【FLIP】一种用于训练CLIP的简单而有效的方案
FLIP
Paper : Scaling Language-Image Pre-training via Masking
Author : Yanghao Li , Haoqi Fan , Ronghang Hu , Christoph Feichtenhofer , Kaiming He
Affiliation : Meta AI, FAIR
Publication : CVPR-2023
Code : https://github.com/facebookresearch/flip
1 前言
作者提出一种用于训练CLIP的简单而有效的方案FLIP(Fast Language-Image Pre-training, FLIP),它在训练过程中对图像块进行大比例的随机Mask移除。Mask机制使得CLIP可以在有限周期内学习到更多的image-text数据对,同时占有更少的内存。所提方案取得了更好的精度与训练时间均衡,相比无Mask基线方案,所提FLIP在精度与训练速度方面具有大幅改善。

1.1 动机
语言监督的视觉预训练,例如 CLIP 已确立为一种简单而强大的学习表示方法。但是由于视觉加语言的复杂性,大规模训练对于语言监督模型的能力至关重要。(例如,原始的 CLIP 模型 使用 4 亿数据进行了 32 个周期的训练,相当于 10,000 个 ImageNet 周期,需要数千个 GPU 天 [52, 36]。)因此,需要一个高效 的CLIP 训练方法。
1.2 相关工作
掩码学习
十多年前,带有掩蔽噪声的去噪自动编码器被提出作为一种无监督表示学习方法。其最突出的应用之一是以BERT为代表的屏蔽语言建模。
掩蔽自动编码器(MAE)方法进一步利用掩蔽来减少训练时间和内存。 MAE 将 ViT 编码器稀疏地应用于可见内容。并且观察到高掩蔽比有利于准确性。
FLIP 与 MAE 及其视觉语言扩展相关。然而,重点是稀疏计算所支持的缩放方面;解决了大规模 CLIP 训练的挑战 。 MoCo 或 BYOL 研究了通过掩蔽加速训练的自监督对比学习,但是准确率受缩放方式或者仅图像的对比学习的限制。
语言监督学习
在过去的几年中,CLIP 和相关工作已经普及了通过语言监督学习视觉表示。CLIP 是一种通过比较图像-文本样本对进行对比学习的形式。除了对比学习之外,还探索了生成学习方法,并可选择与对比损失相结合。
2 方法
简而言之,FLIP 只是屏蔽了 CLIP 训练中的输入数据并减少了计算量。
FLIP 认为屏蔽的好处在于明智地花费计算。直观上,这导致了FLIP对样本进行编码的密集程度与使用多少样本作为学习信号进行比较之间的权衡。通过引入掩蔽,可以:
(i)在相同的挂钟训练时间下从更多的图像文本对中学习
(ii)在相同的内存约束下使用更大的批次进行对比学习。
通过实验表明,对于这两个方面,FLIP 在权衡中都具有优势。
2.1 图像掩码
采用 ViT 作为图像编码器。图像首先被划分为不重叠的 patch。随机屏蔽掉大部分(例如 50% 或 75%)的 patch ; ViT 编码器仅应用于可见 patch。
使用50%(或75%)的掩码比将图像编码的时间复杂度降低到1/2(或1/4);它还允许使用 2 倍(或 4 倍)较大的批次,并使用相同的内存成本进行图像编码。
2.2 文字掩码
与图像掩码采用相同的方式执行文本掩码。FLIP 屏蔽了一部分文本标记,并将编码器仅应用于可见标记。这与 BERT 不同,BERT 用学习到的掩码标记替换它们。这种稀疏计算可以降低文本编码成本。然而,由于文本编码器较小,加速它并不会带来更好的整体权衡。研究文本屏蔽仅用于消融。
2.3 Objective
图像/文本编码器经过训练以最小化对比损失。对比学习的负样本对由同一批次中的其他样本组成。据观察,大量负样本对于图像的自监督对比学习至关重要,这一特性在语言监督学习中更为突出。
与 MAE 不同,FLIP 不使用重建损失。
作者发现重建对于零样本迁移的良好性能来说并不是必需的。放弃解码器和重建损失会产生更好的加速。
2.4 unmasking
虽然编码器是在掩码图像上进行预训练的,但它可以直接应用于完整图像而无需更改,这种简单的设置足以提供有竞争力的结果,并将作为消融实验的baseline。
为了弥补掩蔽造成的分布差距,可以将掩码率设置为0%,并继续进行少量步骤的预训练。这种unmasking 调整策略产生了更有利的精度/时间权衡。
3 实现
FLIP 实现遵循 CLIP 和 OpenCLIP ,并进行了一些修改。
-
图像编码器遵循 ViT 。在补丁嵌入后不使用额外的 LayerNorm。使用全局平均池化。输入大小为 224。
-
文本编码器是一个非自回归 Transformer ,它更容易适应文本掩码以进行消融。作者将序列填充或剪切为固定长度 32。
-
图像编码器和文本编码器的输出通过线性层投影到相同维度的嵌入空间。嵌入的余弦相似度由可学习的 temperature 参数缩放,是 InfoNCE 损失 的输入。
-
在零样本迁移中,遵循《Learning transferable visual models from natural language supervision》代码中的提示工程。使用他们提供的 7 个提示模板进行 ImageNet 零样本传输。
-
实现基于 JAX 和 t5x 库 ,用于大规模分布式训练。作者的训练在 TPU v3 基础设施上运行
4 实验
4.1 消融实验
图像编码器是 ViT-L/16 ,文本编码器具有较小的尺寸。作者在 LAION-400M 上进行训练,并在 ImageNet-1K 验证中评估零样本精度。

!
表中显示了 6.4 个时期训练的消融。图中绘制了最多 32 个时期的权衡。除非另有说明,结果是在 256 个 TPU-v3 核心上进行基准测试的。
4.1.1 掩码率
在这里,相应地缩放批量大小(接下来将被消融),以便大致保持内存占用量。10% 掩码条目表示作者的 CLIP 对应项。掩码 50% 的准确度比 CLIP baseline高 1.2%,掩码 75% 与baseline相当。就速度而言, FLIP 大幅减少,屏蔽 50% 或 75% 仅需要 0.50× 或 0.33× 挂钟训练时间。
4.1.2 批量大小
作者消除了表 1b 中批量大小的影响,增加批量大小可以持续提高准确性。
值得注意的是,即使使用相同的批量大小 16k,FLIP 的 50% 掩码条目也具有与 0% 掩码baseline(68.6%,表 1a)相当的准确度(68.5%,表 1b)。掩码引入的正则化可能可以减少过度拟合,部分抵消在此设置中丢失信息的负面影响。当掩码率高达 75% 时,在保持批量大小不变的情况下,仍然可以观察到负面影响。
作者基于掩码的方法自然鼓励使用大批量。如们根据掩码比扩大批量大小,则几乎不会产生额外的内存成本,如表 1a 中所示。实际上,可用内存始终是较大批次的限制。例如,表 1a 中的设置已达到作者高端基础设施中的内存限制(256 个 TPU-v3 核心,每个核心 16GB 内存)。如果使用较少的设备,内存问题会更加苛刻,作者的方法的增益将是由于批量大小几乎自由增加,这一点更加突出。
4.1.3 文本掩码
表 1c 研究了文本掩码。随机掩码 50% 的文本会使准确度降低 2.2%。这与语言数据比图像数据具有更高的信息密度一致,因此文本掩码率应该更低。
当可变长度文本序列被填充以生成固定长度批次时,可以优先屏蔽填充tokens。优先采样比随机均匀地掩码填充序列保留更多有效信息的标记。它将下降率降低至 0.4%。
虽然作者的文本掩码比典型的掩码语言模型更有效,但总体速度增益是微乎其微的。这是因为文本编码器较小并且文本序列较短。与图像编码器(无掩码)相比,文本编码器的计算成本仅为 4.4%。在这种设置下,文本屏蔽不是一个值得的权衡,作者在其他实验中不会掩码文本。
4.1.4 推理unmasking
默认情况下,作者对模型使用完整图像进行推理。虽然会在训练和推理之间产生分布偏移,但简单地忽略这种偏移效果出人意料地好(表 1d,“无掩码”),即使在从未对完整图像进行训练的零样本设置下也是如此。
表 1d 报告说,如果在推理时使用掩码,准确性会下降很多(例如 7.3%)。这种下降可能是由于推理时的信息丢失造成的,因此作者还与集成多个屏蔽视图进行比较,其中视图彼此互补并放在一起覆盖所有patch。集成缩小了差距(表1d),但仍然落后于简单的全视图推理。
4.1.5 Unmasking 微调
到目前为止,消融实验不涉及Unmasking 微调。表 1e 报告了在预训练数据集上进行额外 0.32 epoch 的无掩码调整的结果。在 75% 的高掩码率下,准确率提高了 1.3%,这表明这种调整可以有效减少预训练和推理之间的分布差距。

图 3中绘制了受未掩码调整影响的权衡(实线与虚线)。Unmasking 微调会带来更多的效果
4.1.6 重建
在表 1f 中,研究添加重建损失函数。重建头遵循MAE中的设计:它有一个小型解码器并重建归一化图像像素。重建损失被添加到对比损失中。
表 1f 显示重建对零短路结果有较小的负面影响。作者还看到 ImageNet 上的微调精度有类似的下降,,虽然这可能是次优超参数(例如,平衡两个损失)的结果,但为了简单起见,作者决定不使用重建损失。放弃重建头还有助于简化系统并提高准确性/时间权衡。
4.1.7 time VS accuracy 权衡

图中详细介绍了准确性与训练时间的权衡。将时间表扩展到最多 32 个时期。
如图所示,FLIP 显然比 CLIP 具有更好的权衡。它可以达到与 CLIP 相似的精度,同时享受 >3 倍的加速。使用相同的 32 epoch 计划,作者的方法比 CLIP 方法准确约 1%,速度快 2 倍(掩码 50%)。
CLIP baseline需要在 256 个 TPU-v3 核心上进行大约 10 天的训练,因此 2-3 倍的加速可以节省很多天的挂钟时间。
4.2 与CLIP的对比实验
在本节中,将在各种场景中与各种 CLIP baseline进行比较。证明FLIP方法是 CLIP 的有竞争力的替代方案
作者考虑以下 CLIP baseline:
? 原始 CLIP baseline,在私有数据集 WIT-400M 上进行训练。
? OpenCLIP ,在 LAION-400M 上进行训练。
? FLIP 再现,在LAION-400M 上进行训练。
原始的 CLIP 是在私有数据集上进行训练的,因此与其直接应该比较反映数据的效果,而不仅仅是方法。 OpenCLIP 是 CLIP 的忠实再现,但在作者可以使用的公共数据集上进行了训练,因此它对作者隔离数据集差异的影响是一个很好的参考。作者的 CLIP 再现进一步有助于隔离其他实现的微妙之处,并使作者能够查明 FLIP 方法的效果。
4.2.1 ImageNet 零样本传输

在表 2 中,FLIP与 ImageNet-1K 零样本传输的 CLIP 基线进行了比较。
作为健全性检查,作者的 CLIP 再现的准确性比在相同数据上训练的 OpenCLIP 稍高。
原始 CLIP 比作者的复制和 OpenCLIP 具有更高的准确性,这可能是由于预训练数据集之间的差异造成的。
表 2 报告了作者的 FLIP 模型的结果,使用了作者在表 1 中消除的最佳实践(64k 批次、50% 掩蔽比和无掩蔽调整)。对于 ViT-L/14,3,作者的方法具有 74.6% 的准确度,比 OpenCLIP 高 1.8%,比作者的 CLIP 再现高 1.5%。与原始 CLIP 相比,作者的方法将差距缩小到 0.7%。如果作者的方法是在 WIT 数据上进行训练的,作者认为作者的方法能够改善原始 CLIP 结果。
4.2.2 ImageNet 线性探测

表 3 比较了linear probe结果,即在具有冻结特征的目标数据集上训练线性分类器。 FLIP 的准确率达到 83.6%,比 CLIP 的准确率高 1.0%。它也比作者使用相同的 SGD 训练器传输原始 CLIP 检查点高 0.6%。
4.2.3 ImageNet 微调
表 3 还比较了完整的微调结果。作者的微调实现遵循 MAE ,针对每个条目调整学习率。值得注意的是,通过作者的微调方法,原始 CLIP 检查点达到 87.4%,远高于之前关于该指标的报告 。 CLIP 在微调下仍然是一个强大的模型。
FLIP 的性能优于在相同数据上预训练的 CLIP 模型。使用作者的微调配方,作者的结果为 86.9%(或使用 L/14 为 87.1%),但落后于原始 CLIP 检查点 87.4% 的结果。
4.2.4 对更多数据集进行零样本分类

在表 4 中,作者额外数据集进行了比较。由于结果可能对评估实施(例如文本提示、图像预处理)敏感,因此作者提供对原始 CLIP 检查点和 OpenCLIP 的评估。
值得注意的是,作者观察到由预训练数据造成的明显系统差距,使用相同的评估代码进行基准测试。 WIT 数据集对某些任务(例如 Aircraft、Country211、SST2)有益,而 LAION 对其他一些任务(例如 Birdsnap、SUN397、Cars)有益。
在隔离预训练数据的影响后,作者观察到 FLIP 明显优于 OpenCLIP 和作者的 CLIP 再现,如表 4 中的绿色标记。
4.2.5 零样本检索

表 5 报告了 Flickr30k 和 COCO 上的图像/文本检索结果。 FLIP 优于所有 CLIP 竞争对手,包括原始 CLIP(在相同的 224 尺寸上评估)。对于这两个检索数据集,WIT 数据集比 LAION 没有优势。
4.2.6 零样本稳健性评估

在表 6 中,作者对稳健性评估进行了比较。作者再次观察到由预训练数据引起的明显的系统差距。使用相同的评估代码(表 6 中的“作者的评估”),在 WIT 上预训练的 CLIP 明显优于在 LAION 上预训练的其他条目。以 IN-Adversarial (IN-A) 为例:基于 LAION 的 OpenCLIP的准确率仅为 48.3%(或 报告的 46.6%)。虽然 FLIP (51.2%) 可以大幅优于基于 LAION 的 CLIP,但仍比基于 WIT 的 CLIP (71.9%) 低 20%。
考虑到预训练数据的影响,作者的 FLIP 训练在所有情况下都明显比 CLIP 训练具有更好的鲁棒性。作者假设掩蔽作为噪声和正则化的一种形式可以提高鲁棒性
4.2.7 图像Caption

请参阅表 7 了解 COCO和 nocaps 上的字幕性能。作者的Caption实现遵循交叉熵训练基线。与预训练后仅添加分类器层的分类不同,这里的微调模型具有新初始化的Caption器(详见附录)。在此任务中,FLIP 在多个指标上都优于原始 CLIP 检查点。与作者在相同数据上进行预训练的 CLIP 基线相比,FLIP 也显示出明显的增益,特别是在 BLEU-4 和 CIDEr 指标方面。
4.2.8视觉问答
作者对 VQAv2 数据集 [26] 进行评估,并按照进行微调设置。作者使用新初始化的多模态融合变压器和答案分类器来获得 VQA 输出(详见附录)。表 7(最右列)报告了 VQAv2 的结果。在 LAION 上预训练的所有条目表现相似,在 WIT 上预训练的 CLIP 是最好的。
4.2.9 摘要
在各种场景中,FLIP 明显优于在相同 LAION 数据上预训练的 CLIP 对应物(OpenCLIP 和作者的复制品),在某些情况下差距很大。
正如在许多下游任务中观察到的那样,WIT 数据和 LAION 数据之间的差异可能会造成巨大的系统差距。作者希望作者的研究能够在未来的研究中引起人们对这些数据依赖性差距的关注。
4.3 Scaling Behavior
作者沿着这三个轴之一研究缩放:
? 模型缩放。作者用 ViT-H 替换 ViT-L 图像编码器,它有 ~2× 参数。文本编码器也会相应地缩放。
? 数据缩放。作者使用 LAION-2B 集将预训练数据从 4 亿扩展至 20 亿。为了更好地将更多数据的影响与更长训练的影响分开,作者固定采样数据的总数(12.8B,相当于400M数据的32个epoch和2B数据的6.4个epoch)。
? 计划扩展。作者将采样数据从 12.8B 增加到 25.6B(400M 数据的 64 个 epoch)。
作者每次都研究沿着这三个轴之一的缩放,同时保持其他轴不变。结果总结在图 4 和表 8 中。
4.3.1 训练曲线
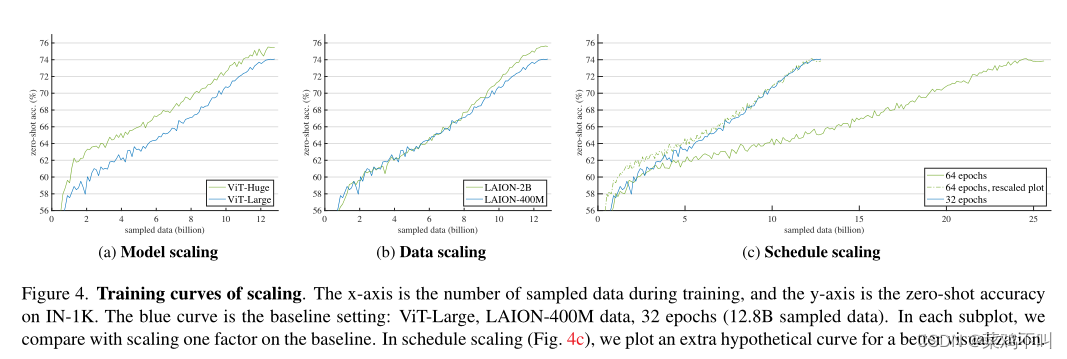
三种缩放策略在训练曲线上表现出不同的趋势(图 4)。
模型缩放(图 4a)呈现出在整个训练过程中持续存在的明显差距,尽管最终差距较小。
另一方面,数据缩放(图 4b)在训练的前半部分表现类似,但后来开始呈现良好的增益。
请注意,此设置中没有额外的计算成本,因为作者控制采样数据的总数。
时间表缩放(图 4c)训练时间延长 2 倍。为了提供更直观的比较,作者绘制了一条沿 x 轴(虚线)重新缩放 1/2 的假设曲线。尽管训练时间更长,但收益正在减少或没有(更多数字见表 8)。
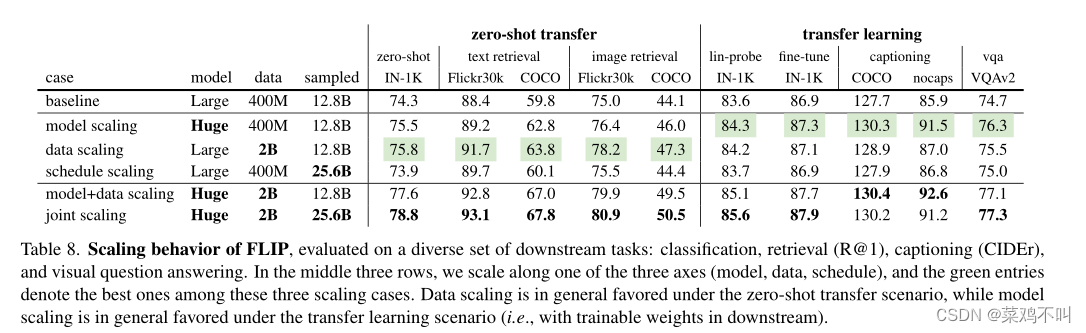
4.3.2 可转移性
表 8 提供了有关扩展行为的各种下游任务的全面比较。总体而言,模型扩展和数据扩展在所有指标中都可以始终优于基线,在某些情况下甚至大幅优于基线。
作者将下游任务分为两种场景:
(i)零样本迁移,即不对下游数据集进行学习;
(ii) 迁移学习,即部分或全部权重在下游数据集上进行训练。
对于这里研究的任务,数据扩展通常有利于零样本迁移,而模型扩展通常有利于迁移学习。然而值得注意的是,迁移学习的性能取决于下游数据集的大小,在太小的下游数据集上训练大模型仍然会面临过拟合的风险。
令人鼓舞的是,数据扩展显然是有益的,甚至不需要更长的训练或额外的计算。相反,即使通过计划扩展花费更多的计算也会带来收益递减。这些比较表明,大规模数据的好处主要是因为它们提供了更丰富的信息。
接下来,作者缩放模型和数据(表 8,倒数第二行)。对于所有指标,模型+数据扩展比单独扩展有所改进。模型缩放和数据缩放的收益是高度互补的:例如,在零样本 IN-1K 中,单独的模型缩放比基线提高了 1.2% (74.3%→75.5%),单独的数据缩放提高了 1.5% (74.3 %→75.8%)。缩放比例均提高了 3.3% (77.6%),超过两个增量的总和。在其他几个任务中也观察到这种行为。这表明更大的模型需要更多数据来释放其潜力。
最后,作者报告所有三个轴的联合扩展(表 8,最后一行)。作者的结果表明,结合计划扩展可以提高大多数指标的性能。
这表明,当与更大的模型和更大规模的数据相结合时,计划扩展特别有益。
作者在零样本 IN-1K 上的结果为 78.8%,优于使用 ViTH 在公共数据上训练的最先进结果(OpenCLIP 的 78.0%)。同样基于 LAION-2B,他们的结果是用 32B 采样数据训练的,比作者多 1.25 倍。鉴于作者使用 50% 的掩蔽,如果两者都在相同的硬件上运行,作者的训练预计比他们快 2.5 倍。由于 OpenCLIP 的结果报告训练成本为 ~5,600 个 GPU 天,给予一个粗略的估计作者的方法可以节省 ~3,360 个 GPU 天。此外,在不启用 2 倍调度的情况下,作者的“模型+数据扩展”条目估计比他们快 5 倍,并且可以节省约 4,480 个 GPU 天。这是相当大的成本降低。
5 讨论和总结
自然语言是比经典封闭式标签更强的监督形式。语言为监督提供了丰富的信息。因此,增加容量(模型扩展)和增加信息(数据扩展),对于在语言监督训练中获得良好结果至关重要。
CLIP 的简单设计使其能够相对容易地在更大的规模上执行,并且与之前的方法相比实现了巨大的飞跃。FLIP在很大程度上保持了 CLIP 的简单性,同时进一步推动其在缩放方面的发展。
FLIP 可以提供 2-3 倍甚至更多的加速。对于本研究中涉及的规模,这种加速可以大量减少挂钟时间(例如,大约数千个 TPU/GPU 天)。
FLIP研究涉及与各种 CLIP baseline的受控比较,这有助于打破不同因素造成的差距。作者证明 FLIP 的性能优于在相同 LAION 数据上预训练的 CLIP 模型。通过比较几个基于 LAION 的模型和原始的基于 WIT 的模型,观察到预训练数据在几个任务中造成了巨大的系统差距。
FLIP 提供了有关缩放行为的受控实验。观察到数据缩放是一个有效的缩放维度,因为它可以提高准确性,而无需在训练或推理时产生额外成本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Cypress.io:快速简单可靠的浏览器测试工具 | 开源日报 No.142
- 梁山泊国潮风礼盒,传承经典,贺礼新春
- Java中创建线程池工具类
- 高端大气的在线文档
- 统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
- Java实战:Swing版记事本
- YACS(上海计算机学会竞赛平台)2022年10月月赛——算式求值(一)
- [DevOps-04] Operate阶段工具
- 931. 下降路径最小和-Python-DP-简单题
- springboot整合kafka附源码