多线程与多进程
操作系统比如 Mac OS X,Linux,Windows 等,都是支持“多任务”的操作系统,操作系统可以同时运行多个任务。一边在逛淘宝,一边在听音乐,一边在用微信聊天,这就是多任务,至少同时有 3 个任务正在运行。

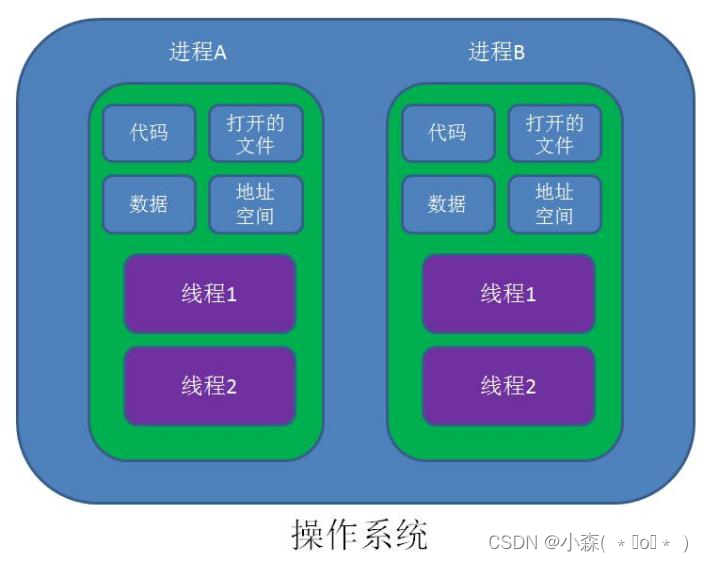
进程和线程都是操作系统中的重要概念。
对于一般的程序,可能会包含若干进程;而每一个进程又可能包含多个同时执行的线程。进程是资源管理的最小单位,而线程则是程序执行的最小单位。
进程和线程的概念
一个任务就是一个进程(Process),比如打开一个浏览器就是启动 一个浏览器进程,打开记
事本就启动了一个记事本进程。
进程:进程就是正在执行的程序,为多任务操作系统中执行任务的基本单元,是包含了程序指令和相关资源的集合。
线程:线程是进程的执行单元。对于大多数程序来说,可能只有一个主线程。但是,为了能够提高效率,有些程序会采用多线程,在系统中所有的线程看起来都是同时执行的。
进程和线程的对比?
进程是重量级的,具体包括进程映像的结构、执行细节以及进程间切换的方法。在进程中,需要处理的问题包括进程间通信、临界区管理和进程调度等。
线程刚好相反,它是轻量级的。线程之间共享许多资源,容易进行通信,生成一个线程的开销较小。但是使用线程会有死锁、数据同步和实现复杂等问题。
由于Python使用了全局解释器锁(GIL)和队列模块,其在线程实现的复杂度上相对于其他语言来说要低得多。??
?进程的开发
| 模块 | 介绍 | 模块 | 介绍 |
| os/sys? | 包含基本进程管理函数 | subprocess | Python基本库中多进 程编程相关模块 |
| multiprocessing | Python基本库中多进程编程模块,核心是fork,重开一个进程,首先会把父进程的代码copy重载一遍 | threading | Python基本库中多线 程管理相关模块 |
multiprocessing模块
multiprocessing 是一个用与 threading 模块相似API的支持产生进程的包。?
from multiprocessing import Process
import os
from time import sleep, time
def test1(name):
?
??print("当前进程的ID", os.getpid())
??print("父进程的ID", os.getppid())
??print("当前进程的名字:", name)
??# 休息3秒
??sleep(3)
if __name__ == '__main__':
??start = time()
??# 创建多个子进程,并且把这些子进程放入列表中
??process_list = []
??print("主进程的ID", os.getpid())
??for i in range(10):
????# args:表示被调用对象的位置参数元组,这里Process就是属于Process类
????p = Process(target=test1, args=('process-%s' % i,))
????
????p.start()
????process_list.append(p)或者自定义一个Process进程类,该类中的run函数由一个子进程调用执行
from multiprocessing import Process
import os
from time import sleep, time
# 自定义一个进程类 继承Process类
class MyProcess(Process):
def __init__(self, name):
???? Process.__init__(self)
???? self.name = name
?? def run(self):
print("当前进程的ID", os.getpid())
???? print("父进程的ID", os.getppid())
???? print("当前进程的名字:", self.name)
???? sleep(3)
if __name__ == '__main__':
??print("主进程ID", os.getpid())
??# 返回当前时间的时间戳
??start = time()
??process_list = []
??for i in range(10):
????# args:表示被调用对象的位置参数元组
????p = MyProcess("process-%s" % i)
????# 开始进程
????p.start()
????process_list.append(p)
??for p in process_list:
????# 一般都会需要父进程等待子进程结束再执行父进程后面的代码,需要join,等待所有的子进程结束
????p.join()
????
????end = time() - start
????print(end)进程间的通信
Python 提供了多种实现进程间通信的机制,主要有 2 种:
1. Python multiprocessing 模块下的 Queue 类,提供了多个进程之间实现通信的诸多方法
2. Pipe,又被称为“管道”,常用于实现 2 个进程之间的通信,这 2 个进程分别位于管道的两端?
Queue 实现进程间通信:
需要使用 multiprocessing 模块中的 Queue 类。简单的理解 Queue 实现进程间通信的方式,就是使用了操作系统给开辟的一个队列空间,各个进程可以把数据放到该队列中,当然也可以从队列中把自己需要的信息取走。?
Pipe 实现进程间通信:
1、send(obj)
发送一个 obj 给管道的另一端,另一端使用 recv() 方法接收。需要说明的是,该 obj 必须是可序列化的,如果该对
象序列化之后超过 32MB,则很可能会引发 ValueError 异常。
2、recv()
接收另一端通过 send() 方法发送过来的数据
3、close()
关闭连接
4、poll([timeout])
返回连接中是否还有数据可以读取
5、send_bytes(buffer[, offset[, size]])?发送字节数据。如果没有指定 offset、size 参数,则默认发送 buffer 字节串的全部数据;如果指定了 offset 和
size 参数,则只发送 buffer 字节串中从 offset 开始、长度为 size的字节数据。通过该方法发送的数据,应该使用
recv_bytes() 或 recv_bytes_into 方法接收。
6、recv_bytes([maxlength])
接收通过 send_bytes() 方法发送的数据,maxlength 指定最多接收的字节数。该方法返回接收到的字节数据
7、recv_bytes_into(buffer[, offset])
功能与 recv_bytes() 方法类似,该方法将接收到的数据放在 buffer 中
?进程池Pool
Python 提供了更好的管理多个进程的方式,就是使用进程池。进程池可以提供指定数量的进程给用户使用,即当有新的请求提交到进程池中时,如果池未满,则会创建一个新的进程用来执行该请求;反之,如果池中的进程数已经达到规定最大值,那么该请求就会等待,只要池中有进程空闲下来,该请求就能得到执行。?
Pool中的函数说明:
- Pool(12):创建多个进程,表示可以同时执行的进程数量。默认大小是CPU的核心数果。
- join():进程池对象调用join,会等待进程池中所有的子进程结束完毕再去结束父进程。
- close():如果我们用的是进程池,在调用join()之前必须要先close(),并且在close()之后不能再继续往进程池添加新的进程?。
- pool.apply_async(func,args,kwds) : 异步执行 ;将事件放入到进程池队列 。args以元组的方式传参,kwds以字典的方式传参。
- pool.apply_sync(func,args,kwds):同步执行;将事件放入到进程池队列。
线程的开发?
使用threading模块来创建线程是很方便的。只要将类继承于threading.Thread,然后在init方法中调用threading.Thread类中的init方法,重写类的run方法就可以了。
单线程执行:?
import time
def say():
??print("这是单线程,单线程,单线程!")
??time.sleep(1)
if __name__ == "__main__":
??start = time.time()
??for i in range(5):
????say()
??end = time.time()
??print(f'使用时间:{end - start}')?多线程执行:
import threading
import time
def say():
??print("多线程,多线程,多线程")
??time.sleep(1)
if __name__ == "__main__":
??
??start = time.time()
??for i in range(5):
????
????t = threading.Thread(target=say)
????t.start() ?
??end = time.time()
??print(f'使用时间:{end - start}')?join方法
该方法将等待,一直到它调用的线程终止. 它的名字表示调用的线程会一直等待,直到指定的线程加入它,当一个进程启动之后,会默认产生一个主线程,因为线程是程序执行流的最小单元,当设置多线程时,主线程会创建多个子线程,在python中,默认情况下(其实就是setDaemon(False)),主线程执行完自己的任务以后,就退出了,此时子线程会继续执行自己的任务,直到自己的任务结束。而join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在终止。
setDaemon?
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。有时候我们需要的是 只要主线程完成了,不管子线程是否完成,都要和主线程一起退出,
这时就可以 用setDaemon方法?。
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
t1 = Thread(target=foo)
t2 = Thread(target=bar)
t1.daemon = True
t1.start()
t2.start()
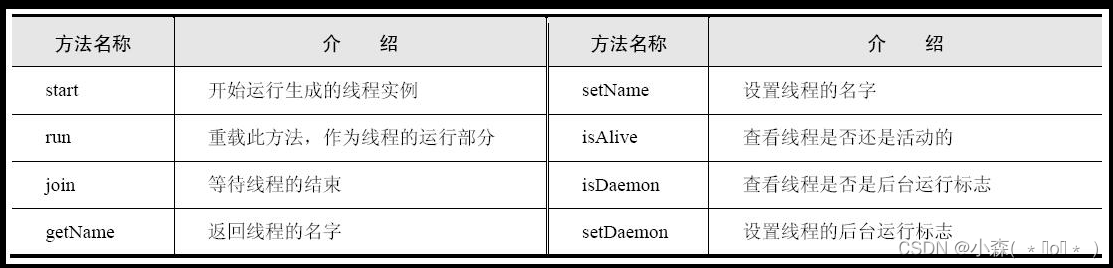
print("main-------")threading模块中Thread类的常用方法:
?线程间的通信
为了避免业务开启过多的线程时。我们就可以通过信号量Semaphore来设置指定个数的线程。车站有3 个安检口,那么同时只能有3 个人安检,别人来了,只能等着别人安检完才可以过。
from threading import Thread, BoundedSemaphore
from time import sleep
def an_jian(num):
??semapshore.acquire()
??print('第{}个人安检完成!'.format(num))
??sleep(2)
??semapshore.release()
if __name__ == '__main__':
semapshore = BoundedSemaphore(3)
for i in range(20):
????thread = Thread(target=an_jian, args=(i,))
???? thread.start()本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!