TrustGeo代码理解(一)main.py
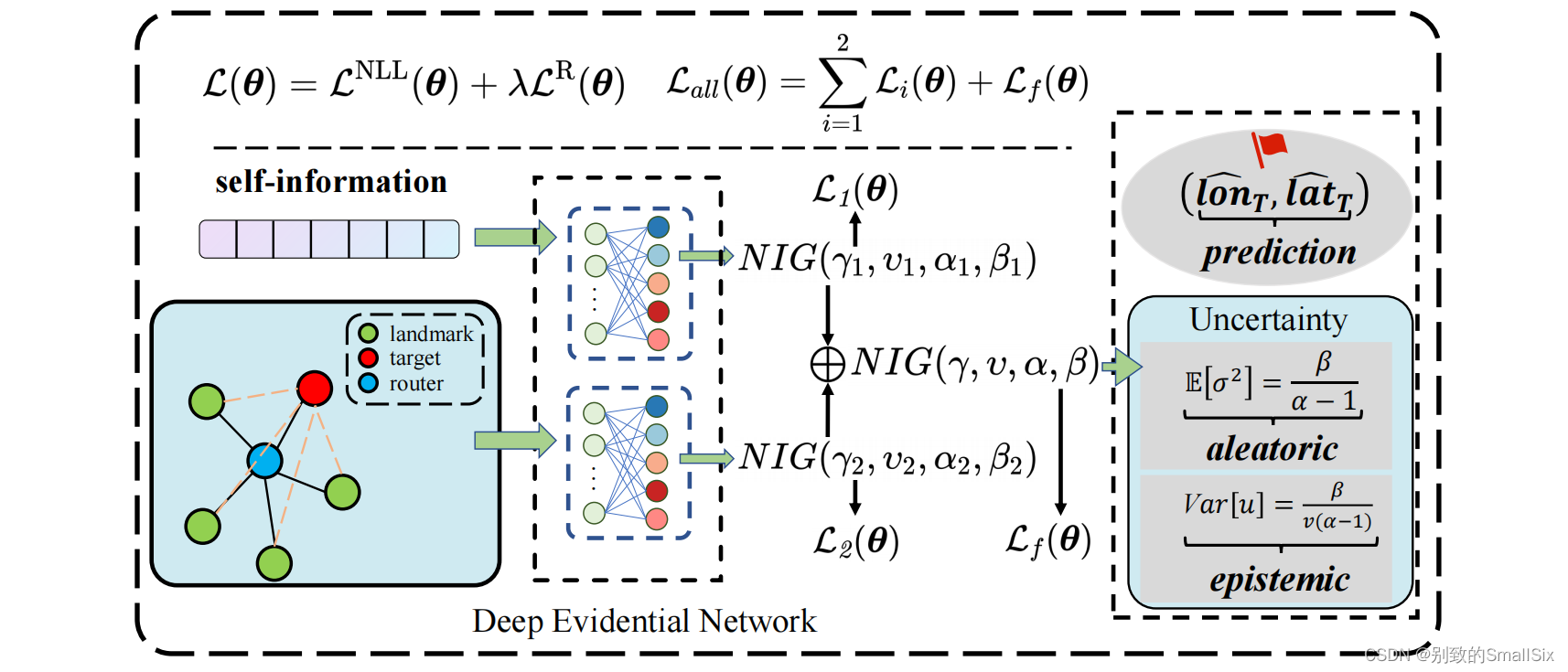
代码链接:https://github.com/ICDM-UESTC/TrustGeo
一、导入各种模块和数据库
# -*- coding: utf-8 -*-
import torch.nn
from lib.utils import *
import argparse, os
import numpy as np
import random
from lib.model import *
import copy
from thop import profile
import pandas as pd整体功能是准备运行一个 PyTorch 深度学习模型的环境,具体的功能实现需要查看 lib.utils、lib.model 中的代码,以及整个文件的后续部分。
1、# -*- coding: utf-8 -*-:指定脚本的字符编码为UTF-8。
2、import torch.nn:导入 PyTorch 的神经网络模块,用于定义和训练神经网络。
3、from lib.utils import *:从 lib.utils 模块中导入所有内容,这可能包括一些工具函数或辅助函数,用于该脚本或项目的其他部分。
4、import argparse, os:导入 argparse 模块用于解析命令行参数,os 模块用于与操作系统交互。
5、import numpy as np:导入 NumPy 库,用于进行科学计算,特别是多维数组的处理。
6、import random:导入 random 模块,用于生成伪随机数。
7、from lib.model import *:从 lib.model 模块中导入所有内容,这可能包括定义神经网络模型的类等。
8、import copy:导入 copy 模块,用于复制对象,通常用于创建对象的深拷贝。
9、from thop import profile:从 thop 模块中导入 profile 函数,该函数用于计算 PyTorch 模型的 FLOPs(浮点运算数)和参数数量。(在代码链接中没有找到)
10、import pandas as pd:导入 Pandas 库,用于数据处理和分析,通常用于处理表格型数据。
二、参数初始化(通过命令行参数)
parser = argparse.ArgumentParser()
# parameters of initializing
parser.add_argument('--seed', type=int, default=2022, help='manual seed')
parser.add_argument('--model_name', type=str, default='TrustGeo')
parser.add_argument('--dataset', type=str, default='New_York', choices=["Shanghai", "New_York", "Los_Angeles"],
help='which dataset to use')这部分代码的目的是通过命令行参数设置一些初始化的参数,例如随机数种子、模型名称和数据集名称。这使得在运行脚本时可以通过命令行参数来指定这些参数的值。
1、parser = argparse.ArgumentParser():创建一个 argparse.ArgumentParser 对象,用于解析命令行参数。
2、# parameters of initializing:注释,表示接下来是初始化参数的部分。
3、parser.add_argument('--seed', type=int, default=2022, help='manual seed'):添加一个命令行参数,名称为 '--seed',表示随机数种子,类型为整数,默认值为 2022,help 参数是在命令行中输入 --help 时显示的帮助信息。
4、parser.add_argument('--model_name', type=str, default='TrustGeo'):添加一个命令行参数,名称为 '--model_name',表示模型的名称,类型为字符串,默认值为 'TrustGeo'。
5、parser.add_argument('--dataset', type=str, default='New_York', choices=["Shanghai", "New_York", "Los_Angeles"], help='which dataset to use'):添加一个命令行参数,名称为 '--dataset',表示数据集的名称,类型为字符串,默认值为 'New_York',choices 参数指定了可选的值为 ["Shanghai", "New_York", "Los_Angeles"],用户只能从这三个值中选择。help 参数是在命令行中输入 --help 时显示的帮助信息。
三、训练过程参数设置
# parameters of training
parser.add_argument('--beta1', type=float, default=0.9)
parser.add_argument('--beta2', type=float, default=0.999)
parser.add_argument('--lambda1', type=float, default=7e-3)
parser.add_argument('--lr', type=float, default=5e-3)
parser.add_argument('--harved_epoch', type=int, default=5)
parser.add_argument('--early_stop_epoch', type=int, default=50)
parser.add_argument('--saved_epoch', type=int, default=200) 这部分代码的目的是设置一些训练过程中的超参数,例如优化器的动量参数、学习率、权重参数等。这些参数在训练过程中会影响模型的更新和收敛速度。
1、# parameters of training:注释,表示接下来是训练参数的部分。
2、parser.add_argument('--beta1', type=float, default=0.9):添加一个命令行参数,名称为 '--beta1',表示 Adam 优化器的第一个动量(momentum)参数,类型为浮点数,默认值为 0.9。
3、parser.add_argument('--beta2', type=float, default=0.999):添加一个命令行参数,名称为 '--beta2',表示 Adam 优化器的第二个动量参数,类型为浮点数,默认值为 0.999。
4、parser.add_argument('--lambda1', type=float, default=7e-3):添加一个命令行参数,名称为 '--lambda1',表示某个权重参数,类型为浮点数,默认值为 7e-3。
5、parser.add_argument('--lr', type=float, default=5e-3):添加一个命令行参数,名称为 '--lr',表示学习率,类型为浮点数,默认值为 5e-3。
6、parser.add_argument('--harved_epoch', type=int, default=5):添加一个命令行参数,名称为 '--harved_epoch',表示某个 epoch 的值,类型为整数,默认值为 5。
7、parser.add_argument('--early_stop_epoch', type=int, default=50):添加一个命令行参数,名称为 '--early_stop_epoch',表示早停(early stop)的 epoch 数,类型为整数,默认值为 50。
8、parser.add_argument('--saved_epoch', type=int, default=200): 添加一个命令行参数,名称为 '--saved_epoch',表示保存模型的 epoch 数,类型为整数,默认值为 200。
四、模型参数设置
# parameters of model
parser.add_argument('--dim_in', type=int, default=30, choices=[51, 30], help="51 if Shanghai / 30 else")
opt = parser.parse_args()
print("Learning rate: ", opt.lr)
print("Dataset: ", opt.dataset)这部分代码的目的是解析命令行参数,并打印出学习率和数据集名称。--dim_in 参数用于指定输入维度,可以选择是 51 或者 30。
1、# parameters of model:注释,表示接下来是训模型参数的部分。
2、parser.add_argument('--dim_in', type=int, default=30, choices=[51, 30], help="51 if Shanghai / 30 else"):添加一个命令行参数,名称为 '--dim_in',表示输入的维度,类型为整数,默认值为 30。choices 参数指定了可选的值为 [51, 30],用户只能从这两个值中选择。help 参数是在命令行中输入 --help 时显示的帮助信息。
3、opt = parser.parse_args():使用 argparse 解析命令行参数,将结果存储在 opt 变量中。
4、print("Learning rate: ", opt.lr):打印学习率,即 opt 对象中的 lr 属性。
5、print("Dataset: ", opt.dataset):打印数据集名称,即 opt 对象中的 dataset 属性。
五、设置随机种子数
if opt.seed:
print("Random Seed: ", opt.seed)
random.seed(opt.seed)
torch.manual_seed(opt.seed)
torch.set_printoptions(threshold=float('inf'))这一部分的目的是确保在使用随机数的场景中,每次运行程序得到的随机结果是可复现的。通过设置相同的随机数种子,可以使得每次运行得到相同的随机数序列。
1、如果 opt 对象中的 seed 属性存在(不为 0 或 False 等假值),则执行以下操作:
- 打印随机数种子的信息。
- 使用 random 模块设置 Python 内建的随机数生成器的种子。
- 使用 PyTorch 的 torch 模块设置随机数种子。
2、torch.set_printoptions(threshold=float('inf')):设置 PyTorch 的打印选项,将打印的元素数量限制设置为无穷大,即不限制打印的元素数量。这样可以确保在打印张量时,所有元素都会被打印出来,而不会被省略。
六、过滤所有警告信息
warnings.filterwarnings('ignore')过滤掉所有警告信息,将警告信息忽略。这通常用于在代码中避免显示一些不影响程序执行的警告信息,以保持输出的清晰。在某些情况下,警告信息可能是有用的,但如果明确知道这些警告对程序执行没有影响,可以选择忽略它们。
七、动态选择运行环境
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("device:", device)
cuda = True if torch.cuda.is_available() else False
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor这部分代码的目的是根据硬件环境动态选择运行模型的设备,并选择相应的 PyTorch 张量类型。如果有可用的 GPU,就使用 GPU 运行模型和 GPU 张量类型;否则,使用 CPU 运行模型和 CPU 张量类型。
1、device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'):创建一个 PyTorch 设备对象,表示运行模型的设备。如果 CUDA 可用(即有可用的 GPU),则使用 'cuda:0' 表示第一个 GPU,否则使用 'cpu' 表示 CPU。
2、print("device:", device):打印设备的信息,即使用的是 GPU 还是 CPU。
3、cuda = True if torch.cuda.is_available() else False:根据 CUDA 是否可用设置一个布尔值,表示是否使用 GPU。如果 CUDA 可用,则 cuda
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (十四)Head first design patterns建造者模式(c++)
- 组件中使用定时器及销毁问题(vue的问题)
- Python 用pytorch从头写transformer源码,一行一解释;机器翻译实例代码
- 基于springboot生鲜交易系统源码和论文
- SpringBoot启动流程分析2--run方法
- 【?什么是分布式系统的一致性 ?】
- Java小案例-Java实现人事管理系统
- super()内置函数的理解与应用
- Springboot整合篇Druid
- 「数据结构」二叉树2