【JVM】运行时数据区
一、前言
JVM运行时数据区是Java虚拟机的内存管理模型,包括方法区、堆、虚拟机栈、本地方法栈和程序计数器。

二、组成
-
程序计数器:是一块较小的内存空间,是当前线程所执行的字节码的行号指示器。
-
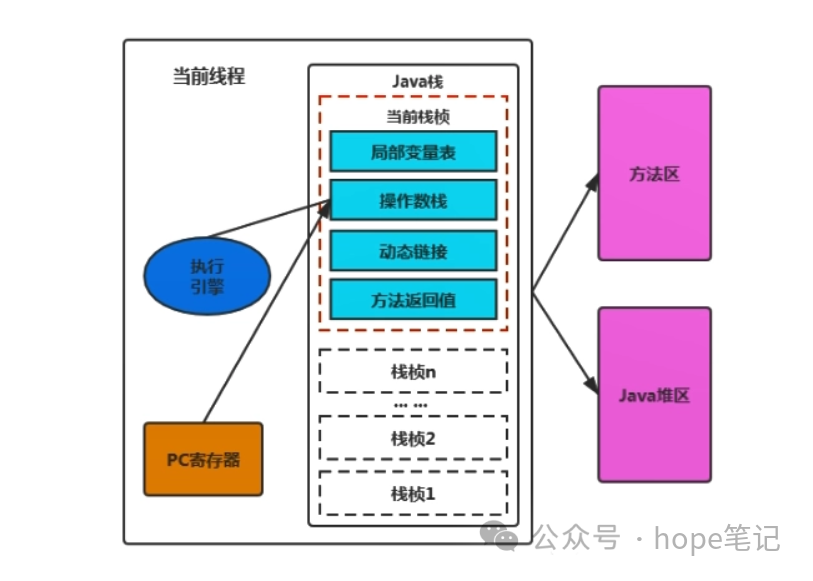
Java虚拟机栈:每个线程在运行时都有自己的一个栈,用于存储局部变量、操作数栈、动态链接等信息。
-
本地方法栈:与虚拟机栈类似,只不过它是用来支持本地方法调用的。
-
Java堆内存:用于存储对象实例。
-
方法区:用于存储类的结构信息、常量、静态变量等数据。
三、程序计数器
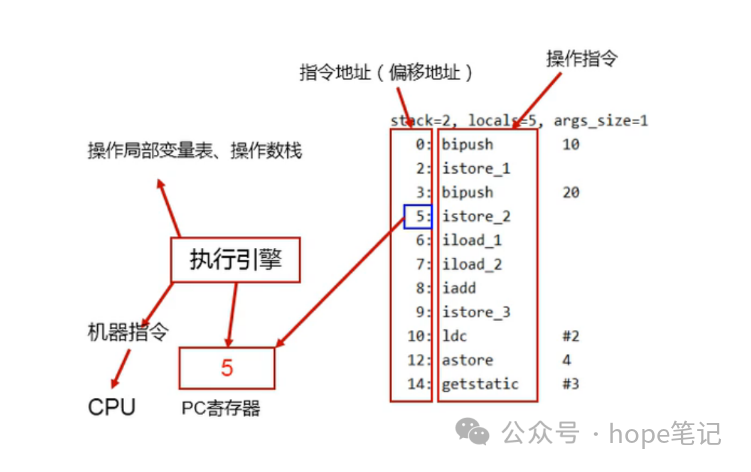
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。
程序计数器用来存储下一条指令的地址,也即将要执行的指令代码,由执行引擎读取下一条指令。
-
它是一块很小的内存空间,几乎可以忽略不计,也是运行速度最快的存储区域;
-
在 JVM 规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程生命周期保持一致;
-
程序计数器会存储当前线程正在执行的 Java 方法的 JVM 指令地址;
-
它是程序控制流的指示器,分支,循环,跳转,异常处理,线程恢复等基础功能都需要依赖这个计数器来完成;
-
它是唯一一个在java虚拟机规范中没有规定任何OutOfMemoryError情况的区域;
四、Java 虚拟机栈(Java Virtual Machine Stacks)
1. 栈的基本概念
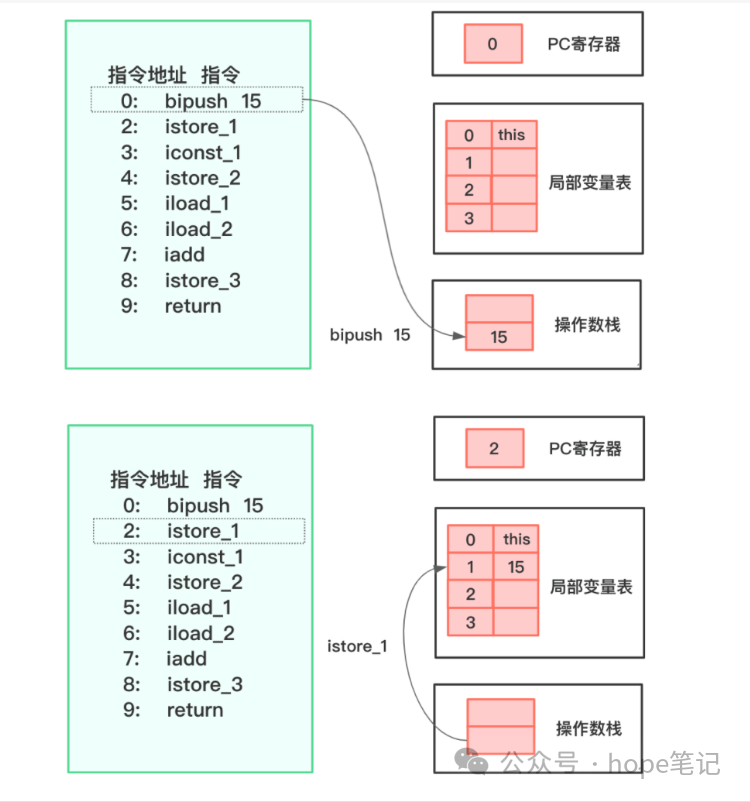
栈是运行时的单位,即栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。Java 虚拟机栈(Java Virtual Machine Stack),早期也叫 Java 栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个栈帧,对应着一次方法的调用。Java 虚拟机栈是线程私有的,主管 Java 程序的运行,它保存方法的局部变量(8种基本数据类型,对象的引用地址),部分结果,并参与方法的调用和返回。
2. 栈的特点
-
栈是一种快速有效的分配存储方式,访问速度仅次于程序计数器;
-
JVM 直接对 java 栈的操作只有两个:调用方法 入栈;执行结束后 出栈;
-
对于栈来说不存在垃圾回收问题。
栈中会出现异常,当线程请求的栈深度大于虚拟机所允许的深度时,会出现StackOverflowError。
3. 栈的运行原理
-
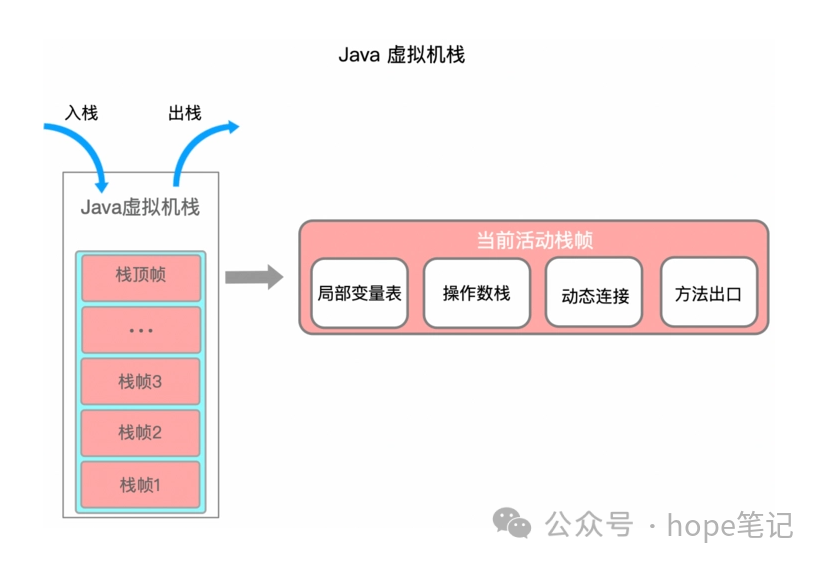
JVM 直接对 java 栈的操作只有两个,就是对栈帧的入栈和出栈,遵循先进后出/后进先出的原则;
-
在一条活动的线程中,一个时间点上,只会有一个活动栈。即只有当前在执行的方法的栈帧(栈顶)是有效地,这个栈帧被称为当前栈(Current Frame),与当前栈帧对应的方法称为当前方法(CurrentMethod),定义这个方法的类称为当前类(Current Class);
-
执行引擎运行的所有字节码指令只针对当前栈帧进行操作;
-
如果在该方法中调用了其他方法,对应的新的栈帧就会被创建出来,放在栈的顶端,成为新的当前栈帧。
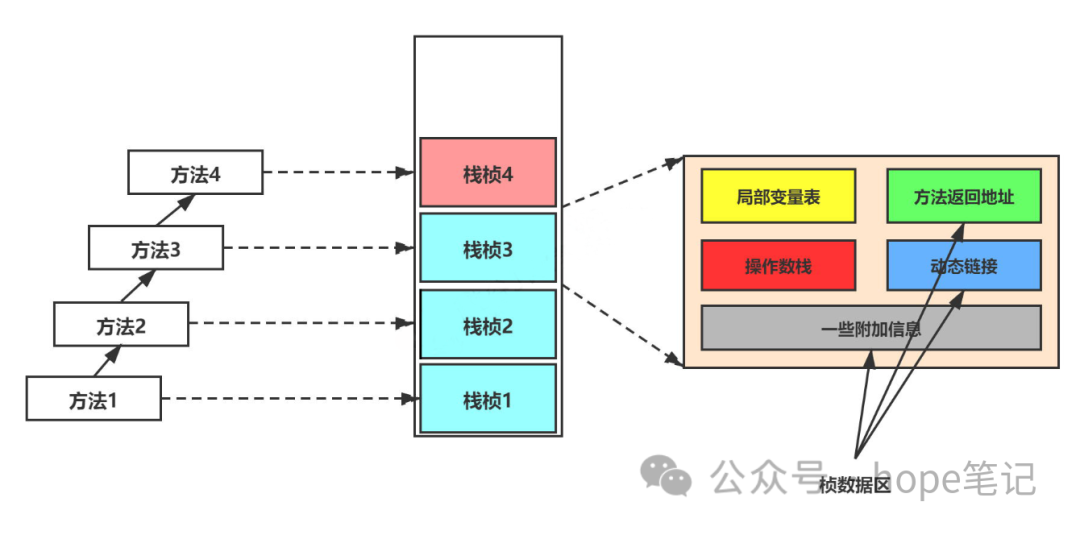
不同线程中所包含的栈帧(方法)是不允许存在相互引用的,即不可能在一个栈中引用另一个线程的栈帧(方法);
如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧;
Java 方法有两种返回的方式,一种是正常的函数返回,使用 return 指令;另一种是抛出异常;不管哪种方式,都会导致栈帧被弹出。
栈帧的内部结构
每个栈帧中存储着:
局部变量表(Local Variables)
局部变量表是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。对于基本数据类型的变量,则直接存储它的值,对于引用类型的变量,则存的是指向对象的引用。
操作数栈(Operand Stack)(或表达式栈)
栈最典型的一个应用就是用来对表达式求值。在一个线程执行方法的过程中,实际上就是不断执行语句的过程,而归根到底就是进行计算的过程。因此可以这么说,程序中的所有计算过程都是在借助于操作数栈来完成的。
动态链接(Dynamic Linking) (或指向运行时常量池的方法引用)
因为在方法执行的过程中有可能需要用到类中的常量,所以必须要有一个引用指向运行时常量。
方法返回地址(Retuen Address)(或方法正常退出或者异常退出的定义)
当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
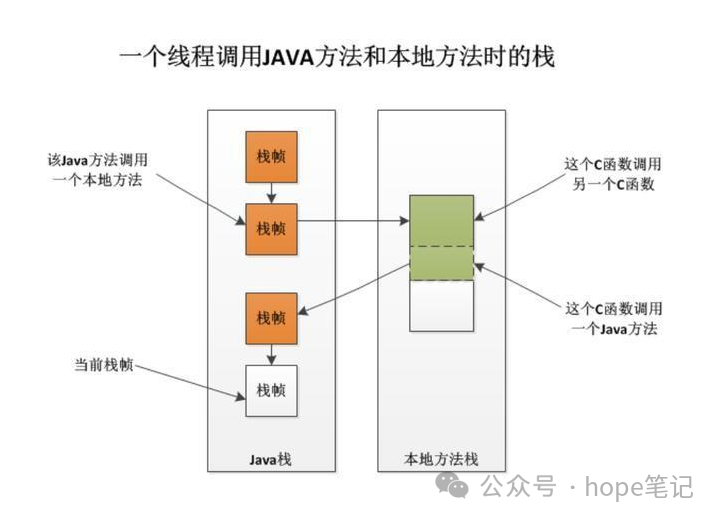
五、本地方法栈(Native Method Stack)
-
Java 虚拟机栈管理 java 方法的调用,而本地方法栈用于管理本地方法的调用;
-
本地方法栈也是线程私有的;
-
允许被实现成固定或者是可动态扩展的内存大小;
-
内存溢出方面也是相同的,如果线程请求分配的栈容量超过本地方法栈允许的最大容量抛出 StackOverflowError;
-
本地方法是用 C 语言写的;
-
它的具体做法是在 Native Method Stack 中登记 native 方法,在 Execution Engine 执行时加载本地方法库。
六、Java 堆内存
1. Java堆内存概述
-
一个 JVM 实例只存在一个堆内存,堆也是 Java 内存管理的核心区域;
-
Java 堆区在 JVM 启动时的时候即被创建,其空间大小也就确定了,是 JVM 管理的最大一块内存空间;
-
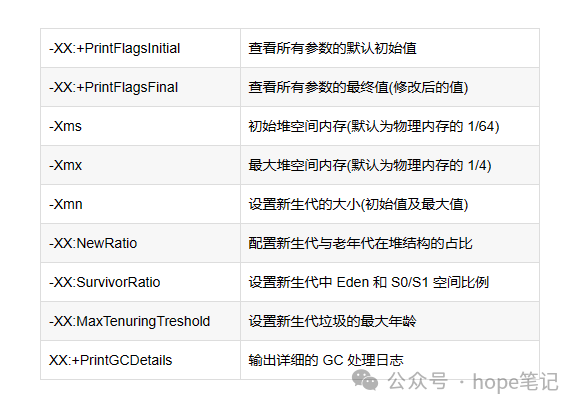
堆内存的大小是可以调节:例如: -Xms:10m(堆起始大小) -Xmx:30m(堆最大内存大小)。一般情况可以将起始值和最大值设置为一致,这样会减少垃圾回收之后堆内存重新分配大小的次数,提高效率;
-
《Java 虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但逻辑上它应该被视为连续的;
-
所有的线程共享 Java 堆,在这里还可以划分线程私有的缓冲区;
-
《Java 虚拟机规范》中对 Java 堆的描述是:所有的对象实例都应当在运行时分配在堆上,
-
在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
-
堆是 GC(Garbage Collection,垃圾收集器)执行垃圾回收的重点区域。
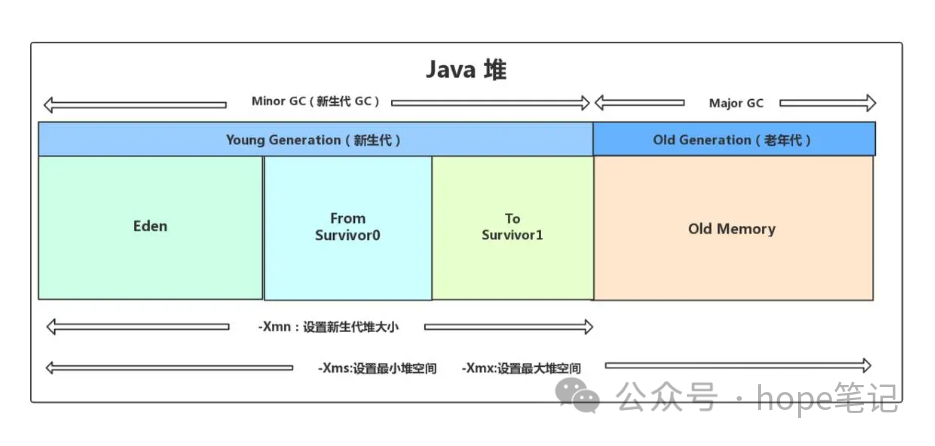
2. 堆内存区域划分
Java8 及之后堆内存分为 :新生区(新生代)+老年区(老年代)
新生区分为 Eden(伊甸园)区和 Survivor(幸存者)区
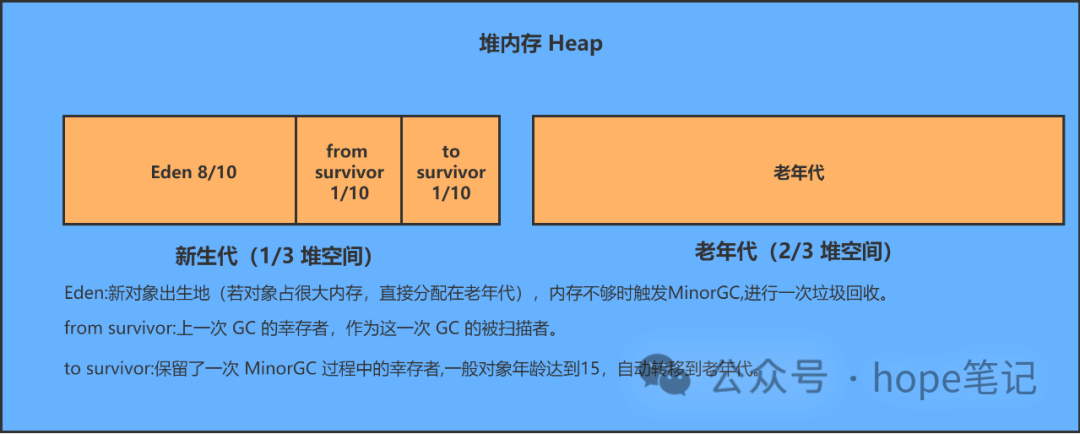
将对象根据存活概率进行分类,对存活时间长的对象,放到固定区,从而减少扫描垃圾时间及 GC 频率。
针对分类进行不同的垃圾回收算法,对算法扬长避短。
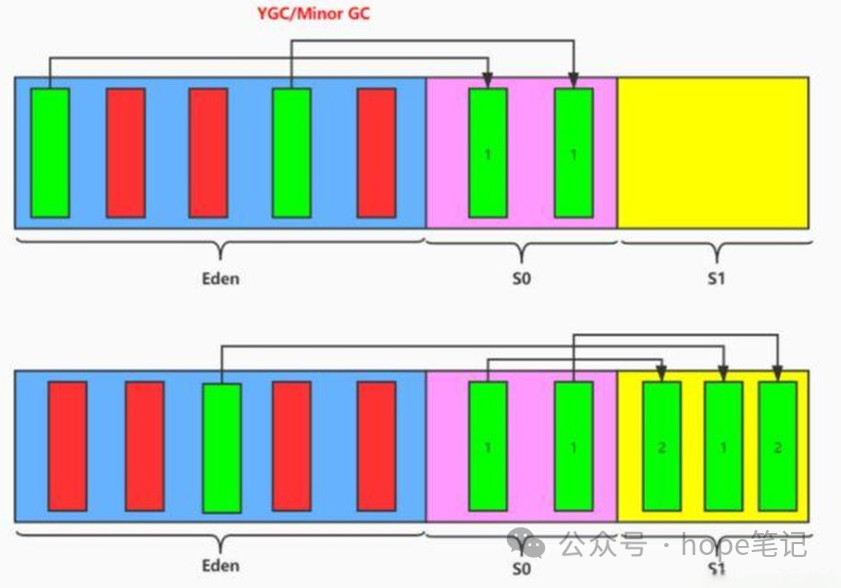
3. 对象创建内存分配过程
为新对象分配内存是一件非常严谨和复杂的任务,VM 的设计者们不仅需要考虑内存如何分配,在哪分配等问题,并且由于内存分配算法与内存回收算法密切相关,所以还需要考虑 GC 执行完内存回收后是否会在内存空间中产生内存碎片。
-
new 的新对象先放到伊甸园区,此区大小有限制;
-
当伊甸园的空间填满时,程序又需要创建对象时,JVM 的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被引用的对象进行销毁,再加载新的对象放到伊甸园区,
-
然后将伊甸园区中的剩余对象移动到幸存者 0 区;
-
如果再次出发垃圾回收,此时上次幸存下来存放到幸存者 0 区的对象,如果没有回收,就会被放到幸存者 1 区,每次会保证有一个幸存者区是空的;
-
如果再次经历垃圾回收,此时会重新放回幸存者 0 区,接着再去幸存者 1 区;
-
什么时候去养老区呢?默认是 15 次,也可以设置参数,最大值为 15:
?-XX:MaxTenuringThreshold=<N>
?在对象头中,它是由 4 位数据来对 GC 年龄进行保存的,所以最大值为 1111,即为15。所以在对象的 GC 年龄达到 15 时,就会从新生代转到老年代;
-
在老年区,相对悠闲,当养老区内存不足时,再次触发 Major GC,进行养老区的内存清理;
-
若养老区执行了 Major GC 之后发现依然无法进行对象保存,就会产生 OOM 异常:Java.lang.OutOfMemoryError:Java heap space。
4.?新生区与老年区配置比例
-
配置新生代与老年代在堆结构的占比(一般不会调):
-
默认**-XX:NewRatio**=2,表示新生代占 1,老年代占 2,新生代占整个堆的 1/3;
-
可以修改**-XX:NewRatio**=4,表示新生代占 1,老年代占 4,新生代占整个堆的 1/5;
-
当发现在整个项目中,生命周期长的对象偏多,那么就可以通过调整老年代的大小,来进行调优 ;
-
在 HotSpot 中,Eden 空间和另外两个 survivor 空间缺省所占的比例是 8 : 1 :1,当然开发人员可以通过选项**-XX:SurvivorRatio**调整这个空间比例。比如-XX:SurvivorRatio=8,新生区的对象默认生命周期超过 15 ,就会去养老区养老。
5. 分代收集思想 Minor GC、Major GC、Full GC
JVM 在进行 GC 时,并非每次都新生区和老年区一起回收的,大部分时候回收的都是指新生区。针对 HotSpot VM 的实现,它里面的 GC 按照回收区域又分为两大类型:一种是部分收集,一种是整堆收集。
-
部分收集:不是完整收集整个 java 堆的垃圾收集.其中又分为:
-
新生区收集(Minor GC/Yong GC):只是新生区(Eden,S0,S1)的垃圾收集;
-
老年区收集(Major GC / Old GC):只是老年区的垃圾收集;
-
整堆收集(Full GC):收集整个 java 堆和方法区的垃圾收集;
????整堆收集出现的情况:
-
-
?System.gc();时;
-
老年区空间不足;
-
方法区空间不足;
-
开发期间尽量避免整堆收集。
-
6.?堆空间的参数设置
7. 字符串常量池
字符串常量池为什么要调整位置?
JDK7 及以后的版本中将字符串常量池放到了堆空间中。因为方法区的回收效率很低,在 Full GC 的时候才会执行永久代的垃圾回收,而 Full GC 是老年代的空间不足、方法区不足时才会触发。
这就导致字符串常量池回收效率不高,而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
七、方法区
1. 方法区的基本理解
方法区,是一个被线程共享的内存区域。其中主要存储加载的类字节码、class/method/field 等元数据、static final 常量、static 变量、即时编译器编译后的代码等数据。另外,方法区包含了一个特殊的区域“运行时常量池”。
Java 虚拟机规范中明确说明:尽管所有的方法区在逻辑上是属于堆的一部分,但对HotSpotJVM 而言,方法区还有一个别名叫做 Non-Heap(非堆),目的就是要和堆分开。
所以,方法区看做是一块独立于 java 堆的内存空间。
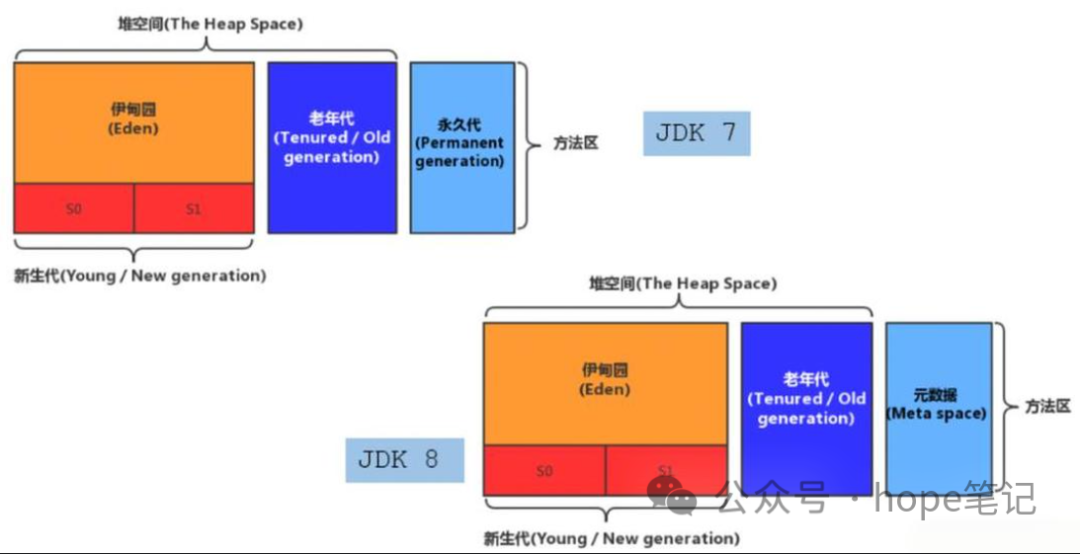
方法区在 JVM 启动时被创建,并且它的实际的物理内存空间中和 Java 堆区一样都可以是不连续的。
方法区的大小,跟堆空间一样,可以选择固定大小或者可扩展。
方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出, 虚拟机同样会抛出内存溢出的错误。
关闭 JVM 就会释放这个区域的内存。
2. 方法区大小设置
Java 方法区的大小不必是固定的,JVM 可以根据应用的需要动态调整。
-
元数据区大小可以使用参数-XX:MetaspaceSize 和 -XX:MaxMataspaceSize 指定,替代上述原有的两个参数;
-
默认值依赖于平台,windows 下,-XXMetaspaceSize 是 21MB;
-
-XX:MaxMetaspaceSize 的值是-1,级没有限制;
-
这个-XX:MetaspaceSize 初始值是 21M 也称为高水位线 一旦触及就会触发 Full GC;
-
因此为了减少 FullGC 那么这个-XX:MetaspaceSize 可以设置一个较高的值;
3.?方法区的内部结构
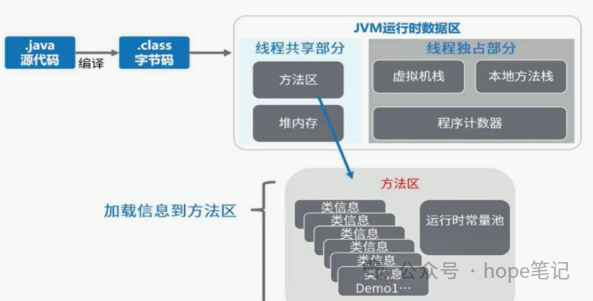
方法区它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存,运行常量池等。
运行常量池就是一张表,虚拟机指令根据这张表,找到要执行的类名、方法名、参数类型、字面量(常量)等信息,存放编译期间生成的各种字面量(常量)和符号引用。
通过反编译字节码文件查看:
反编译字节码文件,并输出值文本文件中,便于查看。参数 -p 确保能查看private 权限类型的字段或方法。
4.?方法区的垃圾回收
有些人认为方法区(如 Hotspot 虚拟机中的元空间或者永久代)是没有垃圾收集行为的,其实不然。《Java 虚拟机规范》对方法区的约束是非常宽松的,提到过可以不要求虚拟机在方法区中实现垃圾收集;
一般来说这个区域的回收效果比较难令人满意,尤其是类型的卸载,条件相当苛刻。但是这部分区域的回收有时又确实是必要的;
方法区的垃圾收集主要回收两部分内容:运行时常量池中废弃的常量和不再使用的类型。
判定一个常量是否“废弃”还是相对简单,而要判定一个类型是否属于“不再被使用的类”的条件就比较苛刻了。需要同时满足下面三个条件:
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类及其任何派生子类的实例。
加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如 OSGi、JSP 的重加载等,否则通常是很难达成的。
该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java开发中常见问题解决:如执行Jar包报“jar中没有主清单属性”等问题解决
- 使用Python开发连连看游戏的技术指南
- 【Vue2+3入门到实战】(21)认识Vue3、使用create-vue搭建Vue3项目、熟悉项目和关键文件
- # 大模型实战作业02
- 数据分析工具PlotJuggler使用小技巧
- 微信小程序性能优化
- Java中String类常用方法详解
- 充电桩检测系统
- 学习鸿蒙开发需要报培训班吗?
- Dubbo架构设计解析