MiniTab的拟合回归模型的系列参数设置
为拟合回归模型指定模型项
统计?> 回归?> 回归?> 拟合回归模型?> 模型
可以向模型添加交互作用项和多项式项。默认情况下,模型仅包含在主对话框中输入的预测变量的主效应。添加项的方法有很多。假设预测变量列表具有 3 个连续变量 X、Y、Z 和 2 个类别变量 A、B。
使用选定预测变量和模型项添加项
要向模型添加项,请选择至少一个预测变量或项。要选择多个项或取消选择一个项,请在单击预测变量或项的同时,按 Ctrl 键。在添加交互作用项和更高阶项时,预测变量的多重共线性会增加。
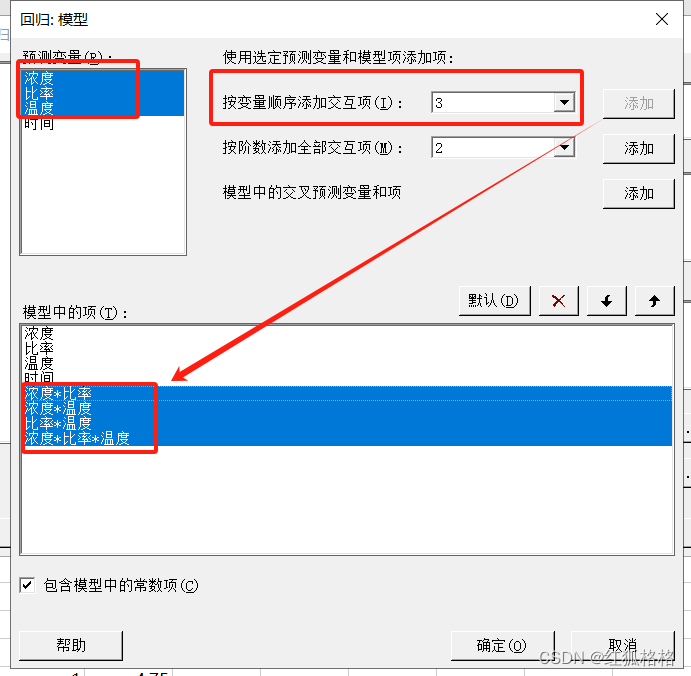
按变量顺序添加交互项
通过指定的顺序添加所有交互作用项。假设按阶数 3 选择预测变量 X、Y、A 和添加交互作用项。单击添加后,Minitab 会添加 X*Y、X*A、Y*A、X*Y*A。
?上述设置进行模型回归之后,回归方程参考如下图:

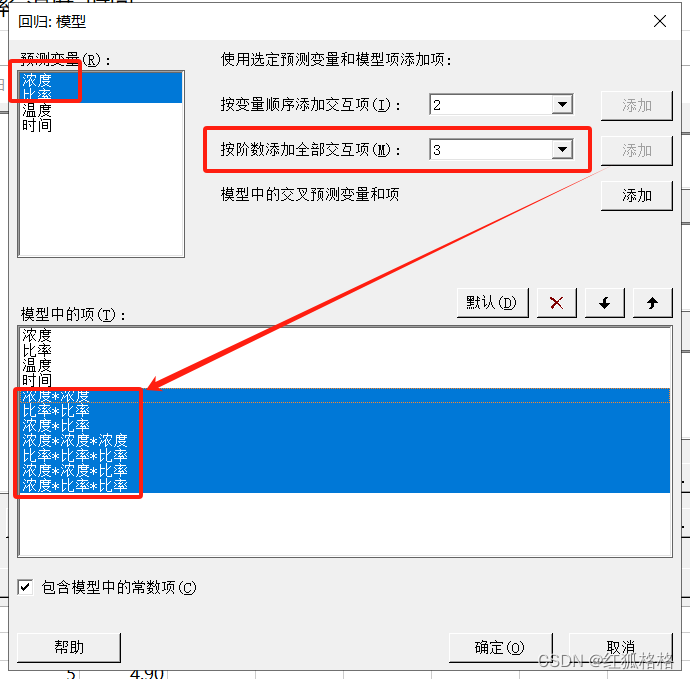
按阶数添加全部交互项
用于建模弯曲。此选项通过指定的顺序添加幂和交互作用项。幂用于连续预测变量。假设通过顺序 3 选择了 X、Y、A 和多个项。单击添加后,Minitab 会添加 X 和 Y 的幂项:X*X、Y*Y、X*X*X、Y*Y*Y。Minitab 还会添加预测变量和幂的交互作用项:X*Y、X*A、Y*A、X*X*Y、X*Y*Y、X*X*A、X*Y*A、Y*Y*A。
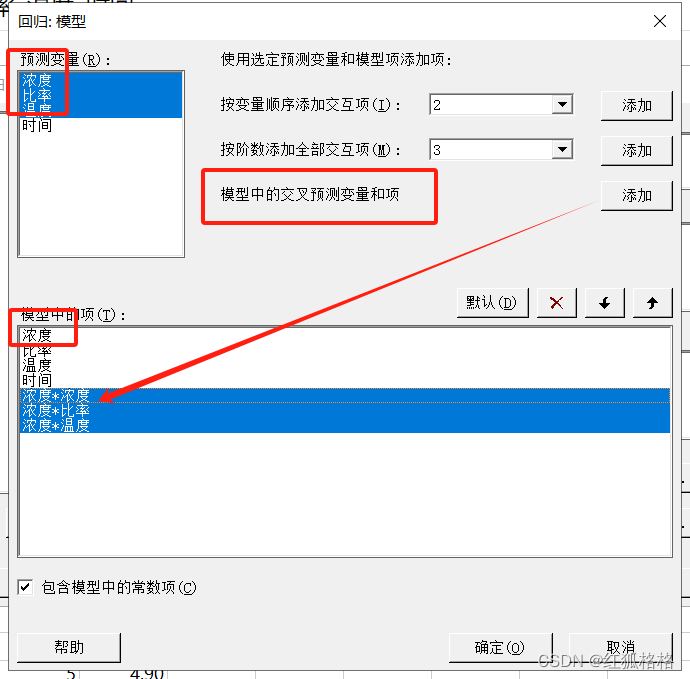
模型中的交叉预测变量和项
此选项可通过以下方式使用:
- 可以交叉两个或更多预测变量。假设选择了 X、Y、Z。单击添加时,Minitab 会添加以下项:X*X、X*Y、X*Z。
- 可以将已存在于模型中的项进行交叉。假设 X*A 和 X*B 已经存在于模型中。如果仅选择这些项并单击添加,则 Minitab 会添加 X*X*A*B。
- 可以在模型中将预测变量与项相交叉。假设 X*X 和 Y*Y 已存在于模型中。如果选择了这些项和预测变量 A、B,然后单击添加,Minitab 会添加 X*X*A、X*X*B、Y*Y*A、Y*Y*B。每个预测变量都与每个模型项交叉,但是预测变量不与它们本身交叉,模型项也不与它们本身交叉。
注意:可能需要取消选择预测变量或项,这样就会只选择希望交叉的项。要取消选择项,请在单击预测变量或项的同时,按 Ctrl 键。
模型中的项
当向模型添加项时,这些项会列在对话框的空白处。可以选择单独的项或多组项进行删除或重新排序等操作。
包含模型中的常数项
选择以便子回归模型中包含常量项。在大多数情况下,应当在模型中包含常量。
删除常量可能是因为在预测变量值等于 0 时假设响应变量为 0。例如,如果存在可以根据食物的脂肪、蛋白质及碳水化合物含量预测卡路里的模型。当脂肪、蛋白质和碳水化合物为 0 时,卡路里含量也将为 0(或非常接近于 0)。
比较不包括常量的模型时,请使用 S 而不是 R2 统计量来评估模型的拟合值。
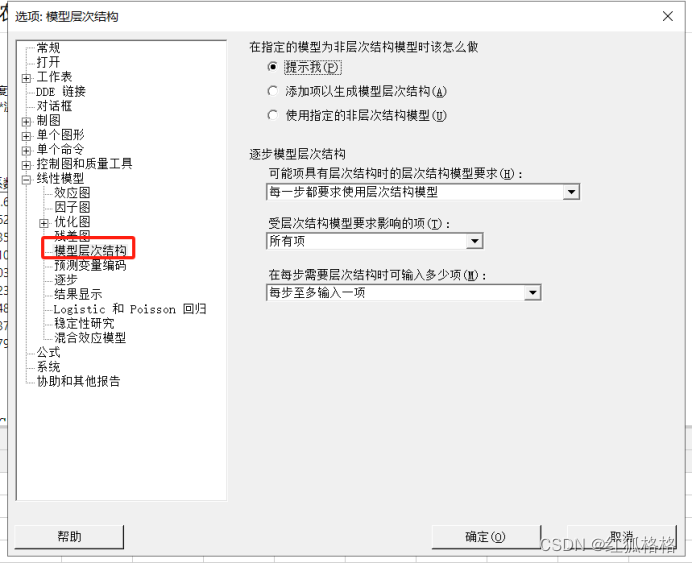
为拟合回归模型指定分层模型
统计?> 回归?> 回归?> 拟合回归模型?> 模型
用于允许 Minitab 向模型添加显示的项以便创建分层模型。在分层模型中,组成高阶项的所有低阶项也将在模型中显示。例如,包含交互作用项 A*B*C 的模型要作为分层结构,必须同时包括 A、B、C、A*B、A*C 和 B*C 项。
模型可能是非分层的。通常,如果低阶项不显著,可以将其删除。包含过多项的模型可能相对来说不太精确,会降低预测新观测值的能力。
请考虑以下技巧:
- 首先拟合分层模型。可稍后再删除不显著的项。
- 如果对预测变量进行标准化,请拟合分层模型以便生成未编码(或自然)单位的方程。
- 如果模型包含类别变量,在类别项至少分层的情况下,结果会更易于解释。
指定 Minitab 是否向模型添加项。
- 添加用于生成模型层次结构的项 (推荐):Minitab 将添加显示的项以便生成分层模型。
- 使用指定的非层次结构模型:Minitab 不会添加项。
此后使用此选项
选择此选项可使的选项成为默认选项。后续将跳过此对话框。如果要查看此选项,可以在文件?> 选项?> 线性模型?> 模型层次结构中更改设置。
选择适用于拟合回归模型的选项
统计?> 回归?> 回归?> 拟合回归模型?> 选项?
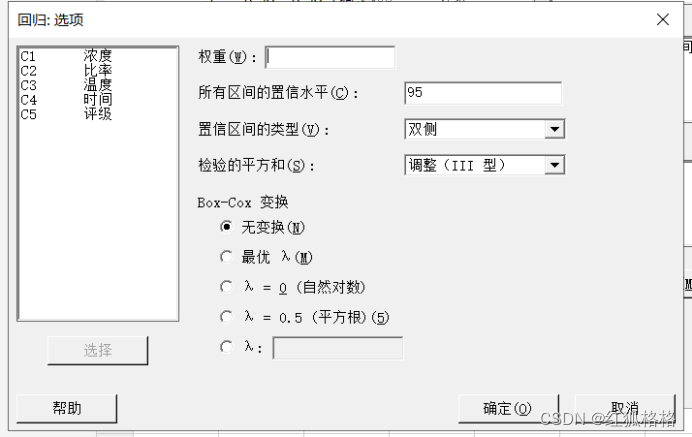
权重
在权重中,输入用于执行加权回归的权重数列。加权回归是一种可以在违反残差中常量方差的最小二乘假设(也称为异方差性)时使用的方法。如果权重正确,此过程会使加权平方残差和最小化,从而产生具有常量方差的残差(也称为同方差性)。
权重必须大于或等于零。权重列的行数必须与响应列的行数相同。
所有区间的置信水平
输入系数和拟合值的置信区间的置信水平。
通常,置信水平为 95% 即可。95% 置信水平表明,如果从总体中随机抽取 100 个样本,则大约 95 个样本的置信区间中将包含响应均值。对于给定的数据集,置信水平越低,生成的区间越窄;置信水平越高,生成的区间越宽。
置信区间的类型
可以选择一个双侧区间或一个单侧边界。对于同一置信水平,边界与区间相比,更接近于点估计值。上限不提供可能的更低值。下限不提供可能的更高值。
例如,水中溶解性固体的预测平均浓度为 13.2 mg/L。多个未来观测值的均值的 95% 置信区间为 12.8 mg/L 到 13.6 mg/L。多个未来观测值的均值的 95% 上限为 13.5 mg/L,该值更为精确,因为边界更接近于预测均值。
双侧:使用双面置信区间来同时估计平均响应的可能的下限值和上限值。
下限:使用置信下限估计均值响应可能的下限值。
上限:使用置信上限来估计平均响应的可能的上限值。
检验的平方和
选择用于计算 F 值和 p 值的平方和 (SS)。调整的 SS 最常用。使用连续平方和,根据项输入模型的顺序来确定项的显著性。
检验的平方和
- 调整(III 型):表示当项添加到包含所有其余项的模型后,误差平方和有所减少。
- 序贯(I 型):表示当项添加到仅包含前一个项的模型后,误差平方和有所减少。
Box-Cox 变换
当残差未呈正态分布或不具有常量方差时,对响应数据执行 Box-Cox 变换。当变换数据时,Minitab 会变换响应数据并将其用于分析。在大多数情况下,除非数据的偏斜非常大,否则不必纠正非正态性。使用 Box-Cox 变换时,所有响应数据必须为正 (>0)。要确定 Box-Cox 变换对于数据是否适宜,请检查残差图和其他诊断度量。
Box-Cox 变换
选择 Minitab 用来变换数据的 lambda 值:
- 无变换:使用原始响应数据。
- 最优 λ:使用应当生成最佳拟合变换的最优 lambda。默认情况下,Minitab 将最优 lambda 值舍入为 ..5 或最接近的整数。例如,Minitab 将 lambda 舍入为 –1、–..5、0、..5、1 等。如果要针对变换使用最优值而非四舍五入值,请选择文件?> 选项?> 线性模型?> 结果显示。
- λ = 0 (自然对数):使用数据的自然对数。
- λ = 0.5 (平方根):使用数据的平方根。
- λ:对 lambda 使用指定的值。其他常见的变换包括平方 (λ = 2)、逆平方根 (λ = ?.5) 和逆 (λ = ?1)。通常情况下,应当使用介于 ?2 和 2 之间的值。
为拟合回归模型执行逐步回归
统计?> 回归?> 回归?> 拟合回归模型?> 逐步
逐步删除项并将其添加到模型中,以便识别有用的项子集。如果选择逐步过程,则在模型对话框中指定的项是最终模型的候选项。

方法
用于拟合模型的方法如下几种选择:?
- 无:使模型与在模型对话框中指定的所有项拟合。
- 逐步:此方法从空模型开始,或包括指定要包含在初始模型或每个模型中的项。然后,Minitab 为每个步骤添加或删除一个项。可以指定要包含在初始模型中或强制包含到每个模型中的项。当模型中未包含的所有变量的 p 值大于指定的入选用 Alpha 值时,以及当模型中的所有变量的 p 值小于或等于指定的删除用 Alpha 值时,Minitab 将停止。
- 向前选择法:此方法从空模型开始,或包括指定要包含在初始模型或每个模型中的项。然后,Minitab 为每个步骤添加最重要的项。当模型中未包含的所有变量的 p 值大于指定的入选用 Alpha 值时,Minitab 将停止。
- 向后消元法:此方法从包含所有潜在项的模型开始,并删除每个步骤中最不重要的项。当模型中的所有变量的 p 值小于或等于指定的删除用 Alpha 值时,Minitab 将停止。
- 转发信息标准:转发信息标准过程在每个步骤中向模型添加具有最低 p 值的项。如果分析设置允许考虑非分层项,但要求每个模型具有分层,则其他项可以在 1 个步骤中输入模型。Minitab 计算每个步骤的信息标准。在大多数情况下,该过程将继续,直到出现以下情况之一:
- 该过程在连续 8 个步骤中没有发现标准改进。
- 该过程拟合全模型。
- 该过程拟合误差自由度为 1 的模型。
如果为过程指定要求每个步骤具有分层模型且一次仅允许输入一个项的设置,则该过程将继续,直到它拟合全模型或拟合误差自由度为 1 的模型。Minitab 显示具有所选信息标准(AICc 或 BIC)最小值的模型的分析结果。
- 前进法并验证:前进法并验证过程取决于验证方法。使用检验数据集时,该过程类似于前进法。在每个步骤结束时,Minitab 计算检验 R2 统计量。在前进法过程结束时,具有最大检验 R2 值的模型为最终模型。
通过交叉验证,该过程在每个折叠上重复前进法。该过程评估每个步骤中的所有折叠,并标识具有最佳 K 折叠逐步 R2 值的步骤。该过程的最后一部分是对完整数据集执行前进法,在折叠上选择的最佳步骤处停止。
对于这两种验证类型,该过程在遇到与前进法标准过程相同的停止情况时停止。
注意:最终模型中包含的项取决于模型的层次结构限制。
潜在项
显示过程将评估的项集。列表中项旁边的指示符(E 或 I表示过程处理项的方式。
- E = 在每个模型中包括项:选择一个项并单击此按钮可将项强加于每个模型,而不论其 p 值多少。再次单击按钮可删除此条件。
- I = 在初始模型中包括项:选择一个项并单击此按钮可在初始模型中包含项。如果项的 p 值过高,则该过程可以删除这些项。再次单击按钮可删除此条件。仅当在方法中选择了逐步后,此按钮才可用。
入选用 Alpha和删除
入选用 Alpha
输入 Minitab 所使用的 alpha 值来确定是否可以向模型中输入项。选择方法中的逐步或向前选择法后,可以设置此值。
删除用 Alpha
输入 Minitab 所使用的 alpha 值来确定是否可以从模型中删除项。选择方法中的逐步或向后消元法后,可以设置此值。
标准

AICc 和 BIC 评估模型的似然,然后将用来添加项的惩罚应用于模型。惩罚会降低趋势,以使模型过度拟合样本数据。趋势降低可能会生成性能通常更佳的模型。
一般准则是,当参数个数相对于样本数量较小时,BIC 对于添加每个参数所施加的惩罚比 AICc 大。在这些情况下,最小化 BIC 的模型往往比最小化 AICc 的模型小。
在一些常见情况(如筛选设计)下,参数个数相对于样本数量通常较大。在这些情况下,最小化 AICc 的模型往往比最小化 BIC 的模型小。例如,对于包含 13 个游程的明确筛选设计,在一组包含 6 个或多个参数的模型中,最小化 AICc 的模型往往比最小化 BIC 的模型小。
指定 前进法并验证的验证
注意:验证设置也位于 验证方式 子对话框中。如果更改设置,Minitab 会自动更新这两个位置的设置。
选择 前进法并验证 时,选择用于检验模型的验证方法。通常,对于较小的样本,K 折叠交叉验证方法比较合适。对于较大的样本,可以将数据分为训练数据集和检验数据集。
K 折叠交叉验证
完成以下步骤以使用 K 折叠交叉验证。
- 从下拉列表中,选择 K 折叠交叉验证。
- 选择下列项之一,指定是随机分配折叠还是使用 ID 列来分配。
- 随机分配每个折叠的行: 选择此选项可以让 Minitab 随机选择每个折叠的行。可以指定折叠数。大多数情况下,默认值 10 效果良好。使用更小的 K 值可能会引入更多的偏倚;但是,K 值越大,引入的变异性可能更多。也可以为随机数生成元设置基数。
- 按 ID 列分配每个折叠的行: 选择此选项可选择要包含在每个折叠中的行。在 ID 列 中,输入标识折叠的列。ID 列中具有相同值的每一行都位于同一折叠中。
使用测试集验证
完成以下步骤,将数据分为训练数据集和检验数据集。
- 从下拉列表中,选择 使用测试集验证。
- 选择下列项之一,指定是随机选择一部分行还是使用 ID 列来选择一部分行。
- 随机选择部分行作为测试集: 选择此选项可以让 Minitab 随机选择检验数据集。可以指定在检验数据集中使用的数据量。大多数情况下,默认值 0.3 效果良好。希望在检验数据集中包含足够的数据,以便充分评估模型。如果不确定模型的形式,则较大的检验数据集可提供更有力的验证。还希望在训练数据集中包含足够的数据,以便充分估计模型。通常,具有较多预测变量的模型需要较多的训练数据来进行估计。
- 按 ID 列定义训练/测试拆分: 选择此选项可自行选择要包含在检验数据集中的行。 在 ID 列中, 输入列以指示哪些行用于检验样本。ID 列必须仅包含 2 个值。在 测试集水平中, 选择用作检验样本的水平。
层次结构
可以确定 Minitab 如何在使用逐步法时强制执行模型层次结构。如果在模型对话框中指定非分层模型,将禁用层次结构按钮。
在分层模型中,组成高阶项的所有低阶项也将显示在模型中。例如,包含交互作用项 A*B*C 的模型为分层结构,但前提是该模型包括 A、B、C、A*B、A*C 和 B*C 项。
模型可能是非分层结构。通常情况下,如果低阶项不显著,可以将其删除,除非专业领域知识建议将其包含在模型中。包含过多项的模型的精确度相对较差,可能会降低预测新观测值的能力。
考虑以下建议:
- 首先拟合分层模型。稍后删除不显著项。
- 如果要标准化连续预测变量,请拟合分层模型,以生成用未编码(或自然)单位表示的方程。
- 如果模型包含类别变量,那么当类别项至少是分层结构时,所得出的结果才更易于解释。
层次结构模型
选择逐步过程是否必须生成一个分层模型。
- 每一步都要求使用层次结构模型:Minitab 只能添加或删除保留分层的项。
- 在最后添加项以生成模型层次结构:最初,Minitab 会遵循逐步过程的标准规则。到最后一步,Minitab 会添加生成分层模型的项,即便其 p 值大于入选用 Alpha值也是如此。如果在方法为转发信息标准时选中此选项,Minitab 会显示一个错误。要在这些步骤中在多个模型中获取可最小化该标准的分层模型,请选择每一步都要求使用层次结构模型。
- 不需要使用层次结构模型:最终模型可能是非分层模型。Minitab 仅根据逐步过程规则添加和删除项。
以下项需使用层次结构
如果需要一个分层模型,请选择必须有分层的项类型。?
- 所有项:包含连续变量和/或类别变量的项必须是分层的。
- 具有类别预测变量的项:只有包含类别变量的项才必须是分层的。
每步可输入多少项
如果每一个步骤都需要分层,请选择 Minitab 可以在每一步添加以保留分层的项数。?
- 每步至多输入一项:如果仅在添加单个项时保留层次结构,可以向模型输入高阶项。所有组成高阶项的低阶项必须已经存在于模型中。
- 可以输入额外项以保持层次结构:即便生成了非分层模型,高次项也可输入模型。但是,还会添加生成分层模型所必备的项,即便其 p 值大于 入选用 Alpha 值也是如此。
显示模型选择详细信息表
指定要显示的关于逐步过程的信息。
- 该方法的详细信息:显示在模型中输入和/或删除预测变量的逐步过程类型和 alpha 值。
- 包含每个步骤的详细信息:显示针对过程的每一个步骤的系数、p 值和模型汇总统计量。
显示 R 平方与步骤的图形
选择前进法并验证时,将为前进法的每个步骤显示训练和验证偏差 R2 值的图。通常,该图将用来确定简化模型是否具有相似的验证值。
指定拟合回归模型的验证方法
统计?> 回归?> 回归?> 拟合回归模型?> 验证方式
选择用于检验模型的验证方法。通常,对于较小的样本,K 折叠交叉验证方法比较合适。对于较大的样本,可以选择使用一部分案例来进行训练和检验。
K 折叠交叉验证
完成以下步骤以使用 K 折叠交叉验证。
- 从下拉列表中,选择K 折叠交叉验证。
- 选择下列项之一,指定是随机分配折叠还是使用 ID 列来分配。
- 随机分配每个折叠的行:选择此选项可以让 Minitab 随机选择每个折叠的行。可以指定折叠数。大多数情况下,默认值 10 效果良好。使用更小的 K 值可能会引入更多的偏倚;但是,K 值越大,引入的变异性可能更多。也可以为随机数生成元设置基数。
- 按 ID 列分配每个折叠的行:选择此选项可选择要包含在每个折叠中的行。在 ID 列中,输入标识折叠的列。ID 列中具有相同值的每一行都位于同一折叠中。
- (可选)选中存储 K 折叠交叉验证的 ID 列以保存 ID 列。
使用测试集验证
完成以下步骤,将数据分为训练数据集和检验数据集。
- 从下拉列表中,选择使用测试集验证。
- 选择下列项之一,指定是随机选择一部分行还是使用 ID 列来选择。
- 随机选择部分行作为测试集:选择此选项可以让 Minitab 随机选择检验数据集。可以指定在检验数据集中使用的数据量。大多数情况下,默认值 0.3 效果良好。希望在检验数据集中包含足够的数据,以便充分评估模型。如果不确定模型的形式,则较大的检验数据集可提供更有力的验证。还希望在训练数据集中包含足够的数据,以便充分估计模型。通常,具有较多预测变量的模型需要较多的训练数据来进行估计。
- 按 ID 列定义训练/测试拆分:选择此选项可自行选择要包含在检验样本中的行。在ID 列中,输入列以指示哪些行用于检验样本。ID 列必须仅包含 2 个值。在测试集水平中,选择用作检验样本的水平。
- (可选)选中存储训练/测试拆分的 ID 列以保存 ID 列。
无
如果选择无,则不会执行其他验证。
选择要针对拟合回归模型显示的图形
统计?> 回归?> 回归?> 拟合回归模型?> 图形
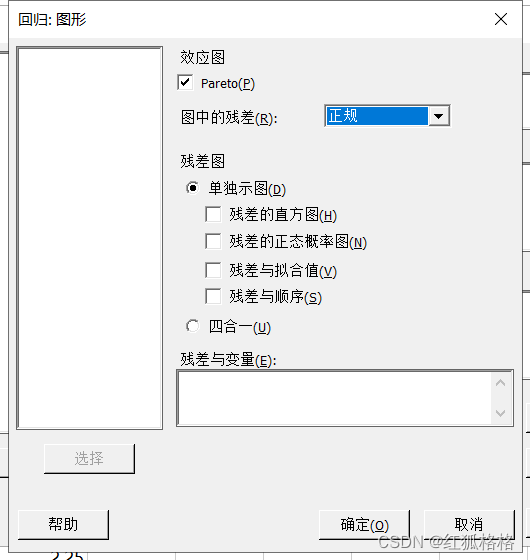
Pareto 图
用于直观地显示系数和方差分析表中的结果。对于模型中的项,此图形可用于比较效应的相对量值并评估其统计显著性。
统计显著性阈值取决于显著性水平(用 α 或 alpha 表示)。除非使用逐步选择法,否则显著性水平为“1 - 用于分析的置信水平”。如果使用向后选择或逐步选择法,则显著性水平为:Minitab 从模型中删除一个称为删除用 Alpha的项。如果使用向前选择,则显著性水平为:Minitab 向模型添加一个称为入选用 Alpha的项。
残差图
残差图,指定要在残差图上显示的残差类型。
- 正规:绘制常规的原始残差。
- 标准化:绘制标准化残差。
- 删后:绘制 t 化删后残差。
残差图
使用残差图可检查模型是否符合分析的假设。
- 单独示图:选择要显示的残差图。
- 残差的直方图:显示残差的直方图。
- 残差的正态概率图:显示残差的正态概率图。
- 残差与拟合值:显示残差与拟合值。
- 残差与顺序:显示残差与数据顺序。每个数据点的行号均显示在 x 轴上。
- 四合一:在一张图形中显示所有四个残差图。
残差与变量
输入一个或多个要绘制的变量和残差。可以绘制以下类型的变量:
- 当前模型中已存在的变量,可用于查找残差中的弯曲。
- 当前模型中不存在的重要变量,可用于确定是否与响应相关。
R 平方与模型选择步骤
当使用前进法并验证 作为逐步过程时,Minitab 会为训练数据集提供 R2 统计量图,并为模型选择过程中的每个步骤提供检验 R2 统计量或 k 折叠逐步 R2 统计量。检验 R2 统计量或 k 折叠逐步 R2 统计量的显示取决于是使用检验数据集还是 k 折叠交叉验证。
解释:使用此图比较每个步骤中不同 R2 统计量的值。通常,当 R2 统计量均较大时,模型执行情况良好。Minitab 显示来自步骤的模型回归统计量,该步骤最大化检验 R2 统计量或 k 折叠逐步 R2 统计量。此图显示任何更简单的模型是否拟合度足够,可成为理想候选。
如果模型过度拟合,检验 R2 统计量或 k 折叠逐步 R2 统计量开始随着项进入模型而减少。当所有数据的相应训练 R2 统计量或 R2 统计量继续增加时,就会发生此减少情况。当为在总体中不重要的效应添加项时,将出现过度拟合模型。过度拟合模型对于预测总体可能没有帮助。如果模型过度拟合,则可以考虑早期步骤的模型。
下图以检验 R2 为例。最初,R2 统计量都接近 70%。对于前几个步骤,R2 统计量都趋向于随着项输入模型而增加。在步骤 6 中,检验 R2 统计量约为 88%。检验 R2 统计量的最大值位于步骤 14 中,其值接近 90%。可以考虑拟合的改进是否证明向模型中添加更多项会增加复杂度。
步骤 14 之后,当 R2 继续增加时,检验 R2 不会增加。步骤 14 之后,检验 R2 的减少表明模型过度拟合。

选择要针对拟合回归模型显示的结果
统计?> 回归?> 回归?> 拟合回归模型?> 结果
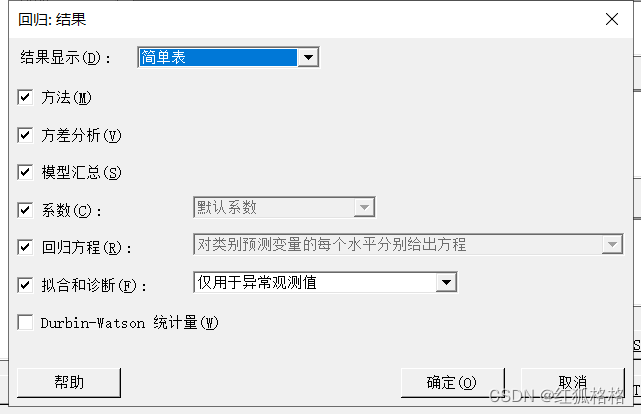
结果显示
- 基本表:显示与发布版 16 回归一致的表。
- 简单表:显示所有表格的更简易版本。
- 扩展表:显示方差分析、系数、模型汇总和拟合与诊断表的扩展版本。
方法:显示一个概括非默认设置的表。
方差分析:显示包含来源源平方和 p 值的方差分析表。
模型汇总:显示可估计模型拟合度的统计量,包含 R2。扩展表包括预测的误差平方和 (PRESS)、更正的 Akaike 信息标准 (AICc) 和 Bayesian 信息标准 (BIC)。
系数:显示系数、系数的标准误、t 值、p 值和 VIF。如果模型包含类别预测变量,会启用下拉列表,这样就可以控制表中类别预测变量的系数数量。
- 默认系数:显示类别预测变量的所有线性独立系数。
- 整套系数:显示所有类别预测变量水平的系数,其中包含最终的线性相关水平。
回归方程:显示回归方程。如果模型包含类别预测变量,会启用下拉列表,这样就可以控制显示的方程数量。
- 对每组因子水平分别给出方程:显示每个类别预测变量组合的单独方程。
- 单一方程:显示一个包含所有类别预测变量的所有水平的方程。
拟合和诊断:
- 仅用于异常观测值:只显示异常观测值的拟合、残差和诊断统计量。
- 适用于所有观测值:显示所有观测值的拟合值、残差和诊断统计量。
Durbin-Watson 统计量:显示 Durbin-Watson 统计量以检验自相关。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 安科瑞ARTM系列-无线测温解决方案
- 跨境电商营销工具定制功能大揭秘!
- 算法-从树某节点到顶级的id,拼接成字符串
- MyBatis ORM映射
- kubernetes volume 数据存储详解
- 性能分析与调优: Linux 监测工具的数据来源
- MacM1Pro Parallels19.1.0 CentOS7.9 Install PostgrepSQL
- Linux网络基础及bonding实际操作
- 【HTML】-- 01 初识HTML
- ICC2:flip first row的影响