FF++数据集下载脚本代码
发布时间:2024年01月19日
#!/usr/bin/env python
""" Downloads FaceForensics++ and Deep Fake Detection public data release
Example usage:
see -h or https://github.com/ondyari/FaceForensics
代码如下:
那位好人下载下来了,可以传给孩子一份啊,孩子真的像发疯了,一直显示502,如有可以分享的友友可以私信我~万分感谢~
FF++数据集是一个用于深度伪造视频检测和分类的数据集,它包含了多种操纵方法和样本。以下是FF++数据集中常见的操纵方式和相应的样本数量:
DeepFake(DF):将人脸转换为另一个人的人脸,使用深度学习模型生成的伪造视频。样本数量约为10,000个。
FaceSwap(FS):将一个人的脸与另一个人的脸进行交换,生成伪造视频。样本数量约为3,000个。
Face2Face(F2F):将一个人的表情和动作映射到另一个人的脸上,生成伪造视频。样本数量约为2,000个。
NeuralTextures(NT):通过合成的方式将一个人的面部纹理添加到另一个人的脸上,生成伪造视频。样本数量约为1,000个。
FaceManipulation(FM):对真实视频进行修改,如对人脸进行遮挡、添加噪声等,生成伪造视频。样本数量约为1,000个。
"""
# -*- coding: utf-8 -*-
import argparse
import os
import urllib
import urllib.request
import tempfile
import time
import sys
import json
import random
from tqdm import tqdm
from os.path import join
# URLs and filenames
FILELIST_URL = 'misc/filelist.json'
DEEPFEAKES_DETECTION_URL = 'misc/deepfake_detection_filenames.json'
DEEPFAKES_MODEL_NAMES = ['decoder_A.h5', 'decoder_B.h5', 'encoder.h5',]
# Parameters
DATASETS = {
'original_youtube_videos': 'misc/downloaded_youtube_videos.zip',
'original_youtube_videos_info': 'misc/downloaded_youtube_videos_info.zip',
'original': 'original_sequences/youtube',
'DeepFakeDetection_original': 'original_sequences/actors',
'Deepfakes': 'manipulated_sequences/Deepfakes',
'DeepFakeDetection': 'manipulated_sequences/DeepFakeDetection',
'Face2Face': 'manipulated_sequences/Face2Face',
'FaceShifter': 'manipulated_sequences/FaceShifter',
'FaceSwap': 'manipulated_sequences/FaceSwap',
'NeuralTextures': 'manipulated_sequences/NeuralTextures'
}
ALL_DATASETS = ['original', 'DeepFakeDetection_original', 'Deepfakes',
'DeepFakeDetection', 'Face2Face', 'FaceShifter', 'FaceSwap',
'NeuralTextures']
COMPRESSION = ['raw', 'c23', 'c40']
TYPE = ['videos', 'masks', 'models']
SERVERS = ['EU', 'EU2', 'CA']
def parse_args():
parser = argparse.ArgumentParser(
description='Downloads FaceForensics v2 public data release.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument('output_path', type=str, help='Output directory.')
parser.add_argument('-d', '--dataset', type=str, default='all',
help='Which dataset to download, either pristine or '
'manipulated data or the downloaded youtube '
'videos.',
choices=list(DATASETS.keys()) + ['all']
)
parser.add_argument('-c', '--compression', type=str, default='raw',
help='Which compression degree. All videos '
'have been generated with h264 with a varying '
'codec. Raw (c0) videos are lossless compressed.',
choices=COMPRESSION
)
parser.add_argument('-t', '--type', type=str, default='videos',
help='Which file type, i.e. videos, masks, for our '
'manipulation methods, models, for Deepfakes.',
choices=TYPE
)
parser.add_argument('-n', '--num_videos', type=int, default=None,
help='Select a number of videos number to '
"download if you don't want to download the full"
' dataset.')
parser.add_argument('--server', type=str, default='EU',
help='Server to download the data from. If you '
'encounter a slow download speed, consider '
'changing the server.',
choices=SERVERS
)
args = parser.parse_args()
# URLs
server = args.server
if server == 'EU':
server_url = 'http://canis.vc.in.tum.de:8100/'
elif server == 'EU2':
server_url = 'http://kaldir.vc.in.tum.de/faceforensics/'
elif server == 'CA':
server_url = 'http://falas.cmpt.sfu.ca:8100/'
else:
raise Exception('Wrong server name. Choices: {}'.format(str(SERVERS)))
args.tos_url = server_url + 'webpage/FaceForensics_TOS.pdf'
args.base_url = server_url + 'v3/'
args.deepfakes_model_url = server_url + 'v3/manipulated_sequences/' + \
'Deepfakes/models/'
return args
def download_files(filenames, base_url, output_path, report_progress=True):
os.makedirs(output_path, exist_ok=True)
if report_progress:
filenames = tqdm(filenames)
for filename in filenames:
download_file(base_url + filename, join(output_path, filename))
def reporthook(count, block_size, total_size):
global start_time
if count == 0:
start_time = time.time()
return
duration = time.time() - start_time
progress_size = int(count * block_size)
speed = int(progress_size / (1024 * duration))
percent = int(count * block_size * 100 / total_size)
sys.stdout.write("\rProgress: %d%%, %d MB, %d KB/s, %d seconds passed" %
(percent, progress_size / (1024 * 1024), speed, duration))
sys.stdout.flush()
def download_file(url, out_file, report_progress=False):
out_dir = os.path.dirname(out_file)
if not os.path.isfile(out_file):
fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)
f = os.fdopen(fh, 'w')
f.close()
if report_progress:
urllib.request.urlretrieve(url, out_file_tmp,
reporthook=reporthook)
else:
urllib.request.urlretrieve(url, out_file_tmp)
os.rename(out_file_tmp, out_file)
else:
tqdm.write('WARNING: skipping download of existing file ' + out_file)
def main(args):
# TOS
print('By pressing any key to continue you confirm that you have agreed '\
'to the FaceForensics terms of use as described at:')
print(args.tos_url)
print('***')
print('Press any key to continue, or CTRL-C to exit.')
_ = input('')
# Extract arguments
c_datasets = [args.dataset] if args.dataset != 'all' else ALL_DATASETS
c_type = args.type
c_compression = args.compression
num_videos = args.num_videos
output_path = args.output_path
os.makedirs(output_path, exist_ok=True)
# Check for special dataset cases
for dataset in c_datasets:
dataset_path = DATASETS[dataset]
# Special cases
if 'original_youtube_videos' in dataset:
# Here we download the original youtube videos zip file
print('Downloading original youtube videos.')
if not 'info' in dataset_path:
print('Please be patient, this may take a while (~40gb)')
suffix = ''
else:
suffix = 'info'
download_file(args.base_url + '/' + dataset_path,
out_file=join(output_path,
'downloaded_videos{}.zip'.format(
suffix)),
report_progress=True)
return
# Else: regular datasets
print('Downloading {} of dataset "{}"'.format(
c_type, dataset_path
))
# Get filelists and video lenghts list from server
if 'DeepFakeDetection' in dataset_path or 'actors' in dataset_path:
filepaths = json.loads(urllib.request.urlopen(args.base_url + '/' +
DEEPFEAKES_DETECTION_URL).read().decode("utf-8"))
if 'actors' in dataset_path:
filelist = filepaths['actors']
else:
filelist = filepaths['DeepFakesDetection']
elif 'original' in dataset_path:
# Load filelist from server
file_pairs = json.loads(urllib.request.urlopen(args.base_url + '/' +
FILELIST_URL).read().decode("utf-8"))
filelist = []
for pair in file_pairs:
filelist += pair
else:
# Load filelist from server
file_pairs = json.loads(urllib.request.urlopen(args.base_url + '/' +
FILELIST_URL).read().decode("utf-8"))
# Get filelist
filelist = []
for pair in file_pairs:
filelist.append('_'.join(pair))
if c_type != 'models':
filelist.append('_'.join(pair[::-1]))
# Maybe limit number of videos for download
if num_videos is not None and num_videos > 0:
print('Downloading the first {} videos'.format(num_videos))
filelist = filelist[:num_videos]
# Server and local paths
dataset_videos_url = args.base_url + '{}/{}/{}/'.format(
dataset_path, c_compression, c_type)
dataset_mask_url = args.base_url + '{}/{}/videos/'.format(
dataset_path, 'masks', c_type)
if c_type == 'videos':
dataset_output_path = join(output_path, dataset_path, c_compression,
c_type)
print('Output path: {}'.format(dataset_output_path))
filelist = [filename + '.mp4' for filename in filelist]
download_files(filelist, dataset_videos_url, dataset_output_path)
elif c_type == 'masks':
dataset_output_path = join(output_path, dataset_path, c_type,
'videos')
print('Output path: {}'.format(dataset_output_path))
if 'original' in dataset:
if args.dataset != 'all':
print('Only videos available for original data. Aborting.')
return
else:
print('Only videos available for original data. '
'Skipping original.\n')
continue
if 'FaceShifter' in dataset:
print('Masks not available for FaceShifter. Aborting.')
return
filelist = [filename + '.mp4' for filename in filelist]
download_files(filelist, dataset_mask_url, dataset_output_path)
# Else: models for deepfakes
else:
if dataset != 'Deepfakes' and c_type == 'models':
print('Models only available for Deepfakes. Aborting')
return
dataset_output_path = join(output_path, dataset_path, c_type)
print('Output path: {}'.format(dataset_output_path))
# Get Deepfakes models
for folder in tqdm(filelist):
folder_filelist = DEEPFAKES_MODEL_NAMES
# Folder paths
folder_base_url = args.deepfakes_model_url + folder + '/'
folder_dataset_output_path = join(dataset_output_path,
folder)
download_files(folder_filelist, folder_base_url,
folder_dataset_output_path,
report_progress=False) # already done
if __name__ == "__main__":
args = parse_args()
main(args)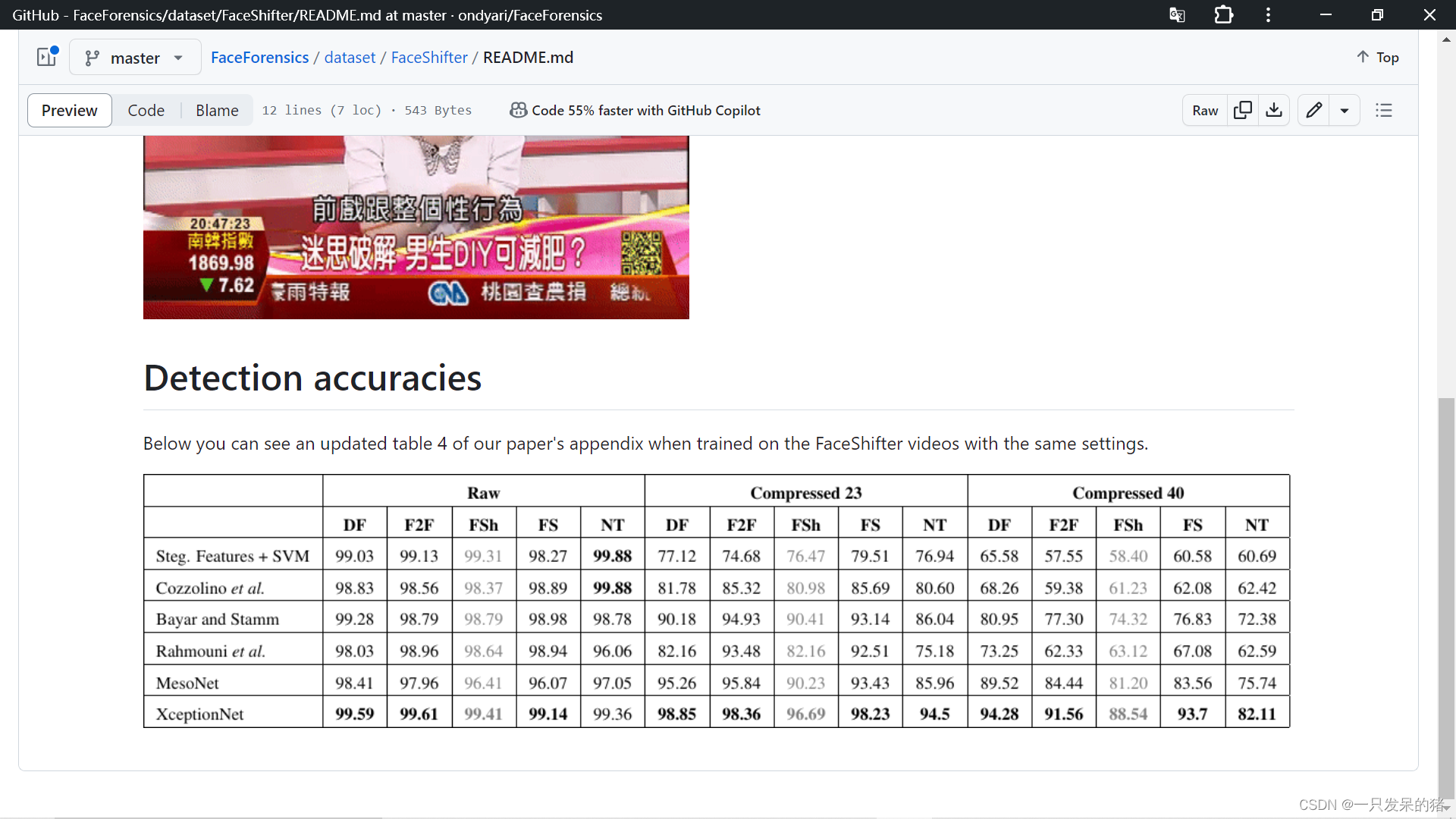
python download_faceforensics.py <output_path> [options]
```
Replace `<output_path>` with the path where you want to save the downloaded files.
Optional arguments:
- `-d, --dataset`: Specify the dataset to download (default: all).
- `-c, --compression`: Specify the compression degree (default: raw).
- `-t, --type`: Specify the file type (default: videos).
- `-n, --num_videos`: Select a number of videos to download (default: None).
- `--server`: Specify the server to download from (default: EU).
Use the `-h` or `--help` option to see the full list of available options and their descriptions.
文章来源:https://blog.csdn.net/weixin_56180495/article/details/135634213
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章