CatBoost算法是如何工作的及使用示例
CatBoost是一个缩写词,指的是“分类提升”,旨在在分类和回归任务中表现良好。CatBoost处理分类变量而不需要手动编码的能力是其主要优势之一。它采用了一种称为有序提升的方法来处理分类特征所面临的困难,如大基数。这使得CatBoost能够自动处理分类数据,节省用户的时间和精力。CatBoost的基本思想是能够有效地处理分类特征。它实现了一种名为有序提升的新技术,该技术通过排列分类变量来生成数值表示。该方法在保持类别信息的同时允许模型使用强大的梯度提升技术。
什么是CatBoost?
CatBoost是Yandex开发的尖端算法,是无缝,高效和令人兴奋的机器学习,分类和回归任务的首选解决方案。凭借其创新的有序提升算法,CatBoost通过利用决策树的力量将预测提升到新的高度。在本文中,您将探索catboost算法的工作原理。
CatBoost的主要功能
与CatBoost相关的主要功能如下:
- 梯度提升:它是一种功能强大的集成学习技术,它结合了弱预测模型(通常是决策树)来构建一个功能强大的预测模型。它的工作原理是迭代地将新模型添加到集合中,每个模型都经过训练以纠正先前模型所犯的错误。CatBoost使用梯度提升,通过关注错误分类的示例来提高模型的准确性。
- 分类特征:分类特征,如颜色或类型,是反映定性数据的变量。CatBoost有效地处理分类特征,而不需要大量的预处理或一次性编码,使其成为现实世界数据集的有效工具。
- 学习率:学习率控制模型在提升阶段学习的步长。为了平衡模型的学习速度和准确性,CatBoost会根据数据集特征自动选择理想的学习率。
- L2正则化:它也被称为岭正则化,在损失函数中引入惩罚项以防止过拟合并提高模型的泛化能力。在CatBoost的上下文中,L2正则化是一个关键特性,有助于控制提升树的复杂性。它通过在训练过程中使用的损失函数中添加正则化项来实现这一点。
Catboost如何工作
CatBoost是一种强大的梯度提升技术,专为机器学习任务而设计,特别是那些涉及结构化输入的任务。它利用了梯度提升的概念,这是一种集成学习方法。该算法首先进行初始猜测,通常是目标变量的平均值。然后,它逐渐构建决策树的集合,每棵树的目标是减少前一棵树的错误或残差。
CatBoost的主要优势之一是它能够有效地处理分类特征。它采用了一种称为“有序提升”的技术来直接处理分类数据,从而加快了训练速度并提高了模型性能。这是通过以保持类别的自然顺序的方式对类别特征进行编码来实现的。
为了防止过度拟合,CatBoost结合了正则化技术。这些技术在训练过程中引入了惩罚或约束,以阻止模型变得过于复杂和过于接近训练数据。正则化有助于泛化模型,使其对未知数据更具鲁棒性。
该算法通过使用梯度下降最小化损失函数来迭代地构造树的集合。在每次迭代中,它计算损失函数相对于当前预测的负梯度,并将新树拟合到负梯度。学习率决定了梯度下降过程中的步长。重复该过程,直到已经添加了预定数量的树或已经满足收敛标准。在进行预测时,CatBoost会将来自集合中所有树的预测组合在一起。这种预测的聚合导致高度准确和可靠的模型。
从数学上讲,
CatBoost可以表示如下:
给定具有N个样本和M个特征的训练数据t,其中每个样本表示为(x_i,y_i),因为x_i是M个特征的向量,y_i是对应的目标变量,CatBoost旨在学习预测目标变量y的函数F(x)。
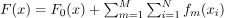
其中,
F(x)表示CatBoost旨在学习的整体预测函数。它接受一个输入向量x并预测相应的目标变量y。
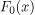
是最初的猜测或基线预测。它通常被设置为训练数据集中目标变量的平均值。此项捕获目标变量的总体平均行为。
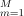
表示所有树的总和。M表示集合中的树的总数。
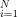
表示训练样本的总和。N表示训练样本的总数。
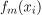
表示对第i个训练样本的第m棵树的预测。集合中的每棵树通过对每个训练样本进行自己的预测来对整体预测做出贡献。
该方程指出,通过将初始猜测F_0(x)与每个训练样本的每个树f_m(x_i)的预测相加,获得总体预测F(x)。对所有树(m)和所有训练样本(i)执行该求和。
开始使用CatBoost
步骤1:导入必要的库
在我们开始编码之前,我们必须首先导入适当的库。我们将使用pandas包进行数据操作,使用CatBoost库实现算法。
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from matplotlib import pyplot as plt
from sklearn.preprocessing import LabelEncoder
步骤2:加载数据集
titanic_data = pd.read_csv('titanic.csv')
titanic_data = titanic_data.drop(['Name', 'Ticket', 'Cabin'], axis=1)
步骤3:预处理数据集
将对数据集执行预处理过程。将处理缺失值,分类变量将转换为数字表示,数据将分为训练集和测试集。
#handle missing values
titanic_data['Age'].fillna(titanic_data['Age'].mean(), inplace=True)
titanic_data['Embarked'].fillna(titanic_data['Embarked'].mode()[0], inplace=True)
# Convert categorical variables to numeric
le=LabelEncoder()
titanic_data[['Sex','Embarked']] = titanic_data[['Sex','Embarked']].apply(le.fit_transform)
# Split the data into features and target
X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
y = titanic_data['Survived']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
步骤4:设置和训练CatBoost模型
我们现在将初始化CatBoostClassifier并定义训练超参数。我们将确定迭代次数、学习率和树深度。最后,将模型拟合到训练数据。
model = CatBoostClassifier(iterations=100, learning_rate=0.1, depth=6)
model.fit(X_train, y_train) # fit the model to training data
步骤5:评估模型的性能
我们可以在训练后的测试数据上评估模型的性能。为了了解模型的精确度、召回率和F1得分,我们将计算准确度得分并提供分类报告。
y_pred = model.predict(X_test) # Predict on the testing data
accuracy = accuracy_score(y_test, y_pred) #model performance
classification_report = classification_report(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:\n", classification_report)
输出
98: learn: 0.3625223 total: 257ms remaining: 2.59ms
99: learn: 0.3621516 total: 259ms remaining: 0us
Accuracy: 0.7988826815642458
Classification Report:
precision recall f1-score support
0 0.79 0.89 0.84 105
1 0.81 0.68 0.74 74
accuracy 0.80 179
macro avg 0.80 0.78 0.79 179
weighted avg 0.80 0.80 0.80 179
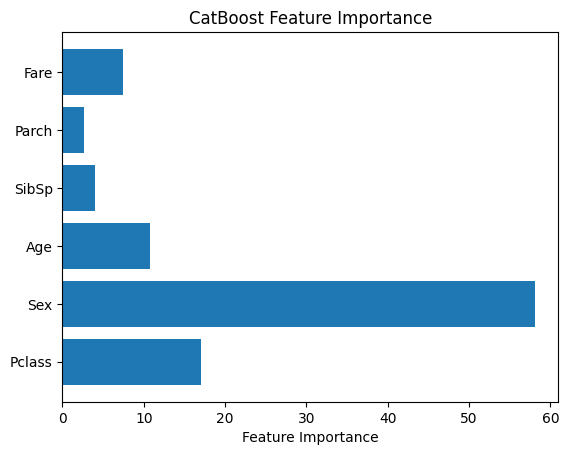
步骤6:CatBoost的特征重要性
CatBoost包括一个内置的特征重要性方法,用于确定模型中每个特征的重要性。可以使用条形图来显示特征显著性分数。
feature_importance = model.get_feature_importance()
feature_names = X.columns
plt.bar(feature_names, feature_importance)
plt.xlabel("Feature Importance")
plt.title("CatBoost Feature Importance")
plt.show()
总结
总而言之,CatBoost是一个功能强大且用户友好的梯度增强库,适用于广泛的应用。无论您是寻找简单机器学习方法的新手,还是寻找顶级性能的经验丰富的从业者,CatBoost都是您工具箱中的有用工具。然而,与任何工具一样,它的成功取决于单个问题和数据集,因此使用它并将其与其他技术进行比较总是一个好主意。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Impala大数据框架学习网站,大数据技能提升必备利器!
- 三维模型数据的高程偏差的几何坐标纠正技术方法浅析
- 【MySQL】sum 函数和 count 函数的相同作用
- 【LeetCode: 238. 除自身以外数组的乘积 +前缀后缀】
- Chatgpt【问心一语】线上运营代理火热招募中!
- 嵌入式学习-IO进程线程-Day6
- 计算机网络——网络模型的组织、看法以及标准化流程
- 机器学习分类
- 公司创建百度百科需要哪些内容?
- 多个table的选中问题