Self-Attention
发布时间:2024年01月13日
前置知识:RNN,Attention机制
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素和Source中的所有元素之间。
Self-Attention是在Source内部元素或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制,相当于是Query=Key=Value,计算过程与Attention一样。
作用
Self-Attention模型可以理解为对RNN的替代,有着以下两个作用:
-
引入Self-Attention后会更容易捕获句子中长距离的相互依赖的特征。Self-Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
-
Self Attention对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self Attention逐渐被广泛使用的主要原因。

对于计算并行性的分析
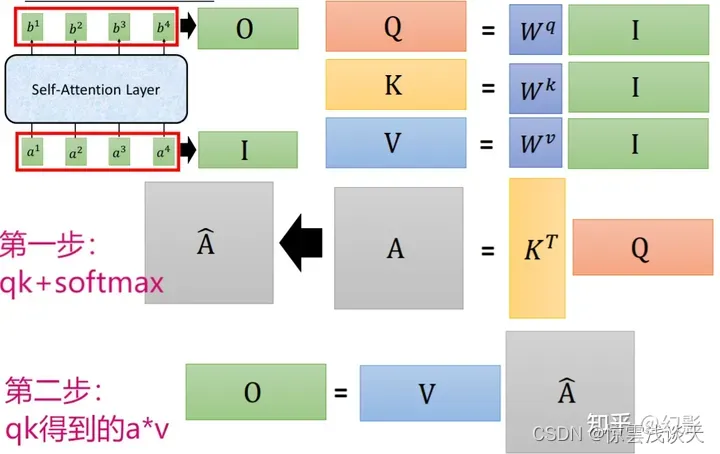
Self-Attention使得Attention模型满足:
其中:
-
dk是Q和K的维度(矩阵中向量的个数,即列数)
对于位置信息的分析

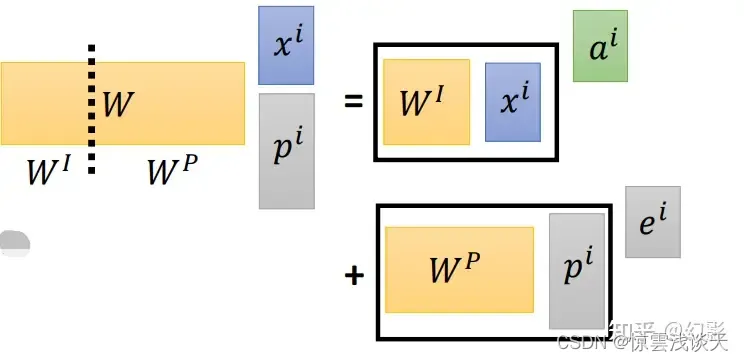
这个位置信息ei不是学出来的,在paper里,是人手设置出来的,每个位置都不一样,代表在第几个positon。
我们构造一个p向量,这是一个one-hot向量,只有某一维为1,代表这个单元是第几个位置。
我们和x进行拼接再进行w的运算得到a,它又等价于右边的公式,相当于ai+ei:
文章来源:https://blog.csdn.net/lty1392309506/article/details/135569501
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录Day8
- 影响TDR测量的关键因素
- 【Wechat_MiniProgram_JS】拓展运算符——`...`JavaScript运算符?
- ZZULIOJ 1118: 数列有序
- 深度学习记录--Momentum gradient descent
- Fiddler及浏览器开发者工具进行弱网测试
- 前端框架前置学习Webpack(1) 常用webpack配置
- 【机组】指令控制模块实验的解密与实战
- Git同步一个分支的提交到另一个分支
- VSCode-Python报错:Import“unreal“could not be resolved Pylance(reportMissingImports)