【深度学习目标检测】四、基于深度学习的抽烟识别(python,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。
YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。
YOLOv8采用了Darknet-53作为其基础网络架构。Darknet-53是一个53层的卷积神经网络,用于提取图像特征。与传统的卷积神经网络相比,Darknet-53具有更深的网络结构和更多的卷积层,可以更好地捕捉图像中的细节和语义信息。
在YOLOv8中,还使用了一些技术来提高检测性能。首先是使用了多尺度检测。YOLOv8在不同的尺度上检测物体,这样可以更好地处理物体的大小变化和远近距离差异。其次是利用了FPN(Feature Pyramid Network)结构来提取多尺度特征。FPN可以将不同层级的特征图进行融合,使得算法对不同大小的物体都有较好的适应性。
此外,YOLOv8还利用了一种称为CSPDarknet的网络结构来减少计算量。CSPDarknet使用了CSP(Cross Stage Partial)结构,在网络的前向和后向传播过程中进行特征融合,从而减少了网络的参数量和计算量。
在训练阶段,YOLOv8使用了一种称为CutMix的数据增强技术。CutMix将不同图像的一部分进行混合,从而增加了数据的多样性和鲁棒性。
总而言之,YOLOv8是一种快速而准确的物体检测算法,它通过引入Darknet-53网络、多尺度检测、FPN结构、CSPDarknet结构和CutMix数据增强等技术,实现了对不同大小和距离的物体进行快速、准确的检测。
本文介绍了基于Yolov8的抽烟检测模型,包括训练过程和数据准备过程,同时提供了推理的代码。对准备计算机视觉相关的毕业设计的同学有着一定的帮助。
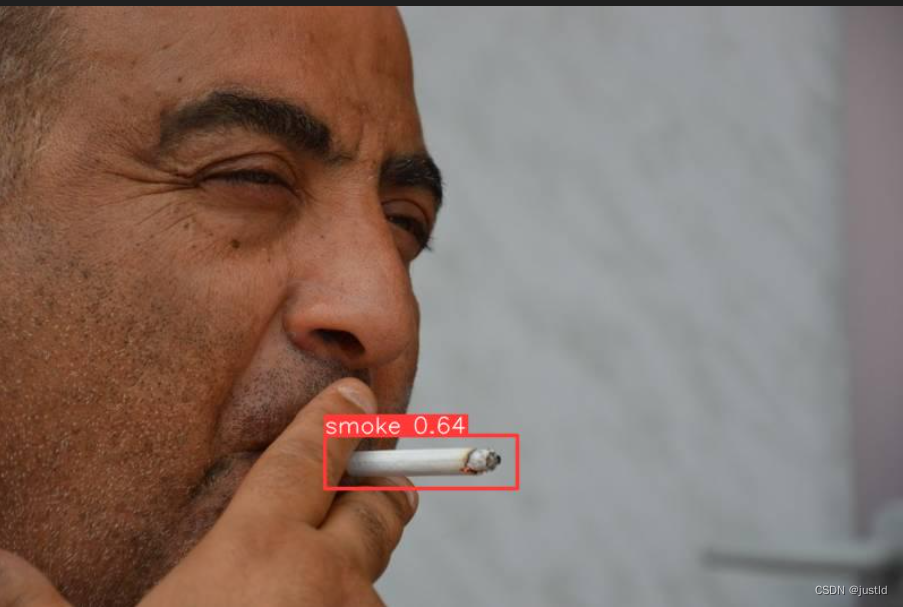
效果如下图:
一、安装YoloV8
yolov8官方文档:https://docs.ultralytics.com/zh/
安装部分参考:官方安装教程
二、数据集准备
抽烟数据集共包含705个训练图片,78个验证图片,图片示例如下:


原始的数据格式为VOC格式,本文提供转换好的yolov8格式数据集,,可以直接放入yolov8中训练,数据集地址:抽烟数据集yolov8格式
三、修改yolov8配置文件
1、修改数据集配置文件
将path替换成自己的数据集路径:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: datasets/smoke/pp_smoke-yolov8 # 更改为自己的数据集路径,建议绝对路ing
train: images/train
val: images/val
test: images/val
# Classes
names:
0: smoke
2、配置模型文件
模型配置文件如下,将nc改成1:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
3、训练模型
使用如下命令开始训练(将相关路径改成自己的路径,建议改成绝对路径):
yolo detect train project=deploy name=yolov8_smoke exist_ok=True optimizer=auto val=True amp=True epochs=100 imgsz=640 model=ultralytics/ultralytics/cfg/models/v8/yolov8_smoke.yaml data=ultralytics/ultralytics/cfg/datasets/smoke.yaml
4、评估模型
使用如下命令评估:
yolo detect val imgsz=640 model=deploy/yolov8_smoke/weights/best.pt data=ultralytics/ultralytics/cfg/datasets/smoke.yaml
精度如下:

5、推理
推理代码如下:
from PIL import Image
from ultralytics import YOLO
# 加载预训练的YOLOv8n模型
model = YOLO('best.pt')
# 在'bus.jpg'上运行推理
image_path = 'smoke_a205.jpg'
results = model(image_path) # 结果列表
# 展示结果
for r in results:
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像
四、相关资料
本文在训练好的模型和推理代码:推理代码和权重
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何使用 Flutter 和地理位置 API 构建基于位置的移动应用程序?
- 残疾人聋哑人专用起床叫醒器震动起床提醒器
- 地理空间分析5——空间关联分析与Python
- 【温故而知新】vue运用之探讨下单页面应用(SPA)与多页面应用(MPA)
- 【RocketMQ每日一问】RocketMQ如何保证消息不丢失?
- ecmaScript-定义变量
- 减小PAPR——PTS技术
- alpha测试和beta测试Gamma测试的区别是什么?
- 面向对象程序设计(异常,RTTI,泛型,动态加载)
- PyTorch视觉工具箱:图像变换与上采样技术详解(1)