DriveLM: Driving with Graph Visual Question Answering
DriveLM: Driving with Graph Visual Question Answering
https://github.com/OpenDriveLab/DriveLM
摘要
我们研究了如何将在网络规模数据上训练的视觉语言模型(VLM)集成到端到端驾驶系统中,以提高泛化能力并实现与人类用户的交互。虽然最近的方法通过单轮视觉问答(VQA)使VLM适应驾驶,但人类驾驶员在多个步骤中进行决策。从关键对象的定位开始,人类在采取行动之前估计对象交互。关键的见解是,我们提出的任务,图VQA,我们通过感知,预测和规划问答对建模图结构的推理,我们获得了一个合适的代理任务来模仿人类的推理过程。我们实例化基于nuScenes和CARLA构建的数据集(DriveLM-Data),并提出了一种基于VLM的基线方法(DriveLM-Agent),用于联合执行Graph VQA和端到端驱动。实验表明,图形VQA提供了一个简单的,原则性的框架推理驾驶场景,和DriveLM数据提供了一个具有挑战性的基准,这项任务。我们的DriveLM-Agent基准与最先进的驾驶专用架构相比,可在端到端自动驾驶方面具有竞争力。值得注意的是,当它在看不见的物体或传感器配置上进行zero-shot评估时,它的好处是明显的。我们希望这项工作可以成为一个起点,为如何将VLM应用于自动驾驶提供新的思路。为了方便未来的研究,所有的代码,数据和模型都向公众开放。
1.介绍
目前的自动驾驶(AD)堆栈仍然缺乏关键功能[8,11]。一个关键的要求是泛化,这涉及到处理看不见的场景或不熟悉的对象的能力。第二个要求涉及这些模型与人类的交互,例如欧盟法规强调了部署中的可解释性[3]。此外,与当今的AD模型不同,人类并不基于几何精确的鸟瞰图(BEV)表示进行导航[13,26,39]。相反,人类隐含地执行以对象为中心的感知,预测和规划(我们称之为P1 - 3(𝑷𝟏 - Perception 𝑷𝟐 - Prediction 𝑷𝟑 - Planning)):对关键对象进行粗略的识别和定位,然后推理它们可能的运动并将这些信息聚合成驱动动作[49,62]。
与此同时,另一个领域也在向前发展:视觉语言模型(VLM)[40,45,73,83]。这些模型有几个优点。首先,他们从互联网规模的数据中对世界有了基本的了解,这可能有助于AD规划的推广。事实上,这种推广已经通过VLM实现了更简单的机器人任务[18,85]。其次,使用语言表示作为输入和输出提供了一个与这些模型进行人性化交互的平台,不像当前方法中更常见的边界框或轨迹[14,25,41,58]。最后,VLM能够通过逻辑推理在多个步骤中做出决策[4,16,75,77,82,85]。重要的是,尽管它们在多个单独的步骤中进行推理,但VLM是端到端可区分的架构,这是自动驾驶非常需要的特征[8]。
最近的工作,使应用程序的VLM AD系统分为两类:场景级或单一对象级的视觉问题问答(VQA)。场景级VQA是指通过一个或两个支持原因来描述驾驶行为的任务,例如,“这辆车正驶入右车道,因为这样做是安全的。”[34,35]。单对象级VQA通过“什么-哪个-哪里-怎么样-为什么”(“what-which-where-how-why)形式的QA链来阐述自我车辆对单个对象的响应的理解,例如,“自我车辆停下来是因为有一个穿着白色衬衫的行人在自我车辆前面穿过十字路口,它不想撞到行人。”[47,55,59]。不幸的是,这两种范式都没有提供合适的代理任务来模仿人类的P1 - 3推理过程,人类考虑多个对象并在多个步骤中对每个对象进行推理。因此,在本文中,我们提出了一个新的任务,沿着相应的数据集和基线模型架构(图1)。

图1.DriveLM:端到端自动驾驶的新任务、数据集、指标和基线。受[8]的启发,DriveLM考虑了图视觉问答(GVQA),其中问题-答案对通过对象级别的逻辑依赖关系互连,即,对象对之间的交互,以及任务级,例如,感知→预测→规划→行为(用自然语言描述的离散化动作)→运动(连续轨迹)。我们提出了DriveLM-Data用于训练DriveLM-Agent,这是GVQA的基线。我们验证其有效性,使用DriveLM-WARNING具有挑战性的设置,需要zero-shot泛化。
任务。图视觉问答(Graph Visual Question Question Questioning,GVQA)是将P1?3推理公式化为一系列有向图中的问答对(Question-answer Pair,QA)。它与上述AD的VQA任务的主要区别是QA之间的逻辑依赖关系的可用性,这些依赖关系可用于指导回答过程。GVQA还包括有关行为和运动规划的问题,以及专用指标(详见第2节)。
数据集。DriveLM-nuScenes和DriveLM-CARLA由标注的QA组成,排列在一个图形中,通过逻辑推理将图像与驾驶行为联系起来。与现有的基准相比,它们在每帧中提供了更多的文本注释(图2和表1)。我们将这些训练数据集与具有挑战性的测试数据配对,以评估零样本泛化。
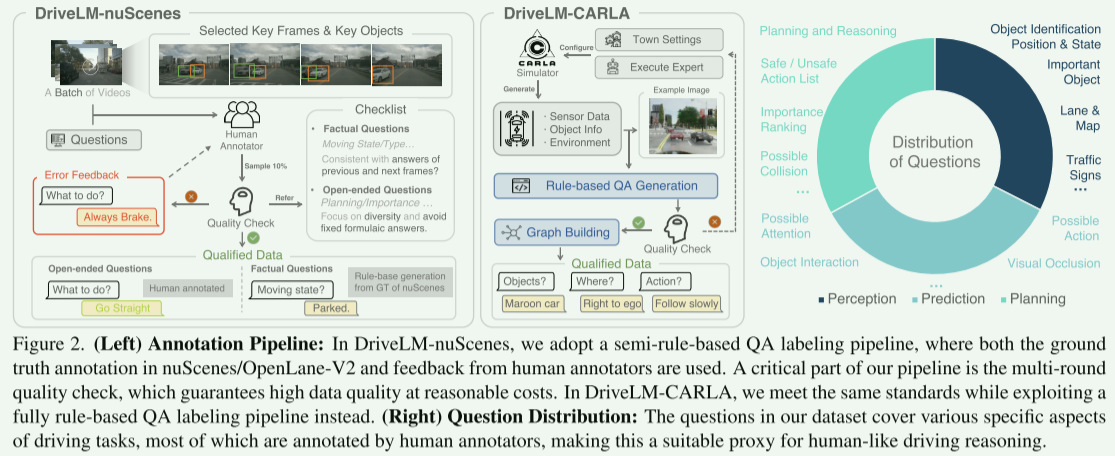
图2.(左)注释管线:在DriveLM-nuScenes中,我们采用了基于半规则的QA标记管道,其中使用了nuScenes/OpenLane-V2中的地面实况注释和来自人类注释者的反馈。我们的管道的一个关键部分是多轮质量检查,它以合理的成本保证高数据质量。在DriveLM-CARLA中,我们满足相同的标准,同时利用完全基于规则的QA标签管道。(右)问题分发:我们数据集中的问题涵盖了驾驶任务的各个特定方面,其中大部分都由人类注释者进行注释,使其成为类似人类驾驶推理的合适代理。
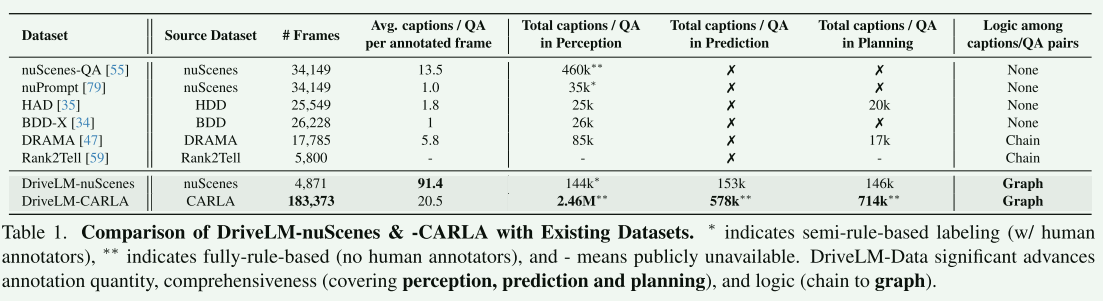
表1.DriveLM-nuScenes和-CARLA与现有数据集的比较。表示半基于规则的标注(有人类注释者),DriveLM-Data显著提高了注释的数量、全面性(涵盖感知、预测和规划)和逻辑性(从链到图)。
模型。DriveLM-Agent采用可应用于任何一般VLM的轨迹标记器[40,45,53,83],再加上一个图形提示方案,该方案将逻辑依赖关系建模为VLM的上下文输入。结果是一种简单、优雅的方法,可以有效地将VLM重新用于端到端AD(第3节)。
我们的实验提供了令人鼓舞的结果。我们发现,GVQA的DriveLM是一个具有挑战性的任务,目前的方法获得中等分数和更好的建模的逻辑依赖关系可能是必要的,以实现强大的QA性能。即便如此,在开环规划设置中进行测试时,DriveLM-Agent已经与最先进的驾驶特定模型[26]竞争,尽管其任务不可知和通用架构。此外,采用图形结构可以提高零样本泛化能力,使DriveLM-Agent能够在仅对nuScenes [5]数据进行训练后,正确处理在Waymo数据集[63]上训练或部署期间未见过的新对象。从这些结果来看,我们相信改进GVQA对于构建具有强大泛化能力的自动驾驶代理具有巨大的潜力。
2.DriveLM:任务、数据、数据库(DriveLM: Task, Data, Metrics)
人类驾驶员通常将他们的决策过程分解为不同的阶段,这些阶段遵循逻辑进程,包括关键对象的识别和定位,他们未来可能的行动和互动,以及基于所有这些信息的自我规划[22,46]。这启发我们提出GVQA作为DriveLM的关键成分,它作为一个合适的代理任务来模仿人类的推理过程。在本节中,我们说明了GVQA任务的制定(第2.1节),介绍了DriveLM-Data(第2.2节),以使用突出的驾驶数据集来验证GVQA的实例化,并概述了用于评估的DriveLM-Data(第2.3节)。
2.1. DriveLM-Task: GVQA
我们将图像帧的所有问答对(QA)组织成一个图形结构,表示为G=(V,E)。V代表顶点的集合,其中每个顶点表示与场景中的一个或多个关键对象相关联的QA对v=(q,a)。GVQA和普通VQA的关键区别在于GVQA中的QA具有逻辑依赖性,我们将其表示为顶点之间的边。E ∈V×V,是一组有向边,其中每条边e=(vp,vc)连接父QA和子QA。我们制定的边缘集E通过合并两个维度:对象级和任务级的边缘。
在对象层次上,我们构造逻辑边e∈E来表示不同对象之间的交互影响。例如,轿车的规划QA节点受到图1(中心)的图示中的行人的感知QA节点的影响。在任务级,我们建立逻辑边e∈E来捕获不同推理阶段的逻辑链:
·感知(P1):识别、描述和定位当前场景中的关键对象。
·预测(P2):基于感知结果估计关键对象的可能动作/交互。
·规划(P3):自我车辆的可能的安全动作。
·行为(B):驾驶决策的分类。
·运动(M):自我车辆未来轨迹的航点。
感知、预测和规划(P1 - 3)的概念类似于端到端AD [8]中的概念,而运动和行为的概念则基于自我车辆的未来轨迹。具体地,我们将运动M定义为自我车辆未来轨迹,其是鸟瞰图(BEV)中具有坐标(x,y)的N个点的集合,表示为M = {(x 0,y 0),(x1,y1),.,(xN,yN)}。每个点是未来位置和当前位置之间的偏移量,偏移量为固定时间间隔。然后,在每个时间间隔的x,y的距离计算为:
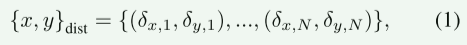
其中,δx,i = xi ? xi?1和δy,i = yi ? yi?1,其中i =1, 2, . . . ,N.行为表征的目标是充当从P1?3到M的接口。为了获得行为表示,我们将xdist和ydist的平均值映射到预定义的bin之一,其中每个bin对应于速度或转向的类别。它们分别表示为Bsp和Bst。在这项工作中,我们考虑5个bins:

其中下标中的数字表示强度。轨迹的速度和转向类别的组合形成其行为类别为B =(Bsp,Bst)。虽然我们使用一个简单的定义B作为一个起点,驾驶与VLMs的研究,我们注意到,我们注意到,我们的公式支持结合更抽象的行为,例如车道变换或超车。
2.2. DriveLM-Data
为了使用第2.1节中定义的图结构提供全面准确的QA,我们引入了DriveLM-nuScenes和DriveLM-CARLA。由于nuScenes和CARLA之间存在显著差异,因此这些数据集的收集方法和统计数据不同。
DriveLM-nuScenes.我们将注释过程分为三个步骤:
1、从视频片段中选择关键帧,
2、在这些关键帧中选择关键对象,
3、然后为这些关键对象注释帧级P1 - 3 QAs。
一部分感知QA是从nuScenes [5]和OpenLane-V2 [70]地面实况生成的,而其余的QA是手动注释的。当我们手动注释DriveLMnuScenes中的绝大多数数据时,质量对这部分数据尤为重要。在标注时,我们会进行多轮严格的质量检查。在每一轮中,我们将数据分类到不同的批次中,并检查每个批次中10%的数据。如果这10%的手工标注数据的合格率没有达到预期,我们会要求标注者重新标注该批次中的所有数据。
在图2(左)中,我们展示了QA注释管道的一个示例,其中所有问题都根据我们的标准进行质量检查。
因此,DriveLM-nuScenes以其更大的规模、更全面的内容和更复杂的结构从先前提出的数据集中脱颖而出(见表1)。
这些QA涵盖了驾驶过程的各个方面,从感知和预测到规划,提供了对自动驾驶场景的全面理解,如图2(右)所示。
DriveLM-CARLA。我们在Leaderboard 2.0框架[17]中使用CARLA 0.9.14与特权的基于规则的专家[30]收集数据。我们在城市,住宅和农村地区设置了一系列路线,并在这些路线上执行专家。在这个过程中,我们收集必要的传感器数据,根据有关对象和场景的特权信息生成相关的QA,并组织逻辑关系将这一系列QA连接到一个图中。我们以20 FPS的速度生成数据和标签。这个过程具有简单的可扩展性,因为我们只需要在CARLA中定义路由和场景设置,后续步骤可以自动执行。基于规则的注释流水线如图2(左)所示。包括370万个QA,我们的DriveLM-CARLA在现有基准测试中脱颖而出,成为最大的文本内容驱动语言基准测试,如表1所示。
2.3. DriveLM-Metrics
为了评估GVQA,DriveLM-Risk由三个组件组成,分别用于评估运动M、行为B和P1?3。
- 为了测量运动阶段的性能,我们使用nuScenes和Waymo基准测试的标准指标:平均和最终位移误差(ADE,FDE)以及预测轨迹上的碰撞率,遵循UniAD [26]。
- 我们评估行为预测的分类精度,沿着分解的整体精度到其转向和速度组件。
- 最后,我们使用两个指标来衡量P1-3的性能。
SPICE [2]是VQA和图像字幕中常用的度量标准,它计算预测文本的结构相似度,而忽略语义。同时,我们使用GPT Score来衡量答案的语义一致性,并补充SPICE度量。具体来说,the question, the ground truth answer, the predicted answer, 询问答案的分数的提示被发送到ChatGPT3.5 [50,51]。我们解析返回的文本以获得分数,分数越高表示语义准确性越好。
3.DriveLM-Agent: A GVQA Baseline
在本节中,我们将介绍DriveLM-Agent,这是第2节中详细介绍的GVQA任务的基线方法。DriveLMAgent建立在通用的视觉语言模型之上,因此可以利用在预训练过程中获得的基础知识。我们的总体目标是通过VQA的不同阶段(P1,P2,P3,B)将图像转换为所需的自我车辆运动(M)。为此,我们选择BLIP-2 [40]作为我们的基础VLM,因为它的架构简单,微调灵活,但所提出的方法可以不可知地应用于其他VLM。

图3.DriveLM-代理架构。给定场景图像,DriveLM-Agent执行上下文提示,以建模五个QA阶段之间的逻辑依赖关系。上下文是使用前面的QA构建的,可以有一个或多个源。
如图3所示,DriveLM-Agent可以分解为几个阶段:
(1)P1 - 3,即,感知、预测、计划是理解场景和推理其结构的基础层。
(2)行为阶段将来自P1 - 3的关键信息聚合到语言空间中对所需驾驶行为的描述中。
(3)最后,运动阶段将行为转换为可执行的驾驶轨迹。为了实现每个链接的QA之间的逻辑依赖关系,我们建议在GVQA图中的连接节点之间使用上下文。我们在下文中进一步阐述这一想法。
3.1. Prompting with Context
像[12,54]中那样直接将图像转换为运动是非常具有挑战性的。出于人类倾向于执行多步推理过程的动机,我们建议使用类似的策略用于基于VLM的驾驶。通过这样做,我们方便检索存储在LLM中的知识,并提高可解释性。
更准确地说,该模型被设计为使用推理过程中前面步骤的答案作为以下问题的上下文。对于每条边e =(vp,vc)∈ E,我们将来自父节点vp的QA附加到当前节点vc的问题,并带有前缀“Context:“。上下文还可以包含来自多个先前节点的QA,在这种情况下,我们将所有QA连接到一个上下文序列。值得注意的是,上下文只是GVQA中制定逻辑依赖的一种可能实现,我们选择它是因为它的简单性。通过该方案,我们根据图建立的逻辑依赖关系向前传递相关信息。
请注意,推理期间图的大小和结构是算法的设计选择,可以根据任务或可用的计算预算进行调整。我们使用此属性在所有可用的QA上进行训练,但在特定的子图上执行推理,其中问题使用统计学进行采样。详情请参阅补充材料。
3.2. Context Aggregation through Behavior
驾驶包含了各种各样的潜在情况,需要适当的反应。然而,尽管这些情况的多样性,有趣的是,几乎所有的事件都涉及可以离散成一组行为的决策。例如,适当地施加制动可以解决各种情况,诸如红灯信号、停车标志或车辆前方存在物体。我们行为阶段的重点是生成这样的行为:用自然语言表达车辆的预期运动。在我们的方法中,行为是对观察到的未来车辆运动的文本描述,并且它也可以表示为类别(Bsp,Bst),该类别被划分为转向和速度的分量(如第2.1节所述)。这种描述有效地充当了一个反射步骤,其中模型从图中提取和总结所有关键信息。为此,我们建议使用所有可能的上下文来源来预测行为,即,P1 - 3中的所有QA。我们根据经验观察到,具有反射行为步骤对于使用VLM驾驶至关重要,并且我们使用所有可能的上下文源的设计选择优于仅使用P3的简单方法。
3.3. Trajectory Tokenization for Motion(运动轨迹标记化)
由于使用通用VLM输出细粒度数值结果并非易事,RT-2 [85]基于专门的轨迹标记化模块处理机器人动作。我们使用这种方法,使DriveLM代理作为输入的图像和行为描述和输出轨迹。具体来说,我们根据列车集轨迹的统计数据,将路点的坐标经验性地划分为256个区间。我们在BLIP-2语言tokenizer中重新定义了token,为每个bin建立了token,并在这个重新定义的词汇表上微调了VLM。为了简单起见,我们使用相同的VLM架构(BLIP-2)来执行此任务,但具有独立的LoRA权重,并在仅由该运动阶段的QA组成的数据集上进行训练。因此,可以使用轻量级LLM [56]或接受命令作为输入的驾驶专用架构[25,80]来执行此功能。
4.实验
在本节中,我们将展示我们的实验结果,旨在解决以下研究问题:
(1)如何有效地将VLM重新用于端到端自动驾驶?
(2)当(a)使用不可见的传感器设置进行评估时;以及(B)在训练期间不可见的物体上进行评估时,用于驾驶的VLM是否可以推广?
(3)VLM通过GVQA进行感知、预测和规划的效果如何?
Setup.我们现在简要概述我们实验中使用的两种设置的关键实施细节(补充材料中提供了更多细节)。所有微调都是通过LoRA实现的[24]。在DriveLM-nuScenes上,我们在火车分裂上微调BLIP-2 10个epoch。每个GPU的批量大小为2,整个训练过程大约持续7个小时,使用8个V100 GPU。我们在DriveLM-CARLA的1/20时间子采样训练分裂上训练BLIP-2 6个时期。这在4个A100 GPU上需要6个小时。
4.1. VLMs for End-to-End Driving
在我们的第一个实验中,我们的目标是评估VLM在DriveLM-nuScenes上执行开环规划的能力。特别是,我们调查的背景下提供的行为和运动阶段的影响。给定传感器数据(在VLM方法的情况下,文本输入),模型需要以航路点的形式预测自我车辆的未来轨迹。
基线。作为任务难度的参考,我们提供了一个简单的Command Mean基线。nuScenes中的每一帧都与3个命令之一相关联,“左转”,“右转”或“直行”。我们输出训练集中命令与当前测试帧命令匹配的所有轨迹的平均值。此外,我们将我们的方法与当前最先进的nuScenes,UniAD [26]进行了比较。除了需要视频输入的作者发布的检查点之外,我们还训练了单帧版本(‘UniAD-Single’),以便与我们的单帧VLM进行公平比较。最后,BLIP-RT-2表示BLIP 2 [40]在DriveLM-Data上进行微调,仅针对运动任务使用第3.3节中描述的轨迹标记化方案。当使用与DriveLM-Agent相同的网络架构但没有上下文输入或VQA训练数据时,这可以作为性能指标。
DriveLM-Agent。我们考虑DriveLMAgent的3个变体,将我们提出的步骤更改:
(1)预测行为然后运动的2阶段版本(如第2.1节所述),但没有任何P1?3上下文用于行为预测(“无”);
(2)构建P1?3图的“链”版本,但仅将最终节点(P3)传递到行为阶段;
(3)使用P1 - 3中的所有QA作为B的上下文的完整模型(“Graph”)。
**结果.**我们在表2中显示了以上列出的方法的结果。在基线中,BLIP-RT-2无法匹配UniAD-Single(尽管两种方法相对于命令平均值表现良好)。这表明,没有任何推理的单阶段方法无法与nuScenes上的现有技术竞争。然而,拟议的DriveLM-Agent预测行为作为运动的中间步骤,提供了显着的性能提升,超过了UniAD-Single。这表明,在适当的激励下,VLM在端到端驱动方面具有惊人的竞争力。有趣的是,在表2的不涉及泛化的实验设置中,DriveLMAgent的链和图版本没有提供任何优于没有上下文的进一步优势。此外,与基于特权视频的UniAD模型相比,单帧VLM不足,这表明具有视频输入的VLM可能是此任务所必需的。
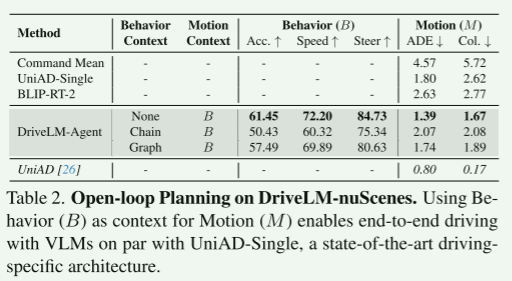
表2.DriveLM-nuScenes上的开环规划。使用行为(B)作为运动(M)的上下文,可以实现与UniAD-Single(一种最先进的驱动专用架构)相当的VLM端到端驱动。
4.2. Generalization Across Sensor Configurations
作为评估第4.1节中模型的更具挑战性的设置,我们现在将它们应用于一个新的领域:Waymo数据集[63]。Waymo的传感器设置不包括后置摄像头,因此我们从UniAD-Single中删除了此输入。VLM方法仅使用前视图,不需要任何调整。
**结果.**如表3所示,UniAD-Single不能很好地适配新的传感器配置,性能低于BLIP-RT-2。DriveLM-Agent的多阶段方法提供了进一步的改进。特别是,速度预测的准确性从没有上下文的43.90上升到了完整图表的54.29。另一方面,链式方法没有提供足够的有用信息,速度精度仅为41.28。

表3.跨传感器网络的零样本化。在DriveLM-nuScenes上训练后,Waymo瓦尔集的1 k个随机采样帧的结果。DriveLM-Agent的性能优于UniAD-Single,并受益于图形上下文。
我们在图4中展示了nuScenes和Waymo上的DriveLM-Agent的定性结果。该模型通常提供直观的答案,但有一些例外(例如,在DriveLM-nuScenes上规划,在Waymo上感知)。这显示了GVQA对交互式驾驶系统的实用性。此外,在Waymo上,我们看到了有意义的预测和规划答案,尽管感知并不完美。有关更多可视化,请参阅补充材料。

图4.DriveLM-Agent的定性结果。(左)DriveLM-nuScenes瓦尔帧,(右)Waymo瓦尔帧。我们展示了问题(Q)、上下文(C)和预测的答案(A)。DriveLM-Agent的输出很容易为人类用户解释。
4.3. Generalization to Unseen Objects
接下来,我们评估零样本泛化到新的对象。DriveLM-CARLA在训练或验证分割中没有任何行人的情况下收集。我们现在生成一个名为DriveLM-CARLA-ped的新测试集,它只包含场景中存在行人的帧。正确的行为是为行人停车。
基线。在本实验中,我们将DriveLMAgent与CARLA的最新技术TransFuser++ [30]进行了比较。与DriveLM-Agent相比,它使用更大的输入图像,额外的LiDAR传感器和几个驾驶特定的注释(深度,语义,3D边界框,HD地图)。然而,由于这些特定于任务的输入和输出,TransFuser++只能在基础DriveLM-CARLA数据集上进行训练,无法在训练过程中纳入一般的计算机视觉数据,这使得泛化更具挑战性。
DriveLM-Agent。利用VLM更通用的架构,我们在DriveLM-Agent的训练过程中包括来自COCO [44]和GQA [28]的样本沿着DriveLM-CARLA。我们比较了几个版本:(1)我们研究了在推理过程中增加一个新的P1问题,“有一个人过马路吗?”(‘+行人QA’)。(2)作为上界,我们在推理过程中直接将地面真值P1?3图输入模型,而不是模型的预测。详情请参阅补充材料。

表4.DriveLM-CARLA中的泛化。所有方法在具有新颖行人对象的DriveLM-CARLA-ped上表现不佳,但DriveLM-Agent可以通过在其GVQA图中包括特定于行人的问题来显着改进。
结果。我们在表4中展示了我们的发现。我们观察到,TransFuser++在DriveLM-CARLA-ped上相对于DriveLM-CARLA比较吃力,准确度从70.19下降到8.72。DriveLM-Agent经历了类似的下降,从59.63下降到4.59。然而,添加行人QA显著提高了泛化设置的性能,达到27.04,尽管在常规场景中的准确性略有下降。这主要是由于VLM无法正确检测所有行人。这表明最近发布的VLM [21,53]的大性能增益可以在驾驶领域支持更好的泛化能力。此外,当行人QA在特权设置中提供时,假设可以访问图中每个问题的完美上下文,DriveLM-Agent在行人帧上获得了近乎完美的分数(20.92 → 92.35)注意,DriveLM-CARLA-ped只包含横穿直路的行人,因此所有模型在转向类(始终是直路)上都获得了100%的准确性。
4.4. Performance for P1?3 via GVQA
在最后一个实验中,我们为GVQA的P1 - 3阶段建立了基线结果,研究了背景的影响。我们使用两个VLM,现成的BLIP-2 [40]模型(在DriveLM上没有微调),以及拟议的DriveLM代理。
基线。我们考虑无上下文的下限(“None”),这对应于与标准VQA(图像和问题输入,答案输出)相同设置的训练和评估。作为每个架构的上限,我们执行GVQA,但在测试时将地面实况(“GT”)上下文输入到模型中,而不是其自己的先前预测。

表5.基线P1?3结果。DriveLM-Agent的性能优于BLIP-2,但无法从上下文的可用性中获益。
**结果.**我们的结果总结在表5中。首先,我们观察到DriveLM-nuScenes对于两个模型来说都更具挑战性,正如在所有上下文设置中相对于DriveLM-CARLA,该数据集上的分数较低所示。这可能是由于DriveLM-nuScenes获得的人类答案的多样性更高,而不是CARLA中基于规则的生成。在这两个数据集上,我们观察到在DriveLM上进行微调的DriveLM-Agent的性能明显优于以零触发方式应用的BLIP-2。我们还观察到SPICE和GPT评分指标不一致,特别是对于BLIP-2。有趣的是,在DriveLM-CARLA上,与无上下文版本相比,具有GT上下文的BLIP-2在SPICE方面获得了超过25分,同时GPT得分略有下降。这表明,目前的VLM能够模仿所提供的上下文的句子结构和风格,但在执行逻辑推理方面面临挑战。总的来说,我们得出结论,DriveLM-Agent可以在没有上下文的情况下在P1 - 3问题回答上获得合理的基线性能。然而,为了更好地利用GVQA中的逻辑依赖关系,可能需要超出朴素级联的专门架构或提示方案。
5.相关工作
自动驾驶中的泛化。对极端情况的“长尾”的推广不足对AD系统造成了重大的安全问题[8,65,66]。为了解决这个问题,以前的研究主要致力于数据驱动的方法[1,6,23,64,71]。例如,EQUICSim [64]通过模拟为安全关键案例收集更多数据。一个新兴的方向涉及利用语义信息来监督对不可见或异常对象的检测[19,72]。这些努力缓解了普遍性不足的问题。即便如此,AD系统的零触发性能目前并不令人满意。在本文中,我们提出了一种更好的泛化方法:使用图VQA学习逻辑推理。
Embodied Planning with LLMs。最近的工作致力于利用LLM [20,36,68]强大的推理和泛化能力来实现AI系统[18,27,29,33,42,57,85]。PaLM-E [18]训练LLM执行各种具体任务,包括顺序机器人操作规划。CaP [42]提供了一个以机器人为中心的语言模型生成程序的公式,该程序在真实的系统上执行。RT-2 [85]将机器人动作表示为语言令牌,训练视觉语言模型以输出机器人策略。这些方法展示了LLM在具体规划任务中的能力,启发我们将其应用于解决AD中泛化的当前缺点,这是远远不够的。
Language-grounded Driving。几种并发方法试图将多模态输入纳入AD任务的LLM [7,32,48,60,72,76,81]。具体来说,GPTDriver [48]和LLM-Driver [7]将感知到的场景状态编码为提示,依靠LLM来制定合理的计划。DriveGPT 4 [81]将原始传感器数据投影到令牌中,并利用LLM进行控制信号和解释的端到端预测。尽管有这些初步的尝试,但通过LLM解决AD泛化的潜力尚未开发。我们的工作将VLM与DriveLM的图结构QA培训相结合。这使我们能够显示零发射端到端规划的好处,这是这些并行研究所没有证明的。
讨论
尽管DriveLM具有很好的推广前景,但这项工作存在一些局限性。
驾驶专用输入。DriveLM-Agent直接应用VLM的视觉模块,将低分辨率的前视图帧作为其输入。目前,无法处理LiDAR等驾驶专用传感器。这导致我们的模型缺乏时间信息和360度场景理解。扩展DriveLM-Agent以从多个视图观察图像是简单的,因为图形公式允许不同节点的不同输入帧。我们把它留给未来的工作来探索多视图和多帧输入的选项。
闭环规划。我们的方法是目前评估下的开环方案。在这种情况下,将自我车辆的状态作为输入可以显著增强度量,但其有效性可能无法很好地转化为真实的世界,因此我们只考虑不这样做的方法。将我们的工作扩展到一个闭环环境,在训练时间和计算成本方面有一个合理的预算,这是一个很有前途的探索方向。随着CARLA的使用,我们提供了一个很有前途的基础,更多的研究方向的闭环规划与VLMs。
效率限制。继承了LLM的缺点,我们的模型需要很长的推理时间,特别是当我们需要基于图结构进行多轮预测时(大约比UniAD慢4倍)。这可能会影响实际执行。探索如何进行模型量化、提炼和剪枝是一个值得研究的方向。
**结论。**我们展示了如何利用VLM作为端到端的自动驾驶代理,并在特定任务的驾驶堆栈上改进泛化。为此,我们提出了图VQA的任务以及新的数据集和指标。配备了这些工具,我们建立了一个基线的方法,有一个简单的架构,并取得了可喜的成果。我们相信,这种方法可以通过使其直接受益于更好的VLM来加速自动驾驶领域的进展。
更广泛的影响。我们的目标是在自动驾驶方面取得进展,如果成功,将产生深远的影响。我们认识到,通过将VLM引入这一领域,我们接受了它们的伦理影响,例如幻觉和高资源使用。然而,通过改善人类与自动驾驶系统之间的互动,我们可以建立对该技术的信心。这可能会加速其接受,并导致长期更安全的运输。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jmeter基础和概念
- vue3+vite+three加载glb模型文件
- 【Verilog】期末复习——简要说明仿真时阻塞赋值和非阻塞赋值的区别。always语句和initial语句的关键区别是什么?能否相互嵌套?
- JavaScript初级知识(4)
- mysql综合实验
- 前端基础location的使用
- 【Java 并发】ThreadPool
- 卡尔曼滤波算法
- 前端Web系统架构设计
- 弹性各向异性后处理软件 ElATools(二)