【Python机器学习系列】建立KNN模型预测心脏疾病(完整实现过程)
这是Python程序开发系列原创文章,我的第198篇原创文章。
一、问题
?对于表格数据,一套完整的机器学习建模流程如下:

????? ? 针对不同的数据集,有些步骤不适用即不需要做,其中橘红色框为必要步骤,由于数据质量较高,本文有些步骤跳过了,跳过的步骤将单独出文章总结!同时欢迎大家关注翻看我之前的一些相关文章。
【Python机器学习系列】一文彻底搞懂机器学习中表格数据的输入形式(理论+源码)
【Python特征工程系列】利用随机森林模型分析特征重要性(源码)
【Python特征工程系列】8步教你用决策树模型分析特征重要性(源码)
【Python机器学习系列】拟合和回归傻傻分不清?一文带你彻底搞懂它
【Python机器学习系列】建立决策树模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立支持向量机模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立逻辑回归模型预测心脏疾病(完整实现过程)
? ? ? ??K最近邻(K-Nearest Neighbors,KNN)是一种基本的监督学习算法,用于分类和回归问题。KNN算法基于实例之间的相似性度量,通过将新样本与训练集中的最近邻样本进行比较,来进行预测或分类。KNN算法的基本思想是:如果一个样本在特征空间中的K个最近邻中的大多数属于某个类别,那么该样本很可能属于该类别。KNN算法不需要显式的训练过程,而是在预测阶段对每个新样本进行计算和比较。
??????? KNN算法的关键参数是K值,即选择的最近邻样本的数量。较小的K值会使模型更加敏感,容易受到噪声的影响,而较大的K值会使模型更加平滑,但可能忽略了样本内部的细节。KNN算法的优点包括简单易懂、不需要训练过程(即懒惰学习)和对于非线性问题具有较好的适应性。然而,KNN算法的缺点是计算复杂度高,对于大型数据集和高维数据效果可能不佳,并且对于不平衡数据集和噪声敏感。在实际应用中,可以通过交叉验证或网格搜索等技术来选择合适的K值,并对数据进行预处理(如特征缩放)以提高算法的性能。scikit-learn是一个流行的Python机器学习库,提供了各种机器学习算法的实现,包括K近邻(KNN)算法。在scikit-learn中,KNN算法的实现主要集中在sklearn.neighbors模块中。
????????本文将实现基于心脏疾病数据集建立KNN模型对心脏疾病患者进行分类预测的完整过程。
二、实现过程
导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report1、准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)df:
数据基本信息:
print(df.head())
print(df.info())
print(df.shape)
print(df.columns)
print(df.dtypes)
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名2、提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts())?#?顺便查看一下样本是否平衡3、数据集划分
df = shuffle(df)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)4、模型的构建与训练
# 模型的构建与训练
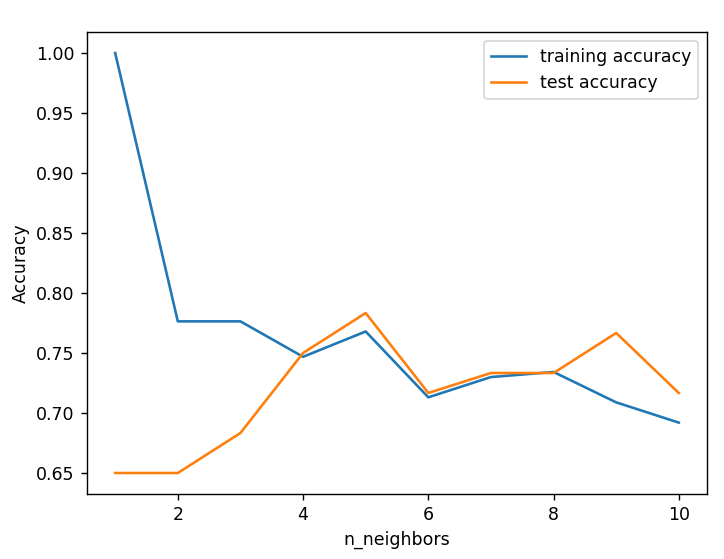
training_accuracy = []
test_accuracy = []
# try n_neighbors from 1 to 10
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
training_accuracy.append(knn.score(X_train, y_train))
test_accuracy.append(knn.score(X_test, y_test))
plt.figure()
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)选择最佳的K=5:
参数详解:
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)- n_neighbors:这个值就是指 KNN 中的 “K”了。前面说到过,通过调整 K 值,算法会有不同的效果。
- weights(权重):最普遍的 KNN 算法无论距离如何,权重都一样,但有时候我们想搞点特殊化,比如距离更近的点让它更加重要。这时候就需要 weight 这个参数了,这个参数有三个可选参数的值,决定了如何分配权重。参数选项如下:? ? ? ?
-
?'uniform':不管远近权重都一样,就是最普通的 KNN 算法的形式。? ? ? ?
-
'distance':权重和距离成反比,距离预测目标越近具有越高的权重。? ? ? ?
-
自定义函数:自定义一个函数,根据输入的坐标值返回对应的权重,达到自定义权重的目的。
- algorithm:在 sklearn 中,要构建 KNN 模型有三种构建方式,1. 暴力法,就是直接计算距离存储比较的那种放松。2. 使用 kd 树构建 KNN 模型 3. 使用球树构建。其中暴力法适合数据较小的方式,否则效率会比较低。如果数据量比较大一般会选择用 KD 树构建 KNN 模型,而当 KD 树也比较慢的时候,则可以试试球树来构建 KNN。参数选项如下: ? 'brute' :蛮力实现 ? 'kd_tree':KD 树实现 KNN ? 'ball_tree':球树实现 KNN ? 'auto':默认参数,自动选择合适的方法构建模型 不过当数据较小或比较稀疏时,无论选择哪个最后都会使用 'brute'
- leaf_size:如果是选择蛮力实现,那么这个值是可以忽略的,当使用KD树或球树,它就是是停止建子树的叶子节点数量的阈值。默认30,但如果数据量增多这个参数需要增大,否则速度过慢不说,还容易过拟合。
- p:和metric结合使用的,当metric参数是"minkowski"的时候,p=1为曼哈顿距离, p=2为欧式距离。默认为p=2。
- metric:指定距离度量方法,一般都是使用欧式距离。
? ? ? ? ? 'euclidean' :欧式距离
? ? ? ? ? 'manhattan':曼哈顿距离
? ? ? ? ? 'chebyshev':切比雪夫距离
? ? ? ? ? 'minkowski':闵可夫斯基距离,默认参数
- n_jobs:指定多少个CPU进行运算,默认是-1,也就是全部都算。
5、模型的推理与评价
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
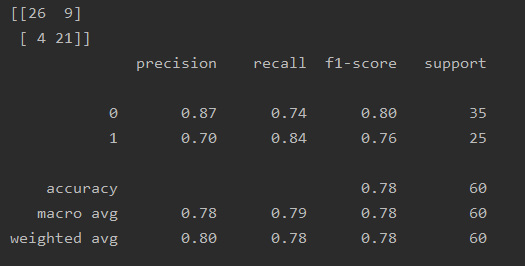
acc = accuracy_score(y_test, y_pred) # 准确率acc
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
cr = classification_report(y_test, y_pred) # 分类报告
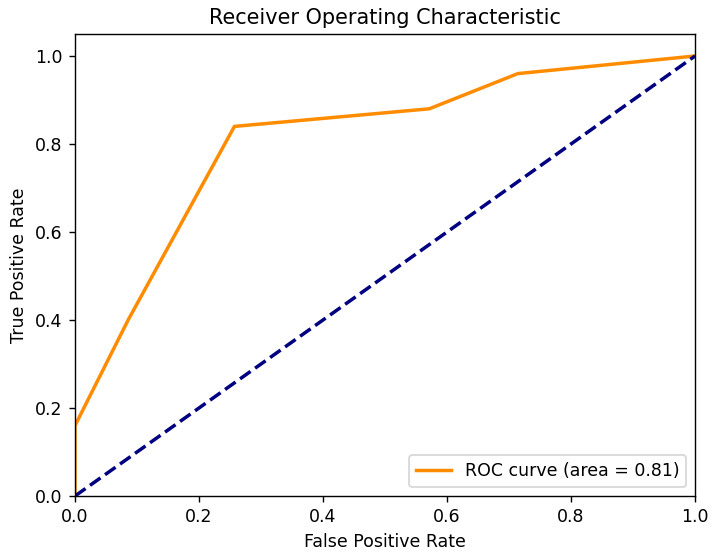
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()cm和cr:
ROC:
三、小结
????????本文利用scikit-learn(一个常用的机器学习库)实现了基于心脏疾病数据集建立KNN模型对心脏疾病患者进行分类预测的完整过程。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信! ? ?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 新年福利,终极幻想-上一波美女大模型
- 「实战应用」如何用DHTMLX Gantt构建类似JIRA式的项目路线图(一)
- assert断言
- “当实力撑不起野心的时候,学习才是唯一的出路”(2023回顾与展望)
- 实战演练:利用XSS漏洞执行CSRF攻击
- 世微AP8105 低功耗PFM DC-DC变换器 升压芯片多种分装
- 抽象类(没有对象)之引用对象失败之谜
- 以Tabs作为例子介绍鸿蒙组件的结构
- 台达B3 系列伺服串口命令破解
- selenium如何使用隧道代理请求目标地址?