[Linux 进程(五)] 程序地址空间深度剖析

1、前言
Linux学习路线比较线性,也比较长,因此一个完整的知识点学习就会分布在两篇文章中,没有连贯起来,订阅的朋友谅解一下,再次感谢订阅!
上一篇文章最后讲到了程序地址空间分布,大家可以先复习一下上一篇文章:程序地址空间的初认识
本片我们深度学习一下程序地址空间,虚拟地址与物理地址的关系,页表与物理地址的映射,写时拷贝的过程,我们带着这些问题开始我们今天新的学习!
2、什么是进程地址空间?
在学习地址空间前,我们要明确:C/C++看到的地址其实并不是真正的地址,它其实是 虚拟地址,真正的地址是物理地址。
我们通过一个故事来带大家更好的理解一下什么是地址空间:
有一个大富豪,他有10亿的资产,同时拥有四个私生子,这四个私生子互相不知道其他人的存在。
私生子1是学生,私生子2是一个社会青年,私生子3是律师,私生子4是企业家。一天富豪分别对四个私生子说:
对1说:你是咱家的大学生,好好学习,以后这10个亿都是你的。
对2说:……,以后这10个亿都是你的。
对3说:……,以后这10个亿都是你的。
对4说:……,以后这10个亿都是你的。
他们都各自以为自己有10个亿等着继承呢,于是他们断断续续的对父亲说:
1:……,有用,需要xxx钱(不过10亿的1/10)。父亲给了。
2:……,有用,需要xxx钱(不过10亿的1/10)。父亲给了。
3:……,有用,需要xxx钱(不过10亿的1/10)。父亲给了。
4:……,有用,需要xxx钱(不过10亿的1/10)。父亲给了。
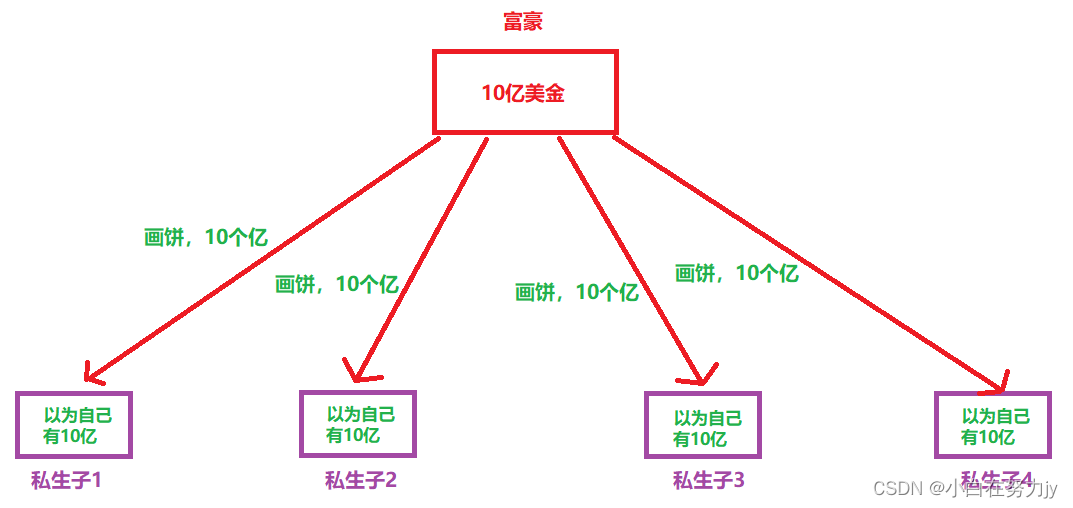
操作系统对应富豪;
内存对应那真实的10个亿;
进程对应为私生子;
虚拟地址空间对应富豪对他们每个人画的10亿的饼。
总结:
地址空间其实并不是真实的,是操作系统给进程画的饼。
3、进程地址空间的划分
我们看一下地址空间的分布:
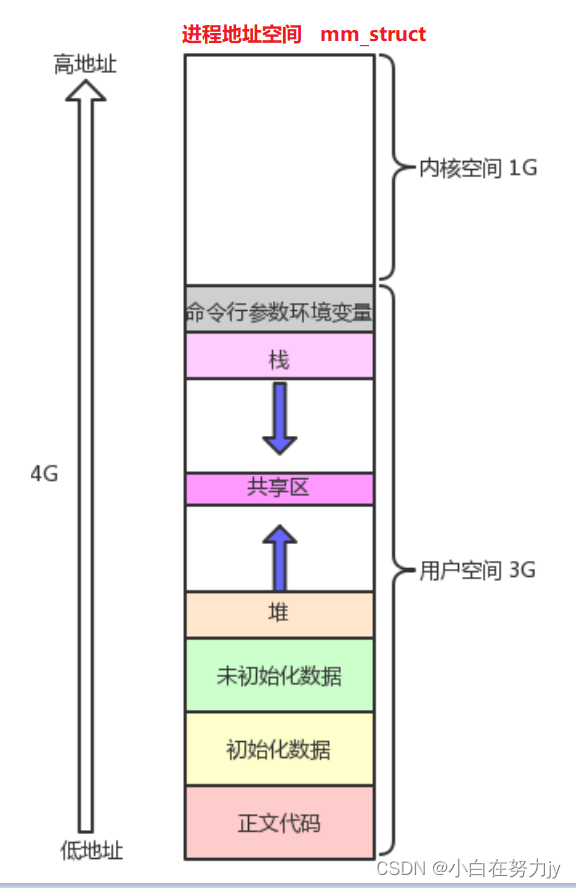
地址空间其实就是上面各个区域结合起来,这些区域的划分很简单,用begin与end两个变量一个指头,一个指尾,来限制范围即可。
根据以上的学习,我们不难得知:虽然地址空间是操作系统给进程画的的饼,但是进程多了这些地址空间我们也需要管理起来,要不然进程和对应的地址空间对应不上。说到管理就不得不提“先描述,再组织”。Linux中,这个进程/虚拟地址空间这个东西,叫做:
struct mm_struct
{
long code_start; // 代码区开始
long code_end; // 代码区结束
long data_start; // 数据区开始
long data_end; // 数据区结束
long heap_start; // 堆区开始
long heap_end; // 堆区结束
long stack_start; // 栈区开始
long stack_end; // 栈区结束
... // 其他属性
}
进程地址空间mm_struct里面其实就是维护了一张链表,每个节点是一个结构体vm_area_struct,里面存的就是一个区域的开始和结束地址。
4、虚拟地址与物理地址的关系
我们来写一段代码探究一下地址:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int g_val = 100;
int main()
{
pid_t id = fork();
if(id == 0)
{
// child
int cnt = 5;
while(1)
{
printf("child, Pid: %d, Ppid: %d, g_val: %d, &g_val = %p\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
if(cnt == 0)
{
g_val = 200;
printf("child change g_val: 100->200\n");
}
cnt--;
}
}
else
{
// father
while(1)
{
printf("father, Pid: %d, Ppid: %d, g_val = %d, &g_val = %p\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
}
}
return 0;
}
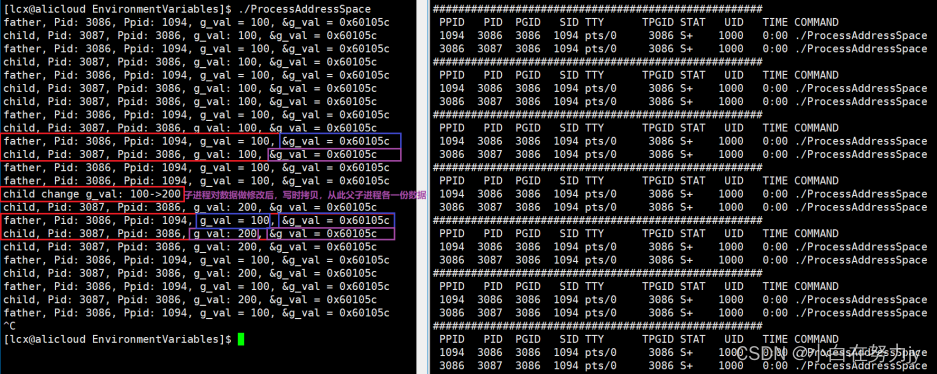
我们知道,在没有发生对数据的改写时,父子进程共用一份代码和数据,这里子进程对数据进行了修改,父子进程读到的值不同了,父子进程的全局变量地址怎么还是相同的???
问题:
父子进程对同一个地址进行读取,竟然读出了不同的值?
我们这就能得出之前的结论:我们C/C++看到的地址是虚拟地址。
有了上面的理解,我们再来谈谈虚拟地址和物理地址的关系:
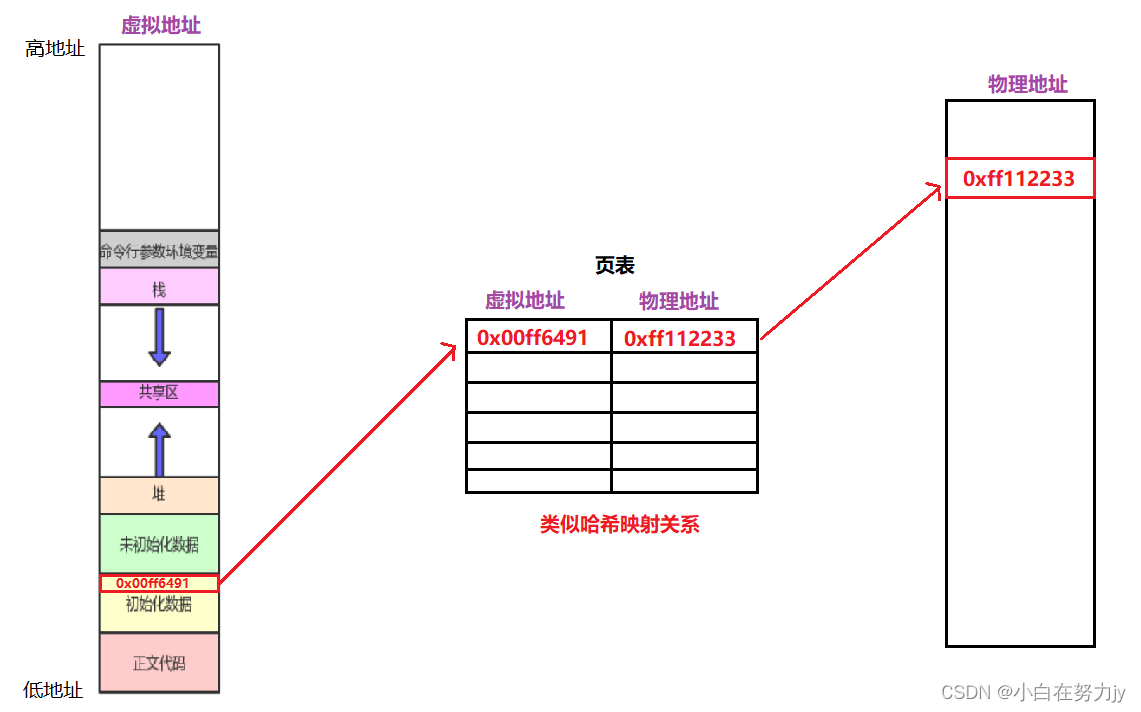
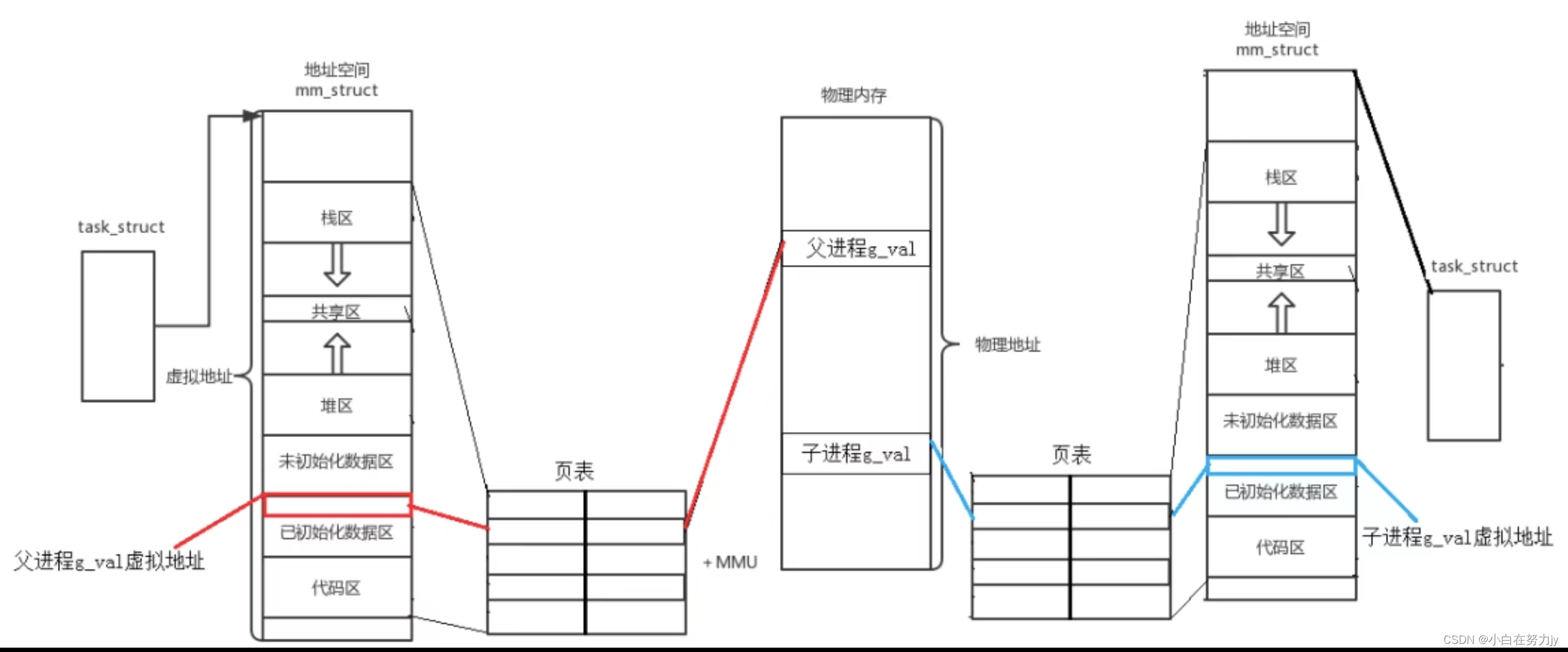
经过虚拟地址的学习以及这张图,我们现在就可以解释,同一个地址的值不同。
当我们fork创建了子进程的时候,子进程与父进程共享一份代码和数据,此时子进程与父进程进程地址空间与页表是一份。
当子进程对值进行修改的时,操作系统将父进程的进程地址空间与页表拷贝一份给子进程。当写入时,产生写时拷贝,重新开一块物理地址存内容,并将子进程页表中物理地址修改即可,子进程的虚拟地址没有变。因此父子进程虚拟地址相同是表象,本质物理地址已经修改了。
5、页表的作用
页表的结构中还有一栏,访问权限,我们下面看一下:
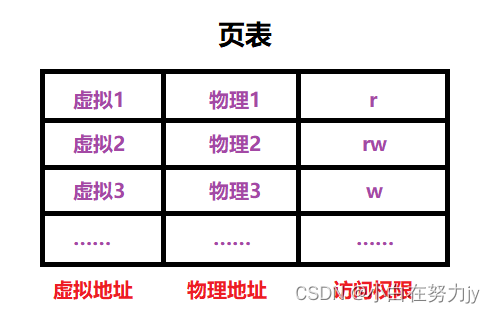
根据此结构,我们知道了页表的第一个作用:页表的存在可以有效的进行进程访问内存的安全检查!
我们配合一段代码,大家更好理解:
char* str = "hello Linux";
*str = 'H';
我们都知道hello Linux是在字符常量区的,是不可被修改的,它不可被修改的本质就是:在页表中,访问权限被设置为r(只读权限)。并不是因为是在代码区不可被修改,内存是可以随意读写的,因为有页表权限的限制。
页表的第二个作用:将无序变有序。
物理内存是不分代码区,栈区,堆区等的,数据在物理内存中的存储是无序的。
页表的存在让进程以统一的视角看待内存,所以任意一个进程,可以通过地址空间+页表可以将乱序的内存数据,变为有序,分门别类的规划好!
CPU中有一个寄存器CR3,它会保存当前进程的页表地址,此页表地址直接就是物理地址。操作系统给用户一个映射的页表,是为了上面的两个作用,它自己是不需要的。
扩展
总结:
- 每一个进程都是有页表的;
- 进程切换,不仅仅是PCB与代码、数据的切换,切换时还要带走自己的进程地址空间与页表。
根据以上的学习,我们想一下,我们的内存只有16/32/64,但是运行一个几百G的大型游戏,是怎么运行的呢?
其实并不是要把这几百G的数据全部加载上来的,而是将数据边加载边执行,对挂起的一个模块数据与代码先换出,然后加载需要加载的,这样进程在内存中就动态的运行起来了。
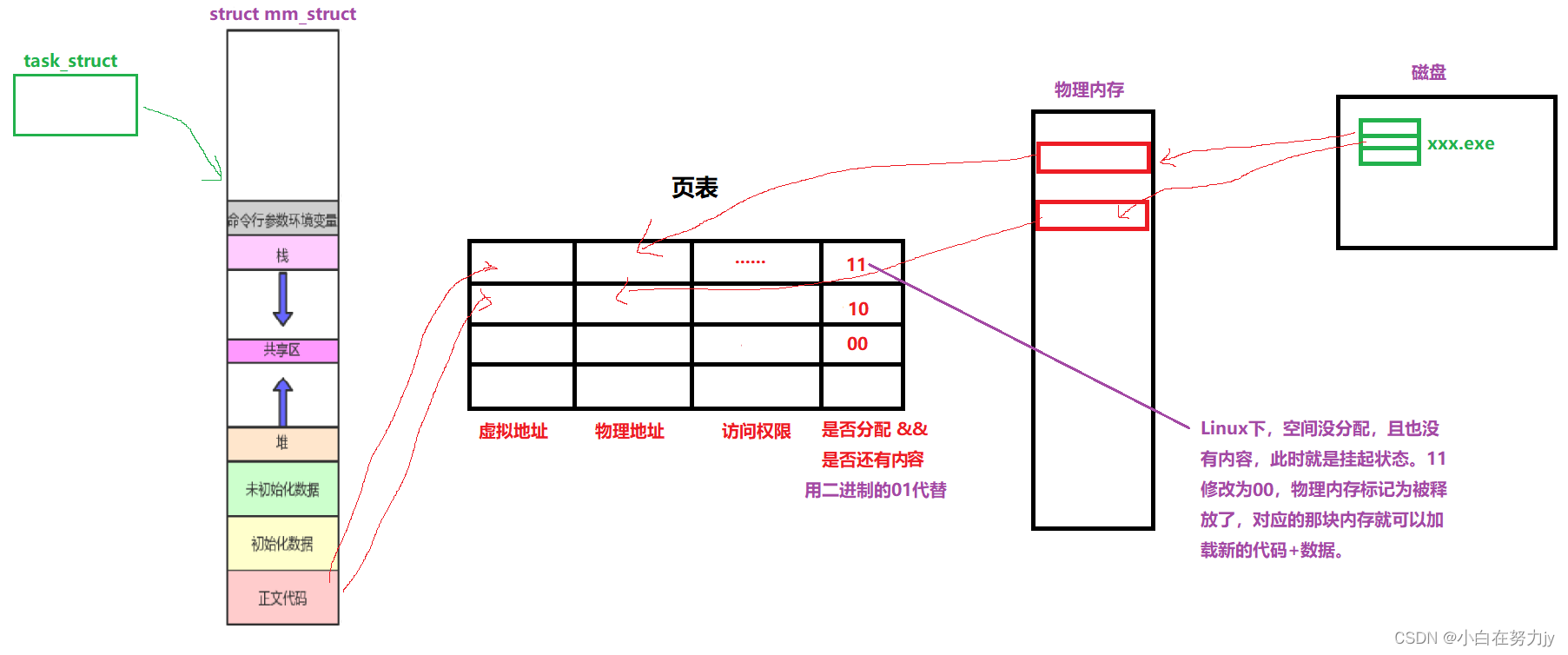
这就是地址空间的分配。当我们其中一块代码被执行完,我们可以覆盖式的像物理内存中重新加载内容,或者重新开辟新的物理内存,重新建立新的映射关系,就可以让程序边加载边执行。
页表中,还有可能存在虚拟地址存在,其他都不存在的情况:
当访问到页表的虚拟地址存在,其他内容不存在时,此时访问暂停,操作系统先申请内存,再根据虚拟地址找到那个可执行程序,重新加载到内存里,并把对应的物理内存放入页表,这时再开始访问,就开始运行新加载的代码了。这个过程叫做缺页中断。
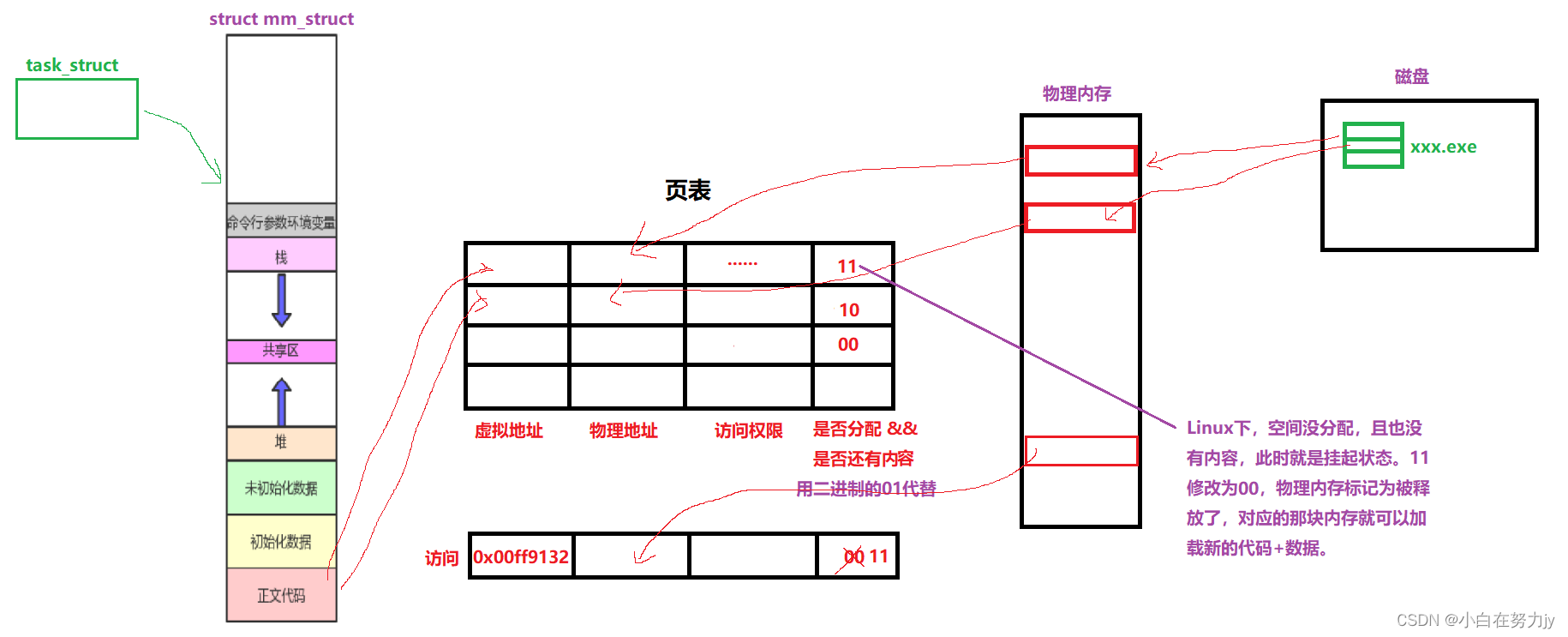
我们其实也不难发现,这背后的一切进程是完全不知道的,是os给做的,所以页表的第三个作用:
页表 左边是进程管理,右边是内存管理。降低进程管理和内存管理的耦合度。
6、为什么要有地址空间?
通过上面的学习,我们来总结一下这个问题的答案:
- 1、有效的保护了物理地址的安全。通过进程地址空间+页表的映射,对不合法的操作可以有效的拦截。
- 2、将物理地址的无序变为有序。物理内存是不分代码区,栈区,堆区等的,数据在物理内存中的存储是无序的。页表的存在让进程以统一的视角看待内存,所以任意一个进程,可以通过地址空间+页表可以将乱序的内存数据,变为有序,分门别类的规划好!
- 3、降低进程管理和物理内存管理之间的耦合度。因为进程地址空间和页表的存在,物理内存可以不关心数据类型,直接对数据进行加载,这样进程管理与物理内存管理就做到了解耦。
- 4、保证进程的独立性。因为地址空间的存在,各个进程都认为所有的内存空间都属于自己。每个进程都有自己的地址空间+页表,这两者配合实现了进程的独立性,每个不知道也不需要知道其他进程的存在!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 碳排放预测 | 基于ARIMA和GM(1,1)的碳排放预测(Matlab)
- 海思3559 yolov5模型转wk详细笔记
- Python 全栈体系【四阶】(八)
- Visual Studio2022实用使用技巧集
- Spring的Bean你了解吗
- 【FPGA/verilog -入门学习17】vivado 实现串口自发自收程序
- odoo17 | 模型视图继承
- 创建第一个SpringMVC项目,入手必看!
- RT-Thread学习
- smartgit选择30天试用后需要输入可执行文件