浏览器原理篇—渲染阻塞
渲染阻塞
1.DOM 的解析
html 文档 边加载边解析 的;网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到数据实时传递给渲染进程,渲染进程的 HTML 解析器,它会动态接收字节流,并将其解析为 DOM
2.字节流转换为 DOM 需要三个阶段
(0)字节流转 tokens ,tokens 生成节点 node,最后生成 DOM;
最关键是第一点;
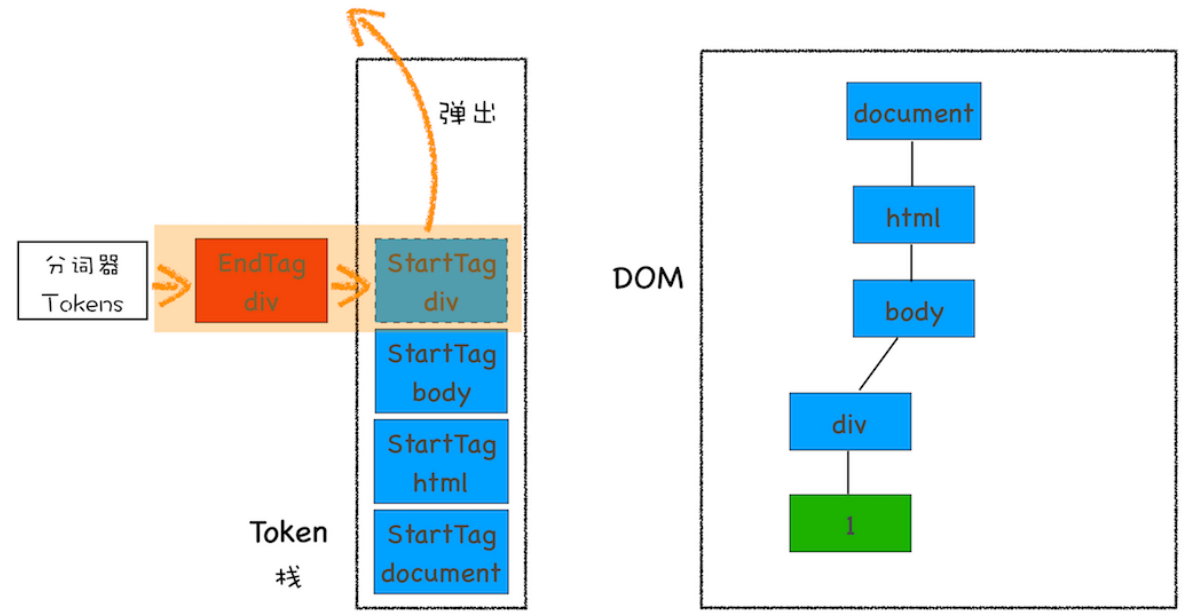
(1)通过分词器将字节流转换为 Token。
Tag Token 又分 StartTag , EndTag,文本 token;
分别对应下图的蓝、红、绿;

靠一个 栈结构 来维护;
注意,文本 Token 是不需要压入到栈
3.JS 影响
(1)script 脚本
会暂停 DOM 解析
因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构
(2)引入外部 JS 文件
会阻塞 DOM 解析,需要等待下载完成才行;
浏览器有个优化,渲染进程有个预解析线程,提前下载 JS 和 css 文件
所以不用操作 dom 的 js 文件,可以设置为异步加载, async 和 defer ,async 加载完立即执行还是会阻塞渲染,最好用 defer;
(3)JS 代码上面的 CSS 文件
因为不知道 JS 是否要处理 CSS,所以不管怎样都会等待 CSS 文件加载好;再继续执行 JS;
(4)script 放在页面底部的影响
不影响 DOM 解析,但会影响渲染;
4.CSS 加载
(1)CSS 加载
CSS 代码下面如果没有 script 代码段,就不会影响 DOMContentLoaded;
如果有 JS 代码,会等待 CSS 加载完成,会阻塞 DOM 解析;
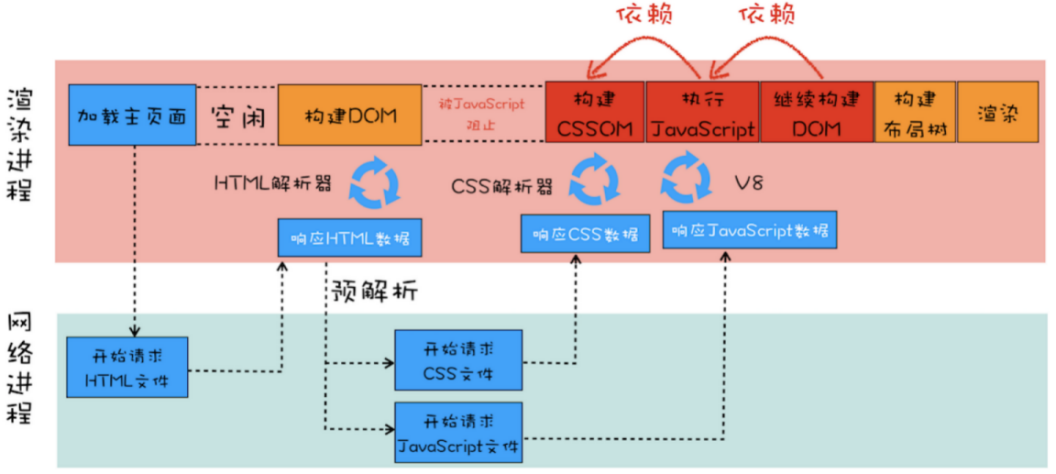
(2)含有 JavaScript 文件和 CSS 文件页面的渲染流水线
预解析器同时发出两个文件请求,不管 CSS 文件和 JavaScript 文件谁先到达,都要先等到 CSS 文件下载完成并生成 CSSOM,然后再执行 JavaScript 脚本,最后再继续构建 DOM,构建布局树,绘制页面
预解析
WebKit 和 Firefox 都进行了这项优化。在执行脚本时,其他线程会解析文档的其余部分,找出并加载需要通过网络加载的其他资源。通过这种方式,资源可以在并行连接上加载,从而提高总体速度。请注意,预解析器不会修改 DOM 树,而是将这项工作交由主解析器处理;预解析器只会解析外部资源(例如外部脚本、样式表和图片)的引用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!