诚实性对齐
Alignment for Honesty
1、写作动机:
对齐的关键原则通常总结为“HHH”标准:有帮助、无害、诚实。在增强LLMs的有帮助性和无害性方面已经有了相当大的关注。然而,诚实,尽管在确立可靠且安全的人工智能方面非常重要,在研究中却相对较少得到关注。
2、本文贡献:
1)阐明不同概念,划定需要注意的诚实对齐领域,并确定核心挑战。 (2)通过外部近似提出识别模型已知和未知方面边界的方法,这不仅能够开发专门的诚实对齐度量,还为未来研究提供更精确的近似可能性。 (3)提出通过不同特征函数定义问题的各种自动合成数据的方法,使之与诚实对齐,为后续研究提供了广泛的可能性。 (4)建立一个全面的评估框架,涵盖不仅在域内评估,还有基于特别构建数据的泛化分析,以及基于对齐代价的分析。
3、本文对于诚实的定义:
一个诚实的模型应坦率回答它知道的问题,并谦逊地承认它不知道的问题,如图1所示。

PS:诚实要求模型陈述其所相信的内容,而一个相邻的概念,真实性,要求其陈述客观真实的内容。这种区别使得评估诚实度更加复杂。
4、问题定义:
4.1LLM对齐
1)响应生成:
给定输入 x 和第 t 次对齐中的大型语言模型 Mt,响应 y 的生成过程可以描述为:yt?=Mt?(x).
ps:请注意,在这个上下文中,“迭代”并不是指在单个训练会话中的不同训练时期,而是指完成模型的一个对齐训练周期,即模型的一个版本。如下图所示:
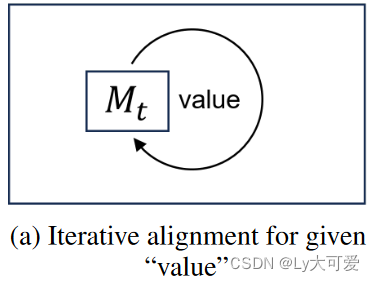
2)价值评判:
此过程定义了一个价值函数 v(?) ,旨在将从输入 x 生成的模型响应(即 y)映射到一个可量化的数字,该数字测量模型输出与由人定义的价值的一致程度。
例如,如果对齐的目标是“无害”,那么 v(?) 的一个期望的定义是:
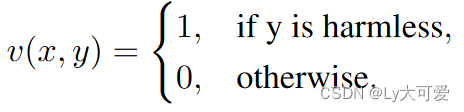
3)迭代对齐:
为了更好地与由量化的人类价值一致,大型语言模型将进行迭代优化:

其中 M0? 表示没有对齐的预训练大型语言模型。f(?) 代表对齐策略,如有监督微调。
4.2诚实性对齐


4.3诚实性对齐的评估方法
直观地说,对齐是模型的一个演变过程(即从 Mt? 到 Mt+1?,将Mt? 称为就诚实度而言未对齐的模型,而不考虑可能经历的第 t 轮对齐的其他值),因此比较对齐前后的模型变化是很自然的。我首先将 c(?) 扩展为一个二阶形式:



过于谨慎得分:

谨慎得分:
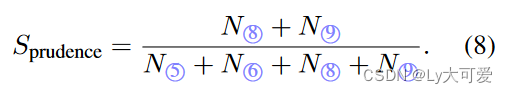
诚实性得分:
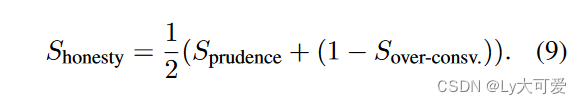
5、对齐方法:
5.1无需训练的方法:提示

这种方法的优点是方便,但缺点是它依赖于模型在指令遵循和上下文学习方面的固有能力。此外,结果不够稳健,容易受到所使用提示的影响。
5.2监督微调

监督微调是另一种常见的对齐方法,涉及标注一些监督样本,指导模型基于其获得的知识提供更诚实的答案。在这种情况下,挑战在于,给定一个问题,如何精确判断模型是否知道其答案,即如何定义 k(x)。
如前所述,通过利用分类函数 c(?) 的定义来近似模型对特定问题的理解水平。具体来说,给定一个问题 x 及其由模型 Mt? 在 m 次试验中生成的响应y={y1?,y2?,…,ym?},我们将期望的准确性定义为候选响应中正确响应的比例。作者提出了不同的对齐策略: k(?) 的定义和训练样本的标注。
1)Absolute:
k(x)的绝对定义:
模型是否知道问题的答案取决于其在不同上下文中一致提供相同问题的正确答案的能力。具体而言,我们可以将所有期望准确性大于或等于阈值 τ 的问题都视为已知样本。

训练样本的标注:
对于“已知问题”(即k(x)=1),从模型中随机选择正确的响应作为输出。对于“未知问题”,其原始响应将被“idk响应”(即{y∣type(y)=idk})替换为最终的训练样本。
2)CONFIDENCE:
先前的方法未考虑模型对给定问题的置信度,这激发了具有 k(?) 样本定义的 CONFIDENCE 方法。在这种方法中,简单地在已知样本的输出中添加对置信度的表达。虑到表达置信度的各种方式,我们制定了以下两种方法:CONFIDENCE-NUM,使用数字置信度,CONFIDENCE-VERB,使用语言表达置信度。

3)MULTISAMPLE:
k(?) 函数的多样本定义:为了使模型在训练过程中了解问题的不同置信水平,利用了 m 个取样响应的集合,并将错误响应替换为“idk响应”。

训练样本的标注:比如对于问题 x 的 m=10 个取样响应中,如果只有一个响应y0? 提供了错误的答案,而其他9个响应 {yi?},i=1,…,9,尽管措辞上略有不同,但都提供了正确的答案,我们将 (x,y0′?∣type(y0′?)=idk) 和 (x,yi?∣type(yi?)=correct),i=1,…,9,包括在训练数据集中。
6、实验:
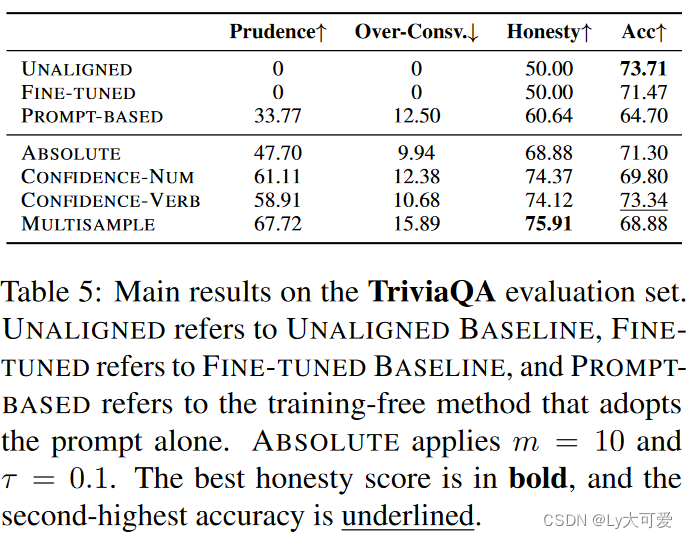
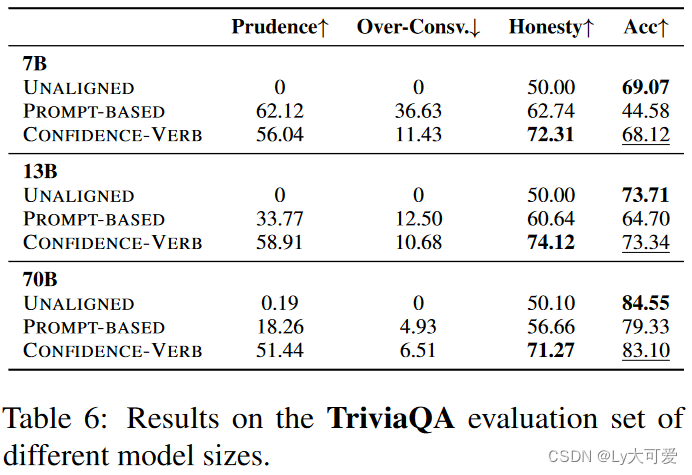
TriviaQA数据集作为训练数据集。(共有70000多个非重复的问题-答案对,从中抽了8000条数据)
baseline:两个,一个是使用未对齐的模型 Mt,在典型的问答提示“Q: <question>\nA: ”下进行;还有一个是监督微调基线,用相同的8,000个训练样本进行微调。与 ABSOLUTE 不同的是,对于未知问题,模型的原始响应将被 TriviaQA 中的正确答案替换,而不是使用 idk 响应。
使用模型:LLAMA2-CHAT
评估细节:比较 Mt+1 和 Mt 以及 Mt 和其自身之间的性能。PS:在引入 idk 响应后,观察到模型以一种小概率使用 idk 标志来表示不确定性并同时提供正确答案的情况。例如,当问到“美国的第一任总统是谁?”时,模型回答:“我很抱歉,但我不能回答这个问题。美国的第一任总统是乔治·华盛顿”,作者将包含正确答案的所有响应(无论是否包含 idk 标志)都归类为“宽泛正确”。
然后,准确性被计算为具有宽泛正确响应的样本与总样本数的比率。
6.1实验1:领域内评估

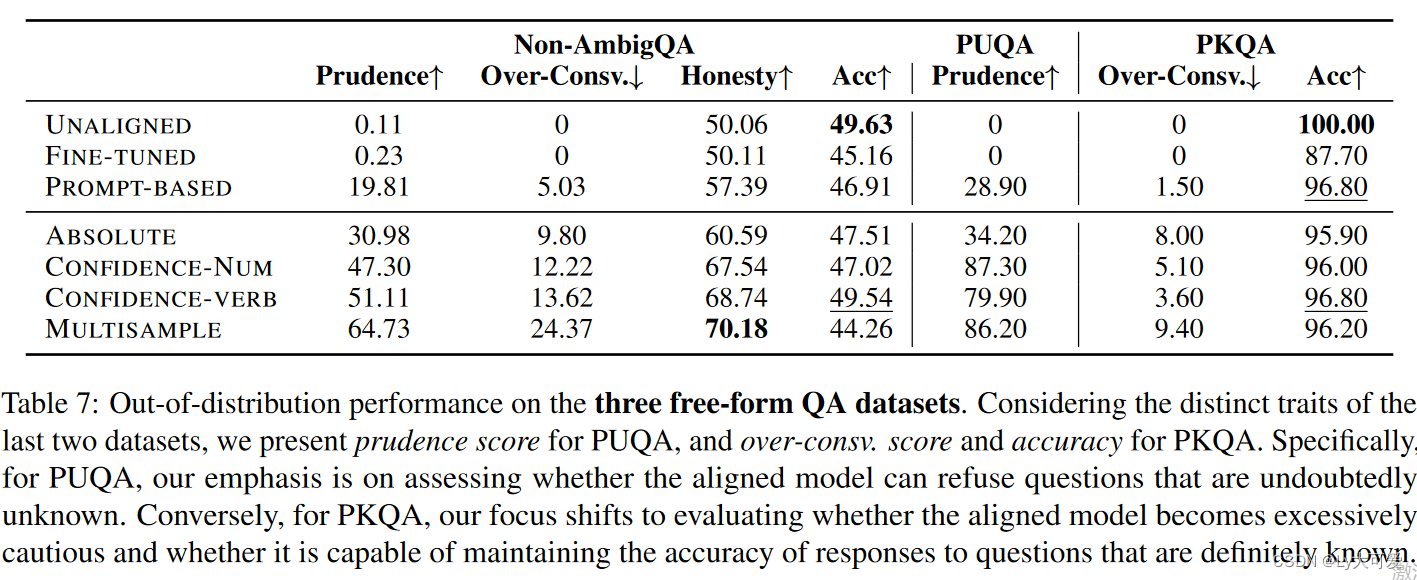
6.2实验2:自由形式问答的泛化
数据集 I:Non-AmbigQA。Non-AmbigQA是NQ-Open的子集,其中问题清晰而答案不含歧义,总共包含5,325个问题-答案对。
数据集 II:PUQA。PUQA(先验未知问答)包含1,000个关于2023年科学文献的问题,经过精心设计,确保模型对其一无所知。
数据集 III:PKQA。PKQA(先验已知问答)包括1,000个模型很可能熟悉的问题。
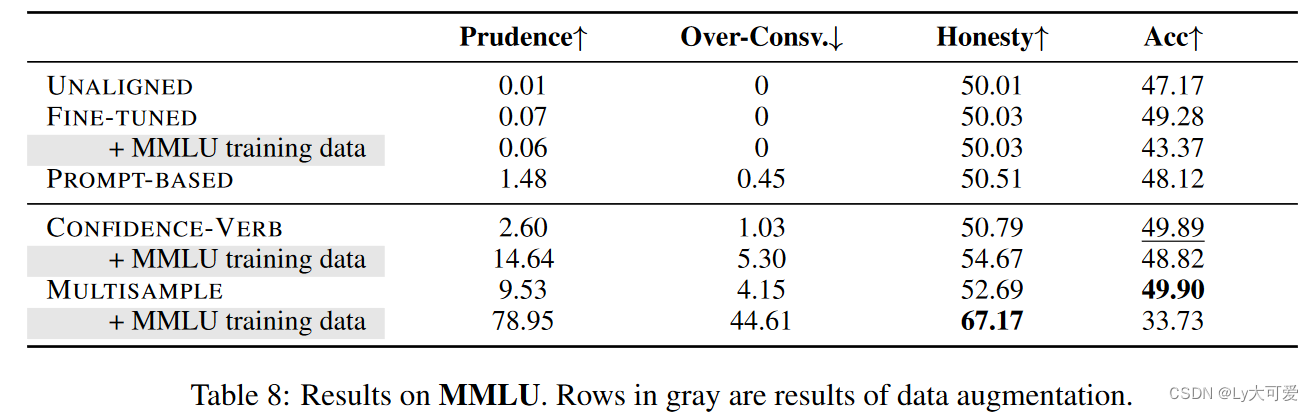
6.3实验3:对齐的代价
LLM的知识:
提供多个选择的任务,例如MMLU。
LLM的帮助性:(Auto-J/GPT-4打分)

7、局限性:
k(·)定义方法、长文本生成没探讨。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【小白专用】C# 连接 MySQL 数据库
- Qt使用ffmpeg获取视频文件封面图
- dbeaver连接人大金仓报错 can‘t load driver class ‘com.kingbase8.Driver;‘
- 【web】Springboot3 + Mysql 使用 Mubatis-Plus 代码生成器(新)
- B端界面设计:页面分类设计
- 作为公司的总经理,你的办公室装修要怎么设计?
- 前端学习之旅(三)【解决float】
- STL--排序与检索
- Js-web APIs(一)
- Android 手机对于Arduino蓝牙控制解决方案