案例系列:便利店销售预测_基于Dart时间序列深度学习模型

文章目录
关键指标
📌 基准:
- 对每个系列应用指数平滑可以生成一个很好的基准预测 - RMSLE: 0.40578
📌 目标:
- 利用大量时间序列通过全局模型使用更复杂、灵活的方法**(Boosted Trees, Neural Networks)**
📌 深度学习模型:
- 本笔记本使用Pytorch通过TS库Darts实现了神经网络模型N-HiTS, LSTM和TFT
📌 最佳模型:
- 33个全局LightGBM模型,每个产品族一个
- 每个模型训练了54个时间序列(对应54个商店)
🏆 -> RMSLE: 0.38558 -> #1 排行榜(2022年9月21日),本笔记本的V24版本
这里发生了什么?
在这个笔记本中,我尝试测试和学习使用机器学习进行时间序列预测的不同方法。我想呈现一个全面的预测工作流程。我的主要重点是探索神经网络模型(如LSTM、NBEATS、TCN、TFT、N-HiTS)。
我基本的理解是:这些复杂而灵活的方法需要大量的数据才能表现良好。对于单个、单变量的时间序列,通常情况下并不是这样,具有更多结构的统计方法往往表现更好。然而,在这里,我们有1782个并行和相关的时间序列 - 54个商店的33个产品类别的销售数据。
我想尝试的方法:
- 全局模型(训练多个时间序列)
- 层次预测(预测协调)
- 集成
- 以上所有方法的组合
我使用 Darts库 进行时间序列建模 - 对于像我这样的初级程序员来说,它简化了工作流程,并且实现了最新的深度学习预测方法。
然而到目前为止,简单的指数平滑基准模型证明优于我的(全局)神经网络模型。基于提升树的全局模型表现良好 - 到目前为止是最好的。但我相信还有很大的优化空间。
1. 库
我在这里使用Darts库进行所有的建模工作。它是一个在Python中进行预测的优秀且直观的选择,特别是对于神经网络模型。开发团队非常乐于助人,并在他们的公共交流渠道上回答问题,所以我强烈推荐这个库用于时间序列预测!
# DARTS预测库
# 安装所需依赖库
!pip install pyyaml==5.4.1
!pip install darts
# 导入所需库
import darts
print(darts.__version__)
# 安装optuna库
!pip install -U optuna==2.0.0
# 导入所需库
import numpy as np
import time
from darts import TimeSeries
from darts.utils.timeseries_generation import gaussian_timeseries, linear_timeseries, sine_timeseries
from darts.models import LightGBMModel, CatBoostModel, Prophet, RNNModel, TFTModel, NaiveSeasonal, ExponentialSmoothing, NHiTSModel
from darts.metrics import mape, smape, rmse, rmsle
from darts.dataprocessing import Pipeline
from darts.dataprocessing.transformers import Scaler, StaticCovariatesTransformer, MissingValuesFiller, InvertibleMapper
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.utils.statistics import check_seasonality, plot_acf, plot_residuals_analysis, plot_hist
from darts.utils.likelihood_models import QuantileRegression
from darts.utils.missing_values import fill_missing_values
from darts.models import MovingAverage
import optuna
from optuna.integration import PyTorchLightningPruningCallback
from optuna.visualization import (
plot_optimization_history,
plot_contour,
plot_param_importances,
)
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from tqdm import tqdm
import sklearn
from sklearn import preprocessing
import pandas as pd
import torch
import matplotlib.pyplot as plt
import gc
%matplotlib inline
torch.manual_seed(1); np.random.seed(1) # 设置随机种子以便复现结果
Collecting pyyaml==5.4.1
Downloading PyYAML-5.4.1-cp37-cp37m-manylinux1_x86_64.whl (636 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m636.6/636.6 kB[0m [31m5.5 MB/s[0m eta [36m0:00:00[0m
[?25hInstalling collected packages: pyyaml
Attempting uninstall: pyyaml
Found existing installation: PyYAML 6.0
Uninstalling PyYAML-6.0:
Successfully uninstalled PyYAML-6.0
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
dask-cudf 21.10.1 requires cupy-cuda114, which is not installed.
pandas-profiling 3.1.0 requires markupsafe~=2.0.1, but you have markupsafe 2.1.1 which is incompatible.
flax 0.6.0 requires rich~=11.1, but you have rich 12.1.0 which is incompatible.
dask-cudf 21.10.1 requires dask==2021.09.1, but you have dask 2022.2.0 which is incompatible.
dask-cudf 21.10.1 requires distributed==2021.09.1, but you have distributed 2022.2.0 which is incompatible.
allennlp 2.10.0 requires protobuf==3.20.0, but you have protobuf 3.19.4 which is incompatible.[0m[31m
[0mSuccessfully installed pyyaml-5.4.1
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mCollecting darts
Downloading darts-0.22.0-py3-none-any.whl (451 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m451.9/451.9 kB[0m [31m4.6 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: scipy>=1.3.2 in /opt/conda/lib/python3.7/site-packages (from darts) (1.7.3)
Requirement already satisfied: scikit-learn>=1.0.1 in /opt/conda/lib/python3.7/site-packages (from darts) (1.0.2)
Requirement already satisfied: numpy>=1.19.0 in /opt/conda/lib/python3.7/site-packages (from darts) (1.21.6)
Requirement already satisfied: catboost>=1.0.6 in /opt/conda/lib/python3.7/site-packages (from darts) (1.0.6)
Requirement already satisfied: requests>=2.22.0 in /opt/conda/lib/python3.7/site-packages (from darts) (2.28.1)
Requirement already satisfied: lightgbm>=2.2.3 in /opt/conda/lib/python3.7/site-packages (from darts) (3.3.2)
Requirement already satisfied: joblib>=0.16.0 in /opt/conda/lib/python3.7/site-packages (from darts) (1.0.1)
Collecting statsforecast>=1.0.0
Downloading statsforecast-1.3.0-py3-none-any.whl (85 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m85.2/85.2 kB[0m [31m8.9 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: torch>=1.8.0 in /opt/conda/lib/python3.7/site-packages (from darts) (1.11.0)
Collecting nfoursid>=1.0.0
Downloading nfoursid-1.0.1-py3-none-any.whl (16 kB)
Requirement already satisfied: pandas>=1.0.5 in /opt/conda/lib/python3.7/site-packages (from darts) (1.3.5)
Requirement already satisfied: xarray>=0.17.0 in /opt/conda/lib/python3.7/site-packages (from darts) (0.20.2)
Collecting tbats>=1.1.0
Downloading tbats-1.1.1-py3-none-any.whl (43 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m43.8/43.8 kB[0m [31m3.5 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: pytorch-lightning>=1.5.0 in /opt/conda/lib/python3.7/site-packages (from darts) (1.7.2)
Requirement already satisfied: tqdm>=4.60.0 in /opt/conda/lib/python3.7/site-packages (from darts) (4.64.0)
Collecting pmdarima>=1.8.0
Downloading pmdarima-2.0.1-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl (1.8 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.8/1.8 MB[0m [31m25.9 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting prophet>=1.1.1
Downloading prophet-1.1.1-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (8.9 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m8.9/8.9 MB[0m [31m63.6 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: shap>=0.40.0 in /opt/conda/lib/python3.7/site-packages (from darts) (0.41.0)
Requirement already satisfied: ipython>=5.0.0 in /opt/conda/lib/python3.7/site-packages (from darts) (7.33.0)
Requirement already satisfied: holidays>=0.11.1 in /opt/conda/lib/python3.7/site-packages (from darts) (0.15)
Requirement already satisfied: statsmodels>=0.13.0 in /opt/conda/lib/python3.7/site-packages (from darts) (0.13.2)
Requirement already satisfied: matplotlib>=3.3.0 in /opt/conda/lib/python3.7/site-packages (from darts) (3.5.3)
Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from catboost>=1.0.6->darts) (1.15.0)
Requirement already satisfied: plotly in /opt/conda/lib/python3.7/site-packages (from catboost>=1.0.6->darts) (5.10.0)
Requirement already satisfied: graphviz in /opt/conda/lib/python3.7/site-packages (from catboost>=1.0.6->darts) (0.8.4)
Requirement already satisfied: hijri-converter in /opt/conda/lib/python3.7/site-packages (from holidays>=0.11.1->darts) (2.2.4)
Requirement already satisfied: korean-lunar-calendar in /opt/conda/lib/python3.7/site-packages (from holidays>=0.11.1->darts) (0.2.1)
Requirement already satisfied: python-dateutil in /opt/conda/lib/python3.7/site-packages (from holidays>=0.11.1->darts) (2.8.2)
Requirement already satisfied: convertdate>=2.3.0 in /opt/conda/lib/python3.7/site-packages (from holidays>=0.11.1->darts) (2.4.0)
Requirement already satisfied: decorator in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (5.1.1)
Requirement already satisfied: jedi>=0.16 in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (0.18.1)
Requirement already satisfied: setuptools>=18.5 in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (59.8.0)
Requirement already satisfied: prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (3.0.30)
Requirement already satisfied: matplotlib-inline in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (0.1.3)
Requirement already satisfied: pickleshare in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (0.7.5)
Requirement already satisfied: traitlets>=4.2 in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (5.3.0)
Requirement already satisfied: backcall in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (0.2.0)
Requirement already satisfied: pexpect>4.3 in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (4.8.0)
Requirement already satisfied: pygments in /opt/conda/lib/python3.7/site-packages (from ipython>=5.0.0->darts) (2.12.0)
Requirement already satisfied: wheel in /opt/conda/lib/python3.7/site-packages (from lightgbm>=2.2.3->darts) (0.37.1)
Requirement already satisfied: pyparsing>=2.2.1 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (3.0.9)
Requirement already satisfied: fonttools>=4.22.0 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (4.33.3)
Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (21.3)
Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (0.11.0)
Requirement already satisfied: pillow>=6.2.0 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (9.1.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.7/site-packages (from matplotlib>=3.3.0->darts) (1.4.3)
Requirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.7/site-packages (from pandas>=1.0.5->darts) (2022.1)
Requirement already satisfied: urllib3 in /opt/conda/lib/python3.7/site-packages (from pmdarima>=1.8.0->darts) (1.26.12)
Requirement already satisfied: Cython!=0.29.18,!=0.29.31,>=0.29 in /opt/conda/lib/python3.7/site-packages (from pmdarima>=1.8.0->darts) (0.29.32)
Requirement already satisfied: setuptools-git>=1.2 in /opt/conda/lib/python3.7/site-packages (from prophet>=1.1.1->darts) (1.2)
Requirement already satisfied: cmdstanpy>=1.0.4 in /opt/conda/lib/python3.7/site-packages (from prophet>=1.1.1->darts) (1.0.4)
Requirement already satisfied: LunarCalendar>=0.0.9 in /opt/conda/lib/python3.7/site-packages (from prophet>=1.1.1->darts) (0.0.9)
Requirement already satisfied: fsspec[http]!=2021.06.0,>=2021.05.0 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (2022.7.1)
Requirement already satisfied: pyDeprecate>=0.3.1 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (0.3.2)
Requirement already satisfied: typing-extensions>=4.0.0 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (4.3.0)
Requirement already satisfied: PyYAML>=5.4 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (5.4.1)
Requirement already satisfied: torchmetrics>=0.7.0 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (0.9.3)
Requirement already satisfied: tensorboard>=2.9.1 in /opt/conda/lib/python3.7/site-packages (from pytorch-lightning>=1.5.0->darts) (2.10.0)
Requirement already satisfied: charset-normalizer<3,>=2 in /opt/conda/lib/python3.7/site-packages (from requests>=2.22.0->darts) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.7/site-packages (from requests>=2.22.0->darts) (2022.6.15)
Requirement already satisfied: idna<4,>=2.5 in /opt/conda/lib/python3.7/site-packages (from requests>=2.22.0->darts) (3.3)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from scikit-learn>=1.0.1->darts) (3.1.0)
Requirement already satisfied: slicer==0.0.7 in /opt/conda/lib/python3.7/site-packages (from shap>=0.40.0->darts) (0.0.7)
Requirement already satisfied: cloudpickle in /opt/conda/lib/python3.7/site-packages (from shap>=0.40.0->darts) (2.1.0)
Requirement already satisfied: numba in /opt/conda/lib/python3.7/site-packages (from shap>=0.40.0->darts) (0.55.2)
Requirement already satisfied: patsy>=0.5.2 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.13.0->darts) (0.5.2)
Requirement already satisfied: importlib-metadata in /opt/conda/lib/python3.7/site-packages (from xarray>=0.17.0->darts) (4.12.0)
Requirement already satisfied: ujson in /opt/conda/lib/python3.7/site-packages (from cmdstanpy>=1.0.4->prophet>=1.1.1->darts) (5.3.0)
Requirement already satisfied: pymeeus<=1,>=0.3.13 in /opt/conda/lib/python3.7/site-packages (from convertdate>=2.3.0->holidays>=0.11.1->darts) (0.5.11)
Requirement already satisfied: aiohttp in /opt/conda/lib/python3.7/site-packages (from fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (3.8.1)
Requirement already satisfied: parso<0.9.0,>=0.8.0 in /opt/conda/lib/python3.7/site-packages (from jedi>=0.16->ipython>=5.0.0->darts) (0.8.3)
Requirement already satisfied: ephem>=3.7.5.3 in /opt/conda/lib/python3.7/site-packages (from LunarCalendar>=0.0.9->prophet>=1.1.1->darts) (4.1.3)
Requirement already satisfied: llvmlite<0.39,>=0.38.0rc1 in /opt/conda/lib/python3.7/site-packages (from numba->shap>=0.40.0->darts) (0.38.1)
Requirement already satisfied: ptyprocess>=0.5 in /opt/conda/lib/python3.7/site-packages (from pexpect>4.3->ipython>=5.0.0->darts) (0.7.0)
Requirement already satisfied: wcwidth in /opt/conda/lib/python3.7/site-packages (from prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0->ipython>=5.0.0->darts) (0.2.5)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (0.4.6)
Requirement already satisfied: markdown>=2.6.8 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (3.3.7)
Requirement already satisfied: werkzeug>=1.0.1 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (2.2.2)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (1.8.1)
Requirement already satisfied: grpcio>=1.24.3 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (1.43.0)
Requirement already satisfied: protobuf<3.20,>=3.9.2 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (3.19.4)
Requirement already satisfied: google-auth<3,>=1.6.3 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (1.35.0)
Requirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (0.6.1)
Requirement already satisfied: absl-py>=0.4 in /opt/conda/lib/python3.7/site-packages (from tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (0.15.0)
Requirement already satisfied: zipp>=0.5 in /opt/conda/lib/python3.7/site-packages (from importlib-metadata->xarray>=0.17.0->darts) (3.8.0)
Requirement already satisfied: tenacity>=6.2.0 in /opt/conda/lib/python3.7/site-packages (from plotly->catboost>=1.0.6->darts) (8.0.1)
Requirement already satisfied: rsa<5,>=3.1.4 in /opt/conda/lib/python3.7/site-packages (from google-auth<3,>=1.6.3->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (4.8)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from google-auth<3,>=1.6.3->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (4.2.4)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /opt/conda/lib/python3.7/site-packages (from google-auth<3,>=1.6.3->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (0.2.7)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /opt/conda/lib/python3.7/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (1.3.1)
Requirement already satisfied: MarkupSafe>=2.1.1 in /opt/conda/lib/python3.7/site-packages (from werkzeug>=1.0.1->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (2.1.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (6.0.2)
Requirement already satisfied: frozenlist>=1.1.1 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (1.3.0)
Requirement already satisfied: asynctest==0.13.0 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (0.13.0)
Requirement already satisfied: yarl<2.0,>=1.0 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (1.7.2)
Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (4.0.2)
Requirement already satisfied: aiosignal>=1.1.2 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (1.2.0)
Requirement already satisfied: attrs>=17.3.0 in /opt/conda/lib/python3.7/site-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning>=1.5.0->darts) (21.4.0)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /opt/conda/lib/python3.7/site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (0.4.8)
Requirement already satisfied: oauthlib>=3.0.0 in /opt/conda/lib/python3.7/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=2.9.1->pytorch-lightning>=1.5.0->darts) (3.2.0)
Installing collected packages: nfoursid, statsforecast, prophet, pmdarima, tbats, darts
Attempting uninstall: prophet
Found existing installation: prophet 1.1
Uninstalling prophet-1.1:
Successfully uninstalled prophet-1.1
Successfully installed darts-0.22.0 nfoursid-1.0.1 pmdarima-2.0.1 prophet-1.1.1 statsforecast-1.3.0 tbats-1.1.1
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m0.22.0
Collecting optuna==2.0.0
Downloading optuna-2.0.0.tar.gz (226 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m226.9/226.9 kB[0m [31m3.2 MB/s[0m eta [36m0:00:00[0m
[?25h Preparing metadata (setup.py) ... [?25l- done
[?25hRequirement already satisfied: alembic in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (1.8.1)
Requirement already satisfied: cliff in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (3.10.1)
Requirement already satisfied: cmaes>=0.5.1 in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (0.8.2)
Requirement already satisfied: colorlog in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (6.6.0)
Requirement already satisfied: joblib in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (1.0.1)
Requirement already satisfied: numpy in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (1.21.6)
Requirement already satisfied: packaging in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (21.3)
Requirement already satisfied: scipy!=1.4.0 in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (1.7.3)
Requirement already satisfied: sqlalchemy>=1.1.0 in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (1.4.39)
Requirement already satisfied: tqdm in /opt/conda/lib/python3.7/site-packages (from optuna==2.0.0) (4.64.0)
Requirement already satisfied: greenlet!=0.4.17 in /opt/conda/lib/python3.7/site-packages (from sqlalchemy>=1.1.0->optuna==2.0.0) (1.1.2)
Requirement already satisfied: importlib-metadata in /opt/conda/lib/python3.7/site-packages (from sqlalchemy>=1.1.0->optuna==2.0.0) (4.12.0)
Requirement already satisfied: Mako in /opt/conda/lib/python3.7/site-packages (from alembic->optuna==2.0.0) (1.2.1)
Requirement already satisfied: importlib-resources in /opt/conda/lib/python3.7/site-packages (from alembic->optuna==2.0.0) (5.8.0)
Requirement already satisfied: PyYAML>=3.12 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (5.4.1)
Requirement already satisfied: stevedore>=2.0.1 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (3.5.0)
Requirement already satisfied: cmd2>=1.0.0 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (2.4.2)
Requirement already satisfied: pbr!=2.1.0,>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (5.10.0)
Requirement already satisfied: pyparsing>=2.1.0 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (3.0.9)
Requirement already satisfied: PrettyTable>=0.7.2 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (3.3.0)
Requirement already satisfied: autopage>=0.4.0 in /opt/conda/lib/python3.7/site-packages (from cliff->optuna==2.0.0) (0.5.1)
Requirement already satisfied: typing-extensions in /opt/conda/lib/python3.7/site-packages (from cmd2>=1.0.0->cliff->optuna==2.0.0) (4.3.0)
Requirement already satisfied: attrs>=16.3.0 in /opt/conda/lib/python3.7/site-packages (from cmd2>=1.0.0->cliff->optuna==2.0.0) (21.4.0)
Requirement already satisfied: wcwidth>=0.1.7 in /opt/conda/lib/python3.7/site-packages (from cmd2>=1.0.0->cliff->optuna==2.0.0) (0.2.5)
Requirement already satisfied: pyperclip>=1.6 in /opt/conda/lib/python3.7/site-packages (from cmd2>=1.0.0->cliff->optuna==2.0.0) (1.8.2)
Requirement already satisfied: zipp>=0.5 in /opt/conda/lib/python3.7/site-packages (from importlib-metadata->sqlalchemy>=1.1.0->optuna==2.0.0) (3.8.0)
Requirement already satisfied: MarkupSafe>=0.9.2 in /opt/conda/lib/python3.7/site-packages (from Mako->alembic->optuna==2.0.0) (2.1.1)
Building wheels for collected packages: optuna
Building wheel for optuna (setup.py) ... [?25l- \ | done
[?25h Created wheel for optuna: filename=optuna-2.0.0-py3-none-any.whl size=312977 sha256=5de6cd631001e876e38b60703e242c8e2eae27b51546131dd83783da6e81f976
Stored in directory: /root/.cache/pip/wheels/22/8b/08/d32553e8cd416e1974ae704d41102b5a691c9612ad982b7991
Successfully built optuna
Installing collected packages: optuna
Attempting uninstall: optuna
Found existing installation: optuna 2.10.1
Uninstalling optuna-2.10.1:
Successfully uninstalled optuna-2.10.1
Successfully installed optuna-2.0.0
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
2. 数据
2.1. 预处理
数据来源:https://www.kaggle.com/competitions/store-sales-time-series-forecasting
现取决于任务的需求和文本的特点。在进行自然语言处理任务之前,进行适当的预处理可以提高模型的性能和准确性。
在加载数据之后,我创建了Darts特定的TimeSeries对象。对于销售数据,我为每个系列生成了所谓的静态协变量(店铺编号、产品系列、城市、地区、类型和集群)。这些协变量可能会在Darts中的某些模型中使用。我还创建了一组基于时间的协变量,如星期几、月份和年份。所有协变量系列都被堆叠在一起。
此外,我将所有系列缩放到0和1之间,然后对它们应用对数变换。我从这个有用的笔记本中得到了这个想法。
# 加载所有数据集
df_train = pd.read_csv('../input/store-sales-time-series-forecasting/train.csv') # 加载训练集
df_test = pd.read_csv('../input/store-sales-time-series-forecasting/test.csv') # 加载测试集
df_holidays_events = pd.read_csv('../input/store-sales-time-series-forecasting/holidays_events.csv') # 加载节假日事件数据集
df_oil = pd.read_csv('../input/store-sales-time-series-forecasting/oil.csv') # 加载油价数据集
df_stores = pd.read_csv('../input/store-sales-time-series-forecasting/stores.csv') # 加载商店数据集
df_transactions = pd.read_csv('../input/store-sales-time-series-forecasting/transactions.csv') # 加载交易数据集
df_sample_submission = pd.read_csv('../input/store-sales-time-series-forecasting/sample_submission.csv') # 加载样本提交数据集
# 销售数据(目标)
family_list = df_train['family'].unique() # 获取唯一的家庭列表
family_list
store_list = df_stores['store_nbr'].unique() # 获取唯一的商店编号列表
store_list
train_merged = pd.merge(df_train, df_stores, on ='store_nbr') # 将训练集和商店数据集按商店编号合并
train_merged = train_merged.sort_values(["store_nbr","family","date"]) # 按商店编号、家庭和日期排序
train_merged = train_merged.astype({"store_nbr":'str', "family":'str', "city":'str',
"state":'str', "type":'str', "cluster":'str'}) # 将商店编号、家庭、城市、州、类型和集群转换为字符串类型
df_test_dropped = df_test.drop(['onpromotion'], axis=1) # 删除测试集中的'onpromotion'列
df_test_sorted = df_test_dropped.sort_values(by=['store_nbr','family']) # 按商店编号和家庭排序
# 创建时间序列对象(Darts)并按产品家族分组存储在字典中
family_TS_dict = {}
for family in family_list:
df_family = train_merged.loc[train_merged['family'] == family] # 选择特定家族的数据
list_of_TS_family = TimeSeries.from_group_dataframe(
df_family,
time_col="date",
group_cols=["store_nbr","family"], # 按商店编号和家庭分组提取单独的时间序列
static_cols=["city","state","type","cluster"], # 还提取这些附加列作为静态协变量
value_cols="sales", # 目标变量
fill_missing_dates=True, # 填充缺失的日期
freq='D') # 频率为每天
for ts in list_of_TS_family:
ts = ts.astype(np.float32) # 将时间序列转换为浮点型
list_of_TS_family = sorted(list_of_TS_family, key=lambda ts: int(ts.static_covariates_values()[0,0])) # 按商店编号排序
family_TS_dict[family] = list_of_TS_family # 将时间序列存储在字典中,键为家族
# 转换销售数据
family_pipeline_dict = {}
family_TS_transformed_dict = {}
for key in family_TS_dict:
train_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs") # 填充缺失值
static_cov_transformer = StaticCovariatesTransformer(verbose=False, transformer_cat = sklearn.preprocessing.OneHotEncoder(), name="Encoder") # 静态协变量转换为独热编码
log_transformer = InvertibleMapper(np.log1p, np.expm1, verbose=False, n_jobs=-1, name="Log-Transform") # 对数转换
train_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaling") # 缩放
train_pipeline = Pipeline([train_filler,
static_cov_transformer,
log_transformer,
train_scaler]) # 创建数据处理流程
training_transformed = train_pipeline.fit_transform(family_TS_dict[key]) # 对时间序列进行转换
family_pipeline_dict[key] = train_pipeline # 存储数据处理流程
family_TS_transformed_dict[key] = training_transformed # 存储转换后的时间序列
# 创建时间序列对象(Darts)
list_of_TS = TimeSeries.from_group_dataframe(
train_merged,
time_col="date",
group_cols=["store_nbr","family"], # 按商店编号和家庭分组提取单独的时间序列
static_cols=["city","state","type","cluster"], # 还提取这些附加列作为静态协变量
value_cols="sales", # 目标变量
fill_missing_dates=True, # 填充缺失的日期
freq='D') # 频率为每天
for ts in list_of_TS:
ts = ts.astype(np.float32) # 将时间序列转换为浮点型
list_of_TS = sorted(list_of_TS, key=lambda ts: int(ts.static_covariates_values()[0,0])) # 按商店编号排序
# 转换销售数据
train_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs") # 填充缺失值
static_cov_transformer = StaticCovariatesTransformer(verbose=False, transformer_cat = sklearn.preprocessing.OneHotEncoder(), name="Encoder") # 静态协变量转换为独热编码
log_transformer = InvertibleMapper(np.log1p, np.expm1, verbose=False, n_jobs=-1, name="Log-Transform") # 对数转换
train_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaling") # 缩放
train_pipeline = Pipeline([train_filler,
static_cov_transformer,
log_transformer,
train_scaler]) # 创建数据处理流程
training_transformed = train_pipeline.fit_transform(list_of_TS) # 对时间序列进行转换
# 创建7天和28天移动平均销售额
sales_moving_average_7 = MovingAverage(window=7) # 创建7天移动平均对象
sales_moving_average_28 = MovingAverage(window=28) # 创建28天移动平均对象
sales_moving_averages_dict = {}
for key in family_TS_transformed_dict:
sales_mas_family = []
for ts in family_TS_transformed_dict[key]:
ma_7 = sales_moving_average_7.filter(ts) # 对时间序列应用7天移动平均
ma_7 = TimeSeries.from_series(ma_7.pd_series()) # 将移动平均结果转换为时间序列
ma_7 = ma_7.astype(np.float32) # 将时间序列转换为浮点型
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="sales_ma_7") # 重命名列
ma_28 = sales_moving_average_28.filter(ts) # 对时间序列应用28天移动平均
ma_28 = TimeSeries.from_series(ma_28.pd_series()) # 将移动平均结果转换为时间序列
ma_28 = ma_28.astype(np.float32) # 将时间序列转换为浮点型
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="sales_ma_28") # 重命名列
mas = ma_7.stack(ma_28) # 将两个移动平均结果堆叠在一起
sales_mas_family.append(mas) # 存储堆叠后的时间序列
sales_moving_averages_dict[key] = sales_mas_family # 存储移动平均结果
# 一般协变量(基于时间和油价)
full_time_period = pd.date_range(start='2013-01-01', end='2017-08-31', freq='D') # 创建完整的时间范围
# 基于时间的协变量
year = datetime_attribute_timeseries(time_index = full_time_period, attribute="year") # 提取年份
month = datetime_attribute_timeseries(time_index = full_time_period, attribute="month") # 提取月份
day = datetime_attribute_timeseries(time_index = full_time_period, attribute="day") # 提取日期
dayofyear = datetime_attribute_timeseries(time_index = full_time_period, attribute="dayofyear") # 提取一年中的第几天
weekday = datetime_attribute_timeseries(time_index = full_time_period, attribute="dayofweek") # 提取星期几
weekofyear = datetime_attribute_timeseries(time_index = full_time_period, attribute="weekofyear") # 提取一年中的第几周
timesteps = TimeSeries.from_times_and_values(times=full_time_period,
values=np.arange(len(full_time_period)),
columns=["linear_increase"]) # 创建线性增长的时间序列
time_cov = year.stack(month).stack(day).stack(dayofyear).stack(weekday).stack(weekofyear).stack(timesteps) # 将所有时间协变量堆叠在一起
time_cov = time_cov.astype(np.float32) # 将时间序列转换为浮点型
# 转换
time_cov_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler") # 缩放
time_cov_train, time_cov_val = time_cov.split_before(pd.Timestamp('20170816')) # 将时间序列分割为训练集和验证集
time_cov_scaler.fit(time_cov_train) # 对训练集进行缩放
time_cov_transformed = time_cov_scaler.transform(time_cov) # 对时间序列进行转换
# 油价
oil = TimeSeries.from_dataframe(df_oil,
time_col = 'date',
value_cols = ['dcoilwtico'],
freq = 'D') # 创建油价时间序列
oil = oil.astype(np.float32) # 将时间序列转换为浮点型
# 转换
oil_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler") # 填充缺失值
oil_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler") # 缩放
oil_pipeline = Pipeline([oil_filler, oil_scaler]) # 创建数据处理流程
oil_transformed = oil_pipeline.fit_transform(oil) # 对油价时间序列进行转换
# 油价的移动平均
oil_moving_average_7 = MovingAverage(window=7) # 创建7天移动平均对象
oil_moving_average_28 = MovingAverage(window=28) # 创建28天移动平均对象
oil_moving_averages = []
ma_7 = oil_moving_average_7.filter(oil_transformed).astype(np.float32) # 对油价时间序列应用7天移动平均
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="oil_ma_7") # 重命名列
ma_28 = oil_moving_average_28.filter(oil_transformed).astype(np.float32) # 对油价时间序列应用28天移动平均
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="oil_ma_28") # 重命名列
oil_moving_averages = ma_7.stack(ma_28) # 将两个移动平均结果堆叠在一起
# 将一般协变量堆叠在一起
general_covariates = time_cov_transformed.stack(oil_transformed).stack(oil_moving_averages) # 将时间协变量、油价和油价的移动平均堆叠在一起
# 商店特定协变量(交易和节假日)
# 交易
df_transactions.sort_values(["store_nbr","date"], inplace=True) # 按商店编号和日期排序
TS_transactions_list = TimeSeries.from_group_dataframe(
df_transactions,
time_col="date",
group_cols=["store_nbr"], # 按商店编号分组提取单独的时间序列
value_cols="transactions", # 协变量
fill_missing_dates=True, # 填充缺失的日期
freq='D') # 频率为每天
transactions_list = []
for ts in TS_transactions_list:
series = TimeSeries.from_series(ts.pd_series()) # 必要的处理以删除静态协变量(以便可以在后面堆叠协变量)
series = series.astype(np.float32) # 将时间序列转换为浮点型
transactions_list.append(series) # 存储时间序列
transactions_list[24] = transactions_list[24].slice(start_ts=pd.Timestamp('20130102'), end_ts=pd.Timestamp('20170815')) # 对时间序列进行切片
from datetime import datetime, timedelta
transactions_list_full = []
for ts in transactions_list:
if ts.start_time() > pd.Timestamp('20130101'):
end_time = (ts.start_time() - timedelta(days=1))
delta = end_time - pd.Timestamp('20130101')
zero_series = TimeSeries.from_times_and_values(
times=pd.date_range(start=pd.Timestamp('20130101'),
end=end_time, freq="D"),
values=np.zeros(delta.days+1))
ts = zero_series.append(ts)
transactions_list_full.append(ts)
transactions_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler") # 填充缺失值
transactions_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler") # 缩放
transactions_pipeline = Pipeline([transactions_filler, transactions_scaler]) # 创建数据处理流程
transactions_transformed = transactions_pipeline.fit_transform(transactions_list_full) # 对交易时间序列进行转换
# 交易的移动平均
trans_moving_average_7 = MovingAverage(window=7) # 创建7天移动平均对象
trans_moving_average_28 = MovingAverage(window=28) # 创建28天移动平均对象
transactions_covs = []
for ts in transactions_transformed:
ma_7 = trans_moving_average_7.filter(ts).astype(np.float32) # 对交易时间序列应用7天移动平均
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="transactions_ma_7") # 重命名列
ma_28 = trans_moving_average_28.filter(ts).astype(np.float32) # 对交易时间序列应用28天移动平均
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="transactions_ma_28") # 重命名列
trans_and_mas = ts.with_columns_renamed(col_names=ts.components, col_names_new="transactions").stack(ma_7).stack(ma_28) # 将交易时间序列和移动平均结果堆叠在一起
transactions_covs.append(trans_and_mas) # 存储堆叠后的时间序列
# 重新定义节假日的类别
df_holidays_events['type'] = np.where(df_holidays_events['transferred'] == True,'Transferred',
df_holidays_events['type']) # 将转让的节假日类型更改为'Transferred'
df_holidays_events['type'] = np.where(df_holidays_events['type'] == 'Transfer','Holiday',
df_holidays_events['type']) # 将'Transfer'类型的节假日更改为'Holiday'
df_holidays_events['type'] = np.where(df_holidays_events['type'] == 'Additional','Holiday',
df_holidays_events['type']) # 将'Additional'类型的节假日更改为'Holiday'
df_holidays_events['type'] = np.where(df_holidays_events['type'] == 'Bridge','Holiday',
df_holidays_events['type']) # 将'Bridge'类型的节假日更改为'Holiday'
# 将节假日分配给所有时间序列并保存在字典中
def holiday_list(df_stores):
listofseries = []
for i in range(0,len(df_stores)):
df_holiday_dummies = pd.DataFrame(columns=['date'])
df_holiday_dummies["date"] = df_holidays_events["date"]
df_holiday_dummies["national_holiday"] = np.where(((df_holidays_events["type"] == "Holiday") & (df_holidays_events["locale"] == "National")), 1, 0) # 判断是否为国家级节假日
df_holiday_dummies["earthquake_relief"] = np.where(df_holidays_events['description'].str.contains('Terremoto Manabi'), 1, 0) # 判断是否为地震救灾日
df_holiday_dummies["christmas"] = np.where(df_holidays_events['description'].str.contains('Navidad'), 1, 0) # 判断是否为圣诞节
df_holiday_dummies["football_event"] = np.where(df_holidays_events['description'].str.contains('futbol'), 1, 0) # 判断是否为足球赛事
df_holiday_dummies["national_event"] = np.where(((df_holidays_events["type"] == "Event") & (df_holidays_events["locale"] == "National") & (~df_holidays_events['description'].str.contains('Terremoto Manabi')) & (~df_holidays_events['description'].str.contains('futbol'))), 1, 0) # 判断是否为国家级活动
df_holiday_dummies["work_day"] = np.where((df_holidays_events["type"] == "Work Day"), 1, 0) # 判断是否为工作日
df_holiday_dummies["local_holiday"] = np.where(((df_holidays_events["type"] == "Holiday") & ((df_holidays_events["locale_name"] == df_stores['state'][i]) | (df_holidays_events["locale_name"] == df_stores['city'][i]))), 1, 0) # 判断是否为地方级节假日
listofseries.append(df_holiday_dummies)
return listofseries
def remove_0_and_duplicates(holiday_list):
listofseries = []
for i in range(0,len(holiday_list)):
df_holiday_per_store = list_of_holidays_per_store[i].set_index('date')
df_holiday_per_store = df_holiday_per_store.loc[~(df_holiday_per_store==0).all(axis=1)] # 删除全为0的行
df_holiday_per_store = df_holiday_per_store.groupby('date').agg({'national_holiday':'max', 'earthquake_relief':'max',
'christmas':'max', 'football_event':'max',
'national_event':'max', 'work_day':'max',
'local_holiday':'max'}).reset_index() # 将相同日期的行合并
listofseries.append(df_holiday_per_store)
return listofseries
def holiday_TS_list_54(holiday_list):
listofseries = []
for i in range(0,54):
holidays_TS = TimeSeries.from_dataframe(list_of_holidays_per_store[i],
time_col = 'date',
fill_missing_dates=True,
fillna_value=0,
freq='D') # 创建节假日时间序列
holidays_TS = holidays_TS.slice(pd.Timestamp('20130101'),pd.Timestamp('20170831')) # 对时间序列进行切片
holidays_TS = holidays_TS.astype(np.float32) # 将时间序列转换为浮点型
listofseries.append(holidays_TS)
return listofseries
list_of_holidays_per_store = holiday_list(df_stores) # 获取每个商店的节假日列表
list_of_holidays_per_store = remove_0_and_duplicates(list_of_holidays_per_store) # 删除全为0的行并合并相同日期的行
list_of_holidays_store = holiday_TS_list_54(list_of_holidays_per_store) # 将节假日列表转换为时间序列
holidays_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Filler") # 填充缺失值
holidays_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaler") # 缩放
holidays_pipeline = Pipeline([holidays_filler, holidays_scaler]) # 创建数据处理流程
holidays_transformed = holidays_pipeline.fit_transform(list_of_holidays_store) # 对节假日时间序列进行转换
# 将商店特定协变量与一般协变量堆叠在一起
store_covariates_future = []
for store in range(0,len(store_list)):
stacked_covariates = holidays_transformed[store].stack(general_covariates) # 将节假日时间序列和一般协变量堆叠在一起
store_covariates_future.append(stacked_covariates) # 存储堆叠后的时间序列
store_covariates_past = []
holidays_transformed_sliced = holidays_transformed # 用于切片过去协变量
for store in range(0,len(store_list)):
holidays_transformed_sliced[store] = holidays_transformed[store].slice_intersect(transactions_covs[store]) # 对节假日时间序列进行切片
general_covariates_sliced = general_covariates.slice_intersect(transactions_covs[store]) # 对一般协变量进行切片
stacked_covariates = transactions_covs[store].stack(holidays_transformed_sliced[store]).stack(general_covariates_sliced) # 将交易时间序列、节假日时间序列和一般协变量堆叠在一起
store_covariates_past.append(stacked_covariates) # 存储堆叠后的时间序列
# 商店/家族特定协变量(促销)
df_promotion = pd.concat([df_train, df_test], axis=0) # 将训练集和测试集合并
df_promotion = df_promotion.sort_values(["store_nbr","family","date"]) # 按商店编号、家族和日期排序
df_promotion.tail()
family_promotion_dict = {}
for family in family_list:
df_family = df_promotion.loc[df_promotion['family'] == family] # 选择特定家族的数据
list_of_TS_promo = TimeSeries.from_group_dataframe(
df_family,
time_col="date",
group_cols=["store_nbr","family"], # 按商店编号和家族分组提取单独的时间序列
value_cols="onpromotion", # 协变量
fill_missing_dates=True, # 填充缺失的日期
freq='D') # 频率为每天
for ts in list_of_TS_promo:
ts = ts.astype(np.float32) # 将时间序列转换为浮点型
family_promotion_dict[family] = list_of_TS_promo # 存储时间序列
promotion_transformed_dict = {}
for key in tqdm(family_promotion_dict):
promo_filler = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs") # 填充缺失值
promo_scaler = Scaler(verbose=False, n_jobs=-1, name="Scaling") # 缩放
promo_pipeline = Pipeline([promo_filler,
promo_scaler])
promotion_transformed = promo_pipeline.fit_transform(family_promotion_dict[key]) # 对时间序列进行转换
# 促销的移动平均
promo_moving_average_7 = MovingAverage(window=7) # 创建7天移动平均对象
promo_moving_average_28 = MovingAverage(window=28) # 创建28天移动平均对象
promotion_covs = []
for ts in promotion_transformed:
ma_7 = promo_moving_average_7.filter(ts) # 对时间序列应用7天移动平均
ma_7 = TimeSeries.from_series(ma_7.pd_series()) # 将移动平均结果转换为时间序列
ma_7 = ma_7.astype(np.float32) # 将时间序列转换为浮点型
ma_7 = ma_7.with_columns_renamed(col_names=ma_7.components, col_names_new="promotion_ma_7") # 重命名列
ma_28 = promo_moving_average_28.filter(ts) # 对时间序列应用28天移动平均
ma_28 = TimeSeries.from_series(ma_28.pd_series()) # 将移动平均结果转换为时间序列
ma_28 = ma_28.astype(np.float32) # 将时间序列转换为浮点型
ma_28 = ma_28.with_columns_renamed(col_names=ma_28.components, col_names_new="promotion_ma_28") # 重命名列
promo_and_mas = ts.stack(ma_7).stack(ma_28) # 将两个移动平均结果堆叠在一起
promotion_covs.append(promo_and_mas) # 存储堆叠后的时间序列
promotion_transformed_dict[key] = promotion_covs # 存储移动平均结果
# 2.5. 将所有协变量组装成字典
past_covariates_dict = {}
for key in tqdm(promotion_transformed_dict):
promotion_family = promotion_transformed_dict[key]
sales_mas = sales_moving_averages_dict[key]
covariates_past = [promotion_family[i].slice_intersect(store_covariates_past[i]).stack(store_covariates_past[i].stack(sales_mas[i])) for i in range(0,len(promotion_family))] # 将促销时间序列、过去协变量和移动平均结果堆叠在一起
past_covariates_dict[key] = covariates_past # 存储堆叠后的时间序列
future_covariates_dict = {}
for key in tqdm(promotion_transformed_dict):
promotion_family = promotion_transformed_dict[key]
covariates_future = [promotion_family[i].stack(store_covariates_future[i]) for i in range(0,len(promotion_family))] # 将促销时间序列和未来协变量堆叠在一起
future_covariates_dict[key] = covariates_future # 存储堆叠后的时间序列
only_past_covariates_dict = {}
for key in tqdm(sales_moving_averages_dict):
sales_moving_averages = sales_moving_averages_dict[key]
only_past_covariates = [sales_moving_averages[i].stack(transactions_covs[i]) for i in range(0,len(sales_moving_averages))] # 将移动平均结果和交易时间序列堆叠在一起
only_past_covariates_dict[key] = only_past_covariates # 存储堆叠后的时间序列
# 删除原始数据集以节省内存
del(df_train)
del(df_test)
del(df_stores)
del(df_holidays_events)
del(df_oil)
del(df_transactions)
gc.collect()
100%|██████████| 33/33 [01:27<00:00, 2.65s/it]
100%|██████████| 33/33 [00:20<00:00, 1.63it/s]
100%|██████████| 33/33 [00:06<00:00, 5.00it/s]
100%|██████████| 33/33 [00:04<00:00, 8.08it/s]
19
2.2. 探索性数据分析
为了给出第一印象,让我们来看一下1782个(商店x产品系列)的时间序列中的一些:
# Some EDA
# 获取'BREAD/BAKERY'类别的第一个TimeSeries
bread_series = family_TS_dict['BREAD/BAKERY'][0]
# 获取'CELEBRATION'类别的第11个TimeSeries
celebration_series = family_TS_dict['CELEBRATION'][11]
# 打印出1782个TimeSeries中的两个
# 创建一个2x2的图表,大小为15x6
plt.subplots(2, 2, figsize=(15, 6))
# 在第1行第1列的位置绘制图像
plt.subplot(1, 2, 1)
# 绘制bread_series的图像,并添加标签,标签内容为bread_series的静态协变量值的一部分
bread_series.plot(label='Sales for {}'.format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
# 绘制celebration_series的图像,并添加标签,标签内容为celebration_series的静态协变量值的一部分
celebration_series.plot(label='Sales for {}'.format(celebration_series.static_covariates_values()[0,1],
celebration_series.static_covariates_values()[0,0],
celebration_series.static_covariates_values()[0,2]))
# 设置标题为"Two Out Of 1782 TimeSeries"
plt.title("Two Out Of 1782 TimeSeries")
# 在第1行第2列的位置绘制图像
plt.subplot(1, 2, 2)
# 绘制bread_series最后365天的图像,并添加标签,标签内容为bread_series的静态协变量值的一部分
bread_series[-365:].plot(label='Sales for {}'.format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
# 绘制celebration_series最后365天的图像,并添加标签,标签内容为celebration_series的静态协变量值的一部分
celebration_series[-365:].plot(label='Sales for {}'.format(celebration_series.static_covariates_values()[0,1],
celebration_series.static_covariates_values()[0,0],
celebration_series.static_covariates_values()[0,2]))
# 设置标题为"Only The Last 365 Days"
plt.title("Only The Last 365 Days")
# 显示图表
plt.show()

让我们还绘制两个系列的自相关图(ACF),并研究季节性模式:
# 绘制面包销量时间序列的自相关图
plot_acf(fill_missing_values(bread_series), m=7, alpha=0.05)
plt.title("{}, store {} in {}".format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
# 绘制庆祝活动时间序列的自相关图
plot_acf(fill_missing_values(celebration_series), alpha=0.05)
plt.title("{}, store {} in {}".format(celebration_series.static_covariates_values()[0,1],
celebration_series.static_covariates_values()[0,0],
celebration_series.static_covariates_values()[0,2]))


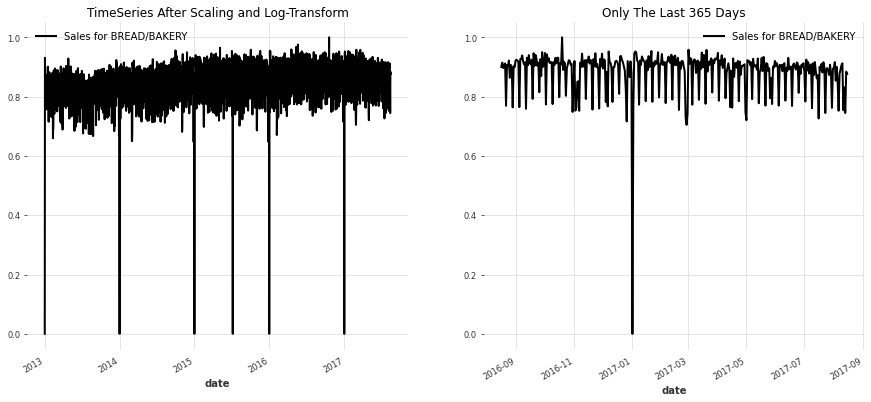
如我们所见,BREAD/BAKERY系列显示出强烈的每周季节性,这是我们所预期的。然而,CELEBRATION系列的季节性模式不太明显。
我对静态协变量进行了编码,并对所有系列应用了0-1缩放+对数转换。静态协变量在时间上不变化 - 我们数据集中的示例是店铺编号或地区。缩放对于许多深度学习模型非常重要,而对训练数据进行对数转换将有助于避免我们的预测低估实际销售额。
# 展示差分后的时间序列
# 首先对示例序列进行转换
# 使用MissingValuesFiller类填充缺失值,不显示详细信息,使用所有可用的CPU核心,命名为"Fill NAs"
train_filler_bread = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs")
# 使用StaticCovariatesTransformer类进行静态协变量转换,不显示详细信息,使用OneHotEncoder进行分类变量转换,命名为"Encoder"
static_cov_transformer_bread = StaticCovariatesTransformer(verbose=False, transformer_cat = sklearn.preprocessing.OneHotEncoder(), name="Encoder")
# 使用InvertibleMapper类进行对数转换,不显示详细信息,使用所有可用的CPU核心,命名为"Log-Transform"
log_transformer_bread = InvertibleMapper(np.log1p, np.expm1, verbose=False, n_jobs=-1, name="Log-Transform")
# 使用Scaler类进行缩放,不显示详细信息,使用所有可用的CPU核心,命名为"Scaling"
train_scaler_bread = Scaler(verbose=False, n_jobs=-1, name="Scaling")
# 使用MissingValuesFiller类填充缺失值,不显示详细信息,使用所有可用的CPU核心,命名为"Fill NAs"
train_filler_celebration = MissingValuesFiller(verbose=False, n_jobs=-1, name="Fill NAs")
# 使用StaticCovariatesTransformer类进行静态协变量转换,不显示详细信息,使用OneHotEncoder进行分类变量转换,命名为"Encoder"
static_cov_transformer_celebration = StaticCovariatesTransformer(verbose=False, transformer_cat = sklearn.preprocessing.OneHotEncoder(), name="Encoder")
# 使用InvertibleMapper类进行对数转换,不显示详细信息,使用所有可用的CPU核心,命名为"Log-Transform"
log_transformer_celebration = InvertibleMapper(np.log1p, np.expm1, verbose=False, n_jobs=-1, name="Log-Transform")
# 使用Scaler类进行缩放,不显示详细信息,使用所有可用的CPU核心,命名为"Scaling"
train_scaler_celebration = Scaler(verbose=False, n_jobs=-1, name="Scaling")
# 创建Pipeline对象,包含填充缺失值、静态协变量转换、对数转换和缩放操作
train_pipeline_bread = Pipeline([train_filler_bread,
static_cov_transformer_bread,
log_transformer_bread,
train_scaler_bread])
train_pipeline_celebration = Pipeline([train_filler_celebration,
static_cov_transformer_celebration,
log_transformer_celebration,
train_scaler_celebration])
# 对面包销售时间序列进行转换
bread_series_transformed = train_pipeline_bread.fit_transform(bread_series)
# 对庆祝活动销售时间序列进行转换
celebration_series_transformed = train_pipeline_celebration.fit_transform(celebration_series)
# 绘图
# 创建2x2的子图,图像大小为15x6
plt.subplots(2, 2, figsize=(15, 6))
# 第一个子图,行1,列2,索引1
plt.subplot(1, 2, 1)
# 绘制面包销售时间序列图,标签为"Sales for {静态协变量值1, 静态协变量值2, 静态协变量值3}"
bread_series_transformed.plot(label='Sales for {}'.format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
plt.title("缩放和对数转换后的时间序列")
# 第二个子图,索引2
plt.subplot(1, 2, 2)
# 绘制最后365天的面包销售时间序列图,标签为"Sales for {静态协变量值1, 静态协变量值2, 静态协变量值3}"
bread_series_transformed[-365:].plot(label='Sales for {}'.format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
plt.title("最后365天")
plt.show()
# 创建2x2的子图,图像大小为15x6
plt.subplots(2, 2, figsize=(15, 6))
# 第一个子图,行1,列2,索引1
plt.subplot(1, 2, 1)
# 绘制庆祝活动销售时间序列图,标签为"Sales for {静态协变量值1, 静态协变量值2, 静态协变量值3}"
celebration_series_transformed.plot(label='Sales for {}'.format(celebration_series.static_covariates_values()[0,1],
celebration_series.static_covariates_values()[0,0],
celebration_series.static_covariates_values()[0,2]))
plt.title("缩放和对数转换后的时间序列")
# 第二个子图,索引2
plt.subplot(1, 2, 2)
# 绘制最后365天的庆祝活动销售时间序列图,标签为"Sales for {静态协变量值1, 静态协变量值2, 静态协变量值3}"
celebration_series_transformed[-365:].plot(label='Sales for {}'.format(celebration_series.static_covariates_values()[0,1],
celebration_series.static_covariates_values()[0,0],
celebration_series.static_covariates_values()[0,2]))
plt.title("最后365天")
plt.show()

协变量
让我们来看看在1号店中BREAD/BAKERY系列过去180天的协变量。
销售移动平均项
# 设置图形大小为10x6
plt.figure(figsize=(10, 6))
# 绘制'BREAD/BAKERY'类别最近180天的销售数据的时间序列图
family_TS_transformed_dict['BREAD/BAKERY'][0][-180:].plot()
# 绘制'BREAD/BAKERY'类别最近180天的销售数据的7日移动平均线图
sales_moving_averages_dict['BREAD/BAKERY'][0][-180:].plot()
# 设置图形标题为"Sales 7- and 28-day Moving Averages"
plt.title("Sales 7- and 28-day Moving Averages")

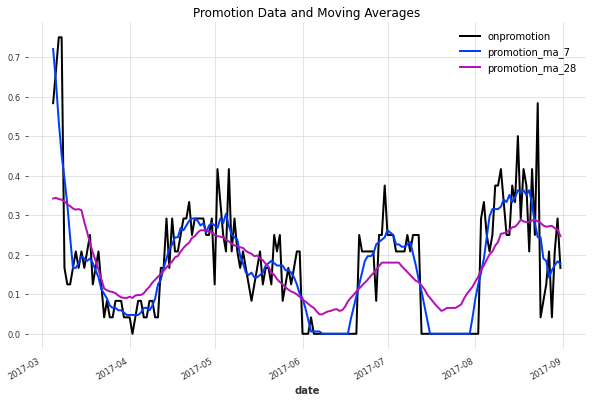
促销数据
# 设置绘图大小
plt.figure(figsize=(10, 6))
# 绘制'BREAD/BAKERY'类别的促销数据的最近180天的折线图
promotion_transformed_dict['BREAD/BAKERY'][0][-180:].plot()
# 设置图表标题
plt.title("促销数据和移动平均值")
交易
# 设置画布大小为10*6
plt.figure(figsize=(10, 6))
# 取出transactions_covs中最后180个数据,并绘制折线图
transactions_covs[0][-180:].plot()
# 设置图表标题为"Transactions Data and Moving Averages"
plt.title("Transactions Data and Moving Averages")
油价
# 设置图形的大小为10x6
plt.figure(figsize=(10, 6))
# 绘制最近180天的原始油价数据
oil_transformed[-180:].plot()
# 绘制最近180天的移动平均线数据
oil_moving_averages[-180:].plot()
# 设置图形的标题为"Oil Price and Moving Averages"
plt.title("Oil Price and Moving Averages")

时间虚拟变量和协变量
# 设置图形的大小为10x6
plt.figure(figsize=(10, 6))
# 绘制时间相关的协变量的最后180个数据点的图形
time_cov_transformed[-180:].plot()
# 设置图形的标题为"时间相关的协变量"
plt.title("Time-Related Covariates")

假期和事件
我按照以下七个类别对可用的假期数据进行了排序。我认为进一步概括这些类别可能会更好。
# 创建一个图形窗口,设置大小为10x6
plt.figure(figsize=(10, 6))
# 获取第一个商店的节假日数据,并排除"date"列
holidays_per_store = list_of_holidays_per_store[0].loc[:, list_of_holidays_per_store[0].columns != "date"]
# 对每个节假日进行求和,并绘制条形图
holidays_per_store.sum().plot.bar(rot=0)
# 设置图表标题为"Holidays and Events"
plt.title("Holidays and Events")

3. 简单基准模型
在考虑神经网络之前,我首先使用传统和更简单的方法建立了一个基准。基准预测性能随后构成了机器学习模型预期性能的下限。我使用了三个简单易实现的模型:
- 朴素季节模型(重复最近的7天)
- 指数平滑
- Facebook Prophet
指数平滑给出了最好的结果。出于计算原因,我在后面注释掉了其他两个模型的训练/评估部分。
3.1. 一些快速回测
让我们快速查看我们大型数据集中两个个体系列的回测(历史预测)。我们从1号店的面包和糕点销售开始——这是我们数据集中更为一致和季节性的系列之一。
# 导入需要的模块和库
from darts.models import NaiveSeasonal, ExponentialSmoothing, Prophet
from darts.timeseries import concatenate
import logging
# 禁用cmdstanpy日志
cmdstanpy_logger = logging.getLogger("cmdstanpy")
cmdstanpy_logger.disabled = True
# 定义三个模型
Naive_Seasonal_Model = NaiveSeasonal(K=7)
Exponential_Smoothing_Model = ExponentialSmoothing()
Prophet_Model = Prophet()
# 定义评估函数,用于评估模型的预测效果
def eval_backtest(backtest_series, actual_series, horizon, transformer, model):
# 将预测结果和实际结果进行反转换,得到真实值
actualdata = transformer.inverse_transform(actual_series, partial=True)
forecasts = transformer.inverse_transform(backtest_series, partial=True)
# 绘制预测结果和实际结果的图像
plt.figure(figsize=(10, 6))
actualdata[-365:].plot(label="Actual Data")
forecasts.plot(label=model)
# 添加图像标题
plt.suptitle("{} in store {} ({})".format(static_cov_transformer_bread.inverse_transform(actual_series).static_covariates_values()[0,1],
static_cov_transformer_bread.inverse_transform(actual_series).static_covariates_values()[0,0],
static_cov_transformer_bread.inverse_transform(actual_series).static_covariates_values()[0,2]))
# 添加图例和标题
plt.legend()
plt.title("Backtest with {}-months horizon, RMSLE = {:.2f}".format(horizon,
rmsle(actual_series=actualdata, pred_series=forecasts)))
# 使用NaiveSeasonal模型进行历史预测
backtest_series_SN = Naive_Seasonal_Model.historical_forecasts(
bread_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
# 使用ExponentialSmoothing模型进行历史预测
backtest_series_ES = Exponential_Smoothing_Model.historical_forecasts(
bread_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
# 使用Prophet模型进行历史预测
backtest_series_Prophet = Prophet_Model.historical_forecasts(
bread_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
# 对三个模型的预测结果进行评估
eval_backtest(
backtest_series=concatenate(backtest_series_SN),
actual_series=bread_series_transformed,
horizon=16,
transformer=train_pipeline_bread,
model="Seasonal Naive (K=7) Forecasts"
)
eval_backtest(
backtest_series=concatenate(backtest_series_ES),
actual_series=bread_series_transformed,
horizon=16,
transformer=train_pipeline_bread,
model="Exponential Smoothing Forecasts"
)
eval_backtest(
backtest_series=concatenate(backtest_series_Prophet),
actual_series=bread_series_transformed,
horizon=16,
transformer=train_pipeline_bread,
model="Facebook Prophet Forecasts"
)


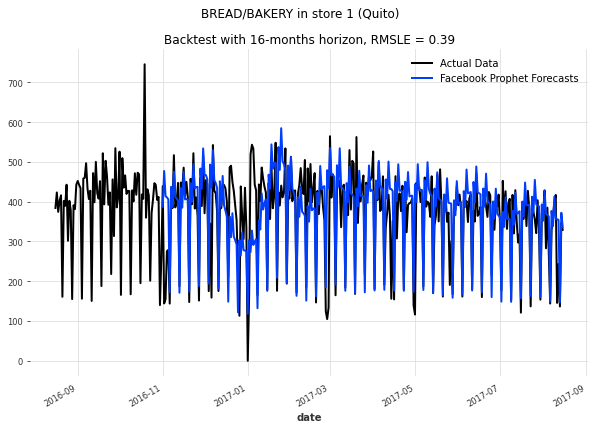
除了2017年圣诞/新年期间的零销售外,该系列遵循非常一致的模式-人们每周都吃面包。所有三个模型都能够相当好地预测这种模式。然而,季节性Naive模型在这个观察到的向下尖峰之后严重失败。
现在让我们看一个更复杂的系列-以19号店的CELEBRATION产品系列为例。尽管这个系列也有季节性模式,但它显示出更多的尖峰。我们的基准模型现在会怎样表现呢?
# 评估回测函数
def eval_backtest(backtest_series, actual_series, horizon, transformer, model):
# 将实际数据进行逆变换
actualdata = transformer.inverse_transform(actual_series, partial=True)
# 将回测数据进行逆变换
forecasts = transformer.inverse_transform(backtest_series, partial=True)
# 绘制图像
plt.figure(figsize=(10, 6))
# 绘制最近365天的实际数据
actualdata[-365:].plot(label="Actual Data")
# 绘制预测数据
forecasts.plot(label=model)
plt.legend()
# 设置图像标题
plt.suptitle("{} in store {} ({})".format(static_cov_transformer_celebration.inverse_transform(actual_series).static_covariates_values()[0,1],
static_cov_transformer_celebration.inverse_transform(actual_series).static_covariates_values()[0,0],
static_cov_transformer_celebration.inverse_transform(actual_series).static_covariates_values()[0,2]))
# 设置子标题
plt.title("Backtest with {}-months horizon, RMSLE = {:.2f}".format(horizon,
rmsle(actual_series=actualdata, pred_series=forecasts)))
# Naive Seasonal Model 回测
backtest_series_SN_2 = Naive_Seasonal_Model.historical_forecasts(
celebration_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
# Exponential Smoothing Model 回测
backtest_series_ES_2 = Exponential_Smoothing_Model.historical_forecasts(
celebration_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
# Prophet Model 回测
backtest_series_Prophet_2 = Prophet_Model.historical_forecasts(
celebration_series_transformed,
start=pd.Timestamp('20161101'),
forecast_horizon=16,
stride=16,
last_points_only=False,
retrain=True,
verbose=False,
)
调用评估回测函数进行评估
eval_backtest(
backtest_series=concatenate(backtest_series_SN_2),
actual_series=celebration_series_transformed,
horizon=16,
transformer=train_pipeline_celebration,
model=“Seasonal Naive (K=7) Forecasts”
)
eval_backtest(
backtest_series=concatenate(backtest_series_ES_2),
actual_series=celebration_series_transformed,
horizon=16,
transformer=train_pipeline_celebration,
model=“Exponential Smoothing Forecasts”
)
eval_backtest(
backtest_series=concatenate(backtest_series_Prophet_2),
actual_series=celebration_series_transformed,
horizon=16,
transformer=train_pipeline_celebration,
model=“Facebook Prophet Forecasts”
)
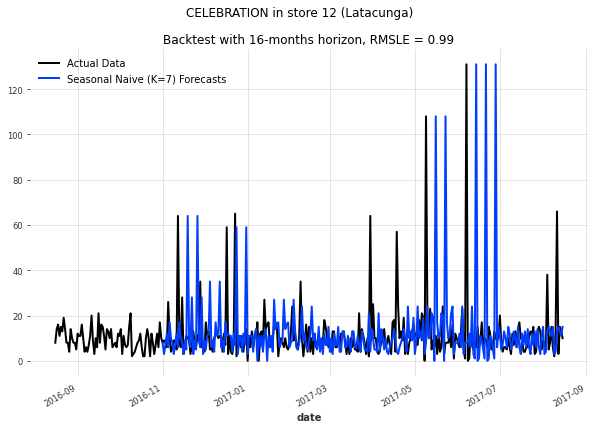
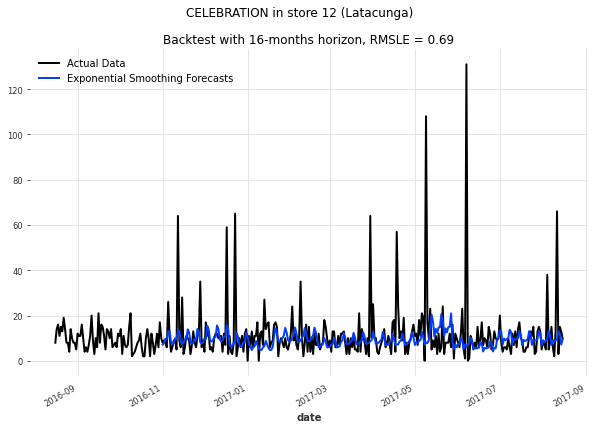

这些预测并不理想 - 预测销售并不那么容易。 "庆祝"产品的销售高峰很可能是由特殊事件引起的。 虽然季节性Naive模型会生成许多错误预测的高峰(并错过大部分实际高峰),指数平滑和Prophet模型可以捕捉到潜在的季节性模式和趋势,但却错过了所有高峰。 根据这些预测,当最需要时,我们的超市将不会提供足够的庆祝商品,从而错过了很多利润。
从这个小实验中,我们已经可以看出好的模型必须既捕捉到产品销售的一般季节性和趋势,又要理解可预测的高峰和其他特殊模式。 例如,由于我们有关于假期的数据,希望在某种程度上可能实现这一点。
<a id="3.2."></a> <br>
# 3.2. 训练/测试分割性能比较
从现在开始,我将使用**简单的训练/测试分割**来评估所有系列的模型 - 预测的时间范围将是**16天**,以模拟排行榜预测任务。虽然滚动窗口验证(如之前的回测)是一种更可靠的方法,但在预测项目的实验阶段中,它将需要太多的计算资源。一旦我们开始训练神经网络模型,这一点将变得明显。
```python
# 展示目标序列的训练集和验证集示例
# 将目标序列的前16个数据作为训练集
training_series_bread = bread_series_transformed[:-16]
# 将目标序列的后16个数据作为验证集
val_series_bread = bread_series_transformed[-16:]
# 创建一个大小为10x6的图像
plt.figure(figsize=(10, 6))
# 绘制训练集最后100个数据的折线图,并标注为"Training"
training_series_bread[-100:].plot(label='Training')
# 绘制验证集的折线图,并标注为"Validation"
val_series_bread.plot(label='Validation')
# 添加图例
plt.legend()
# 设置图像标题,使用目标序列的静态协变量值进行格式化
plt.title("{} in store {} ({})".format(bread_series.static_covariates_values()[0,1],
bread_series.static_covariates_values()[0,0],
bread_series.static_covariates_values()[0,2]))
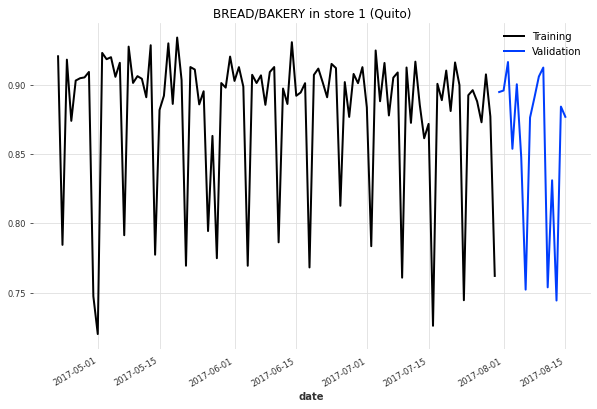
对于我们的基准方法,我们现在训练1782个模型,每个(店铺x产品类别)时间序列一个模型。然后,这些模型生成的预测结果将被转换回原始比例。此外,我们对所有在过去两周内没有销售的系列预测纯零预测(这是一个相对随意的选择)。
# Exponential Smoothing Models and Forecasts
# 定义指数平滑模型构建函数
def ESModelBuilder(training_list):
# 创建一个空列表,用于存储指数平滑模型
listofESmodels = []
# 遍历训练数据列表
for i in range(0,len(training_list)):
# 创建一个指数平滑模型对象
ES_model = ExponentialSmoothing()
# 使用训练数据拟合模型
ES_model.fit(training_list[i])
# 将拟合好的模型添加到列表中
listofESmodels.append(ES_model)
# 返回指数平滑模型列表
return listofESmodels
# 定义指数平滑模型预测函数
def ESForecaster(model_list):
# 创建一个空列表,用于存储预测结果
listofESpreds = []
# 遍历模型列表
for i in range(0,len(model_list)):
# 使用模型进行预测,预测未来16个时间步的值
pred_ES = model_list[i].predict(n=16)
# 将预测结果添加到列表中
listofESpreds.append(pred_ES)
# 返回预测结果列表
return listofESpreds
# 创建指数平滑模型和预测结果的字典
ES_Models_Family_Dict = {}
ES_Forecasts_Family_Dict = {}
# 获取开始时间
st = time.time()
# 遍历家族列表
for family in tqdm(family_list):
# 获取家族的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
# 提取训练数据,去除最后16个时间步
training_data = [ts[:-16] for ts in sales_family]
# 使用训练数据构建指数平滑模型
ES_Models_Family_Dict[family] = ESModelBuilder(training_data)
# 使用指数平滑模型进行预测
forecasts_ES = ESForecaster(ES_Models_Family_Dict[family])
# 反向转换
ES_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_ES, partial=True)
# 零预测
for i in range(0,len(ES_Forecasts_Family_Dict[family])):
# 如果训练数据的最后14个时间步的值都为0
if (training_data[i].univariate_values()[-14:] == 0).all():
# 将预测结果设置为0
ES_Forecasts_Family_Dict[family][i] = ES_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)
# 获取结束时间
et = time.time()
# 计算执行时间
elapsed_time_exp = et - st
100%|██████████| 33/33 [10:53<00:00, 19.79s/it]
# Exponential Smoothing模型和预测的函数
# Naive Seasonal模型的构建函数
def NSModelBuilder(training_list):
# 用于存储Naive Seasonal模型的列表
listofNSmodels = []
# 遍历训练数据列表
for i in range(0,len(training_list)):
# 构建Naive Seasonal模型
NS_model = NaiveSeasonal(K=7)
# 对模型进行拟合
NS_model.fit(training_list[i])
# 将模型添加到列表中
listofNSmodels.append(NS_model)
# 返回模型列表
return listofNSmodels
# Naive Seasonal模型的预测函数
def NSForecaster(model_list):
# 用于存储预测结果的列表
listofNSpreds = []
# 遍历模型列表
for i in range(0,len(model_list)):
# 对模型进行预测
pred_NS = model_list[i].predict(n=16)
# 将预测结果添加到列表中
listofNSpreds.append(pred_NS)
# 返回预测结果列表
return listofNSpreds
# Exponential Smoothing模型的构建函数
def ESModelBuilder(training_list):
# 用于存储Exponential Smoothing模型的列表
listofESmodels = []
# 遍历训练数据列表
for i in range(0,len(training_list)):
# 构建Exponential Smoothing模型
ES_model = ExponentialSmoothing()
# 对模型进行拟合
ES_model.fit(training_list[i])
# 将模型添加到列表中
listofESmodels.append(ES_model)
# 返回模型列表
return listofESmodels
# Exponential Smoothing模型的预测函数
def ESForecaster(model_list):
# 用于存储预测结果的列表
listofESpreds = []
# 遍历模型列表
for i in range(0,len(model_list)):
# 对模型进行预测
pred_ES = model_list[i].predict(n=16)
# 将预测结果添加到列表中
listofESpreds.append(pred_ES)
# 返回预测结果列表
return listofESpreds
# Prophet模型的构建函数
def ProphetModelBuilder(training_list):
# 用于存储Prophet模型的列表
listofPmodels = []
# 遍历训练数据列表
for i in range(0,len(training_list)):
# 构建Prophet模型
P_model = Prophet()
# 对模型进行拟合
P_model.fit(training_list[i])
# 将模型添加到列表中
listofPmodels.append(P_model)
# 返回模型列表
return listofPmodels
# Prophet模型的预测函数
def ProphetForecaster(model_list):
# 用于存储预测结果的列表
listofPpreds = []
# 遍历模型列表
for i in range(0,len(model_list)):
# 对模型进行预测
pred_P = model_list[i].predict(n=16)
# 将预测结果添加到列表中
listofPpreds.append(pred_P)
# 返回预测结果列表
return listofPpreds
# Exponential Smoothing模型的训练和预测
# 用于存储Naive Seasonal模型的字典
NS_Models_Family_Dict = {}
# 用于存储Naive Seasonal模型预测结果的字典
NS_Forecasts_Family_Dict = {}
# 用于存储Exponential Smoothing模型的字典
ES_Models_Family_Dict = {}
# 用于存储Exponential Smoothing模型预测结果的字典
ES_Forecasts_Family_Dict = {}
# 用于存储Prophet模型的字典
Prophet_Models_Family_Dict = {}
# 用于存储Prophet模型预测结果的字典
Prophet_Forecasts_Family_Dict = {}
# 导入所需的库
import time
from multiprocessing import Pool
# 遍历family_list列表
for family in tqdm(family_list):
# 获取该family的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
# 获取训练数据
training_data = [ts[:-16] for ts in sales_family]
# 构建Naive Seasonal模型
NS_Models_Family_Dict[family] = NSModelBuilder(training_data)
# 对模型进行预测
forecasts_NS = NSForecaster(NS_Models_Family_Dict[family])
# 将预测结果进行反转换
NS_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_NS, partial=True)
# 进行零预测
for i in range(0,len(NS_Forecasts_Family_Dict[family])):
if (training_data[i].univariate_values()[-21:] == 0).all():
NS_Forecasts_Family_Dict[family][i] = NS_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)
for family in tqdm(family_list):
# 获取该family的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
# 获取训练数据
training_data = [ts[:-16] for ts in sales_family]
# 构建Exponential Smoothing模型
ES_Models_Family_Dict[family] = ESModelBuilder(training_data)
# 对模型进行预测
forecasts_ES = ESForecaster(ES_Models_Family_Dict[family])
# 将预测结果进行反转换
ES_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_ES, partial=True)
# 进行零预测
for i in range(0,len(ES_Forecasts_Family_Dict[family])):
if (training_data[i].univariate_values()[-21:] == 0).all():
ES_Forecasts_Family_Dict[family][i] = ES_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)
# 由于计算时间较长,此处注释掉
# for family in tqdm(family_list):
# # 获取该family的销售时间序列数据
# sales_family = family_TS_transformed_dict[family]
# # 获取训练数据
# training_data = [ts[:-16] for ts in sales_family]
# # 构建Prophet模型
# Prophet_Models_Family_Dict[family] = ProphetModelBuilder(training_data)
# # 对模型进行预测
# forecasts_Prophet = ProphetForecaster(Prophet_Models_Family_Dict[family])
# # 将预测结果进行反转换
# Prophet_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_Prophet, partial=True)
# # 进行零预测
# for i in range(0,len(Prophet_Forecasts_Family_Dict[family])):
# if (training_data[i].univariate_values()[-21:] == 0).all():
# Prophet_Forecasts_Family_Dict[family][i] = Prophet_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)
'\n# Functions for Exponential Smoothing Models and Forecasts\n\ndef NSModelBuilder(training_list):\n\n listofNSmodels = []\n\n for i in range(0,len(training_list)):\n NS_model = NaiveSeasonal(K=7)\n NS_model.fit(training_list[i])\n listofNSmodels.append(NS_model)\n\n return listofNSmodels \n\ndef NSForecaster(model_list):\n\n listofNSpreds = []\n\n for i in range(0,len(model_list)):\n pred_NS = model_list[i].predict(n=16)\n listofNSpreds.append(pred_NS) \n\n return listofNSpreds \n\ndef ESModelBuilder(training_list):\n\n listofESmodels = []\n\n for i in range(0,len(training_list)):\n ES_model = ExponentialSmoothing()\n ES_model.fit(training_list[i])\n listofESmodels.append(ES_model)\n\n return listofESmodels \n\ndef ESForecaster(model_list):\n\n listofESpreds = []\n\n for i in range(0,len(model_list)):\n pred_ES = model_list[i].predict(n=16)\n listofESpreds.append(pred_ES) \n\n return listofESpreds \n\ndef ProphetModelBuilder(training_list):\n\n listofPmodels = []\n\n for i in range(0,len(training_list)):\n P_model = Prophet()\n P_model.fit(training_list[i])\n listofPmodels.append(P_model)\n\n return listofPmodels \n\ndef ProphetForecaster(model_list):\n\n listofPpreds = []\n\n for i in range(0,len(model_list)):\n pred_P = model_list[i].predict(n=16)\n listofPpreds.append(pred_P) \n\n return listofPpreds \n\n# Train and Forecast with Exponential Smoothing Models\n\nNS_Models_Family_Dict = {}\nNS_Forecasts_Family_Dict = {}\nES_Models_Family_Dict = {}\nES_Forecasts_Family_Dict = {}\nProphet_Models_Family_Dict = {}\nProphet_Forecasts_Family_Dict = {}\n\nimport time\nfrom multiprocessing import Pool\n\nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts[:-16] for ts in sales_family]\n\n NS_Models_Family_Dict[family] = NSModelBuilder(training_data)\n forecasts_NS = NSForecaster(NS_Models_Family_Dict[family])\n \n # Transform Back\n NS_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_NS, partial=True)\n\n # Zero Forecasting\n for i in range(0,len(NS_Forecasts_Family_Dict[family])):\n if (training_data[i].univariate_values()[-21:] == 0).all():\n NS_Forecasts_Family_Dict[family][i] = NS_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)\n \n \nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts[:-16] for ts in sales_family]\n\n ES_Models_Family_Dict[family] = ESModelBuilder(training_data)\n forecasts_ES = ESForecaster(ES_Models_Family_Dict[family])\n \n # Transform Back\n ES_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_ES, partial=True)\n\n # Zero Forecasting\n for i in range(0,len(ES_Forecasts_Family_Dict[family])):\n if (training_data[i].univariate_values()[-21:] == 0).all():\n ES_Forecasts_Family_Dict[family][i] = ES_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)\n \n # commented out due to long computation\n\nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts[:-16] for ts in sales_family]\n\n Prophet_Models_Family_Dict[family] = ProphetModelBuilder(training_data)\n forecasts_Prophet = ProphetForecaster(Prophet_Models_Family_Dict[family])\n \n # Transform Back\n Prophet_Forecasts_Family_Dict[family] = family_pipeline_dict[family].inverse_transform(forecasts_Prophet, partial=True)\n\n # Zero Forecasting\n for i in range(0,len(Prophet_Forecasts_Family_Dict[family])):\n if (training_data[i].univariate_values()[-21:] == 0).all():\n Prophet_Forecasts_Family_Dict[family][i] = Prophet_Forecasts_Family_Dict[family][i].map(lambda x: x * 0)\n '
让我们来检查一下我们创建的16天验证集上的RMSLE得分:
# Re-Format Forecasts from Dictionaries to One List
# 创建一个空列表 forecast_list_ES
forecast_list_ES = []
# 遍历 family_list 中的每个元素 family
for family in family_list:
# 将 ES_Forecasts_Family_Dict 字典中 family 对应的值添加到 forecast_list_ES 列表中
forecast_list_ES.append(ES_Forecasts_Family_Dict[family])
# 创建一个空列表 sales_data
sales_data = []
# 遍历 family_list 中的每个元素 family
for family in family_list:
# 将 family_TS_dict 字典中 family 对应的值添加到 sales_data 列表中
sales_data.append(family_TS_dict[family])
# Function to Flatten Nested Lists
# 定义一个函数 flatten,用于将嵌套列表展开为一维列表
def flatten(l):
# 使用列表推导式将嵌套列表展开为一维列表
return [item for sublist in l for item in sublist]
# 将 sales_data 列表展开为一维列表,赋值给 actual_list
actual_list = flatten(sales_data)
# 将 forecast_list_ES 列表展开为一维列表,赋值给 pred_list_ES
pred_list_ES = flatten(forecast_list_ES)
# Mean RMSLE
# 使用 rmsle 函数计算 actual_list 和 pred_list_ES 的均值 RMSLE,将结果赋值给 ES_rmsle
ES_rmsle = rmsle(actual_series=actual_list,
pred_series=pred_list_ES,
n_jobs=-1,
inter_reduction=np.mean)
# 打印输出结果
print("\n")
print("The mean RMSLE for the Local Exponential Smoothing Models over 1782 series is {:.5f}.".format(ES_rmsle))
print('Training & Inference duration:', elapsed_time_exp, 'seconds')
print("\n")
The mean RMSLE for the Local Exponential Smoothing Models over 1782 series is 0.37411.
Training & Inference duration: 653.0645875930786 seconds
# Re-Format Forecasts from Dictionaries to One List
# 创建一个空列表 forecast_list_NS
forecast_list_NS = []
# 遍历 family_list 列表中的每一个元素
for family in tqdm(family_list):
# 将 NS_Forecasts_Family_Dict 字典中对应 family 键的值添加到 forecast_list_NS 列表中
forecast_list_NS.append(NS_Forecasts_Family_Dict[family])
# 创建一个空列表 forecast_list_ES
forecast_list_ES = []
# 遍历 family_list 列表中的每一个元素
for family in tqdm(family_list):
# 将 ES_Forecasts_Family_Dict 字典中对应 family 键的值添加到 forecast_list_ES 列表中
forecast_list_ES.append(ES_Forecasts_Family_Dict[family])
# 创建一个空列表 sales_data
sales_data = []
# 遍历 family_list 列表中的每一个元素
for family in tqdm(family_list):
# 将 family_TS_dict 字典中对应 family 键的值添加到 sales_data 列表中
sales_data.append(family_TS_dict[family])
# 定义一个函数 flatten,用于将嵌套列表展开为一维列表
def flatten(l):
# 使用列表推导式将嵌套列表展开为一维列表
return [item for sublist in l for item in sublist]
# 将 sales_data 列表展开为一维列表,并赋值给 actual_list
actual_list = flatten(sales_data)
# 将 forecast_list_NS 列表展开为一维列表,并赋值给 pred_list_NS
pred_list_NS = flatten(forecast_list_NS)
# 将 forecast_list_ES 列表展开为一维列表,并赋值给 pred_list_ES
pred_list_ES = flatten(forecast_list_ES)
# Mean RMSLE
# 调用 rmsle 函数计算 actual_list 和 pred_list_NS 的 RMSLE 值,使用 np.mean 进行内部归约,将结果赋值给 NS_rmsle
NS_rmsle = rmsle(actual_series = actual_list,
pred_series = pred_list_NS,
n_jobs = -1,
inter_reduction=np.mean)
# 调用 rmsle 函数计算 actual_list 和 pred_list_ES 的 RMSLE 值,使用 np.mean 进行内部归约,将结果赋值给 ES_rmsle
ES_rmsle = rmsle(actual_series = actual_list,
pred_series = pred_list_ES,
n_jobs = -1,
inter_reduction=np.mean)
# 打印 Naive Seasonal (K=7) Model 的平均 RMSLE 值
print("The mean RMSLE for the Naive Seasonal (K=7) Model over all 1782 series is {:.5f}.".format(NS_rmsle))
print("\n")
# 打印 Exponential Smoothing 的平均 RMSLE 值
print("The mean RMSLE for Exponential Smoothing over all 1782 series is {:.5f}.".format(ES_rmsle))
print("\n")
'\n# Mean RMSLE\n\nNS_rmsle = rmsle(actual_series = actual_list,\n pred_series = pred_list_NS,\n n_jobs = -1,\n inter_reduction=np.mean)\n\nES_rmsle = rmsle(actual_series = actual_list,\n pred_series = pred_list_ES,\n n_jobs = -1,\n inter_reduction=np.mean)\n\n#Prophet_rmsle = rmsle(actual_series = actual_list,\n# pred_series = pred_list_Prophet,\n# n_jobs = -1,\n# inter_reduction=np.mean)\n\nprint("The mean RMSLE for the Naive Seasonal (K=7) Model over all 1782 series is {:.5f}.".format(NS_rmsle))\nprint("\n")\nprint("The mean RMSLE for Exponential Smoothing over all 1782 series is {:.5f}.".format(ES_rmsle))\nprint("\n")\n#print("The mean RMSLE for Prophet over all 1782 series is {:.5f}.".format(Prophet_rmsle))\n'
指数平滑法在我们的验证数据中取得了最小的误差(RMSLE = 0.37411)!
为了进一步研究这些模型的性能,让我们打印出每个产品类别的平均RMSLE:
# Mean RMSLE for Families
# 创建一个空字典用于存储每个家庭的预测RMSLE值
family_forecast_rmsle_ES = {}
# 遍历家庭列表
for family in family_list:
# 计算家庭实际时间序列和预测时间序列的RMSLE值
ES_rmsle_family = rmsle(actual_series = family_TS_dict[family],
pred_series = ES_Forecasts_Family_Dict[family],
n_jobs = -1,
inter_reduction=np.mean)
# 将家庭和对应的RMSLE值添加到字典中
family_forecast_rmsle_ES[family] = ES_rmsle_family
# 按照RMSLE值对字典进行排序
family_forecast_rmsle_ES = dict(sorted(family_forecast_rmsle_ES.items(), key=lambda item: item[1]))
# 打印结果标题
print("\n")
print("Mean RMSLE for the 33 different product families, from worst to best:")
print("\n")
# 遍历字典中的键/值对并打印它们
for key, value in family_forecast_rmsle_ES.items():
print(key, ' : ', value)
Mean RMSLE for the 33 different product families, from worst to best:
BOOKS : 0.02651197503458817
PRODUCE : 0.16843766125266366
DAIRY : 0.17848655145201983
BABY CARE : 0.18114626716417453
BREAD/BAKERY : 0.18897676415105819
DELI : 0.2066933250933373
GROCERY I : 0.2127276035335266
POULTRY : 0.21482292812599496
MEATS : 0.21491541089879915
BEVERAGES : 0.2473325661277561
PREPARED FOODS : 0.264123423522481
PERSONAL CARE : 0.2664165041230439
HOME APPLIANCES : 0.26717466516377136
EGGS : 0.2776606798514665
FROZEN FOODS : 0.2784342567353302
HOME CARE : 0.3332755628285514
CLEANING : 0.3497135935068673
LAWN AND GARDEN : 0.3534249305533779
LIQUOR,WINE,BEER : 0.42864824751226854
LADIESWEAR : 0.44249147647648795
PLAYERS AND ELECTRONICS : 0.4470152310152792
SEAFOOD : 0.4648584971121303
PET SUPPLIES : 0.46642742684488553
HOME AND KITCHEN II : 0.47475863290616677
HOME AND KITCHEN I : 0.49530259318248976
AUTOMOTIVE : 0.5076609042415264
HARDWARE : 0.511367753289844
MAGAZINES : 0.5339185188412147
CELEBRATION : 0.5348196982287526
BEAUTY : 0.5420208134871055
GROCERY II : 0.6049866249277764
LINGERIE : 0.6661096176342214
SCHOOL AND OFFICE SUPPLIES : 0.9951124074306023
我还绘制了生成的三个最差的预测 - 也许我们可以从中学到一些东西:
# 绘制五个最差的预测结果
errorlist = [] # 创建一个空列表用于存储错误值
# 遍历actual_list中的每个元素
for i in range(0, len(actual_list)):
# 计算RMSLE错误值
error = rmsle(actual_series = actual_list[i],
pred_series = pred_list_ES[i])
# 获取当前actual_list元素的静态协变量值
errorfam = actual_list[i].static_covariates_values()[0,1]
# 将错误值和静态协变量值添加到errorlist列表中
errorlist.append([errorfam,error])
# 创建一个名为rmsle_series_ES的DataFrame,列名为'family'和'RMSLE',数据为errorlist中的值
rmsle_series_ES = pd.DataFrame(errorlist,columns=['family','RMSLE'])
# 对rmsle_series_ES按'RMSLE'列进行降序排序,并取前3个最大值
worst_3_ES = rmsle_series_ES.sort_values(by=['RMSLE'], ascending=False).head(3)
# 创建一个包含worst_3_ES个数个子图的图表,大小为(20, 5)
fig,axs = plt.subplots(1,len(worst_3_ES),figsize=(20, 5))
# 定义标签列表
labels = ["actual data", "ES forecast"]
# 遍历worst_3_ES中的每个元素
for i in range(0, len(worst_3_ES)):
# 获取ES预测结果和实际数据
plt_forecast = pred_list_ES[(worst_3_ES.index[i])]
plt_actual = actual_list[(worst_3_ES.index[i])]
# 计算当前预测结果和实际数据的RMSLE错误值
plt_err = rmsle(plt_actual, plt_forecast)
# 获取当前子图
axis = axs[i]
# 在当前子图上绘制实际数据的最后100个数据点
plt_actual[-100:].plot(ax=axis, label="actual data")
# 在当前子图上绘制ES预测结果
plt_forecast.plot(ax=axis, label="ES forecast")
# 在当前子图上添加图例,位置为左上角
axis.legend(loc="upper left")
# 设置当前子图的标题,包括静态协变量值、店铺编号和时间戳,以及RMSLE错误值
axis.title.set_text("{} in store {} ({}) \n RMSLE: {}".format(plt_forecast.static_covariates_values()[0,1],
plt_forecast.static_covariates_values()[0,0],
plt_forecast.static_covariates_values()[0,2],
plt_err))

显然,学校终于开始了;)那些预测非常糟糕,但是指数平滑模型无法预测像这样的销售突然飙升。我的希望是使用更具信息的模型,如神经网络模型,使用协变量捕捉这种(在这种情况下可能是月/周特定的)模式。
4. 全局建模
现在我们已经建立了一个坚实的基准,我们能改进我们的预测吗?我对时间序列预测的当前理解是这样的:
当处理小数据集和少量维度时,花哨/复杂的模型(我在说你,神经网络)不会带来太多好处,甚至可能没有好处。我经常发现简单的统计模型表现更好。
直观地说,这是有道理的:神经网络是高度复杂的非线性模型,不对手头的数据施加任何结构。另一方面,ARIMA、指数平滑或Prophet等统计方法涉及大量固定结构,并且不像神经网络或提升树模型那样灵活。但是,当建模一个只有几百个数据点的单变量时间序列时,我们不需要这么多的灵活性-我们的数据中没有足够的信号来建模高度复杂的关系。当涉及捕捉季节性和趋势等基本模式时,统计方法做得很好。
然而,手头的店铺销售数据包括1782个相当长的时间序列,包括一组相关的协变量(如假期和产品促销)。这意味着应该有一些信号可以利用机器学习模型。我预计(大部分)这1782个系列在某种程度上是相似/相关的,因为它们都涉及店铺销售,应该遵循共同的模式。那么现在怎么办呢?
**全局模型!**我的计划是利用神经网络和提升模型的力量,尽可能地利用我们庞大数据集中的信号。而局部模型(如我们的指数平滑基准)是在一个时间序列上训练的,全局模型是在多个序列上训练的。
我们现在将介绍三种不同的深度学习模型:
- LSTM(长短期记忆)
- N-HiTS(用于时间序列预测的神经层次插值)
- TFT(时间融合变压器)
LSTM模型(1995年)已经存在一段时间了,而TFT(2019年)和N-HiTS(2022年)是相对较新的模型。我选择了这三个神经网络模型,是因为它们在利用协变量方面有不同的方式。
LSTM是一种循环神经网络(RNN),它期望协变量延伸到未来,直到预测的时间范围。在Darts框架中,这些被称为future_covariates。N-HiTS类似于N-BEATS模型,但可能在计算方面具有优势。该模型只能接受past_covariates,即在生成预测时已知的过去时间点的协变量。最后,TFT模型支持past_covariates、future_covariates以及static_covariates。
计算问题
重要的是,为了使计算可行,以下模型都是使用完整时间序列的小子集进行训练(请参阅代码中的参数max_samples_per_ts)。我认为Kaggle GPU处理更大的数据速度不够快。因此,以下模型不应被视为最佳模型,而应作为最简示例。
CatBoost使用每个系列的最后365个样本(输入+输出长度)进行训练,N-HiTS使用最后180个样本进行训练,LSTM使用最后60个样本进行训练,TFT仅使用每个系列的最后7个样本进行训练。我选择这些数字是为了在进行一些实验后大致均衡这些模型的训练时间。
4.1. N-HiTS

来源: https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fimages.deepai.org%2Fconverted-papers%2F2201.12886%2Fx4.png&pos_id=img-EdVKganz-1704333436129)
任务:请翻译以下markdown为中文,请保留markdown的格式,并输出翻译结果。
语料:
N-HiTS only supports past_covariates. As I still want to use the future-known information on promotion, holidays and time dummies, I shift back those covariates 16 days to the past. I define a function for training the model and then create an Optuna study, which I let run for 5 trials on the relatively slow Kaggle GPU. That is not a lot and will likely not deliver very good hyperparameters, but suffices as an example.
翻译结果:
N-HiTS只支持past_covariates。由于我仍然想要使用关于促销、假期和时间虚拟变量的未来已知信息,我将这些协变量向过去推移16天。我定义了一个用于训练模型的函数,然后创建了一个Optuna研究,我让它在相对较慢的Kaggle GPU上运行5次试验。这并不多,可能无法得到非常好的超参数,但足以作为一个示例。
# Data Preparation for N-HiTS
# 定义一个函数flatten,用于将嵌套列表展开为一维列表
def flatten(l):
return [item for sublist in l for item in sublist]
# 初始化一个空列表future_covariates_full,用于存储未来协变量
future_covariates_full = []
# 遍历family_list中的每个family
for family in family_list:
# 将future_covariates_dict中对应family的协变量添加到future_covariates_full列表中
future_covariates_full.append(future_covariates_dict[family])
# 将future_covariates_full列表展开为一维列表
future_covariates_full = flatten(future_covariates_full)
# 初始化一个空列表only_past_covariates,用于存储过去协变量
only_past_covariates = []
# 遍历family_list中的每个family
for family in family_list:
# 将only_past_covariates_dict中对应family的协变量添加到only_past_covariates列表中
only_past_covariates.append(only_past_covariates_dict[family])
# 将only_past_covariates列表展开为一维列表
only_past_covariates = flatten(only_past_covariates)
# 初始化一个空列表NHiTS_covariates,用于存储N-HiTS协变量
NHiTS_covariates = []
# 遍历future_covariates_full列表中的每个元素
for i in range(0,len(future_covariates_full)):
# 将当前元素向后移动16个位置
shifted = future_covariates_full[i].shift(n=-16)
# 取shifted和only_past_covariates[i]的交集
cut = shifted.slice_intersect(only_past_covariates[i])
# 将cut和only_past_covariates[i]进行堆叠
stacked = cut.stack(only_past_covariates[i])
# 将堆叠后的结果添加到NHiTS_covariates列表中
NHiTS_covariates.append(stacked)
# 将训练数据划分为训练集、验证集和测试集
# 定义验证集的长度为16
val_len = 16
# 将训练数据的前部分去除后2倍验证集长度的部分作为训练集
train = [s[: -(2 * val_len)] for s in training_transformed]
# 将训练数据的后部分去除后2倍验证集长度到验证集长度的部分作为验证集
val = [s[-(2 * val_len) : -val_len] for s in training_transformed]
# 将训练数据的后部分验证集长度的部分作为测试集
test = [s[-val_len:] for s in training_transformed]
"""
我们编写一个函数来构建和拟合一个N-HiTS模型,以便以后重复使用。
参数:
- input_chunk_length: 输入时间序列的长度
- num_stacks: 模型中堆叠的块的数量
- num_blocks: 每个堆叠中块的数量
- num_layers: 每个块中的层数
- layer_exp: 每个块中层的宽度的指数
- dropout: 模型中的dropout率
- lr: 模型的学习率
- likelihood: 模型的似然函数
- callbacks: 训练过程中的回调函数列表
- max_samples: 每个时间序列的最大样本数
"""
def build_fit_nhits_model(
input_chunk_length,
num_stacks,
num_blocks,
num_layers,
layer_exp,
dropout,
lr,
likelihood=None,
callbacks=None,
#max_samples=None
):
# 设置随机种子以保证结果的可重复性
torch.manual_seed(42)
# 一些固定的参数,对于所有模型都是相同的
MAX_N_EPOCHS = 50
MAX_SAMPLES_PER_TS = 180
# 在训练过程中,我们将监控验证集的损失以进行早停
early_stopper = EarlyStopping("val_loss", min_delta=0.0001, patience=2, verbose=True)
if callbacks is None:
callbacks = [early_stopper]
else:
callbacks = [early_stopper] + callbacks
# 检测是否有可用的GPU
if torch.cuda.is_available():
pl_trainer_kwargs = {
"accelerator": "gpu",
"gpus": 1,
"auto_select_gpus": True,
"callbacks": callbacks,
}
num_workers = 2
else:
pl_trainer_kwargs = {"callbacks": callbacks}
num_workers = 0
# 构建N-HiTS模型
model = NHiTSModel(
input_chunk_length=input_chunk_length,
output_chunk_length=16,
num_stacks=num_stacks,
num_blocks=num_blocks,
num_layers=num_layers,
layer_widths=2 ** layer_exp,
dropout=dropout,
n_epochs=MAX_N_EPOCHS,
batch_size=128,
add_encoders=None,
likelihood=None,
loss_fn=torch.nn.MSELoss(),
random_state=42,
optimizer_kwargs={"lr": lr},
pl_trainer_kwargs=pl_trainer_kwargs,
model_name="nhits_model",
force_reset=True,
save_checkpoints=True,
)
# 在训练过程中进行验证时,我们可以使用稍长一些的验证集,其中包含前input_chunk_length个时间步长
model_val_set = [s[-((2 * val_len) + input_chunk_length) : -val_len] for s in training_transformed]
# 训练模型
model.fit(
series=train,
val_series=model_val_set,
past_covariates=NHiTS_covariates,
val_past_covariates=NHiTS_covariates,
max_samples_per_ts=MAX_SAMPLES_PER_TS,
num_loader_workers=num_workers,
)
# 在训练过程中重新加载最佳模型
model = NHiTSModel.load_from_checkpoint("nhits_model")
return model
# Hyperparameter Tuning with Optuna
# 定义目标函数,用于优化
def objective(trial):
# 设置回调函数,用于在训练过程中进行剪枝
callback = [PyTorchLightningPruningCallback(trial, monitor="val_loss")]
# 设置输入数据的时间长度,范围在21到365天之间
input_chunk_length = trial.suggest_int("input_chunk_length", 63, 270)
# 其他超参数
num_stacks = trial.suggest_int("num_stacks", 1, 3)
num_blocks = trial.suggest_int("num_blocks", 1, 3)
num_layers = trial.suggest_int("num_layers", 1, 3)
layer_exp = trial.suggest_int("layer_exp", 7, 10)
#layer_widths = 2 ** layer_exp
dropout = trial.suggest_float("dropout", 0.01, 0.2, step=0.01)
lr = trial.suggest_float("lr", 5e-5, 0.1, log=True)
# 使用这些超参数构建并训练N-HiTS模型
model = build_fit_nhits_model(
input_chunk_length=input_chunk_length,
num_stacks=num_stacks,
num_blocks=num_blocks,
num_layers=num_layers,
layer_exp=layer_exp,
dropout=dropout,
lr=lr,
likelihood=None,
callbacks=callback,
#max_samples=365
)
# 在验证集上评估模型的性能
preds = model.predict(series=train, past_covariates=NHiTS_covariates, n=val_len)
rmsles = rmsle(val, preds, n_jobs=-1, verbose=True)
rmsle_val = np.mean(rmsles)
# 返回RMSLE值,如果RMSLE值为NaN,则返回无穷大
return rmsle_val if rmsle_val != np.nan else float("inf")
# 定义回调函数,用于打印当前的值和参数以及最佳的值和参数
def print_callback(study, trial):
print(f"Current value: {trial.value}, Current params: {trial.params}")
print(f"Best value: {study.best_value}, Best params: {study.best_trial.params}")
# 清空GPU缓存
torch.cuda.empty_cache()
# 创建一个Optuna的Study对象,用于存储和管理优化过程中的信息
study_nhits = optuna.create_study(direction="minimize")
# 使用Optuna进行超参数优化
study_nhits.optimize(objective, n_trials=5, callbacks=[print_callback])
# 打印最佳的值和参数
print(f"Best value: {study_nhits.best_value}, Best params: {study_nhits.best_trial.params}")
[32m[I 2022-11-17 01:53:07,429][0m A new study created in memory with name: no-name-5c2552b2-b320-4ff4-bfc9-d357fc0dfefc[0m
/opt/conda/lib/python3.7/site-packages/torch/random.py:111: UserWarning: CUDA reports that you have 2 available devices, and you have used fork_rng without explicitly specifying which devices are being used. For safety, we initialize *every* CUDA device by default, which can be quite slow if you have a lot of GPUs. If you know that you are only making use of a few CUDA devices, set the environment variable CUDA_VISIBLE_DEVICES or the 'devices' keyword argument of fork_rng with the set of devices you are actually using. For example, if you are using CPU only, set CUDA_VISIBLE_DEVICES= or devices=[]; if you are using GPU 0 only, set CUDA_VISIBLE_DEVICES=0 or devices=[0]. To initialize all devices and suppress this warning, set the 'devices' keyword argument to `range(torch.cuda.device_count())`.
).format(num_devices=num_devices, caller=_caller, devices_kw=_devices_kw))
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
f"Setting `Trainer(gpus={gpus!r})` is deprecated in v1.7 and will be removed"
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:286: LightningDeprecationWarning: The `Callback.on_epoch_end` hook was deprecated in v1.6 and will be removed in v1.8. Please use `Callback.on_<train/validation/test>_epoch_end` instead.
f"The `Callback.{hook}` hook was deprecated in v1.6 and"
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 0 is already reported.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 1 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 2 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 3 is already reported.
Predicting: 0it [00:00, ?it/s]
0%| | 0/1782 [00:00<?, ?it/s]
[32m[I 2022-11-17 02:09:37,702][0m Trial 0 finished with value: 0.06768599688497698 and parameters: {'input_chunk_length': 181, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 9, 'dropout': 0.14, 'lr': 0.010078784588065512}. Best is trial 0 with value: 0.06768599688497698.[0m
Current value: 0.06768599688497698, Current params: {'input_chunk_length': 181, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 9, 'dropout': 0.14, 'lr': 0.010078784588065512}
Best value: 0.06768599688497698, Best params: {'input_chunk_length': 181, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 9, 'dropout': 0.14, 'lr': 0.010078784588065512}
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
f"Setting `Trainer(gpus={gpus!r})` is deprecated in v1.7 and will be removed"
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:286: LightningDeprecationWarning: The `Callback.on_epoch_end` hook was deprecated in v1.6 and will be removed in v1.8. Please use `Callback.on_<train/validation/test>_epoch_end` instead.
f"The `Callback.{hook}` hook was deprecated in v1.6 and"
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 0 is already reported.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 1 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 2 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 3 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 4 is already reported.
Predicting: 0it [00:00, ?it/s]
0%| | 0/1782 [00:00<?, ?it/s]
[32m[I 2022-11-17 02:30:14,519][0m Trial 1 finished with value: 0.07773928345327351 and parameters: {'input_chunk_length': 190, 'num_stacks': 3, 'num_blocks': 1, 'num_layers': 3, 'layer_exp': 8, 'dropout': 0.13, 'lr': 0.004889729367858116}. Best is trial 0 with value: 0.06768599688497698.[0m
Current value: 0.07773928345327351, Current params: {'input_chunk_length': 190, 'num_stacks': 3, 'num_blocks': 1, 'num_layers': 3, 'layer_exp': 8, 'dropout': 0.13, 'lr': 0.004889729367858116}
Best value: 0.06768599688497698, Best params: {'input_chunk_length': 181, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 9, 'dropout': 0.14, 'lr': 0.010078784588065512}
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
f"Setting `Trainer(gpus={gpus!r})` is deprecated in v1.7 and will be removed"
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:286: LightningDeprecationWarning: The `Callback.on_epoch_end` hook was deprecated in v1.6 and will be removed in v1.8. Please use `Callback.on_<train/validation/test>_epoch_end` instead.
f"The `Callback.{hook}` hook was deprecated in v1.6 and"
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 0 is already reported.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 1 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 2 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 3 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 4 is already reported.
Predicting: 0it [00:00, ?it/s]
0%| | 0/1782 [00:00<?, ?it/s]
[32m[I 2022-11-17 02:58:50,845][0m Trial 2 finished with value: 0.06323797155681068 and parameters: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}. Best is trial 2 with value: 0.06323797155681068.[0m
Current value: 0.06323797155681068, Current params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
Best value: 0.06323797155681068, Best params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
f"Setting `Trainer(gpus={gpus!r})` is deprecated in v1.7 and will be removed"
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:286: LightningDeprecationWarning: The `Callback.on_epoch_end` hook was deprecated in v1.6 and will be removed in v1.8. Please use `Callback.on_<train/validation/test>_epoch_end` instead.
f"The `Callback.{hook}` hook was deprecated in v1.6 and"
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 0 is already reported.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 1 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 2 is already reported.
Predicting: 0it [00:00, ?it/s]
0%| | 0/1782 [00:00<?, ?it/s]
[32m[I 2022-11-17 03:15:41,498][0m Trial 3 finished with value: 0.10835513633253573 and parameters: {'input_chunk_length': 268, 'num_stacks': 2, 'num_blocks': 1, 'num_layers': 3, 'layer_exp': 10, 'dropout': 0.14, 'lr': 0.004136010167916462}. Best is trial 2 with value: 0.06323797155681068.[0m
Current value: 0.10835513633253573, Current params: {'input_chunk_length': 268, 'num_stacks': 2, 'num_blocks': 1, 'num_layers': 3, 'layer_exp': 10, 'dropout': 0.14, 'lr': 0.004136010167916462}
Best value: 0.06323797155681068, Best params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
f"Setting `Trainer(gpus={gpus!r})` is deprecated in v1.7 and will be removed"
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/configuration_validator.py:286: LightningDeprecationWarning: The `Callback.on_epoch_end` hook was deprecated in v1.6 and will be removed in v1.8. Please use `Callback.on_<train/validation/test>_epoch_end` instead.
f"The `Callback.{hook}` hook was deprecated in v1.6 and"
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 0 is already reported.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 1 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 2 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 3 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 4 is already reported.
Validation: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/optuna/trial/_trial.py:592: UserWarning: The reported value is ignored because this `step` 5 is already reported.
Predicting: 0it [00:00, ?it/s]
0%| | 0/1782 [00:00<?, ?it/s]
[32m[I 2022-11-17 03:42:26,509][0m Trial 4 finished with value: 0.1885274393627962 and parameters: {'input_chunk_length': 268, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 1, 'layer_exp': 10, 'dropout': 0.03, 'lr': 0.05155994337933316}. Best is trial 2 with value: 0.06323797155681068.[0m
Current value: 0.1885274393627962, Current params: {'input_chunk_length': 268, 'num_stacks': 1, 'num_blocks': 3, 'num_layers': 1, 'layer_exp': 10, 'dropout': 0.03, 'lr': 0.05155994337933316}
Best value: 0.06323797155681068, Best params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
Best value: 0.06323797155681068, Best params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
所以这些是找到的最佳超参数:
# 输出最佳数值和最佳超参数:
print(f"Best value: {study_nhits.best_value}, Best params: {study_nhits.best_trial.params}")
Best value: 0.06323797155681068, Best params: {'input_chunk_length': 266, 'num_stacks': 3, 'num_blocks': 3, 'num_layers': 2, 'layer_exp': 8, 'dropout': 0.01, 'lr': 0.002996870143374216}
让我们来看一下调优过程:
在调试试验中改进错误得分
plot_optimization_history(study_nhits)
var gd = document.getElementById(‘5ffc3537-6e6d-407e-8246-83c04dec8e50’);
var x = new MutationObserver(function (mutations, observer) {{
var display = window.getComputedStyle(gd).display;
if (!display || display === ‘none’) {{
console.log([gd, ‘removed!’]);
Plotly.purge(gd);
observer.disconnect();
}}
}});
// Listen for the removal of the full notebook cells
var notebookContainer = gd.closest(‘#notebook-container’);
if (notebookContainer) {{
x.observe(notebookContainer, {childList: true});
}}
// Listen for the clearing of the current output cell
var outputEl = gd.closest(‘.output’);
if (outputEl) {{
x.observe(outputEl, {childList: true});
}}
}) }; }); </script> </div>
超参数重要性在调优试验中的作用
# 导入绘图库
import matplotlib.pyplot as plt
def plot_param_importances(study_nhits):
"""
绘制参数重要性图表
参数:
- study_nhits: 学习结果的命中次数
返回值:
无返回值
"""
# 获取参数名称和重要性
param_names = study_nhits.keys()
param_importances = study_nhits.values()
# 创建一个水平条形图
plt.barh(param_names, param_importances)
# 添加标题和标签
plt.title("Parameter Importances")
plt.xlabel("Importance")
plt.ylabel("Parameter")
# 显示图表
plt.show()
var gd = document.getElementById(‘34218726-666c-4a4d-878c-57c9a11004d9’);
var x = new MutationObserver(function (mutations, observer) {{
var display = window.getComputedStyle(gd).display;
if (!display || display === ‘none’) {{
console.log([gd, ‘removed!’]);
Plotly.purge(gd);
observer.disconnect();
}}
}});
// Listen for the removal of the full notebook cells
var notebookContainer = gd.closest(‘#notebook-container’);
if (notebookContainer) {{
x.observe(notebookContainer, {childList: true});
}}
// Listen for the clearing of the current output cell
var outputEl = gd.closest(‘.output’);
if (outputEl) {{
x.observe(outputEl, {childList: true});
}}
}) }; }); </script> </div>
超参数搜索空间和相应的错误分数
# 导入必要的库
import matplotlib.pyplot as plt
import numpy as np
def plot_contour(study, params):
"""
绘制轮廓图函数
参数:
study (optuna.study.Study): Optuna Study对象,包含了试验的历史信息。
params (list): 需要绘制轮廓图的参数列表。
返回:
None
"""
# 获取参数的取值范围
param_values = [trial.params[param] for trial in study.trials for param in params]
# 获取目标函数的取值
values = [trial.value for trial in study.trials]
# 将参数和目标函数的取值转换为numpy数组
param_values = np.array(param_values)
values = np.array(values)
# 绘制轮廓图
plt.figure(figsize=(8, 6))
plt.scatter(param_values[:, 0], param_values[:, 1], c=values)
plt.xlabel(params[0])
plt.ylabel(params[1])
plt.colorbar()
plt.show()
var gd = document.getElementById(‘788c599b-d426-49b5-b0f6-71c13d47e46e’);
var x = new MutationObserver(function (mutations, observer) {{
var display = window.getComputedStyle(gd).display;
if (!display || display === ‘none’) {{
console.log([gd, ‘removed!’]);
Plotly.purge(gd);
observer.disconnect();
}}
}});
// Listen for the removal of the full notebook cells
var notebookContainer = gd.closest(‘#notebook-container’);
if (notebookContainer) {{
x.observe(notebookContainer, {childList: true});
}}
// Listen for the clearing of the current output cell
var outputEl = gd.closest(‘.output’);
if (outputEl) {{
x.observe(outputEl, {childList: true});
}}
}) }; }); </script> </div>
使用我们在这个短暂的调整会话中得到的超参数,现在我们训练N-HiTS模型并对测试集进行预测。
# 获取最佳试验参数
nhits_params = study_nhits.best_trial.params
# 获取开始时间
st = time.time()
# 构建并拟合NHiTS模型
NHiTS_Model = build_fit_nhits_model(**nhits_params)
# 为测试数据生成预测
training_data = [ts[:-16] for ts in training_transformed]
preds = NHiTS_Model.predict(series=training_data, past_covariates=NHiTS_covariates, n=val_len)
# 反向转换
forecasts_back = train_pipeline.inverse_transform(preds, partial=True)
# 零预测
for n in range(0,len(forecasts_back)):
if (list_of_TS[n][:-16].univariate_values()[-14:] == 0).all():
forecasts_back[n] = forecasts_back[n].map(lambda x: x * 0)
# 获取结束时间
et = time.time()
# 获取执行时间
elapsed_time_nhits = et - st
# 平均RMSLE
NHiTS_rmsle = rmsle(actual_series = list_of_TS,
pred_series = forecasts_back,
n_jobs = -1,
inter_reduction=np.mean)
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning:
Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
Sanity Checking: 0it [00:00, ?it/s]
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py:682: UserWarning:
Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool1d in a future release.
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Predicting: 0it [00:00, ?it/s]
# 输出一个空行
print("\n")
# 输出全局N-HiTS模型在1782个序列上的平均RMSLE值,保留小数点后5位
print("The mean RMSLE for the Global N-HiTS Model over 1782 series is {:.5f}.".format(NHiTS_rmsle))
# 输出训练和推断的时间,单位为秒
print('Training & Inference duration:', elapsed_time_nhits, 'seconds')
# 输出一个空行
print("\n")
The mean RMSLE for the Global N-HiTS Model over 1782 series is 0.43265.
Training & Inference duration: 1102.850519657135 seconds
4.2. LSTM
4.2. LSTM
LSTM只支持未来已知的协变量。为了利用我们仅有的过去已知协变量(销售和交易数据),我将它们向前推移16天。虽然这种方法可能不是最优的,但我发现它比完全舍弃这些协变量要好。
微调后,我得到了以下LSTM的超参数:
- 输入块长度:131
- 隐藏维度:39
- RNN层数:3
- 学习率:0.0019971227090605087
让我们使用所有的数据来训练这个模型,并对16天的测试集进行预测!
# 数据准备用于LSTM
def flatten(l):
return [item for sublist in l for item in sublist] # 将嵌套的列表展平为一维列表的函数
future_covariates_full = [] # 存储所有家族的未来协变量的列表
for family in family_list: # 遍历家族列表
future_covariates_full.append(future_covariates_dict[family]) # 将每个家族的未来协变量添加到列表中
future_covariates_full = flatten(future_covariates_full) # 将未来协变量列表展平为一维列表
# 将过去的协变量向前移动,以便可以将其用作未来的协变量
only_past_covariates = [] # 存储所有家族的仅过去协变量的列表
for family in family_list: # 遍历家族列表
only_past_covariates.append(only_past_covariates_dict[family]) # 将每个家族的仅过去协变量添加到列表中
only_past_covariates = flatten(only_past_covariates) # 将仅过去协变量列表展平为一维列表
LSTM_covariates = [] # 存储LSTM协变量的列表
for i in range(0,len(only_past_covariates)): # 遍历仅过去协变量列表的索引
shifted = only_past_covariates[i].shift(n=16) # 将过去协变量向前移动16个时间步
cut = future_covariates_full[i].slice_intersect(shifted) # 将未来协变量和移动后的过去协变量进行交集操作
stacked = cut.stack(shifted) # 将交集后的协变量堆叠起来
LSTM_covariates.append(stacked) # 将堆叠后的协变量添加到LSTM协变量列表中
# 在移动后对目标和协变量进行交集操作
LSTM_target = [] # 存储LSTM目标的列表
for i in range(0, len(training_transformed)): # 遍历训练数据转换后的列表的索引
sliced = training_transformed[i].slice_intersect(LSTM_covariates[i]) # 将转换后的数据和LSTM协变量进行交集操作
LSTM_target.append(sliced) # 将交集后的数据添加到LSTM目标列表中
# 将数据分为训练集/验证集/测试集用于调优和验证
val_len = 16 # 验证集长度
LSTM_train = [s[: -(2 * val_len)] for s in LSTM_target] # 训练集为目标数据的前面部分(去除后面两个验证集长度)
LSTM_val = [s[-(2 * val_len) : -val_len] for s in LSTM_target] # 验证集为目标数据的中间部分(长度为两个验证集长度)
LSTM_test = [s[-val_len:] for s in LSTM_target] # 测试集为目标数据的后面部分(长度为一个验证集长度)
"""
我们编写一个函数来构建和拟合一个TCN模型,以便以后重复使用。
参数:
- input_chunk_length: 输入序列的长度
- hidden_dim: 隐藏层的维度
- n_rnn_layers: RNN层的数量
- lr: 学习率
- likelihood: 模型的似然函数
- callbacks: 回调函数列表
返回:
- model: 训练好的模型
"""
def build_fit_lstm_model(
input_chunk_length,
hidden_dim,
n_rnn_layers,
lr,
likelihood=None,
callbacks=None,
):
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 一些固定的参数,对于所有模型都是相同的
MAX_N_EPOCHS = 100
MAX_SAMPLES_PER_TS = 60
# 在训练过程中,我们将监控验证集的损失以进行早停
early_stopper = EarlyStopping("val_loss", min_delta=0.0001, patience=2, verbose=True)
if callbacks is None:
callbacks = [early_stopper]
else:
callbacks = [early_stopper] + callbacks
# 检测是否有可用的GPU
if torch.cuda.is_available():
pl_trainer_kwargs = {
"accelerator": "gpu",
"gpus": 1,
"auto_select_gpus": True,
"callbacks": callbacks,
}
num_workers = 2
else:
pl_trainer_kwargs = {"callbacks": callbacks}
num_workers = 0
# 构建LSTM模型
model = RNNModel(
model="LSTM",
input_chunk_length=input_chunk_length,
hidden_dim=hidden_dim,
n_rnn_layers=n_rnn_layers,
dropout=0,
training_length=input_chunk_length + val_len -1,
n_epochs=MAX_N_EPOCHS,
batch_size=128,
add_encoders=None,
likelihood=None,
loss_fn=torch.nn.MSELoss(),
random_state=42,
optimizer_kwargs={"lr": lr},
pl_trainer_kwargs=pl_trainer_kwargs,
model_name="lstm_model",
force_reset=True,
save_checkpoints=True,
)
# 在训练过程中进行验证时,我们可以使用稍长一些的验证集,其中包含前input_chunk_length个时间步长
model_val_set = [s[-((2 * val_len) + input_chunk_length) : -val_len] for s in LSTM_target]
# 训练模型
model.fit(
series=LSTM_train,
val_series=model_val_set,
future_covariates=LSTM_covariates,
val_future_covariates=LSTM_covariates,
max_samples_per_ts=MAX_SAMPLES_PER_TS,
num_loader_workers=num_workers,
)
# 在训练过程中重新加载最佳模型
model = RNNModel.load_from_checkpoint("lstm_model")
return model
# 清空GPU缓存
torch.cuda.empty_cache()
# 获取开始时间
st = time.time()
# 构建并训练LSTM模型
LSTM_Model = build_fit_lstm_model(**lstm_params)
# 对测试数据进行预测
# 先将LSTM_target中的最后16个时间步去掉,作为训练数据
training_data = [ts[:-16] for ts in LSTM_target]
# 使用LSTM_Model对训练数据进行预测,同时使用LSTM_covariates作为未来协变量
preds = LSTM_Model.predict(series=training_data, future_covariates=LSTM_covariates, n=val_len)
# 将预测结果转换回原始数据的尺度
forecasts_back = train_pipeline.inverse_transform(preds, partial=True)
# 对于预测结果中,历史数据的最后14个时间步全为0的情况,将预测结果设为0
for n in range(0,len(forecasts_back)):
if (LSTM_target[n][:-16].univariate_values()[-14:] == 0).all():
forecasts_back[n] = forecasts_back[n].map(lambda x: x * 0)
# 获取结束时间
et = time.time()
# 计算LSTM模型的执行时间
elapsed_time_lstm = et - st
# 计算预测结果的均方根对数误差
LSTM_rmsle = rmsle(actual_series = list_of_TS,
pred_series = forecasts_back,
n_jobs = -1,
inter_reduction=np.mean)
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning:
Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
Sanity Checking: 0it [00:00, ?it/s]
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Predicting: 0it [00:00, ?it/s]
# 输出一个空行
print("\n")
# 输出全局LSTM模型在1782个序列上的平均RMSLE值,保留小数点后5位
print("The mean RMSLE for the Global LSTM Model over 1782 series is {:.5f}.".format(LSTM_rmsle))
# 输出训练和推理的时间,单位为秒
print('Training & Inference duration:', elapsed_time_lstm, 'seconds')
# 输出一个空行
print("\n")
The mean RMSLE for the Global LSTM Model over 1782 series is 0.55443.
Training & Inference duration: 1438.0281417369843 seconds
4.3. TFT
TFT(Thin Film Transistor)是一种液晶显示技术,它使用薄膜晶体管来控制每个像素的亮度和颜色。TFT显示屏通常具有更高的分辨率和更好的色彩表现力,因此在许多应用中得到广泛应用,例如电视、电脑显示器和智能手机等。
TFT显示屏的优点包括高分辨率、高对比度、快速响应时间和低功耗。它们还可以在广泛的温度范围内工作,并且可以在户外使用。
然而,TFT显示屏也有一些缺点,例如视角受限、成本较高和易受损等。此外,TFT显示屏需要背光源才能显示图像,这会增加其厚度和重量。
总的来说,TFT显示屏是一种高质量的显示技术,适用于许多应用。随着技术的不断发展,TFT显示屏的性能和功能将继续提高。
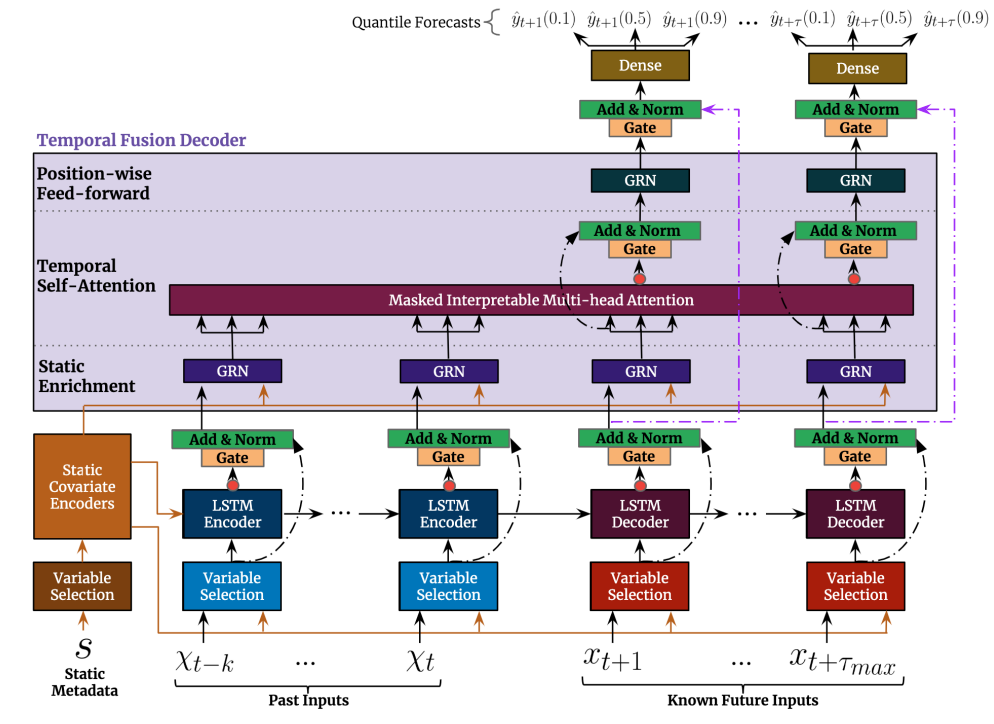
模型介绍
TFT模型原生支持所有类型的协变量,包括静态协变量。然而,它的计算量非常大。
我将使用以下超参数:
- input_chunk_length: 230
- output_chunk_length: 16
- hidden_size: 16
- lstm_layers: 3
- num_attention_heads: 4
- full_attention: True
- hidden_continuous_size: 16
- dropout: 0.060000000000000005
- lr: 0.009912733600616069
# 定义一个函数,用于将多维列表展开成一维列表
def flatten(l):
return [item for sublist in l for item in sublist]
# 初始化一个空列表,用于存储所有家庭的未来协变量
future_covariates_full = []
# 遍历家庭列表,将每个家庭的未来协变量添加到future_covariates_full列表中
for family in family_list:
future_covariates_full.append(future_covariates_dict[family])
# 将future_covariates_full列表展开成一维列表
future_covariates_full = flatten(future_covariates_full)
# 初始化一个空列表,用于存储所有家庭的过去协变量
only_past_covariates_full = []
# 遍历家庭列表,将每个家庭的过去协变量添加到only_past_covariates_full列表中
for family in family_list:
only_past_covariates_full.append(only_past_covariates_dict[family])
# 将only_past_covariates_full列表展开成一维列表
only_past_covariates_full = flatten(only_past_covariates_full)
# 将数据集分为训练集、验证集和测试集
val_len = 16
# 训练集为原始数据集中除了最后两个验证集长度的部分
train = [s[: -(2 * val_len)] for s in training_transformed]
# 验证集为原始数据集中最后两个验证集长度的部分
val = [s[-(2 * val_len) : -val_len] for s in training_transformed]
# 测试集为原始数据集中最后一个验证集长度的部分
test = [s[-val_len:] for s in training_transformed]
"""
我们编写一个函数来构建和拟合TCN模型,以便以后重复使用。
参数:
- input_chunk_length: 输入时间序列的长度
- output_chunk_length: 输出时间序列的长度
- hidden_size: LSTM隐藏层的大小
- lstm_layers: LSTM层数
- num_attention_heads: 注意力头的数量
- full_attention: 是否使用全注意力机制
- hidden_continuous_size: 连续特征的隐藏层大小
- dropout: Dropout的比例
- lr: 学习率
- likelihood: 概率分布函数
- callbacks: 回调函数列表
返回:
- model: 训练好的TFT模型
"""
def build_fit_tft_model(
input_chunk_length,
output_chunk_length,
hidden_size,
lstm_layers,
num_attention_heads,
full_attention,
hidden_continuous_size,
dropout,
lr,
likelihood=None,
callbacks=None,
):
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 一些固定的参数,对所有模型都是相同的
MAX_N_EPOCHS = 100
MAX_SAMPLES_PER_TS = 7
# 在训练过程中,我们将监控验证集的损失以进行早停
early_stopper = EarlyStopping("val_loss", min_delta=0.0001, patience=2, verbose=True)
if callbacks is None:
callbacks = [early_stopper]
else:
callbacks = [early_stopper] + callbacks
# 检测是否有可用的GPU
if torch.cuda.is_available():
pl_trainer_kwargs = {
"accelerator": "gpu",
"gpus": 1,
"auto_select_gpus": True,
"callbacks": callbacks,
}
num_workers = 2
else:
pl_trainer_kwargs = {"callbacks": callbacks}
num_workers = 0
# 构建TFT模型
model = TFTModel(
input_chunk_length=input_chunk_length,
output_chunk_length=output_chunk_length,
hidden_size=hidden_size,
lstm_layers=lstm_layers,
num_attention_heads=num_attention_heads,
full_attention=full_attention,
hidden_continuous_size=hidden_continuous_size,
dropout=dropout,
batch_size=128,
n_epochs=MAX_N_EPOCHS,
add_encoders=None,
likelihood=None,
loss_fn=torch.nn.MSELoss(),
random_state=42,
optimizer_kwargs={"lr": lr},
pl_trainer_kwargs=pl_trainer_kwargs,
model_name="tft_model",
force_reset=True,
save_checkpoints=True,
)
# 在训练过程中进行验证时,我们可以使用稍长一点的验证集,其中包含前input_chunk_length个时间步长
model_val_set = [s[-((2 * val_len) + input_chunk_length) : -val_len] for s in training_transformed]
# 训练模型
model.fit(
series=train,
val_series=model_val_set,
past_covariates=only_past_covariates_full,
val_past_covariates=only_past_covariates_full,
future_covariates=future_covariates_full,
val_future_covariates=future_covariates_full,
max_samples_per_ts=MAX_SAMPLES_PER_TS,
num_loader_workers=num_workers,
)
# 在训练过程中重新加载最佳模型
model = TFTModel.load_from_checkpoint("tft_model")
return model
# 设置TFT模型的参数
tft_params = {'input_chunk_length': 230,
'output_chunk_length': 16,
'hidden_size': 16,
'lstm_layers': 3,
'num_attention_heads': 4,
'full_attention': True,
'hidden_continuous_size': 16,
'dropout': 0.060000000000000005,
'lr': 0.009912733600616069}
# 清空GPU缓存
torch.cuda.empty_cache()
# 获取开始时间
st = time.time()
# 构建并训练TFT模型
TFT_Model = build_fit_tft_model(**tft_params)
# 为测试数据生成预测
training_data = [ts[:-16] for ts in training_transformed]
preds = TFT_Model.predict(series=training_data, past_covariates=only_past_covariates_full, future_covariates=future_covariates_full, n=val_len)
# 反向转换预测结果
forecasts_back = train_pipeline.inverse_transform(preds, partial=True)
# 零预测
for n in range(0,len(forecasts_back)):
if (list_of_TS[n][:-16].univariate_values()[-14:] == 0).all():
forecasts_back[n] = forecasts_back[n].map(lambda x: x * 0)
# 获取结束时间
et = time.time()
# 计算执行时间
elapsed_time_tft = et - st
# 计算均值RMSLE
TFT_rmsle = rmsle(actual_series = list_of_TS,
pred_series = forecasts_back,
n_jobs = -1,
inter_reduction=np.mean)
/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning:
Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
Sanity Checking: 0it [00:00, ?it/s]
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
Predicting: 0it [00:00, ?it/s]
# 打印空行
print("\n")
# 打印全球TFT模型在1782个系列上的平均RMSLE
print("The mean RMSLE for the Global TFT Model over 1782 series is {:.5f}.".format(TFT_rmsle))
# 打印训练和推断的持续时间
print('Training & Inference duration:', elapsed_time_tft, 'seconds')
# 打印空行
print("\n")
The mean RMSLE for the Global TFT Model over 1782 series is 0.43226.
Training & Inference duration: 1090.5660014152527 seconds
4.4. 提升树

尽管我的重点是深度学习模型,但我发现提升树模型在这个预测问题中表现最佳。Darts提供了LightGBM和CatBoost的实现。
由于Kaggle内核的内存问题,我暂时注释了提升树的训练。但是从以前的笔记本和在Colab上的训练中,我可以告诉你,这些模型到目前为止给出了最好的分数。
# 定义函数flatten,用于将嵌套列表展平
def flatten(l):
return [item for sublist in l for item in sublist]
# 初始化future_covariates_full列表
future_covariates_full = []
# 遍历family_list中的每个family
for family in family_list:
# 将future_covariates_dict中对应family的值添加到future_covariates_full列表中
future_covariates_full.append(future_covariates_dict[family])
# 将future_covariates_full列表展平
future_covariates_full = flatten(future_covariates_full)
# 初始化only_past_covariates_full列表
only_past_covariates_full = []
# 遍历family_list中的每个family
for family in family_list:
# 将only_past_covariates_dict中对应family的值添加到only_past_covariates_full列表中
only_past_covariates_full.append(only_past_covariates_dict[family])
# 将only_past_covariates_full列表展平
only_past_covariates_full = flatten(only_past_covariates_full)
# 初始化only_past_covariates_shifted列表
only_past_covariates_shifted = []
# 遍历only_past_covariates_full列表中的每个时间序列ts
for ts in only_past_covariates_full:
# 将ts向后平移16个时间步
shifted = ts.shift(n=16)
# 将平移后的时间序列添加到only_past_covariates_shifted列表中
only_past_covariates_shifted.append(shifted)
# 将训练数据划分为调参和验证集
# 定义验证集的长度为16
val_len = 16
# 对训练数据进行划分,得到训练集、验证集和测试集
train = [s[: -(2 * val_len)] for s in training_transformed]
val = [s[-(2 * val_len) : -val_len] for s in training_transformed]
test = [s[-val_len:] for s in training_transformed]
'\ndef flatten(l):\n return [item for sublist in l for item in sublist]\n\nfuture_covariates_full = []\n\nfor family in family_list:\n future_covariates_full.append(future_covariates_dict[family])\n \nfuture_covariates_full = flatten(future_covariates_full)\n\n\nonly_past_covariates_full = []\n\nfor family in family_list:\n only_past_covariates_full.append(only_past_covariates_dict[family])\n \nonly_past_covariates_full = flatten(only_past_covariates_full)\n\n\nonly_past_covariates_shifted = []\n\nfor ts in only_past_covariates_full:\n shifted = ts.shift(n=16)\n only_past_covariates_shifted.append(shifted)\n\n# Split in train/val/test for Tuning and Validation\n\nval_len = 16\n\ntrain = [s[: -(2 * val_len)] for s in training_transformed]\nval = [s[-(2 * val_len) : -val_len] for s in training_transformed]\ntest = [s[-val_len:] for s in training_transformed]\n'
# 导入CatBoostModel模型
from darts.models import CatBoostModel
# 定义一个函数,用于构建和拟合TCN模型,以便以后重复使用
def build_fit_cboost_model(
lags, # 时间序列的滞后期数
firstlag, # 未来协变量的第一个滞后期
pastcovlag, # 过去协变量的滞后期数
out_len, # 输出序列的长度
learning_rate, # 学习率
depth # 模型的深度
):
# 设置随机种子,以便结果可重复
torch.manual_seed(42)
# 定义一个所有模型都相同的固定参数
MAX_SAMPLES_PER_TS = 365
# 构建CatBoost模型
model = CatBoostModel(lags = lags, # 时间序列的滞后期数
lags_future_covariates = (firstlag,1), # 未来协变量的滞后期数
lags_past_covariates = [-pastcovlag], # 过去协变量的滞后期数
output_chunk_length=out_len, # 输出序列的长度
learning_rate=learning_rate, # 学习率
depth=depth, # 模型的深度
early_stopping_rounds=10, # 提前停止轮数
random_state=2022, # 随机种子
logging_level='Silent' # 日志级别
)
# 在训练过程中进行验证时,可以使用稍长一些的验证集,其中还包含前input_chunk_length个时间步长
model_val_set = [s[-((2 * val_len) + lags) : -val_len] for s in training_transformed]
# 训练模型
model.fit(
series=train, # 训练序列
val_series=model_val_set, # 验证序列
past_covariates=only_past_covariates_shifted, # 过去协变量
val_past_covariates=only_past_covariates_shifted, # 验证过去协变量
future_covariates=future_covariates_full, # 未来协变量
val_future_covariates=future_covariates_full, # 验证未来协变量
max_samples_per_ts=MAX_SAMPLES_PER_TS # 每个时间序列的最大样本数
)
# 在训练过程中重新加载最佳模型
#model = LightGBMModel.load_from_checkpoint("lgbm_model")
return model # 返回模型
' We write a function to build and fit a TCN Model, which we will re-use later.\n\nfrom darts.models import CatBoostModel\n\ndef build_fit_cboost_model(\n lags,\n firstlag,\n pastcovlag,\n out_len,\n learning_rate,\n depth\n ):\n\n # reproducibility\n torch.manual_seed(42)\n\n # some fixed parameters that will be the same for all models\n MAX_SAMPLES_PER_TS = 365\n\n # build the TCN model\n model = CatBoostModel(lags = lags,\n lags_future_covariates = (firstlag,1),\n lags_past_covariates = [-pastcovlag], \n output_chunk_length=out_len,\n learning_rate=learning_rate,\n depth=depth,\n early_stopping_rounds=10,\n random_state=2022,\n logging_level=\'Silent\'\n )\n\n # when validating during training, we can use a slightly longer validation\n # set which also contains the first input_chunk_length time steps\n model_val_set = [s[-((2 * val_len) + lags) : -val_len] for s in training_transformed]\n\n # train the model\n model.fit(\n series=train,\n val_series=model_val_set,\n past_covariates=only_past_covariates_shifted,\n val_past_covariates=only_past_covariates_shifted,\n future_covariates=future_covariates_full,\n val_future_covariates=future_covariates_full,\n max_samples_per_ts=MAX_SAMPLES_PER_TS\n )\n\n # reload best model over course of training\n #model = LightGBMModel.load_from_checkpoint("lgbm_model")\n\n return model\n'
# 定义CatBoost模型的参数
catboost_params = {'lags': 144,
'out_len': 3,
'firstlag': 44,
'pastcovlag': 60,
'learning_rate': 0.06539829509538796,
'depth': 9}
# 记录开始时间
st = time.time()
# 构建并训练CatBoost模型
CatBoost_Model = build_fit_cboost_model(**catboost_params)
# 为测试数据生成预测结果
# 将训练数据转换为CatBoost模型所需的格式
training_data = [ts[:-16] for ts in training_transformed]
# 进行预测
preds = CatBoost_Model.predict(series=training_data, past_covariates=only_past_covariates_shifted, future_covariates=future_covariates_full, n=val_len)
# 将预测结果转换回原始数据的格式
forecasts_back = train_pipeline.inverse_transform(preds, partial=True)
# 零预测
# 如果最近14天的历史数据都为0,则将预测结果设为0
for n in range(0,len(forecasts_back)):
if (list_of_TS[n][:-16].univariate_values()[-14:] == 0).all():
forecasts_back[n] = forecasts_back[n].map(lambda x: x * 0)
# 记录结束时间
et = time.time()
# 计算模型训练和预测所用的时间
elapsed_time_cboost = et - st
# 计算平均RMSLE
CatBoost_rmsle = rmsle(actual_series = list_of_TS,
pred_series = forecasts_back,
n_jobs = -1,
inter_reduction=np.mean)
# 输出结果
print("\n")
print("The mean RMSLE for the Global CatBoost Model over 1782 series is {:.5f}.".format(CatBoost_rmsle))
print('Training & Inference duration:', elapsed_time_cboost, 'seconds')
print("\n")
'\ncatboost_params = {\'lags\': 144, \n \'out_len\': 3, \n \'firstlag\': 44, \n \'pastcovlag\': 60, \n \'learning_rate\': 0.06539829509538796, \n \'depth\': 9}\n\n# get the start time\nst = time.time()\n\nCatBoost_Model = build_fit_cboost_model(**catboost_params)\n\n# Generate Forecasts for the Test Data\ntraining_data = [ts[:-16] for ts in training_transformed] \npreds = CatBoost_Model.predict(series=training_data, past_covariates=only_past_covariates_shifted, future_covariates=future_covariates_full, n=val_len)\n\n# Transform Back\nforecasts_back = train_pipeline.inverse_transform(preds, partial=True)\n\n# Zero Forecasting\nfor n in range(0,len(forecasts_back)):\n if (list_of_TS[n][:-16].univariate_values()[-14:] == 0).all():\n forecasts_back[n] = forecasts_back[n].map(lambda x: x * 0)\n\n# get the end time\net = time.time()\n\n# get the execution time\nelapsed_time_cboost = et - st\n\n# Mean RMSLE\n\nCatBoost_rmsle = rmsle(actual_series = list_of_TS,\n pred_series = forecasts_back,\n n_jobs = -1,\n inter_reduction=np.mean)\n\nprint("\n")\nprint("The mean RMSLE for the Global CatBoost Model over 1782 series is {:.5f}.".format(CatBoost_rmsle))\nprint(\'Training & Inference duration:\', elapsed_time_cboost, \'seconds\')\nprint("\n")\n\n'
"""
从darts.models导入CatBoostModel
定义一个函数build_fit_family_cboost_model,用于构建和拟合CatBoost模型,以便以后重复使用。
参数:
- lags:时间序列的滞后步长
- firstlag:第一个滞后步长
- pastcovlag:过去协变量的滞后步长
- out_len:输出长度
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 构建CatBoost模型
model = CatBoostModel(
lags=lags,
lags_future_covariates=(firstlag, 1),
lags_past_covariates=[-pastcovlag],
output_chunk_length=out_len,
early_stopping_rounds=10,
random_state=2022
)
# 在训练过程中进行验证时,可以使用稍长一些的验证集,该验证集还包含了第一个输入时间步长
model_val_set = [s[-((2 * val_len) + lags):-val_len] for s in sales_family]
# 训练模型
model.fit(
series=train,
val_series=model_val_set,
past_covariates=only_past_covariates_fam_shifted,
val_past_covariates=only_past_covariates_fam_shifted,
future_covariates=future_covariates_fam,
val_future_covariates=future_covariates_fam
)
返回模型
# 训练CatBoost Family模型
CatBoost_Models = {}
for family in tqdm(family_list):
# 获取当前family的销售时间序列和未来协变量
sales_family = family_TS_transformed_dict[family]
future_covariates_fam = future_covariates_dict[family]
only_past_covariates_fam = only_past_covariates_dict[family]
only_past_covariates_fam_shifted = []
# 对过去协变量进行滞后处理
for ts in only_past_covariates_fam:
shifted = ts.shift(n=16)
only_past_covariates_fam_shifted.append(shifted)
# 将数据集划分为训练集、验证集和测试集
val_len = 16
train = [s[:-(2 * val_len)] for s in sales_family]
# 构建并拟合CatBoost Family模型
CatBoost_Model = build_fit_family_cboost_model(
lags=365,
firstlag=28,
pastcovlag=14,
out_len=1
)
# 将模型添加到CatBoost_Models字典中
CatBoost_Models[family] = CatBoost_Model
"""
'\nfrom darts.models import CatBoostModel\n\ndef build_fit_family_cboost_model(\n lags,\n firstlag,\n pastcovlag,\n out_len,\n ):\n\n # reproducibility\n torch.manual_seed(42)\n\n # build the CatBoost model\n model = CatBoostModel(lags = lags,\n lags_future_covariates = (firstlag,1),\n lags_past_covariates = [-pastcovlag], \n output_chunk_length=out_len,\n early_stopping_rounds=10,\n random_state=2022\n )\n\n # when validating during training, we can use a slightly longer validation\n # set which also contains the first input_chunk_length time steps\n model_val_set = [s[-((2 * val_len) + lags) : -val_len] for s in sales_family]\n\n # train the model\n model.fit(\n series=train,\n val_series=model_val_set,\n past_covariates=only_past_covariates_fam_shifted,\n val_past_covariates=only_past_covariates_fam_shifted,\n future_covariates=future_covariates_fam,\n val_future_covariates=future_covariates_fam\n )\n\n return model\n\n# Train CatBoost Family Models\n\nCatBoost_Models = {}\n\nfor family in tqdm(family_list):\n \n sales_family = family_TS_transformed_dict[family]\n future_covariates_fam = future_covariates_dict[family]\n only_past_covariates_fam = only_past_covariates_dict[family]\n \n only_past_covariates_fam_shifted = [] \n for ts in only_past_covariates_fam:\n shifted = ts.shift(n=16)\n only_past_covariates_fam_shifted.append(shifted)\n\n # Split in train/val/test\n val_len = 16\n train = [s[: -(2 * val_len)] for s in sales_family]\n\n CatBoost_Model = build_fit_family_cboost_model( lags = 365,\n firstlag = 28,\n pastcovlag = 14,\n out_len = 1)\n\n CatBoost_Models[family] = CatBoost_Model\n '
# 生成测试数据的预测结果
CatBoost_Forecasts_Families = {} # 创建一个空字典,用于存储每个家族的预测结果
for family in tqdm(family_list): # 遍历家族列表
sales_family = family_TS_transformed_dict[family] # 获取当前家族的销售时间序列数据
training_data = [ts[:-16] for ts in sales_family] # 获取训练数据,去除最后16个时间步
future_covariates_fam = future_covariates_dict[family] # 获取当前家族的未来协变量数据
only_past_covariates_fam = only_past_covariates_dict[family] # 获取当前家族的过去协变量数据
only_past_covariates_fam_shifted = [] # 创建一个空列表,用于存储过去协变量数据的平移版本
for ts in only_past_covariates_fam: # 遍历过去协变量数据
shifted = ts.shift(n=16) # 将每个时间序列向后平移16个时间步
only_past_covariates_fam_shifted.append(shifted) # 将平移后的时间序列添加到列表中
forecast_CatBoost = CatBoost_Models[family].predict(n=16, # 使用CatBoost模型对未来16个时间步进行预测
series=training_data, # 使用训练数据进行预测
future_covariates=future_covariates_fam, # 使用未来协变量数据进行预测
past_covariates=only_past_covariates_fam_shifted # 使用平移后的过去协变量数据进行预测
)
CatBoost_Forecasts_Families[family] = forecast_CatBoost # 将预测结果添加到字典中
# 进行反向转换
CatBoost_Forecasts_Families_back = {} # 创建一个空字典,用于存储反向转换后的预测结果
for family in tqdm(family_list): # 遍历家族列表
CatBoost_Forecasts_Families_back[family] = family_pipeline_dict[family].inverse_transform(CatBoost_Forecasts_Families[family], partial=True) # 使用家族对应的pipeline对预测结果进行反向转换
# 零预测处理
for family in tqdm(CatBoost_Forecasts_Families_back): # 遍历反向转换后的预测结果字典
for n in range(0,len(CatBoost_Forecasts_Families_back[family])): # 遍历每个家族的预测结果
if (family_TS_dict[family][n][:-16].univariate_values()[-14:] == 0).all(): # 如果家族的最后14个时间步的销售量都为0
CatBoost_Forecasts_Families_back[family][n] = CatBoost_Forecasts_Families_back[family][n].map(lambda x: x * 0) # 将预测结果全部置为0
'\n# Generate Forecasts for the Test Data\n\nCatBoost_Forecasts_Families = {}\n\nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts[:-16] for ts in sales_family]\n future_covariates_fam = future_covariates_dict[family]\n only_past_covariates_fam = only_past_covariates_dict[family]\n \n only_past_covariates_fam_shifted = [] \n for ts in only_past_covariates_fam:\n shifted = ts.shift(n=16)\n only_past_covariates_fam_shifted.append(shifted)\n\n forecast_CatBoost = CatBoost_Models[family].predict(n=16,\n series=training_data,\n future_covariates=future_covariates_fam,\n past_covariates=only_past_covariates_fam_shifted\n )\n \n CatBoost_Forecasts_Families[family] = forecast_CatBoost\n\n# Transform Back\n\nCatBoost_Forecasts_Families_back = {}\n\nfor family in tqdm(family_list):\n\n CatBoost_Forecasts_Families_back[family] = family_pipeline_dict[family].inverse_transform(CatBoost_Forecasts_Families[family], partial=True)\n\n# Zero Forecasting\n\nfor family in tqdm(CatBoost_Forecasts_Families_back):\n for n in range(0,len(CatBoost_Forecasts_Families_back[family])):\n if (family_TS_dict[family][n][:-16].univariate_values()[-14:] == 0).all():\n CatBoost_Forecasts_Families_back[family][n] = CatBoost_Forecasts_Families_back[family][n].map(lambda x: x * 0)\n '
# Re-Format all 1782 Forecasts in one List and Evaluate Performance
# 创建一个空列表forecast_list_CatBoost,用于存储所有的预测结果
forecast_list_CatBoost = []
# 遍历family_list中的每个family
for family in family_list:
# 将CatBoost_Forecasts_Families_back[family]添加到forecast_list_CatBoost中
forecast_list_CatBoost.append(CatBoost_Forecasts_Families_back[family])
# 创建一个空列表sales_data,用于存储所有的销售数据
sales_data = []
# 遍历family_list中的每个family
for family in family_list:
# 将family_TS_dict[family]添加到sales_data中
sales_data.append(family_TS_dict[family])
# 定义一个函数flatten,用于将嵌套列表展平为一维列表
def flatten(l):
return [item for sublist in l for item in sublist]
# 将sales_data展平为一维列表,并赋值给actual_list
actual_list = flatten(sales_data)
# 将forecast_list_CatBoost展平为一维列表,并赋值给pred_list_CatBoost
pred_list_CatBoost = flatten(forecast_list_CatBoost)
# 调用rmsle函数计算平均RMSLE
CatBoost_rmsle = rmsle(actual_series=actual_list,
pred_series=pred_list_CatBoost,
n_jobs=-1,
inter_reduction=np.mean)
# 打印平均RMSLE的值
print("\n")
print("The mean RMSLE for the 33 CatBoost Global Product Family Models over all 1782 series is {:.5f}.".format(CatBoost_rmsle))
print("\n")
# Mean RMSLE for Families
# 创建一个空字典family_forecast_rmsle_CatBoost,用于存储每个family的RMSLE值
family_forecast_rmsle_CatBoost = {}
# 遍历family_list中的每个family
for family in family_list:
# 调用rmsle函数计算每个family的RMSLE值
CatBoost_rmsle_family = rmsle(actual_series=family_TS_dict[family],
pred_series=CatBoost_Forecasts_Families_back[family],
n_jobs=-1,
inter_reduction=np.mean)
# 将每个family的RMSLE值添加到family_forecast_rmsle_CatBoost字典中
family_forecast_rmsle_CatBoost[family] = CatBoost_rmsle_family
# 按照RMSLE值对family_forecast_rmsle_CatBoost字典进行排序
family_forecast_rmsle_CatBoost = dict(sorted(family_forecast_rmsle_CatBoost.items(), key=lambda item: item[1]))
# 打印从最差到最好的33个不同产品家族的平均RMSLE值
print("Mean RMSLE for the 33 different product families, from worst to best:")
print("\n")
# 遍历family_forecast_rmsle_CatBoost字典中的键值对,并打印它们
for key, value in family_forecast_rmsle_CatBoost.items():
print(key, ' : ', value)
'\n# Re-Format all 1782 Forecasts in one List and Evaluate Performance\n\nforecast_list_CatBoost = []\n\nfor family in family_list:\n forecast_list_CatBoost.append(CatBoost_Forecasts_Families_back[family])\n\nsales_data = []\n\nfor family in family_list:\n sales_data.append(family_TS_dict[family])\n\ndef flatten(l):\n return [item for sublist in l for item in sublist]\n \nactual_list = flatten(sales_data)\npred_list_CatBoost = flatten(forecast_list_CatBoost)\n\n# Mean RMSLE\n\nCatBoost_rmsle = rmsle(actual_series = actual_list,\n pred_series = pred_list_CatBoost,\n n_jobs = -1,\n inter_reduction=np.mean)\n\nprint("\n")\nprint("The mean RMSLE for the 33 CatBoost Global Product Family Models over all 1782 series is {:.5f}.".format(CatBoost_rmsle))\nprint("\n")\n\n# Mean RMSLE for Families\n\nfamily_forecast_rmsle_CatBoost = {}\n\nfor family in family_list:\n\n CatBoost_rmsle_family = rmsle(actual_series = family_TS_dict[family],\n pred_series = CatBoost_Forecasts_Families_back[family],\n n_jobs = -1,\n inter_reduction=np.mean)\n \n family_forecast_rmsle_CatBoost[family] = CatBoost_rmsle_family\n\nfamily_forecast_rmsle_CatBoost = dict(sorted(family_forecast_rmsle_CatBoost.items(), key=lambda item: item[1]))\n\nprint("Mean RMSLE for the 33 different product families, from worst to best:")\nprint("\n")\n\n# Iterate over key/value pairs in dict and print them\nfor key, value in family_forecast_rmsle_CatBoost.items():\n print(key, \' : \', value)\n'
# 绘制五个最差的预测结果
errorlist = [] # 创建一个空列表,用于存储误差值
for i in range(0, len(actual_list)): # 遍历实际值列表的索引范围
error = rmsle(actual_series = actual_list[i], # 调用rmsle函数计算实际值和预测值之间的误差
pred_series = pred_list_CatBoost[i])
errorfam = actual_list[i].static_covariates_values()[0,1] # 获取实际值的静态协变量值
errorlist.append([errorfam,error]) # 将静态协变量值和误差值添加到errorlist列表中
rmsle_series_CatBoost = pd.DataFrame(errorlist,columns=['family','RMSLE']) # 创建一个DataFrame,列名为'family'和'RMSLE',数据为errorlist
worst_3_CatBoost = rmsle_series_CatBoost.sort_values(by=['RMSLE'], ascending=False).head(3) # 对RMSLE列进行降序排序,并取前三个最大值
for i in range(0, len(worst_3_CatBoost)): # 遍历worst_3_CatBoost的索引范围
plt_forecast = pred_list_CatBoost[(worst_3_CatBoost.index[i])] # 获取对应索引的预测值
plt_actual = actual_list[(worst_3_CatBoost.index[i])] # 获取对应索引的实际值
plt_err = rmsle(plt_actual, plt_forecast) # 计算对应索引的实际值和预测值之间的误差
plt.figure(figsize=(10, 6)) # 创建一个大小为10x6的图像
plt_actual[-100:].plot(label="actual data") # 绘制最后100个实际值的折线图
plt_forecast.plot(label="CatBoost forecast") # 绘制CatBoost预测值的折线图
plt.title("{} in store {} ({}) - RMSLE: {}".format(plt_forecast.static_covariates_values()[0,1], # 设置图像标题,包括静态协变量的值、商店编号和日期,以及误差值
plt_forecast.static_covariates_values()[0,0],
plt_forecast.static_covariates_values()[0,2],
plt_err))
'\n# Plot the five worst forecasts \n\nerrorlist = []\n\nfor i in range(0, len(actual_list)):\n\n error = rmsle(actual_series = actual_list[i], \n pred_series = pred_list_CatBoost[i])\n \n errorfam = actual_list[i].static_covariates_values()[0,1]\n \n errorlist.append([errorfam,error])\n\nrmsle_series_CatBoost = pd.DataFrame(errorlist,columns=[\'family\',\'RMSLE\'])\nworst_3_CatBoost = rmsle_series_CatBoost.sort_values(by=[\'RMSLE\'], ascending=False).head(3)\n\nfor i in range(0, len(worst_3_CatBoost)):\n plt_forecast = pred_list_CatBoost[(worst_3_CatBoost.index[i])]\n plt_actual = actual_list[(worst_3_CatBoost.index[i])]\n plt_err = rmsle(plt_actual, plt_forecast)\n\n plt.figure(figsize=(10, 6))\n plt_actual[-100:].plot(label="actual data")\n plt_forecast.plot(label="CatBoost forecast")\n plt.title("{} in store {} ({}) - RMSLE: {}".format(plt_forecast.static_covariates_values()[0,1], \n plt_forecast.static_covariates_values()[0,0],\n plt_forecast.static_covariates_values()[0,2],\n plt_err))\n'
4.5. 模型比较
让我们快速比较一下在这个笔记本中训练的模型的性能:
# 打印本地指数平滑模型的平均RMSLE值
print("Mean RMSLE for Local Exponential Smoothing Models: {:.5f}.".format(ES_rmsle))
# 打印本地指数平滑模型的训练时间
print('Training duration:', elapsed_time_exp, 'seconds')
print("\n")
# 打印全局N-HiTS模型的平均RMSLE值
print("Mean RMSLE for Global N-HiTS Model: {:.5f}.".format(NHiTS_rmsle))
# 打印全局N-HiTS模型的训练时间
print('Training duration:', elapsed_time_nhits, 'seconds')
print("\n")
# 打印全局LSTM模型的平均RMSLE值
print("Mean RMSLE for Global LSTM Model: {:.5f}.".format(LSTM_rmsle))
# 打印全局LSTM模型的训练时间
print('Training duration:', elapsed_time_lstm, 'seconds')
print("\n")
# 打印全局TFT模型的平均RMSLE值
print("Mean RMSLE for Global TFT Model: {:.5f}.".format(TFT_rmsle))
# 打印全局TFT模型的训练时间
print('Training duration:', elapsed_time_tft, 'seconds')
print("\n")
# 打印全局CatBoost模型的平均RMSLE值
# print("Mean RMSLE for Global CatBoost Model{:.5f}.".format(CatBoost_rmsle))
# 打印全局CatBoost模型的训练时间
# print('Training duration:', elapsed_time_cboost, 'seconds')
# print("\n")
Mean RMSLE for Local Exponential Smoothing Models: 0.37411.
Training duration: 653.0645875930786 seconds
Mean RMSLE for Global N-HiTS Model: 0.43265.
Training duration: 1102.850519657135 seconds
Mean RMSLE for Global LSTM Model: 0.55443.
Training duration: 1438.0281417369843 seconds
Mean RMSLE for Global TFT Model: 0.43226.
Training duration: 1090.5660014152527 seconds
**重要提示:**在这些全局模型中,只有TFT“知道”哪个系列是哪个。它使用包含有关商店和产品系列信息的静态协变量来识别每个系列。N-HiTS、LSTM和LightGBM/CatBoost是使用来自所有1782个系列的样本进行训练的,而没有直接的关于每个系列的商店/系列ID的信息。这意味着,这些模型将所有样本都视为来自相同的数据生成过程。这是否是一个好的假设?不确定 - 也许为每个产品系列甚至商店训练全局模型会更好。在全局模型中,拥有更多的数据和个体系列之间的更多相似性之间存在权衡。我对这个话题非常感兴趣 - 如果您有任何想法,请留言!
5. 在排行榜上提交
重新对基线指数平滑模型进行全量训练数据的重新训练,得到了公开的RMSLE得分为0.40578,这足以进入前10%。33个全球LightGBM模型(每个产品族一个)在提交时获得了#1的排行榜得分为0.38558。此外,我还添加了使用CatBoost生成提交预测的代码,但每个产品族只有一个全局CatBoost模型。取消注释以使用其中任何一个。
# Train Final Exponential Smoothing Models and Forecast for Submission
# 创建两个空字典,用于存储指数平滑模型和预测结果
ES_Models_Family_Dict_Submission = {}
ES_Forecasts_Family_Dict_Submission = {}
# 遍历每个family
for family in tqdm(family_list):
# 获取当前family的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
# 使用训练数据构建指数平滑模型
ES_Models_Family_Dict_Submission[family] = ESModelBuilder(training_data)
# 使用指数平滑模型进行预测
forecasts_ES = ESForecaster(ES_Models_Family_Dict_Submission[family])
# 将预测结果进行逆变换
ES_Forecasts_Family_Dict_Submission[family] = family_pipeline_dict[family].inverse_transform(forecasts_ES, partial=True)
# 对预测结果进行零值预测
for i in range(0,len(ES_Forecasts_Family_Dict_Submission[family])):
if (training_data[i].univariate_values()[-21:] == 0).all():
ES_Forecasts_Family_Dict_Submission[family][i] = ES_Forecasts_Family_Dict_Submission[family][i].map(lambda x: x * 0)
# Prepare Submission in Correct Format
# 创建一个空列表,用于存储每个store和family的预测结果
listofseries = []
# 遍历每个store和family
for store in range(0,54):
for family in tqdm(family_list):
# 获取当前store和family的预测结果
oneforecast = ES_Forecasts_Family_Dict_Submission[family][store].pd_dataframe()
oneforecast.columns = ['fcast']
# 将预测结果添加到列表中
listofseries.append(oneforecast)
# 将所有预测结果合并为一个DataFrame
df_forecasts = pd.concat(listofseries)
df_forecasts.reset_index(drop=True, inplace=True)
# 将负值的预测结果设为0
df_forecasts[df_forecasts < 0] = 0
# 将预测结果与测试数据按照id进行合并
forecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)
# 按照id进行排序
forecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=['id'])
# 删除不需要的列
forecasts_kaggle_sorted = forecasts_kaggle_sorted.drop(['date','store_nbr','family'], axis=1)
# 重命名列名
forecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})
# 重置索引
forecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)
# 将预测结果保存为submission.csv文件
submission_kaggle = forecasts_kaggle_sorted
submission_kaggle.to_csv('submission.csv', index=False)
# Train 33 Global LightGBM Models with Full Data
# 导入所需的库和模块
from sklearn.metrics import mean_squared_log_error as msle, mean_squared_error as mse
from lightgbm import early_stopping
# 创建一个空字典,用于存储LightGBM模型
LGBM_Models_Submission = {}
# 遍历每个family
for family in tqdm(family_list):
# 获取当前family的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
# 获取当前family的未来协变量数据
TCN_covariates = future_covariates_dict[family]
# 对训练数据进行切片
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
# 创建一个LightGBM模型
LGBM_Model_Submission = LightGBMModel(lags = 63,
lags_future_covariates = (14,1),
lags_past_covariates = [-16,-17,-18,-19,-20,-21,-22],
output_chunk_length=1,
random_state=2022,
# max_bin= [63],
gpu_use_dp= "false")
# 使用训练数据和协变量数据拟合模型
LGBM_Model_Submission.fit(series=train_sliced,
future_covariates=TCN_covariates,
past_covariates=transactions_transformed,
verbose=True)
# 将模型添加到字典中
LGBM_Models_Submission[family] = LGBM_Model_Submission
# Generate Forecasts for Submission
# 创建一个空字典,用于存储LightGBM模型的预测结果
LGBM_Forecasts_Families_Submission = {}
# 遍历每个family
for family in tqdm(family_list):
# 获取当前family的销售时间序列数据
sales_family = family_TS_transformed_dict[family]
training_data = [ts for ts in sales_family]
# 获取当前family的未来协变量数据
LGBM_covariates = future_covariates_dict[family]
# 对训练数据进行切片
train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]
# 使用LightGBM模型进行预测
forecast_LGBM = LGBM_Models_Submission[family].predict(n=16,
series=train_sliced,
future_covariates=LGBM_covariates,
past_covariates=transactions_transformed)
# 将预测结果添加到字典中
LGBM_Forecasts_Families_Submission[family] = forecast_LGBM
# Transform Back
# 创建一个空字典,用于存储逆变换后的预测结果
LGBM_Forecasts_Families_back_Submission = {}
# 遍历每个family
for family in tqdm(family_list):
# 对预测结果进行逆变换
LGBM_Forecasts_Families_back_Submission[family] = family_pipeline_dict[family].inverse_transform(LGBM_Forecasts_Families_Submission[family], partial=True)
# Zero Forecasting
# 对预测结果进行零值预测
for family in tqdm(LGBM_Forecasts_Families_back_Submission):
for n in range(0,len(LGBM_Forecasts_Families_back_Submission[family])):
if (family_TS_dict[family][n].univariate_values()[-21:] == 0).all():
LGBM_Forecasts_Families_back_Submission[family][n] = LGBM_Forecasts_Families_back_Submission[family][n].map(lambda x: x * 0)
# Prepare Submission in Correct Format
# 创建一个空列表,用于存储每个store和family的预测结果
listofseries = []
# 遍历每个store和family
for store in range(0,54):
for family in tqdm(family_list):
# 获取当前store和family的预测结果
oneforecast = LGBM_Forecasts_Families_back_Submission[family][store].pd_dataframe()
oneforecast.columns = ['fcast']
# 将预测结果添加到列表中
listofseries.append(oneforecast)
# 将所有预测结果合并为一个DataFrame
df_forecasts = pd.concat(listofseries)
df_forecasts.reset_index(drop=True, inplace=True)
# 将负值的预测结果设为0
df_forecasts[df_forecasts < 0] = 0
# 将预测结果与测试数据按照id进行合并
forecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)
# 按照id进行排序
forecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=['id'])
# 删除不需要的列
forecasts_kaggle_sorted = forecasts_kaggle_sorted.drop(['date','store_nbr','family'], axis=1)
# 重命名列名
forecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})
# 重置索引
forecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)
# 将预测结果保存为submission.csv文件
submission_kaggle = forecasts_kaggle_sorted
submission_kaggle.to_csv('submission.csv', index=False)
'\n# Train Final Exponential Smoothing Models and Forecast for Submission\n\nES_Models_Family_Dict_Submission = {}\nES_Forecasts_Family_Dict_Submission = {}\n\nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts for ts in sales_family]\n\n ES_Models_Family_Dict_Submission[family] = ESModelBuilder(training_data)\n forecasts_ES = ESForecaster(ES_Models_Family_Dict_Submission[family])\n \n # Transform Back\n ES_Forecasts_Family_Dict_Submission[family] = family_pipeline_dict[family].inverse_transform(forecasts_ES, partial=True)\n\n # Zero Forecasting\n for i in range(0,len(ES_Forecasts_Family_Dict_Submission[family])):\n if (training_data[i].univariate_values()[-21:] == 0).all():\n ES_Forecasts_Family_Dict_Submission[family][i] = ES_Forecasts_Family_Dict_Submission[family][i].map(lambda x: x * 0)\n \n \n# Prepare Submission in Correct Format\n\nlistofseries = []\n\nfor store in range(0,54):\n for family in tqdm(family_list):\n oneforecast = ES_Forecasts_Family_Dict_Submission[family][store].pd_dataframe()\n oneforecast.columns = [\'fcast\']\n listofseries.append(oneforecast)\n\ndf_forecasts = pd.concat(listofseries) \ndf_forecasts.reset_index(drop=True, inplace=True)\n\n# No Negative Forecasts\ndf_forecasts[df_forecasts < 0] = 0\nforecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)\nforecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=[\'id\'])\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.drop([\'date\',\'store_nbr\',\'family\'], axis=1)\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)\n\n# Submission\nsubmission_kaggle = forecasts_kaggle_sorted\nsubmission_kaggle.to_csv(\'submission.csv\', index=False)\n\n# Train 33 Global LightGBM Models with Full Data\n\nfrom sklearn.metrics import mean_squared_log_error as msle, mean_squared_error as mse\nfrom lightgbm import early_stopping\n\nLGBM_Models_Submission = {}\n\nfor family in tqdm(family_list):\n\n # Define Data for family\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts for ts in sales_family] \n TCN_covariates = future_covariates_dict[family]\n train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]\n\n LGBM_Model_Submission = LightGBMModel(lags = 63,\n lags_future_covariates = (14,1),\n lags_past_covariates = [-16,-17,-18,-19,-20,-21,-22],\n output_chunk_length=1,\n random_state=2022,\n # max_bin= [63],\n gpu_use_dp= "false")\n \n LGBM_Model_Submission.fit(series=train_sliced, \n future_covariates=TCN_covariates,\n past_covariates=transactions_transformed,\n verbose=True)\n\n LGBM_Models_Submission[family] = LGBM_Model_Submission\n \n # Generate Forecasts for Submission\n\nLGBM_Forecasts_Families_Submission = {}\n\nfor family in tqdm(family_list):\n\n sales_family = family_TS_transformed_dict[family]\n training_data = [ts for ts in sales_family]\n LGBM_covariates = future_covariates_dict[family]\n train_sliced = [training_data[i].slice_intersect(TCN_covariates[i]) for i in range(0,len(training_data))]\n\n forecast_LGBM = LGBM_Models_Submission[family].predict(n=16,\n series=train_sliced,\n future_covariates=LGBM_covariates,\n past_covariates=transactions_transformed)\n \n LGBM_Forecasts_Families_Submission[family] = forecast_LGBM\n\n# Transform Back\n\nLGBM_Forecasts_Families_back_Submission = {}\n\nfor family in tqdm(family_list):\n\n LGBM_Forecasts_Families_back_Submission[family] = family_pipeline_dict[family].inverse_transform(LGBM_Forecasts_Families_Submission[family], partial=True)\n\n# Zero Forecasting\n\nfor family in tqdm(LGBM_Forecasts_Families_back_Submission):\n for n in range(0,len(LGBM_Forecasts_Families_back_Submission[family])):\n if (family_TS_dict[family][n].univariate_values()[-21:] == 0).all():\n LGBM_Forecasts_Families_back_Submission[family][n] = LGBM_Forecasts_Families_back_Submission[family][n].map(lambda x: x * 0)\n \n# Prepare Submission in Correct Format\n\nlistofseries = []\n\nfor store in range(0,54):\n for family in tqdm(family_list):\n oneforecast = LGBM_Forecasts_Families_back_Submission[family][store].pd_dataframe()\n oneforecast.columns = [\'fcast\']\n listofseries.append(oneforecast)\n\ndf_forecasts = pd.concat(listofseries) \ndf_forecasts.reset_index(drop=True, inplace=True)\n\n# No Negative Forecasts\ndf_forecasts[df_forecasts < 0] = 0\nforecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)\nforecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=[\'id\'])\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.drop([\'date\',\'store_nbr\',\'family\'], axis=1)\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})\nforecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)\n\n# Submission\nsubmission_kaggle = forecasts_kaggle_sorted\nsubmission_kaggle.to_csv(\'submission.csv\', index=False)\n'
"""
从darts.models导入CatBoostModel
def build_fit_family_cboost_model(
lags,
firstlag,
pastcovlag,
out_len,
):
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 构建CatBoost模型
model = CatBoostModel(lags = lags,
lags_future_covariates = (firstlag,1),
lags_past_covariates = [-pastcovlag],
output_chunk_length=out_len,
learning_rate=learning_rate,
depth=depth,
early_stopping_rounds=10,
random_state=2022
)
# 在训练过程中进行验证时,可以使用稍长一些的验证集,该验证集还包含了前input_chunk_length个时间步长
model_val_set = [s[-(val_len + lags) : ] for s in sales_family]
# 训练模型
model.fit(
series=train,
val_series=model_val_set,
past_covariates=only_past_covariates_fam_shifted,
val_past_covariates=only_past_covariates_fam_shifted,
future_covariates=future_covariates_fam,
val_future_covariates=future_covariates_fam
)
return model
# 训练提交模型
CatBoost_Models = {}
for family in tqdm(family_list):
sales_family = family_TS_transformed_dict[family]
future_covariates_fam = future_covariates_dict[family]
only_past_covariates_fam = only_past_covariates_dict[family]
only_past_covariates_fam_shifted = []
for ts in only_past_covariates_fam:
shifted = ts.shift(n=16)
only_past_covariates_fam_shifted.append(shifted)
# 分割训练集/验证集/测试集
val_len = 16
train = [s[: -val_len] for s in sales_family]
CatBoost_Model = build_fit_family_cboost_model( lags = 144,
firstlag = 44,
pastcovlag = 60,
learning_rate = 0.06539829509538796,
depth = 9,
out_len = 3)
CatBoost_Models[family] = CatBoost_Model
# 生成提交的预测结果
CatBoost_Forecasts_Families_Submission = {}
for family in tqdm(family_list):
sales_family = family_TS_transformed_dict[family]
training_data = [ts[:-16] for ts in sales_family]
future_covariates_fam = future_covariates_dict[family]
only_past_covariates_fam = only_past_covariates_dict[family]
only_past_covariates_fam_shifted = []
for ts in only_past_covariates_fam:
shifted = ts.shift(n=16)
only_past_covariates_fam_shifted.append(shifted)
forecast_CatBoost = CatBoost_Models[family].predict(n=16,
series=training_data,
future_covariates=future_covariates_fam,
past_covariates=only_past_covariates_fam_shifted)
CatBoost_Forecasts_Families_Submission[family] = forecast_CatBoost
# 转换回原始数据
CatBoost_Forecasts_Families_back_Submission = {}
for family in tqdm(family_list):
CatBoost_Forecasts_Families_back_Submission[family] = family_pipeline_dict[family].inverse_transform(CatBoost_Forecasts_Families_Submission[family], partial=True)
# 零预测
for family in tqdm(CatBoost_Forecasts_Families_back_Submission):
for n in range(0,len(CatBoost_Forecasts_Families_back_Submission[family])):
if (family_TS_dict[family][n].univariate_values()[-14:] == 0).all():
CatBoost_Forecasts_Families_back_Submission[family][n] = CatBoost_Forecasts_Families_back_Submission[family][n].map(lambda x: x * 0)
# 准备正确格式的提交结果
listofseries = []
for store in range(0,54):
for family in tqdm(family_list):
oneforecast = CatBoost_Forecasts_Families_back_Submission[family][store].pd_dataframe()
oneforecast.columns = ['fcast']
listofseries.append(oneforecast)
df_forecasts = pd.concat(listofseries)
df_forecasts.reset_index(drop=True, inplace=True)
# 无负预测值
df_forecasts[df_forecasts < 0] = 0
forecasts_kaggle = pd.concat([df_test_sorted, df_forecasts.set_index(df_test_sorted.index)], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle.sort_values(by=['id'])
forecasts_kaggle_sorted = forecasts_kaggle_sorted.drop(['date','store_nbr','family'], axis=1)
forecasts_kaggle_sorted = forecasts_kaggle_sorted.rename(columns={"fcast": "sales"})
forecasts_kaggle_sorted = forecasts_kaggle_sorted.reset_index(drop=True)
# 提交
submission_kaggle = forecasts_kaggle_sorted
submission_kaggle.to_csv('submission.csv', index=False)
"""
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 这个UPS监控技术,简直是太牛了!
- L1-041:寻找250
- 企业快成长AI技术创新论坛·深圳站:让创新创意肆意生长
- 达摩研究院Paraformer-large模型已支持windows
- stm32f407 bm -> freertos
- IDEA的天花板级别使用技巧,yyds!
- 有关List的线程安全、高效读取:不变模式下的CopyOnWriteArrayList类、数据共享通道:BlockingQueue
- 银行非功能测试总结
- 【K8S基础】-k8s的核心概念控制器和调度器
- 开箱即用的企业级数据和业务管理中后台前端框架Ant Design Pro 5的开箱使用和偏好配置