西瓜书学习笔记——Boosting(公式推导+举例应用)
引言
Boosting是一种集成学习方法,旨在通过整合多个弱学习器来构建一个强学习器。其核心思想是迭代训练模型,关注之前被错误分类的样本,逐步提升整体性能。Boosting的代表算法包括AdaBoost、Gradient Boosting和XGBoost等,在实际应用中取得了广泛成功。
AdaBoost算法
AdaBoost是一种集成学习算法,其基本结构如下:
-
初始化权重: 为训练集中的每个样本初始化权重。
-
迭代训练弱学习器: 通过多次迭代,训练简单的弱学习器,每一轮都会调整样本的权重,更关注之前分类错误的样本。
-
更新样本权重: 根据当前弱学习器的性能,更新样本的权重,使得在下一轮迭代中更关注之前分类错误的样本。
-
组合弱学习器: 将每个弱学习器的输出按权重线性组合,构建最终的强分类器。
这一过程重复进行,直到达到预定的迭代次数或所有样本都被正确分类。
下面是AdaBoost的结构图示意图:
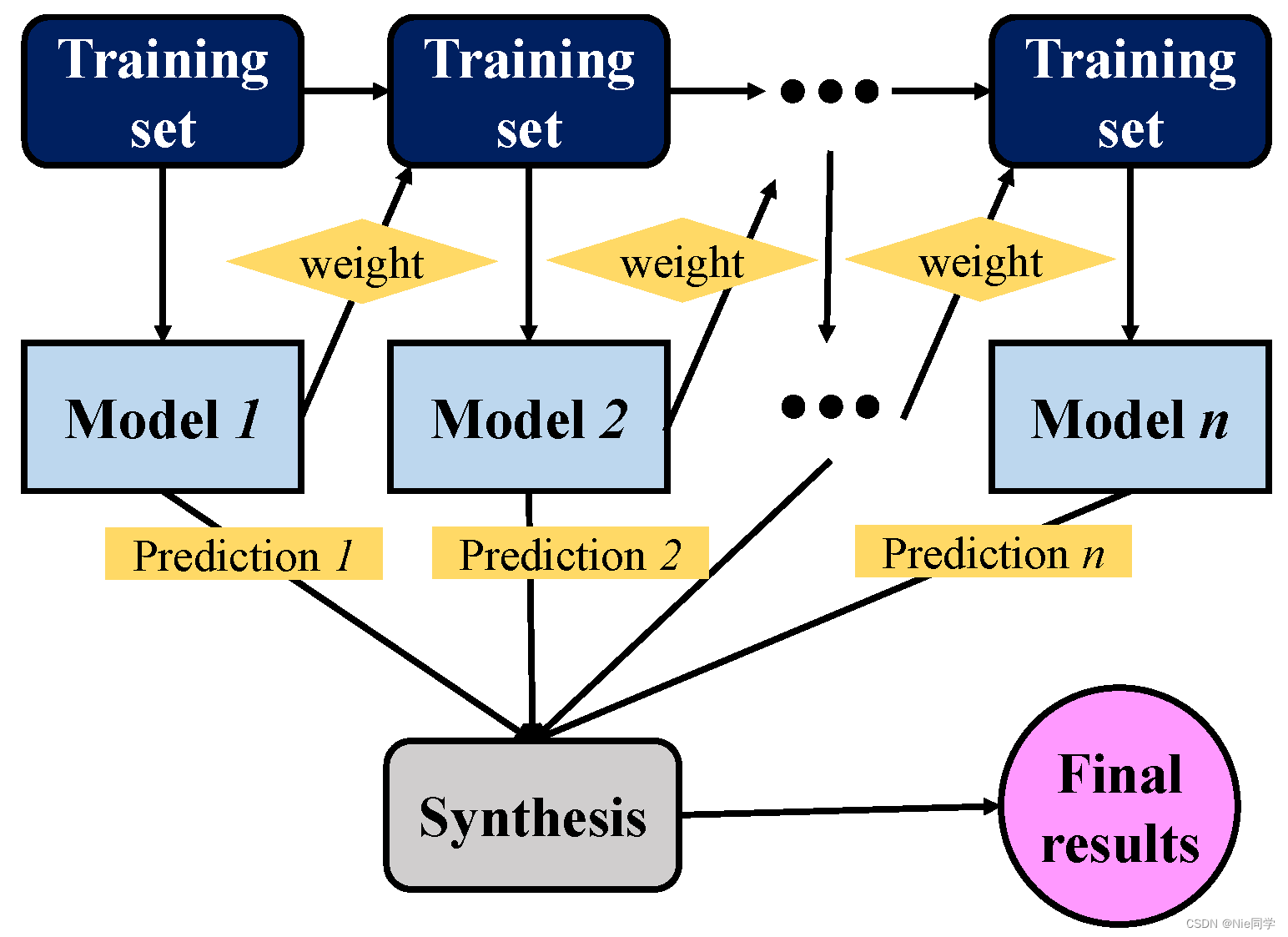
AdaBoost算法流程如下图所示:

下面我们采用基于加性模型的推导方式,即基学习器的线性组合:
H
(
x
)
=
∑
t
=
1
T
α
t
h
t
(
x
)
(1)
H(x)=\sum_{t=1}^T\alpha_th_t(x) \tag{1}
H(x)=t=1∑T?αt?ht?(x)(1)
其最小化指数损失函数为:
?
e
x
p
(
H
∣
D
)
=
E
x
~
D
[
e
?
f
(
x
)
H
(
x
)
]
(2)
\ell_{exp}(H|\mathcal{D})=\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H(x)}] \tag{2}
?exp?(H∣D)=Ex?~D[e?f(x)H(x)](2)
即 D [ e ? f ( x ) H ( x ) ] \mathcal{D}[e^{-f(x)H(x)}] D[e?f(x)H(x)] 可以被理解为在分布 D \mathcal{D} D 下,函数 e ? f ( x ) H ( x ) e^{-f(x)H(x)} e?f(x)H(x) 的期望值;其中 f ( x ) f(x) f(x)是真实值; H ( x ) H(x) H(x)为模型的预测值;
AdaBoost算法正确性说明
再此之前我们先把(2)式展开
- 对于离散型:
? e x p ( H ∣ D ) = ∑ x D ( x ) e ? f ( x ) H ( x ) (3) \ell_{exp}(H|\mathcal{D})=\sum_x \mathcal{D}(x) e^{-f(x)H(x)} \tag{3} ?exp?(H∣D)=x∑?D(x)e?f(x)H(x)(3) - 对于连续型:
? e x p ( H ∣ D ) = ∫ D ( x ) e ? f ( x ) H ( x ) d x (4) \ell_{exp}(H|\mathcal{D})=\int \mathcal{D}(x) e^{-f(x)H(x)}dx \tag{4} ?exp?(H∣D)=∫D(x)e?f(x)H(x)dx(4)
以离散型为例,接着使用最小二乘法,使得
?
e
x
p
\ell_{exp}
?exp?最小,即对
?
e
x
p
\ell_{exp}
?exp?求对
H
(
x
)
H(x)
H(x)的偏导有:
?
?
exp
(
H
∣
D
)
?
H
(
x
)
=
∑
x
?
D
(
x
)
e
?
f
(
x
)
H
(
x
)
?
H
(
x
)
=
∑
x
?
D
(
x
)
f
(
x
)
e
?
f
(
x
)
H
(
x
)
(5)
\begin{aligned} \frac{\partial \ell_{\text{exp}}(H|\mathcal{D})}{\partial H(x)} &= \sum_x \frac{\partial \mathcal{D}(x) e^{-f(x)H(x)}}{\partial H(x)} \\ &= \sum_x-\mathcal{D(x)}f(x)e^{-f(x)H(x)} \\ \end{aligned} \tag{5}
?H(x)??exp?(H∣D)??=x∑??H(x)?D(x)e?f(x)H(x)?=x∑??D(x)f(x)e?f(x)H(x)?(5)
又因为
f
(
x
)
∈
{
?
1
,
+
1
}
f(x)\in\{-1,+1\}
f(x)∈{?1,+1},所以式(5)可变形为:
∑
x
?
D
(
x
)
f
(
x
)
e
?
f
(
x
)
H
(
x
)
=
?
∑
x
D
(
x
)
e
?
H
(
x
)
+
∑
x
D
(
x
)
e
H
(
x
)
=
?
e
?
H
(
x
)
P
(
f
(
x
)
=
1
∣
x
)
+
e
H
(
x
)
P
(
f
(
x
)
=
?
1
∣
x
)
(6)
\begin{aligned} & \sum_x-\mathcal{D(x)}f(x)e^{-f(x)H(x)} \\ &= -\sum_x\mathcal{D}(x)e^{-H(x)}+\sum_x\mathcal{D}(x)e^{H(x)} \\ &= -e^{-H(x)} P(f(x)=1|x)+e^{H(x)}P(f(x)=-1|x) \end{aligned} \tag{6}
?x∑??D(x)f(x)e?f(x)H(x)=?x∑?D(x)e?H(x)+x∑?D(x)eH(x)=?e?H(x)P(f(x)=1∣x)+eH(x)P(f(x)=?1∣x)?(6)
其中 P ( f ( x ) = 1 ∣ x ) P(f(x)=1|x) P(f(x)=1∣x)代表在数据集 x x x中好瓜的概率; P ( f ( x ) = ? 1 ∣ x ) P(f(x)=-1|x) P(f(x)=?1∣x)代表在数据集 x x x中坏瓜的概率。
令(6)式为零可得:
H
(
x
)
=
1
2
ln
?
P
(
f
(
x
)
=
1
∣
x
)
P
(
f
(
x
)
=
?
1
∣
x
)
(7)
H(x)=\frac{1}{2}\ln\frac{P(f(x)=1|x)}{P(f(x)=-1|x)} \tag{7}
H(x)=21?lnP(f(x)=?1∣x)P(f(x)=1∣x)?(7)
又因为对于一个二分类问题
H
(
x
)
∈
{
?
1
,
+
1
}
H(x)\in\{-1,+1\}
H(x)∈{?1,+1},故可将(7)式简化,有:
s
i
g
n
(
H
(
x
)
)
=
s
i
g
n
(
1
2
ln
?
P
(
f
(
x
)
=
1
∣
x
)
P
(
f
(
x
)
=
?
1
∣
x
)
)
=
{
1
,
P
(
f
(
x
)
=
1
∣
x
)
>
P
(
f
(
x
)
=
?
1
∣
x
)
?
1
,
P
(
f
(
x
)
=
1
∣
x
)
<
P
(
f
(
x
)
=
?
1
∣
x
)
=
max
y
∈
{
?
1
,
+
1
}
P
(
f
(
x
)
=
y
∣
x
)
(8)
\begin{aligned} \mathrm{sign}(H(x))&=\mathrm{sign}(\frac{1}{2}\ln\frac{P(f(x)=1|x)}{P(f(x)=-1|x)})\\ &=\begin{cases} 1,\quad P(f(x)=1|x)>P(f(x)=-1|x)\\ -1,\quad P(f(x)=1|x)<P(f(x)=-1|x) \end{cases}\\ &=\underset{y\in\{-1,+1\}}{\text{max}} \quad P(f(x)=y|x) \end{aligned} \tag{8}
sign(H(x))?=sign(21?lnP(f(x)=?1∣x)P(f(x)=1∣x)?)={1,P(f(x)=1∣x)>P(f(x)=?1∣x)?1,P(f(x)=1∣x)<P(f(x)=?1∣x)?=y∈{?1,+1}max?P(f(x)=y∣x)?(8)
其中 max y ∈ { ? 1 , + 1 } P ( f ( x ) = y ∣ x ) \underset{y\in\{-1,+1\}}{\text{max}} \quad P(f(x)=y|x) y∈{?1,+1}max?P(f(x)=y∣x)该部分可以理解为在给定输入 x x x的情况下,选择具有最大条件概率的类别 y y y,即谁的概率大,就是什么类别。
这就意味着 s i g n ( H ( x ) ) \mathrm{sign}(H(x)) sign(H(x))达到了贝叶斯最优错误率。这说明指数损失函数是分类任务原本 0 / 1 0/1 0/1损失函数的一致性替代损失函数。因为该函数具有较好的数学性质,故用它来替代原本的 0 / 1 0/1 0/1损失函数是较好的选择。
AdaBoost算法如何解决权重更新问题?
在AdaBoost算法中,第一个基分类器
h
1
h_1
h1?是通过直接将基学习器算法用于初始数据分布而得到的;此后的每次迭代地生成
h
t
h_t
ht?和
α
t
\alpha_t
αt?,当基分类器
h
t
h_t
ht?基于分布
D
t
\mathcal{D_t}
Dt?产生后,该分类器的权重应该使得
α
t
h
t
\alpha_th_t
αt?ht?最小化指数损失函数
?
e
x
p
(
α
t
h
t
∣
D
t
)
=
E
x
~
D
t
[
e
?
f
(
x
)
α
t
h
t
(
x
)
]
=
∑
x
D
t
(
x
)
e
?
f
(
x
)
α
t
h
t
(
x
)
(9)
\begin{aligned} \ell_{exp}(\alpha_th_t|\mathcal{D}_t)&=\mathbb{E}_x\sim \mathcal{D}_t[e^{-f(x)\alpha_th_t(x)}] \\ &= \sum_x\mathcal{D_t(x)}e^{-f(x)\alpha_th_t(x)} \\ \end{aligned} \tag{9}
?exp?(αt?ht?∣Dt?)?=Ex?~Dt?[e?f(x)αt?ht?(x)]=x∑?Dt?(x)e?f(x)αt?ht?(x)?(9)
此时对于式(9)我们可以分类讨论:
f
(
x
)
=
h
t
(
x
)
f(x)=h_t(x)
f(x)=ht?(x)和
f
(
x
)
≠
h
t
(
x
)
f(x)\ne h_t(x)
f(x)=ht?(x),有:
∑
x
D
t
(
x
)
e
?
f
(
x
)
α
t
h
t
(
x
)
=
e
?
α
t
P
(
f
(
x
)
=
h
t
(
x
)
∣
x
)
+
e
α
t
P
(
f
(
x
)
≠
h
t
(
x
)
∣
x
)
=
e
?
α
t
P
x
~
D
t
[
f
(
x
)
=
h
t
(
x
)
]
+
e
α
t
P
x
~
D
t
[
f
(
x
)
≠
h
t
(
x
)
]
=
e
?
α
t
(
1
?
?
t
)
+
e
α
t
?
t
(10)
\begin{aligned} & \sum_x\mathcal{D_t(x)}e^{-f(x)\alpha_th_t(x)} \\ &=e^{-\alpha_t}P(f(x)=h_t(x)|x)+e^{\alpha_t}P(f(x)\ne h_t(x)|x)\\ &=e^{-\alpha_t}P_x\sim\mathcal{D}_t[f(x)=h_t(x)]+e^{\alpha_t}P_x\sim\mathcal{D}_t[f(x)\ne h_t(x)]\\ &=e^{-\alpha_t}(1-\epsilon_t)+e^{\alpha_t}\epsilon_t \end{aligned} \tag{10}
?x∑?Dt?(x)e?f(x)αt?ht?(x)=e?αt?P(f(x)=ht?(x)∣x)+eαt?P(f(x)=ht?(x)∣x)=e?αt?Px?~Dt?[f(x)=ht?(x)]+eαt?Px?~Dt?[f(x)=ht?(x)]=e?αt?(1??t?)+eαt??t??(10)
其中
?
t
=
P
x
~
D
t
[
f
(
x
)
≠
h
t
(
x
)
]
\epsilon_t=P_x\sim\mathcal{D}_t[f(x)\ne h_t(x)]
?t?=Px?~Dt?[f(x)=ht?(x)],考虑到指数损失函数对
α
t
\alpha_t
αt?(权重)求偏导有:
? ? exp ( α t h t ∣ D t ) ? α t = ? e ? α t ( 1 ? ? t ) + e α t ? t (11) \frac{\partial \ell_{\text{exp}}(\alpha_th_t|\mathcal{D}_t)}{\partial \alpha_t}=-e^{-\alpha_t}(1-\epsilon_t)+e^{\alpha_t}\epsilon_t \tag{11} ?αt???exp?(αt?ht?∣Dt?)?=?e?αt?(1??t?)+eαt??t?(11)
令式(11)为零有:
α
t
=
1
2
ln
?
(
1
?
?
t
?
t
)
(12)
\alpha_t=\frac{1}{2}\ln(\frac{1-\epsilon_t}{\epsilon_t}) \tag{12}
αt?=21?ln(?t?1??t??)(12)
这正是算法流程图中第六行的权重更新公式。
AdaBoost算法如何解决调整下一轮基学习器样本分布问题?
AdaBoost算法在获得 H t ? 1 H_{t-1} Ht?1?之后的样本分布将进行调整,使得下一轮的基学习器 h t h_t ht?能纠正 H t ? 1 H_{t-1} Ht?1?的一些错误,理想的 h t h_t ht?能纠正 H t ? 1 H_{t-1} Ht?1?的全部错误,即最小化:
? e x p ( H t ? 1 + h t ∣ D ) = E x ~ D [ e ? f ( x ) ( H t ? 1 ( x ) + h t ( x ) ) ] = E x ~ D [ e ? f ( x ) H t ? 1 ( x ) e ? f ( x ) h t ( x ) ] (13) \begin{aligned} \ell_{exp}(H_{t-1}+h_t|\mathcal{D})&=\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)(H_{t-1}(x)+h_t(x))}] \\ &= \mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}e^{-f(x)h_t(x)}] \\ \end{aligned} \tag{13} ?exp?(Ht?1?+ht?∣D)?=Ex?~D[e?f(x)(Ht?1?(x)+ht?(x))]=Ex?~D[e?f(x)Ht?1?(x)e?f(x)ht?(x)]?(13)
注意到
f
(
x
)
f(x)
f(x)和
h
t
(
x
)
∈
{
?
1
,
+
1
}
h_t(x)\in\{-1,+1\}
ht?(x)∈{?1,+1}故,
f
2
(
x
)
=
h
t
2
(
x
)
=
1
f^2(x)=h^2_t(x)=1
f2(x)=ht2?(x)=1,因为
e
x
≈
1
+
x
+
x
2
2
!
+
x
3
3
!
+
x
4
4
!
+
…
e^x \approx 1 + x + \frac{x^2}{2!} + \frac{x^3}{3!} + \frac{x^4}{4!} + \ldots
ex≈1+x+2!x2?+3!x3?+4!x4?+…;故可对式(13)中的
e
?
f
(
x
)
h
t
(
x
)
e^{-f(x)h_t(x)}
e?f(x)ht?(x)泰勒展开近似为:
?
e
x
p
(
H
t
?
1
+
h
t
∣
D
)
≈
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
(
1
?
f
(
x
)
h
t
(
x
)
)
+
f
2
(
x
)
h
t
2
(
x
)
2
)
]
=
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
(
1
?
f
(
x
)
h
t
(
x
)
)
+
1
2
)
]
(14)
\begin{aligned} \ell_{exp}(H_{t-1}+h_t|\mathcal{D})&\approx\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h_t(x))+\frac{f^2(x)h^2_t(x)}{2})] \\ &=\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h_t(x))+\frac{1}{2})] \end{aligned} \tag{14}
?exp?(Ht?1?+ht?∣D)?≈Ex?~D[e?f(x)Ht?1?(x)(1?f(x)ht?(x))+2f2(x)ht2?(x)?)]=Ex?~D[e?f(x)Ht?1?(x)(1?f(x)ht?(x))+21?)]?(14)
于是,理想的基学习器
h
t
(
x
)
=
arg?min
h
?
e
x
p
(
H
t
?
1
+
h
∣
D
)
=
arg?min
h
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
(
1
?
f
(
x
)
h
(
x
)
)
+
1
2
)
]
(15)
\begin{aligned} h_t(x)&=\underset{h}{\text{arg min}} \quad \ell_{exp}(H_{t-1}+h|\mathcal{D}) \\ &=\underset{h}{\text{arg min}} \quad \mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h(x))+\frac{1}{2})] \\ \end{aligned} \tag{15}
ht?(x)?=harg?min??exp?(Ht?1?+h∣D)=harg?min?Ex?~D[e?f(x)Ht?1?(x)(1?f(x)h(x))+21?)]?(15)
因为式(15)中
(
1
?
f
(
x
)
h
t
(
x
)
)
+
1
2
)
(1-f(x)h_t(x))+\frac{1}{2})
(1?f(x)ht?(x))+21?)
1
1
1和
1
2
\frac{1}{2}
21?与最终结果无关,故可以省略,且-号变为+号将目标函数从求最小变成求最大值,故式(15)可简化为:
arg?min
h
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
(
1
?
f
(
x
)
h
(
x
)
)
+
1
2
)
]
=
arg?max
h
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
f
(
x
)
h
(
x
)
]
=
arg?max
h
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
f
(
x
)
h
(
x
)
]
(16)
\begin{aligned} &\underset{h}{\text{arg min}} \quad \mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h(x))+\frac{1}{2})] \\ &=\underset{h}{\text{arg max}} \quad \mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}f(x)h(x)] \\ &=\underset{h}{\text{arg max}} \quad \mathbb{E}_x\sim \mathcal{D}[\frac{e^{-f(x)H_{t-1}(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}f(x)h(x)] \end{aligned}\tag{16}
?harg?min?Ex?~D[e?f(x)Ht?1?(x)(1?f(x)h(x))+21?)]=harg?max?Ex?~D[e?f(x)Ht?1?(x)f(x)h(x)]=harg?max?Ex?~D[Ex?~D[e?f(x)Ht?1?(x)]e?f(x)Ht?1?(x)?f(x)h(x)]?(16)
注意到
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]
Ex?~D[e?f(x)Ht?1?(x)]是一个常数。令
D
t
\mathcal{D}_t
Dt?表示一个分布,使其更符合概率密度函数的定义:
D
t
=
D
(
x
)
e
?
f
(
x
)
H
t
?
1
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
(17)
\mathcal{D_t}=\frac{\mathcal{D(x)}e^{-f(x)H_{t-1}(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]} \tag{17}
Dt?=Ex?~D[e?f(x)Ht?1?(x)]D(x)e?f(x)Ht?1?(x)?(17)
其中 D t ( x ) \mathcal{D_t}(x) Dt?(x)表示未来的分布函数, D ( x ) D(x) D(x)表示过去的分布函数。
根据数学期望的定义,等价于:
h
t
(
x
)
=
arg?max
h
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
f
(
x
)
h
(
x
)
]
=
arg?max
h
E
x
~
D
t
[
f
(
x
)
h
(
x
)
]
(18)
\begin{aligned} h_t(x)&=\underset{h}{\text{arg max}} \quad \mathbb{E}_x\sim \mathcal{D}[\frac{e^{-f(x)H_{t-1}(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}f(x)h(x)]\\ &=\underset{h}{\text{arg max}} \quad \mathbb{E}_x\sim \mathcal{D_t}[f(x)h(x)] \end{aligned}\tag{18}
ht?(x)?=harg?max?Ex?~D[Ex?~D[e?f(x)Ht?1?(x)]e?f(x)Ht?1?(x)?f(x)h(x)]=harg?max?Ex?~Dt?[f(x)h(x)]?(18)
由于
f
(
x
)
,
h
(
x
)
∈
{
?
1
,
+
1
}
f(x),h(x)\in \{-1,+1\}
f(x),h(x)∈{?1,+1},有:
f
(
x
)
h
(
x
)
=
1
?
2
χ
(
f
(
x
)
≠
h
(
x
)
)
(19)
f(x)h(x)=1-2\chi{(f(x)\ne h(x))} \tag{19}
f(x)h(x)=1?2χ(f(x)=h(x))(19)
其中
χ
(
f
(
x
)
≠
h
(
x
)
)
\chi{(f(x)\ne h(x))}
χ(f(x)=h(x))的定义如下:
χ
(
f
(
x
)
≠
h
t
(
x
)
)
=
{
1
如果?
f
(
x
)
≠
h
(
x
)
0
如果?
f
(
x
)
=
h
(
x
)
(20)
\chi{(f(x) \ne h_t(x))} = \begin{cases} 1 & \text{如果 } f(x) \ne h(x) \\ 0 & \text{如果 } f(x) = h(x) \end{cases} \tag{20}
χ(f(x)=ht?(x))={10?如果?f(x)=h(x)如果?f(x)=h(x)?(20)
则理想的基学习器为:
h
t
(
x
)
=
arg?min
h
E
x
~
D
t
[
χ
(
f
(
x
)
≠
h
(
x
)
)
]
(21)
h_t(x)=\underset{h}{\text{arg min}} \quad \mathbb{E}_x\sim \mathcal{D_t}[\chi(f(x)\ne h(x))] \tag{21}
ht?(x)=harg?min?Ex?~Dt?[χ(f(x)=h(x))](21)
考虑到
D
t
\mathcal{D_t}
Dt?与
D
t
+
1
\mathcal{D_{t+1}}
Dt+1?的关系有:
D
t
+
1
(
x
)
=
D
(
x
)
e
?
f
(
x
)
H
t
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
(
x
)
]
=
D
(
x
)
e
?
f
(
x
)
(
H
t
?
1
(
x
)
+
α
t
h
t
(
x
)
)
E
x
~
D
[
e
?
f
(
x
)
H
t
(
x
)
]
=
D
(
x
)
e
?
f
(
x
)
H
t
?
1
(
x
)
e
?
f
(
x
)
α
t
h
t
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
(
x
)
]
=
D
(
x
)
e
?
f
(
x
)
H
t
?
1
(
x
)
e
?
f
(
x
)
α
t
h
t
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
?
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
E
x
~
D
[
e
?
f
(
x
)
H
t
(
x
)
]
=
D
t
(
x
)
?
e
?
f
(
x
)
α
t
h
t
(
x
)
E
x
~
D
[
e
?
f
(
x
)
H
t
?
1
(
x
)
]
E
x
~
D
[
e
?
f
(
x
)
H
t
(
x
)
]
(22)
\begin{aligned} \mathcal{D_{t+1}}(x)&=\frac{\mathcal{D(x)}e^{-f(x)H_{t}(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]} \\ &=\frac{\mathcal{D(x)}e^{-f(x)(H_{t-1}(x)+\alpha_th_t(x))}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]} \\ &= \frac{\mathcal{D(x)}e^{-f(x)H_{t-1}(x)}e^{-f(x)\alpha_th_t(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]} \\ &=\frac{\mathcal{D(x)}e^{-f(x)H_{t-1}(x)}e^{-f(x)\alpha_th_t(x)}}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}\cdot \frac{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]}\\ &=\mathcal{D_t(x)} \cdot e^{-f(x)\alpha_th_t(x)}\frac{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]} \end{aligned} \tag{22}
Dt+1?(x)?=Ex?~D[e?f(x)Ht?(x)]D(x)e?f(x)Ht?(x)?=Ex?~D[e?f(x)Ht?(x)]D(x)e?f(x)(Ht?1?(x)+αt?ht?(x))?=Ex?~D[e?f(x)Ht?(x)]D(x)e?f(x)Ht?1?(x)e?f(x)αt?ht?(x)?=Ex?~D[e?f(x)Ht?1?(x)]D(x)e?f(x)Ht?1?(x)e?f(x)αt?ht?(x)??Ex?~D[e?f(x)Ht?(x)]Ex?~D[e?f(x)Ht?1?(x)]?=Dt?(x)?e?f(x)αt?ht?(x)Ex?~D[e?f(x)Ht?(x)]Ex?~D[e?f(x)Ht?1?(x)]??(22)
其中 E x ~ D [ e ? f ( x ) H t ? 1 ( x ) ] E x ~ D [ e ? f ( x ) H t ( x ) ] \frac{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t-1}(x)}]}{\mathbb{E}_x\sim \mathcal{D}[e^{-f(x)H_{t}(x)}]} Ex?~D[e?f(x)Ht?(x)]Ex?~D[e?f(x)Ht?1?(x)]?是常数。这就是AdaBoost算法流程图中第7行的样本分布更新公式。
AdaBoost算法总结
需要注意的是,AdaBoost算法对于无法接受带权样本的基学习算法,可通过重采样法来处理,即在每一轮学习中,根据样本分布对训练集进行重新采样,再用重采样而得到的样本集对基学习器进行训练。
偏差-方差分解是解释模型在预测中的性能时的一种常用方法。在这个角度来看,Boosting算法(例如AdaBoost)可以被解释为一个降低偏差并提高模型复杂度的方法。
-
偏差(Bias): 表示模型的预测值与实际值的差异。高偏差意味着模型对训练数据的拟合不足。在Boosting中,通过迭代训练弱学习器,并对先前模型分类错误的样本进行更多关注,模型逐渐减小了偏差。每个弱学习器可能拟合不足,但通过组合它们,整个模型能够更好地适应训练数据。
-
方差(Variance): 表示模型对训练数据的敏感性。高方差意味着模型对训练数据的小扰动很敏感,可能导致对新数据的泛化能力较差。Boosting通过降低弱学习器的方差来提高整个模型的泛化能力。每个弱学习器都是一个简单的模型,通常是一个深度较浅的决策树桩,因此具有较低的方差。
在Boosting中,每一轮迭代都会调整样本的权重,使得模型更加关注先前分类错误的样本。这种调整增加了模型对先前被错误分类的样本的拟合程度,降低了偏差。与此同时,通过使用多个弱学习器的组合,整体模型具有较低的方差,更有助于泛化到新数据。
总体而言,Boosting通过对高偏差、低方差的弱学习器的集成,实现了偏差-方差的权衡,提高了整体模型的性能和泛化能力。
实验分析
这个数据集包含了工作经验得分、技能熟练度得分、沟通能力得分、学历水平得分以及录取标签。我们的目标是利用工作经验、技能熟练度、沟通能力和学历等属性信息,通过机器学习模型来预测一个人是否被录取。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 读取数据
data = pd.read_csv('data/adaboost_recruitment_dataset_scores.csv')
data
# 分离特征和标签
X = data.drop('录取标签', axis=1)
y = data['录取标签']
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
用决策树算法
# 创建决策树分类器
decision_tree_clf = DecisionTreeClassifier(max_depth=1, random_state=42)
# 训练模型
decision_tree_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred_decision_tree = decision_tree_clf.predict(X_test)
# 评估准确性
decision_tree_accuracy = accuracy_score(y_test, y_pred_decision_tree)
print(f'准确性: {decision_tree_accuracy:.2f}')
准确性: 0.87
用AdaBoost算法
# 创建 AdaBoostClassifier 的实例,使用决策树作为基分类器
base_classifier = DecisionTreeClassifier(max_depth=1)
adaboost_clf = AdaBoostClassifier(base_classifier, n_estimators=60, random_state=42)
# 训练模型
adaboost_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred_adaboost = adaboost_clf.predict(X_test)
# 评估准确性
adaboost_accuracy = accuracy_score(y_test, y_pred_adaboost)
print(f'准确性: {adaboost_accuracy:.2f}')
准确性: 0.92
绘制评价图像
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决坐标轴负号'-'显示为方块的问题
# 绘制单一决策树的混淆矩阵
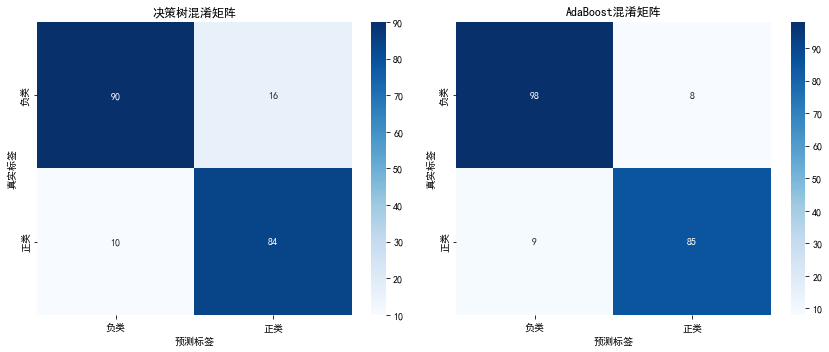
conf_matrix_decision_tree = confusion_matrix(y_test, y_pred_decision_tree)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.heatmap(conf_matrix_decision_tree, annot=True, fmt='d', cmap='Blues', xticklabels=['负类', '正类'], yticklabels=['负类', '正类'])
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('决策树混淆矩阵')
# 绘制 AdaBoost 的混淆矩阵
conf_matrix_adaboost = confusion_matrix(y_test, y_pred_adaboost)
plt.subplot(1, 2, 2)
sns.heatmap(conf_matrix_adaboost, annot=True, fmt='d', cmap='Blues', xticklabels=['负类', '正类'], yticklabels=['负类', '正类'])
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('AdaBoost混淆矩阵')
plt.tight_layout()
plt.show()
# 打印单一决策树的分类报告
print("单一决策树分类报告:\n", classification_report(y_test, y_pred_decision_tree))
# 打印 AdaBoost 的分类报告
print("AdaBoost分类报告:\n", classification_report(y_test, y_pred_adaboost))
单一决策树分类报告:
precision recall f1-score support
0.0 0.90 0.85 0.87 106
1.0 0.84 0.89 0.87 94
accuracy 0.87 200
macro avg 0.87 0.87 0.87 200
weighted avg 0.87 0.87 0.87 200
AdaBoost分类报告:
precision recall f1-score support
0.0 0.92 0.92 0.92 106
1.0 0.91 0.90 0.91 94
accuracy 0.92 200
macro avg 0.91 0.91 0.91 200
weighted avg 0.91 0.92 0.91 200
根据上述分析报告,可知AdaBoost模型相对于单一决策树表现更佳,具有更高的准确度和综合指标。在AdaBoost中,对未被录取和被录取的预测精确性较高,同时识别实际样本的能力也表现出色,呈现出更好的泛化性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vercel自动部署实战:零基础实操指南
- LiveGBS流媒体平台GB/T28181功能-基础配置接入控制白名单黑名单配置控制设备安全接入设备单独配置接入密码
- 开始学习第十四天
- Qt 信号槽相关
- Monkey:提升 Android 应用稳定性与性能的利器
- 【每次启动wsl时自动更新ip】
- 如何搭建Z-blog网站并结合内网穿透实现无公网ip访问本地站点
- 什么是MoS2/WS2转角异质结薄膜(WS2/MoSe2)
- MATLAB聚类及给无标签数据加标签
- 什么是信号抖动