自动机器学习AutoML-Autogluon
1.AutoGluon介绍
AutoGluon是一个具有自动化机器学习功能的开源框架,它旨在简化机器学习模型的训练和部署过程。AutoGluon提供了一种简单、灵活且高效的方法,可以自动化地完成特征工程、模型选择和超参数调优等流程,从而为开发者提供了更多的时间和精力来解决其他问题。
在使用AutoGluon时,开发者只需提供数据集和目标变量,AutoGluon将自动执行以下步骤:
- 自动化特征工程:AutoGluon可以自动分析数据集中的特征,并根据其类型和特性进行转换和编码。它可以处理数值特征、类别特征和文本特征,并自动选择适当的转换方法。此外,AutoGluon还可以处理缺失值和异常值,并生成新的特征以提高模型的性能。
- 模型选择和超参数调优:AutoGluon可以自动选择适合数据集和任务的模型,并对模型的超参数进行优化。它使用了一种称为AutoML的技术,通过在候选模型和超参数上进行搜索和评估,找到最佳的组合。AutoGluon支持各种类型的机器学习模型,包括分类、回归和聚类等。
- 模型集成和融合:AutoGluon还提供了模型集成和融合的功能,可以将多个模型的预测结果进行组合,以获得更好的性能。它支持多种集成方法,包括投票、平均和堆叠等。
2.AutoGluon使用
使用AutoGluon最好在在一个新的虚拟环境中(比如新建一个conda虚拟环境)安装,否则很容易产生包版本冲突的问题。如下:
conda create -y --force -n p38 python=3.8
pip conda activate p38
pip install autogluon
AutoGluon加载格式化数据(.csv) 使用TabularDataset,TabularDataset的使用方式和pandas十分相似,如果遇上无法加载的格式,也可以用pandas先加载再转为TabularDataset。如下:
from autogluon.tabular import TabularDataset, TabularPredictor
df = TabularDataset('./train.csv')
df.drop('number', axis=1, inplace=True)
df_pred_1=TabularDataset(pd.read_excel('./test.xlsx'))
pred_xlsx = TabularDataset(pd.read_excel('./predict.xlsx'))
AutoGluon训练模型 使用TabularPredictor,它只接受一个Train_data参数作为训练数据,因此不必将特征和标签分开,只需要告诉TabularPredictor你的标签列列名即可。
from sklearn.model_selection import train_test_split
X=df
y=df.iloc[:,-1]
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=0)
print(test_x.shape)
print(train_x.shape)
print(test_y.shape)
train_x
predictor = TabularPredictor(label='fetal_health').fit(train_data=train_x)
通过predictor.leaderboard(test_x, silent=True),我们可以看到各个学习器的测试得分和验证得分以及训练时间等等信息。可以看到最好的模型为lightGMB。
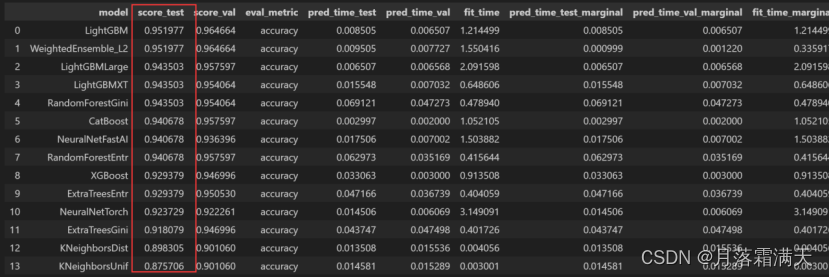
3.AutoGluon的训练结果
Autogluon的预测代码很简单,和sk-learn中的模型使用方式相同。使用的指标准确率、召回率和F1得分来衡量。
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix,accuracy_score,recall_score,f1_score,classification_report
test_data_t=test_x.drop(labels=['fetal_health'],axis=1)
#模型预测
# predictor=TabularPredictor.load("AutogluonModels/ag-20231223_094300/")
#可以设置不同的模型,也可以不写model,默认是最优的模型
pred=predictor.predict(test_data_t,model='LightGBM')
#获取准确率、召回率、F1值
dc=accuracy_score(pred, test_y)
print("accuracy_score",dc)
recall=recall_score(pred, test_y,average='weighted')
print("recall_score",recall)
f1=f1_score(pred, test_y,average='weighted')
print("f1_score",f1)
cm = confusion_matrix(pred, test_y)
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True,fmt='.0f')
plt.show()
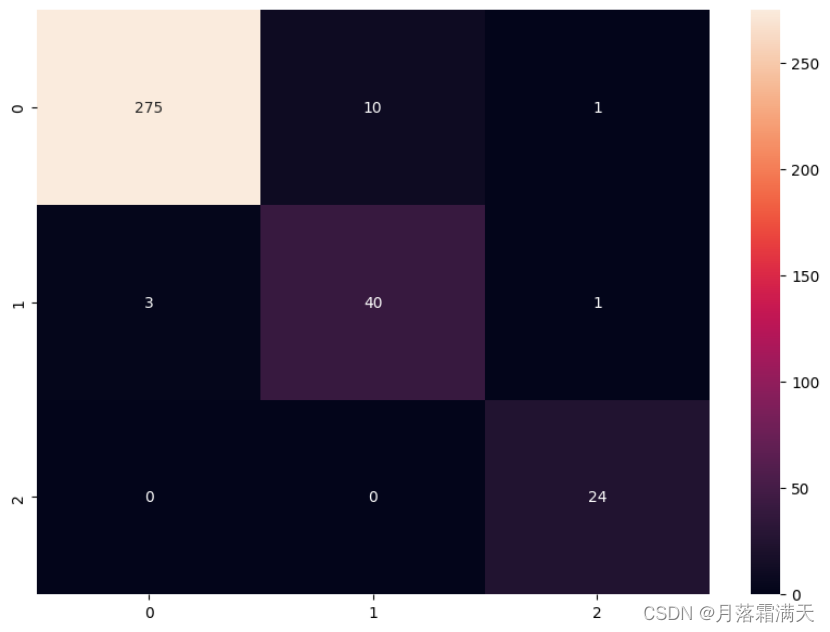
4.AutoGluon的预测
TabularDataset无法直接读取xlsx文件,需要使用pandas先将xlsx格式的数据读取进内存再转为TabularDataset
import pandas as pd
from autogluon.tabular import TabularDataset,TabularPredictor
#加载模型
# predictor=TabularPredictor.load("AutogluonModels/ag-20211108_092108/")
#输入数据
df_pred_1=TabularDataset(pd.read_excel('./test.xlsx'))
pred_xlsx = TabularDataset(pd.read_excel('./predict.xlsx'))
#预测
pred=predictor.predict(df_pred_1)
#保存结果
pred_xlsx['fetal_health']=pred
pred_xlsx.to_excel("predict_autogluon.xlsx",index=False)
5. 完整代码
# %%
from autogluon.tabular import TabularDataset, TabularPredictor
df = TabularDataset('./train.csv')
# df.drop('number', axis=1, inplace=True)
# %%
from sklearn.model_selection import train_test_split
X=df
y=df.iloc[:,-1]
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=2)
print(test_x.shape)
print(train_x.shape)
print(test_y.shape)
train_x
# %%
predictor = TabularPredictor(label='fetal_health').fit(train_data=train_x)
# %%
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix,accuracy_score,recall_score,f1_score,classification_report
test_data_t=test_x.drop(labels=['fetal_health'],axis=1)
#模型预测
# predictor=TabularPredictor.load("AutogluonModels/ag-20231223_094300/")
#可以设置不同的模型,也可以不写model,默认是最优的模型
pred=predictor.predict(test_data_t,model='LightGBM')
#获取准确率、召回率、F1值
dc=accuracy_score(pred, test_y)
print("accuracy_score",dc)
recall=recall_score(pred, test_y,average='weighted')
print("recall_score",recall)
f1=f1_score(pred, test_y,average='weighted')
print("f1_score",f1)
cm = confusion_matrix(pred, test_y)
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True,fmt='.0f')
plt.show()
# %%
predictor.leaderboard(test_x, silent=True)
# %%
import pandas as pd
from autogluon.tabular import TabularDataset,TabularPredictor
#加载模型
# predictor=TabularPredictor.load("AutogluonModels/ag-20211108_092108/")
#输入数据
df_pred_1=TabularDataset(pd.read_excel('./test.xlsx'))
pred_xlsx = TabularDataset(pd.read_excel('./predict.xlsx'))
#预测
pred=predictor.predict(df_pred_1)
#保存结果
pred_xlsx['fetal_health']=pred
pred_xlsx.to_excel("predict_autogluon.xlsx",index=False)
6.代码所用数据集介绍
该数据集包含从心电图检查中提取的2126条特征记录,然后由三名产科专家将其分类为3类:
正常
疑似
病理性的
创建一个多类模型以将CTG功能分类为三种胎儿健康状态。
每个数据包含21个属性。最后一列“fetal_health”的值表示健康程度,为分类标签,其中“1”为正常,“2”为疑似,“3”为病例性的。
代码中的train.csv是在原始数据集分出了测试集之后用于训练的部分。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c++时间复杂度详解
- ScottPlot5 Blazor WebAssembly测试
- JAVA用Zxing生成的二维码扫码桩识别出现\000026
- 校园转转二手市场源码+Java二手交易市场整站源码
- NLP深入学习(八):感知机学习
- 华为机试真题实战应用【赛题代码篇】-最小传输时延(附python、C++和JAVA代码实现)
- java天气查询app(开题+源码)
- 文件系统(六)—文件系统mount过程 转载
- 分布式Session使用步骤
- 微信小程序 手机号授权登录 偶尔后端解密失败