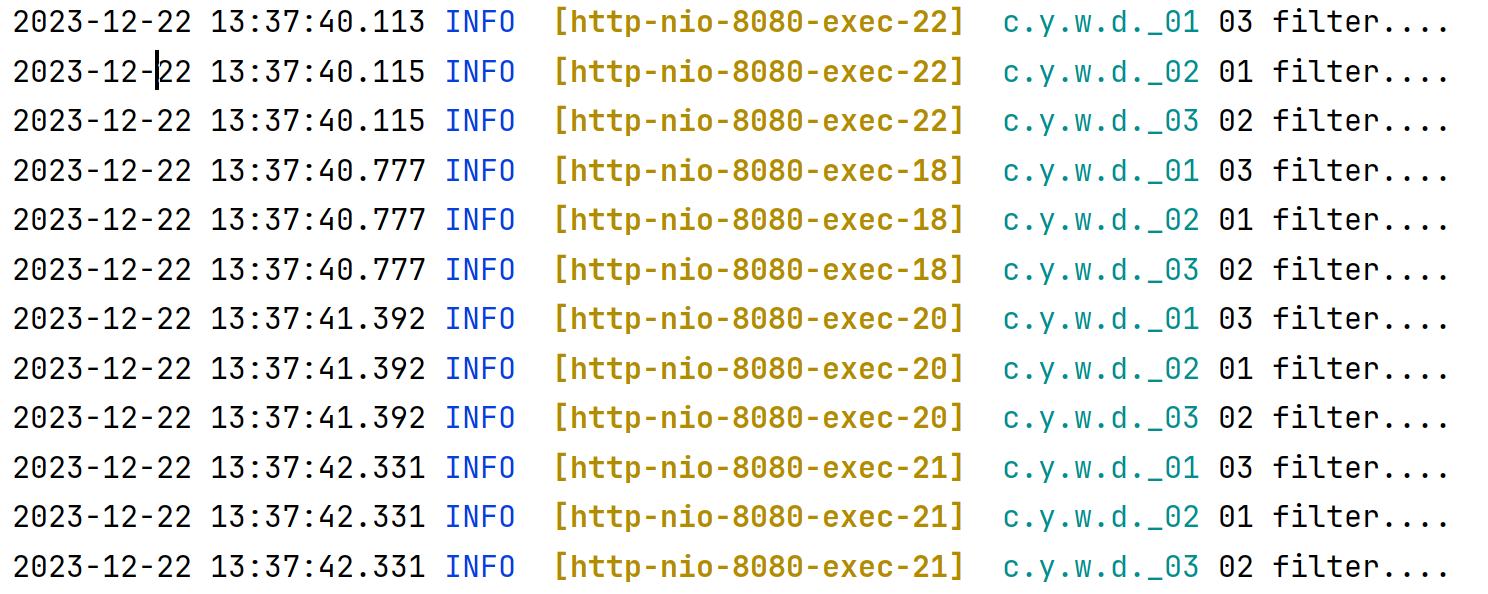
没有任何效果。
改变 addMappingForUrlPatterns 的调用
isMatchAfter 全部为 true
尝试改变 addMappingForUrlPatterns 方法的调用顺序,即:
filter_02.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
filter_01.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
filter_03.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), true, "/*");
执行结果为:
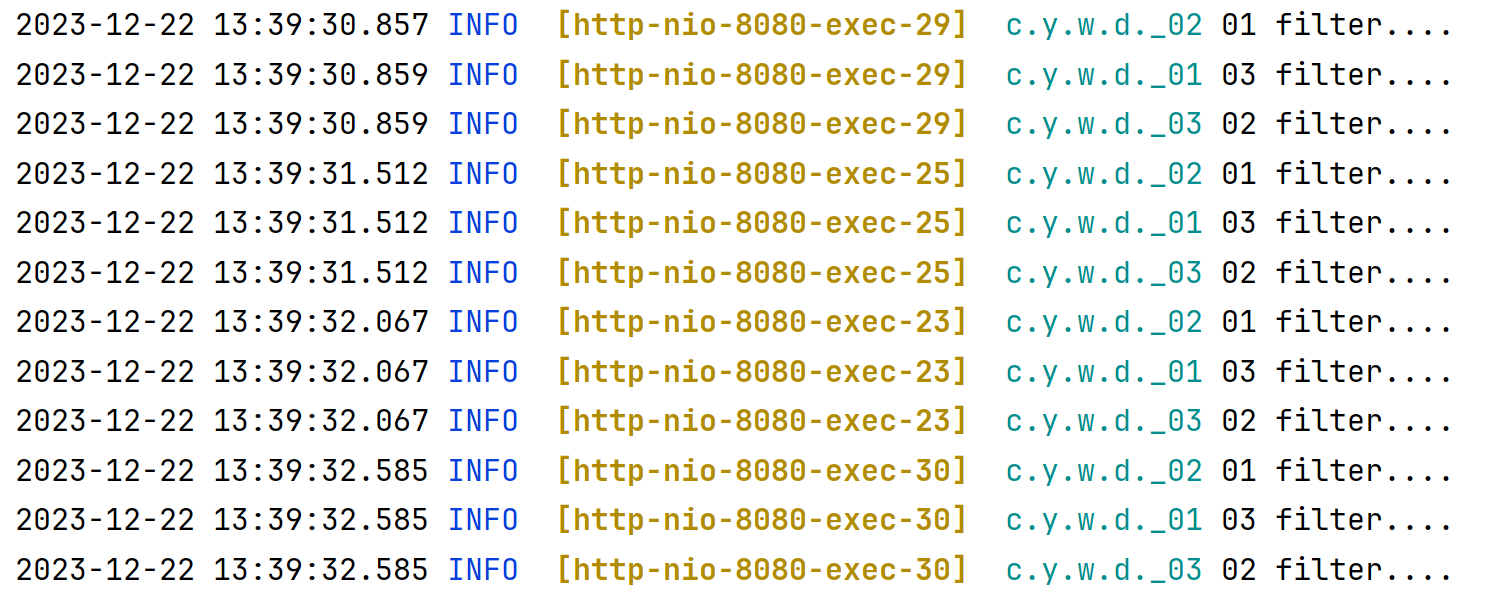
不受到 isMatchAfter 的影响。只与调用顺序有关。
isMatchAfter 全部为 false
直接上结果:
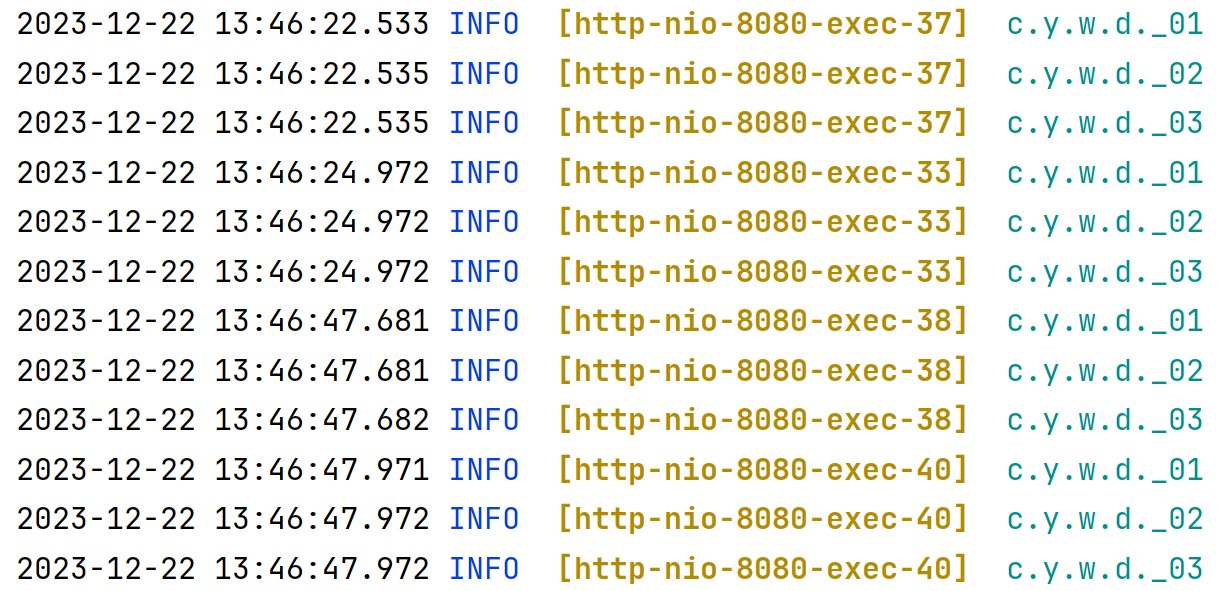
不受到 isMatchAfter 的影响。只与调用顺序有关。
isMatchAfter 只有一个为 true

执行结果为:
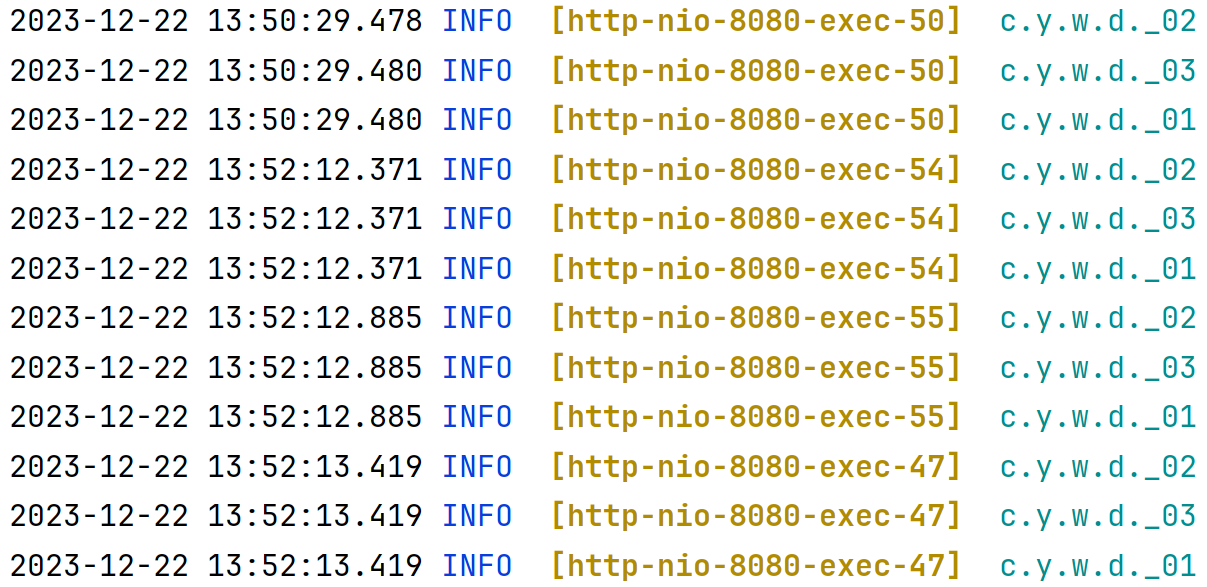
为 true 的 filter 在所有 filter 之后执行。
isMatchAfter 只有一个为 false
修改源码为:

执行结果为:

可以看见,isMatchAfter 为 true 的 filter 变成了第一个执行的。
当有多个 true 和 false 时
为了测试方便,我们新增一个 filter,对代码做如下修改:
执行结果为:
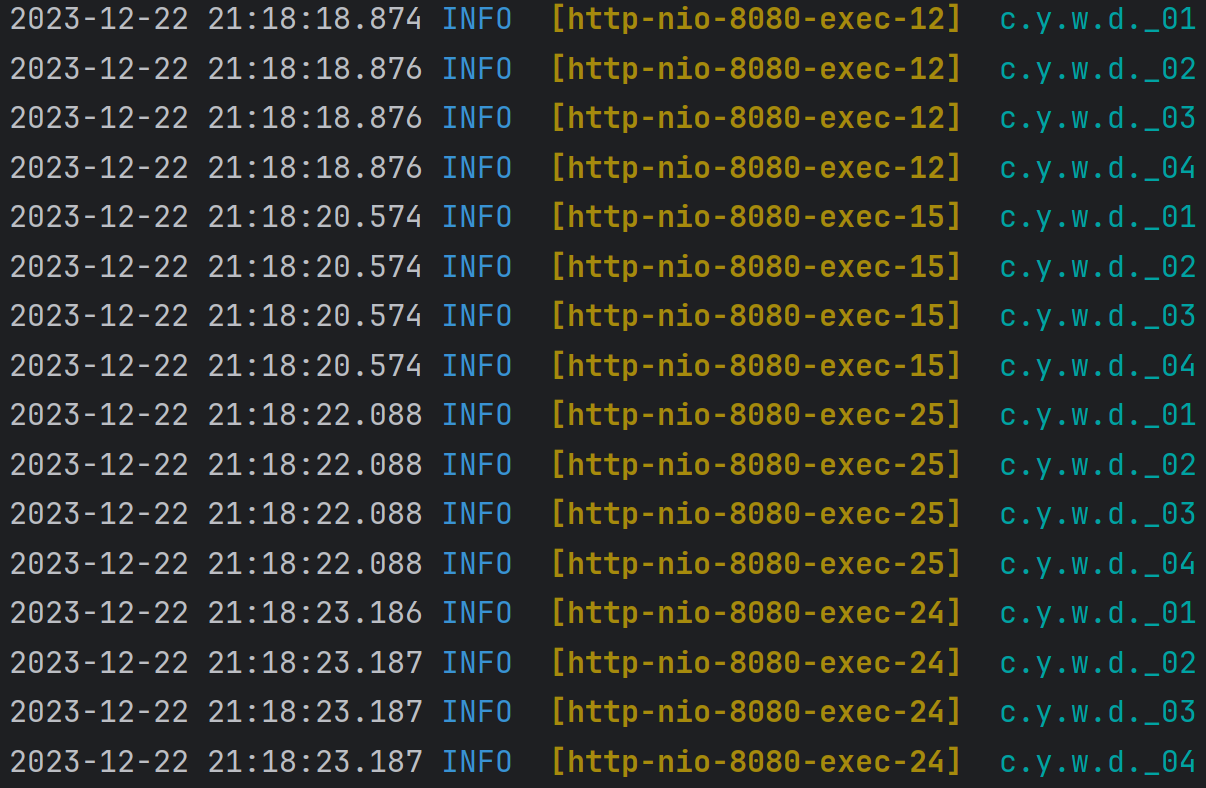
调换顺序:

执行结果为:
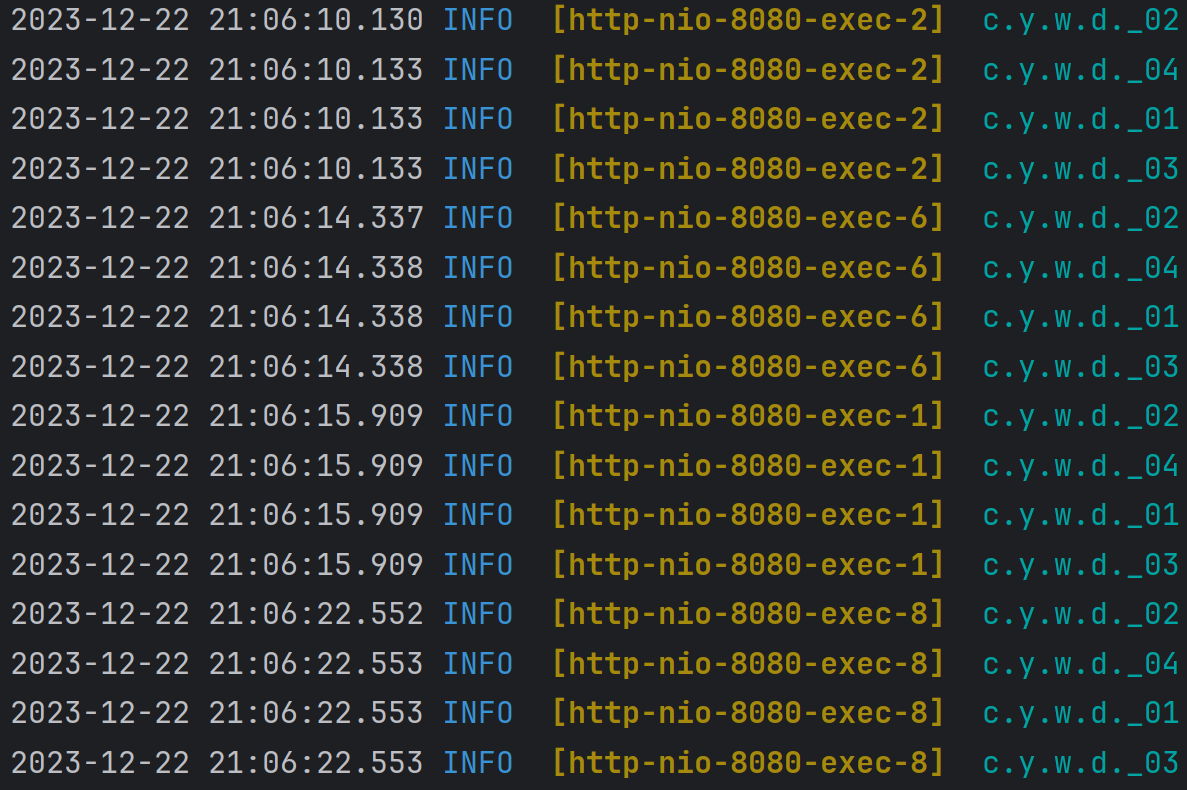
调换顺序:

执行结果为:
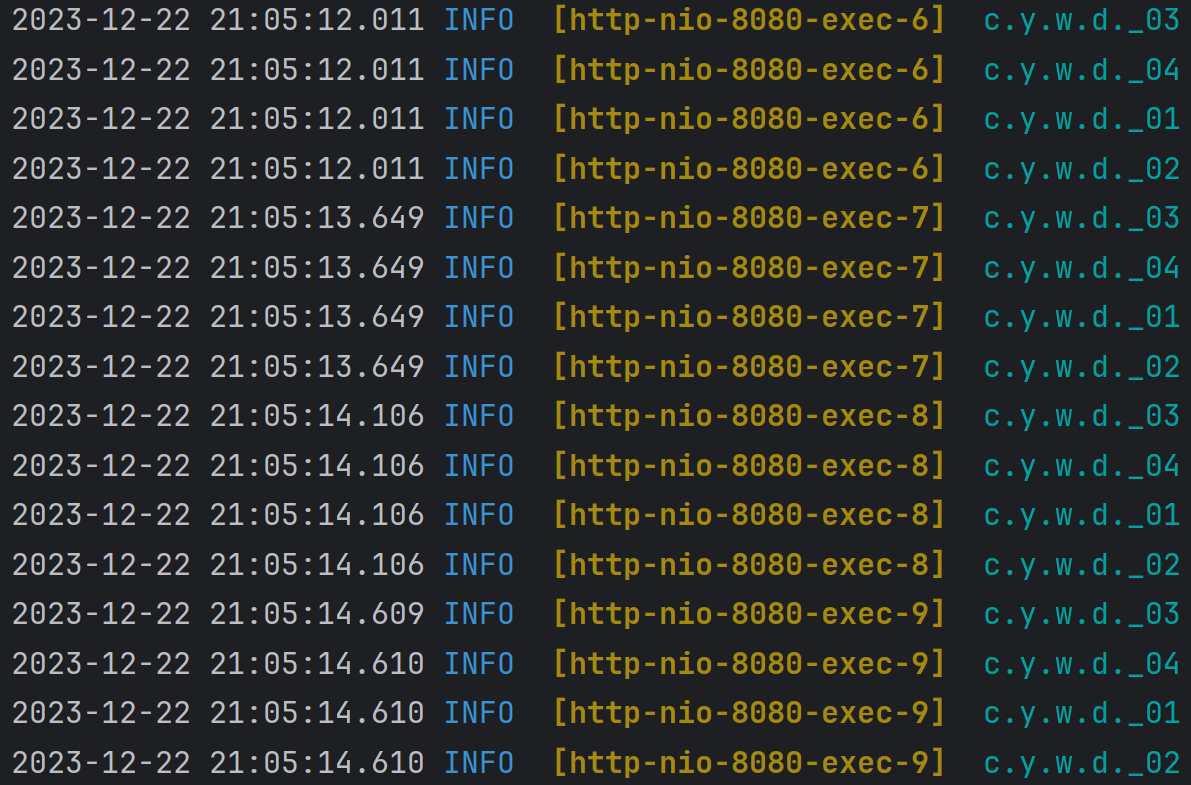
全部能够执行,并且按照调用顺序执行。根据以上,规律可以进行总结了。
若一个 filter 在注册的时候,将 isMatchAfter 设置为 false,就会调换到过滤链中所有 isMatchAfter 值为 false 的下一个位置(不加入到队首);若设置为 true,就默认加载过滤链尾。
故而,在多个 true,false 混合的时候,例如以 true, true, false, false 为例,那么假如的顺序为:
- 加入链尾。
01; - 加入链尾。
01 -> 02; - 加入链首。
03 -> 01 -> 02; - 加入链首。
03 -> 04 -> 01 -> 02;
若顺序为 false, false, true, true:
- 加入链首。
01; - 加入链首。
01 -> 02; - 加入链尾。
01 -> 02 -> 03; - 加入链尾。
01 -> 02 -> 03 -> 04;
这与我们的实验结果是一致的。
总结
在不同文件夹下,过滤器的调用顺序与结论符合。
同一文件夹下
实验结果完全相同。这里的实验过程,限于篇幅就略过了。
总结
在同一文件夹下,过滤器的调用顺序与结论符合。
总结
动态注册过滤器的执行顺序只与 addMappingForUrlPatterns 方法的调用顺序和该方法的参数 isMatchAfter 有关。与文件夹,文件名,filterName 无关。
总结
实验结果完全契合模型。实际上,结合 tomcat 的源码,tomcat 只不过是将模型的队列用数组实现了而已。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!