向量检索-用最简单的语言
? ? ? ?看之前首先要懂两个基本条件:
? ? ? ? 1. 什么是向量
? ? ? ? 2. 会使用向量的检索
? ? ? ? 3. 知道至少一种向量的索引
这里我们拿比较的流行的HNSW算法来进行分析:
???????最直接的做法是根据向量在给定数据集中采用KNN来找到K个最近的向量。但在实际应用中,待检索的数据往往是千万甚至亿级,KNN的计算量过大。因此,通常采用ANN(Approximate Nearest Neighbor,相似近邻)来快速相似检索
???????????????????????????????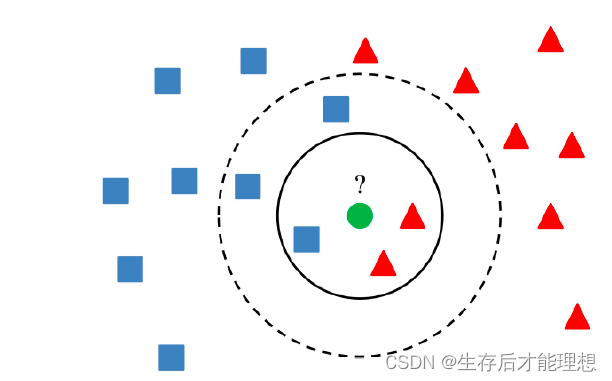
相似性检索:????????
在NSW中,构建图的阶段通过节点的随机插入来引入随机性,构建出一个small world graph,从而实现快速检索。但NSW构造的图并不稳定,节点之间的差异较大:
-
先插入的顶点,其连接的邻居节点,基本都比较远(弱连接属性强)
-
后插入的顶点,其连接的邻居节点,基本都比较近(弱连接属性弱)
-
对于具有聚类效应的点,由于后续插入的点可能都和其建立连接,对应节点的度可能会比较高
如何构造具有更稳定的small world graph呢?HNSW算法就在NSW基础之上引入了分层图的思想,通过对图进行分层,实现由粗到细的检索。
1、图构造
HNSW在构造图时如下图所示:
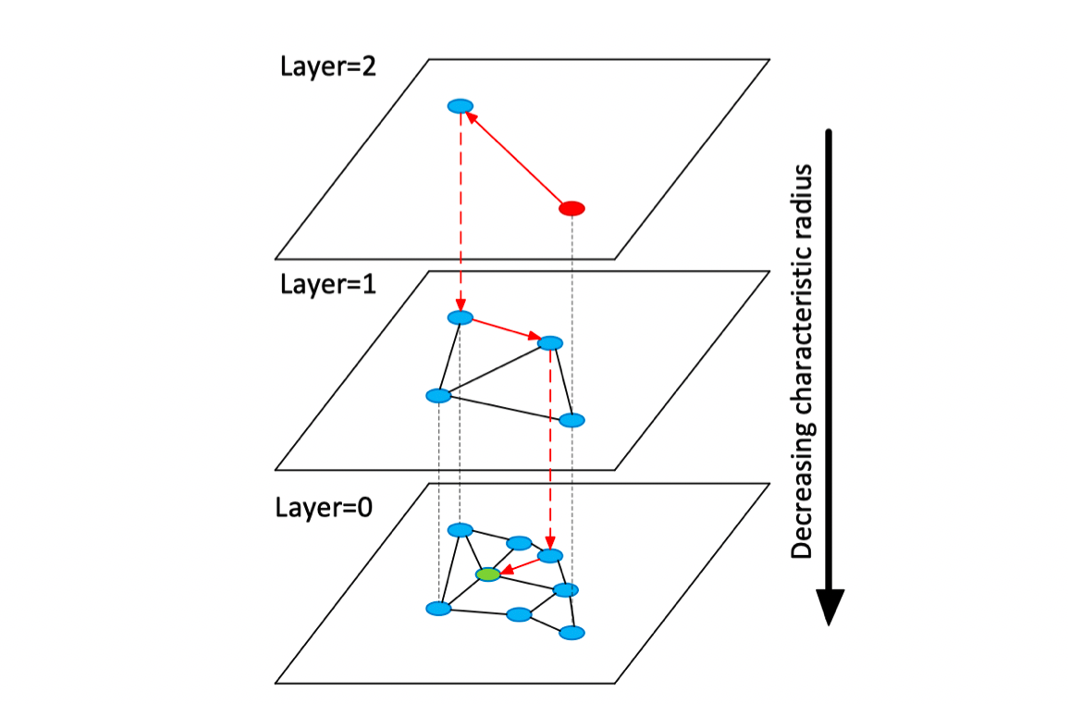
核心如下:
-
layer=0层包含了数据集中的所有点 -
layer=l层是以50%的概率随机从layer=l-1层中选择的点构成的。因此,最大层数为 -
插入构图时,先计算新顶点可以深入到第几层(),在每层的NSW图中查找m个近邻,然后连接它们
2、图检索
对HNSW进行查询时,从最高层开始检索,逐层往下,从而实现快速搜索
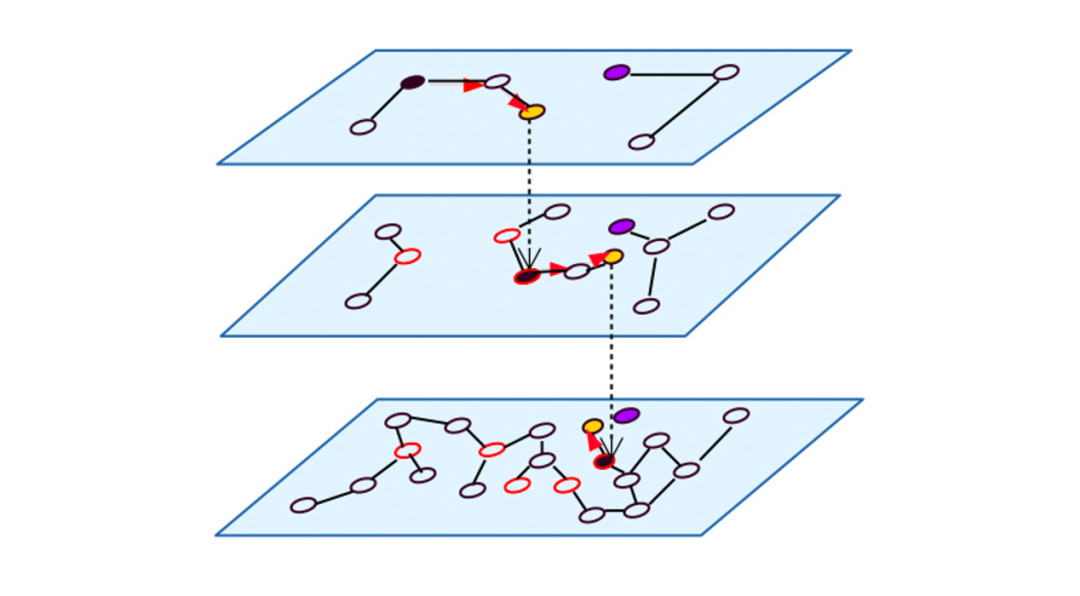
?
总结:想要更高性能的相似性检索需要需要依赖索引,比如HNSW,当我们使用索引检索时它和暴力检索不同的的是:
? ? ? ? 1. 暴力检索会遍历所有节点,然后进行一 一返回
? ? ? ? 2. 使用索引检索时,它返回的是ANN 所有的近邻节点,返回近邻节点的时候它并不会按照从最相似的开始返回,而是将所有近邻结果全部返回,返回之后在进行排序。
? ? ? ? 3. 要返回多少近邻节点是算法中的参数,可以进行调节。当然,也可以返回之后在进行过滤。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 最新微信投票平台系统源码 一键创建各种投票活动 盈利模式强大
- RMI简介
- 1、中级机器学习课程简介
- 蓝桥杯 java 不同子串
- 【无标题】
- PHP||PHP互动与会话技术:GET 和 POST&PHP 会话技术:Cookie 和 Session
- C语言memcpy()函数用法
- 【热学】欧阳欣院士北京大学
- Incorporate Vector-Based Graphics
- Making Large Language Models Perform Better in Knowledge Graph Completion论文阅读