【ZooKeeper高手实战】ZooKeeper 工业级的场景(配置中心、日志系统、数据同步系统)
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送
发送 资料 可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁

ZooKeeper 工业级的场景
zk 节点监听的 经典应用场景
-
配置中心:可以将分布式业务系统中的配置放在 zk 中或者基于 zk 封装一个配置中心,并且对配置进行监听,如果配置发生变更,立马就可以通过 zk 通知到所有监听配置项的系统,从而可以及时响应就比如在分布式业务中需要
降级,打开一个降级开关,所有系统感知到之后,进行对应的降级处理 -
集群负载均衡:对于需要进行负载均衡的机器去 zk 中注册自己,创建为临时节点,注册成 ip,如下图对于提供同一个服务的不同机器在同一个节点下边注册自己的 ip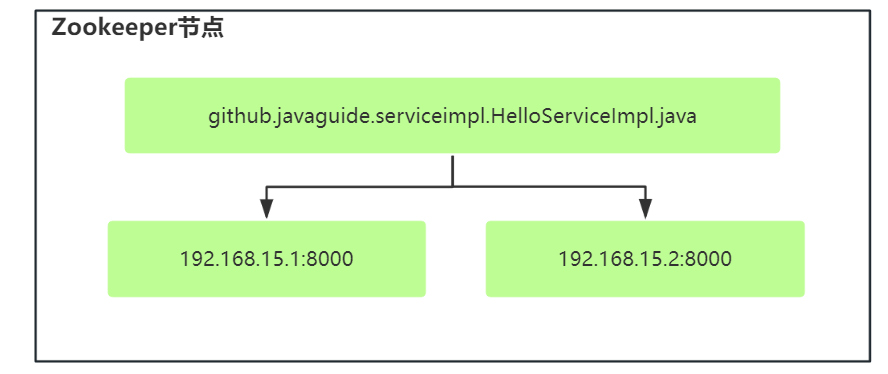
基于 zk 如何实现分布式业务系统的 配置中心
分布式系统的配置中心,用于存储以下配置:
- 数据库配置信息、地址、用户名、密码
- 限流开关、手动降级开关
比如对 手动降级开关 来说,开发人员通过手动设置降级开关,而各个系统去监听这个降级开关的 znode,如果监听到,就对各个接口采取降级措施,整个配置中心的设计如下(这里只讲一下应用场景,具体也就是通过对节点的监听实现的,后边会讲到):
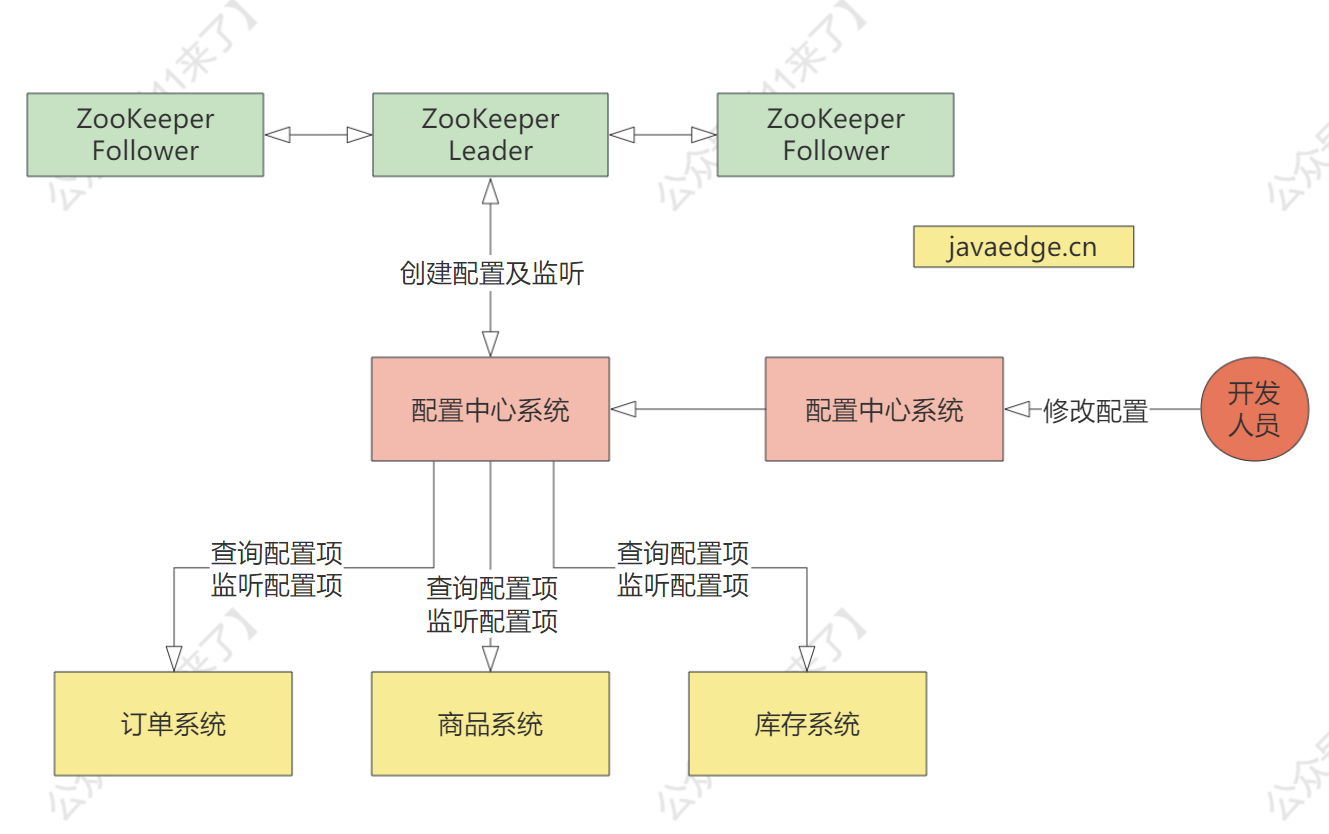
基于 ZK + ES 的日志中心架构设计
在业务系统中会部署很多台机器,由于日志过于分散,需要统一收集到 ES 中进行日志存储,并且可以通过可视化工作台方便开发人员随时检索日志,下边将会设计一个 基于 ZK + ES 的日志中心系统!
先来说一下日志中心的 需求场景:
日志中心系统需要集群部署,在各个业务系统中都有日志客户端,通过客户端自动把日志异步化写入到 Kafka 中去,对应不同的 Topic,日志中心系统为 Master-Slave 架构,Slave 负责从 Kafka 中消费某些 Topic 里的日志写入 ES,Master 负责给 Slave 分配对应要消费的 Topic
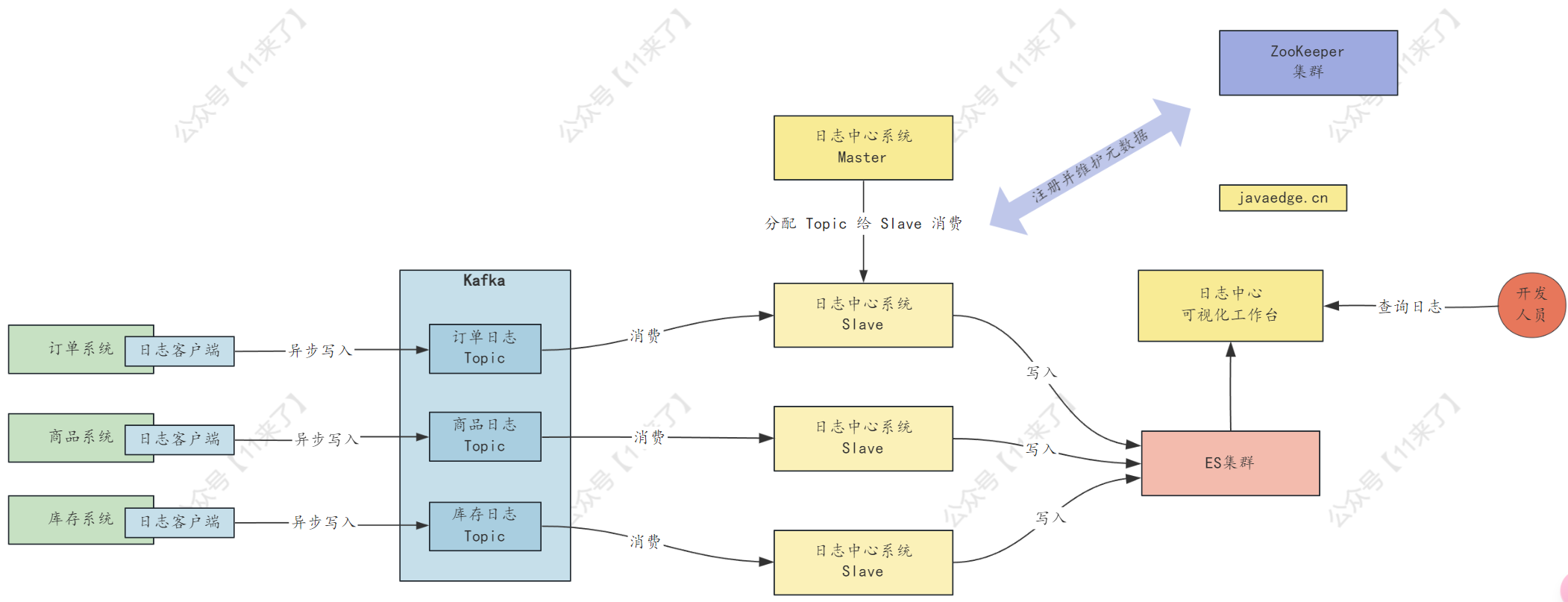
那么基于上边说的需求场景,我们需要在 zk 中存储这些数据:
需要收集的 Topic 列表:通过这个值,日志中心才知道需要去 Kafka 中拉取哪些数据存入到 ES 集群中- 存入 zk 中的节点目录:/log-center/topics/#{topic}
日志中心节点列表:日志中心系统的 slave 时集群化部署的,因此当 slave 节点上线之后需要去 zk 中注册自己的 ip+port,并且注册为临时节点,这样也可以感知到 slave 节点的上下线,并且通过这个列表还可以对 slave 节点进行负载均衡处理- 存入 zk 中的节点目录:/log-center/slaves/#{host}
slave 节点的分组信息:可以将多个 slave 节点分成一个组,相当于是多个 slave 节点属于一个 consumer group,可以并行去消费同一个 Topic 中的数据,加快消费速度- 存入 zk 中的节点目录:
- /log-center/slave-groups/#{group01}/#{slave01}
- /log-center/slave-groups/#{group01}/#{slave02}
- /log-center/slave-groups/#{group02}/#{slave01}
- 存入 zk 中的节点目录:
每个 slave 分组所分配的 Topic:表示这个 slave 分组需要去将哪些 Topic 数据给拉取并存入 ES 中- 存入 zk 中的节点目录:
- /log-center/slave-groups/#{group01}/topics/#{topic}
- /log-center/slave-groups/#{group02}/topics/#{topic}
- 存入 zk 中的节点目录:
一个简略版本的日志中心系统就是需要在 zk 中存储这些值了,当然既然 slave 集群部署了,还可以在 zk 中存储每个 slave 节点的消费速率,以及在 Topic 中消费的偏移量 offset,这样如果有某个 slave 节点挂了之后,可以让其他的 slave 节点接管这个 slave 节点需要消费的数据,做一个 故障转移 的处理
数据同步系统的架构设计
ZooKeeper 还可以用在数据同步系统中
数据同步系统就是需要将 源数据存储 和 目标数据存储 中的数据进行同步,从而保持数据一致,那么数据同步系统就分为了 3 个部分:
-
Master:负责去 zk 中监听数据同步的任务,当监听到之后,将数据同步的任务发放给 Collector 和 Store -
Collector:监听 zk 中的数据同步任务的节点,当监听到节点有同步的任务时,就负责去源数据存储中拉取待同步的数据 -
Store:监听 zk 中的数据同步任务的节点,当监听到节点有同步的任务时,就去 Kafka 中拉取待同步的数据,将数据写入到目标数据存储中
整体的一个流程如下图:
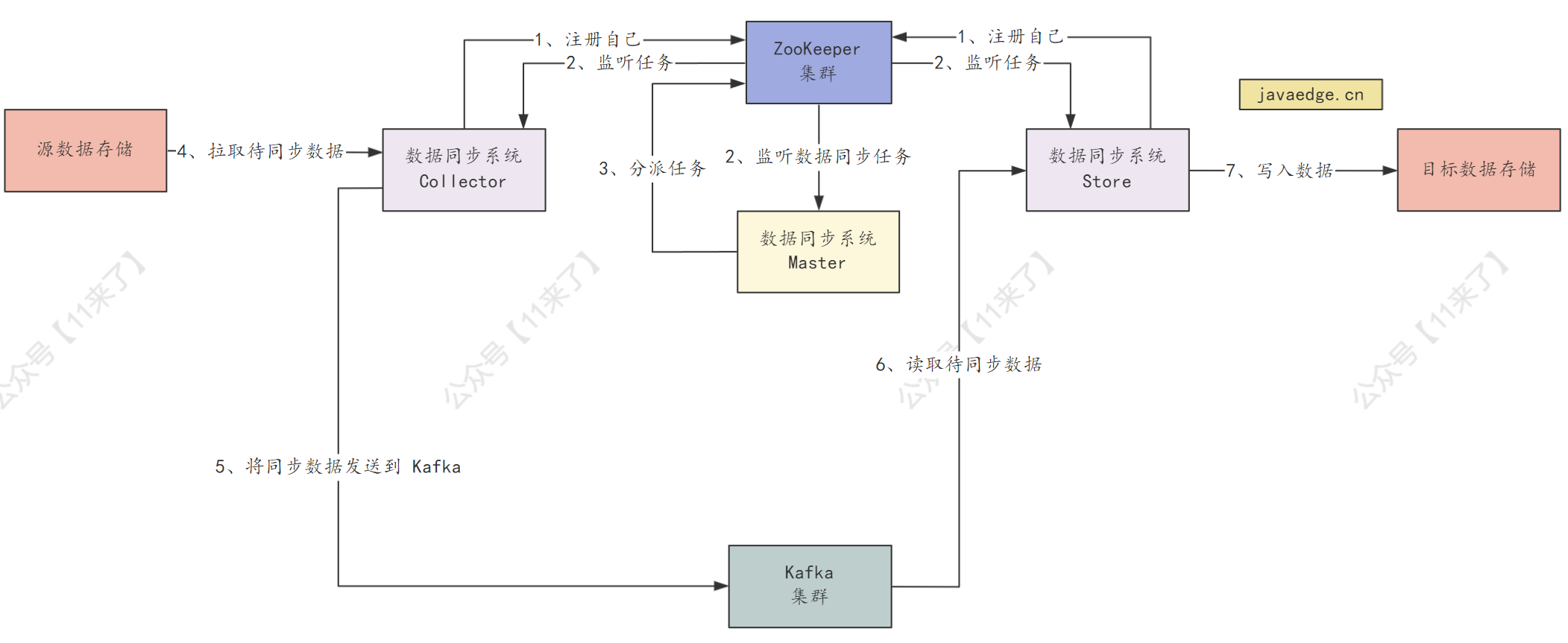
那么在数据同步系统中,zk 管理的数据就相比于日志中心架构要简单一些,只需要管理 同步任务 创建及监听即可,节点设计如下:
发布数据同步任务到 zk 中:- 存入 zk 中的节点目录:/data-sync-system/data-sync-tasks/#{data-sync-task}
Collector 监听的数据同步任务:- 存入 zk 中的节点目录:/data-sync-system/collectors/#{collector}/data-sync-tasks/#{data-sync-task}
Store 监听的数据同步任务:- 存入 zk 中的节点目录:/data-sync-system/stores/#{store}/data-store-tasks/#{data-store-task}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大模型系列:OpenAI使用技巧_使用文本向量做语义文本搜索
- stl中的list模拟实现
- HTML---初识CSS
- Vue3前端h5移动端页面预览PDF使用pdfjs-dist,添加自定义文本水印
- [C++]:11.模拟实现vector
- 前端加密后端校验(MD5)
- 【Python程序开发系列】一文总结程序运行出现No module named ‘xxx‘的解决方案
- 青少年CTF-qsnctf-A1-Misc-签到
- 闪存的基础知识1-Vt的定义
- JNPF低代码与其他低代码工具功能有什么不同?