大数据毕业设计:python美食推荐系统 协同过滤推荐算法 可视化 Django框架(源码)?
发布时间:2024年01月19日
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业?。🍅
1、项目介绍
技术栈:
Python语言、Django框架、协同过滤推荐算法、Echarts可视化、HTML
美食推荐系统是基于协同过滤推荐算法的应用程序,旨在为用户提供个性化的美食推荐。系统使用Python语言和Django框架进行开发,并结合Echarts可视化库和HTML技术,实现了用户界面和推荐结果的展示。
该系统的核心是协同过滤推荐算法。该算法基于用户的历史行为和其他用户的行为进行分析,通过计算用户之间的相似度,为用户推荐他可能喜欢的美食。具体而言,系统会根据用户的历史评分数据和浏览记录,找到与用户兴趣相似的其他用户,然后根据这些用户的评分数据,推荐给用户他们喜欢的美食。
2、项目界面
(1)美食数据分析
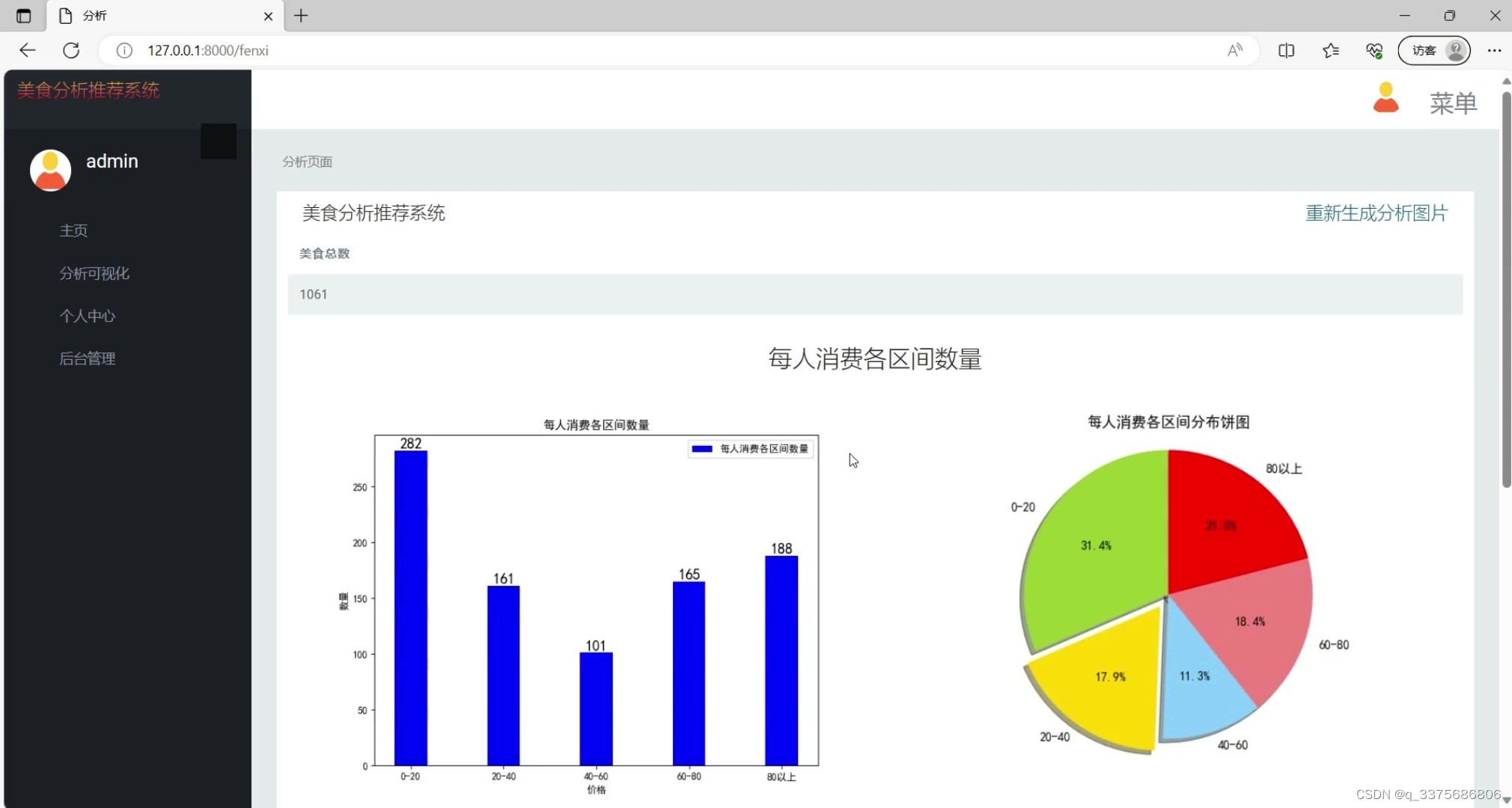
(2)美食评分区间分析
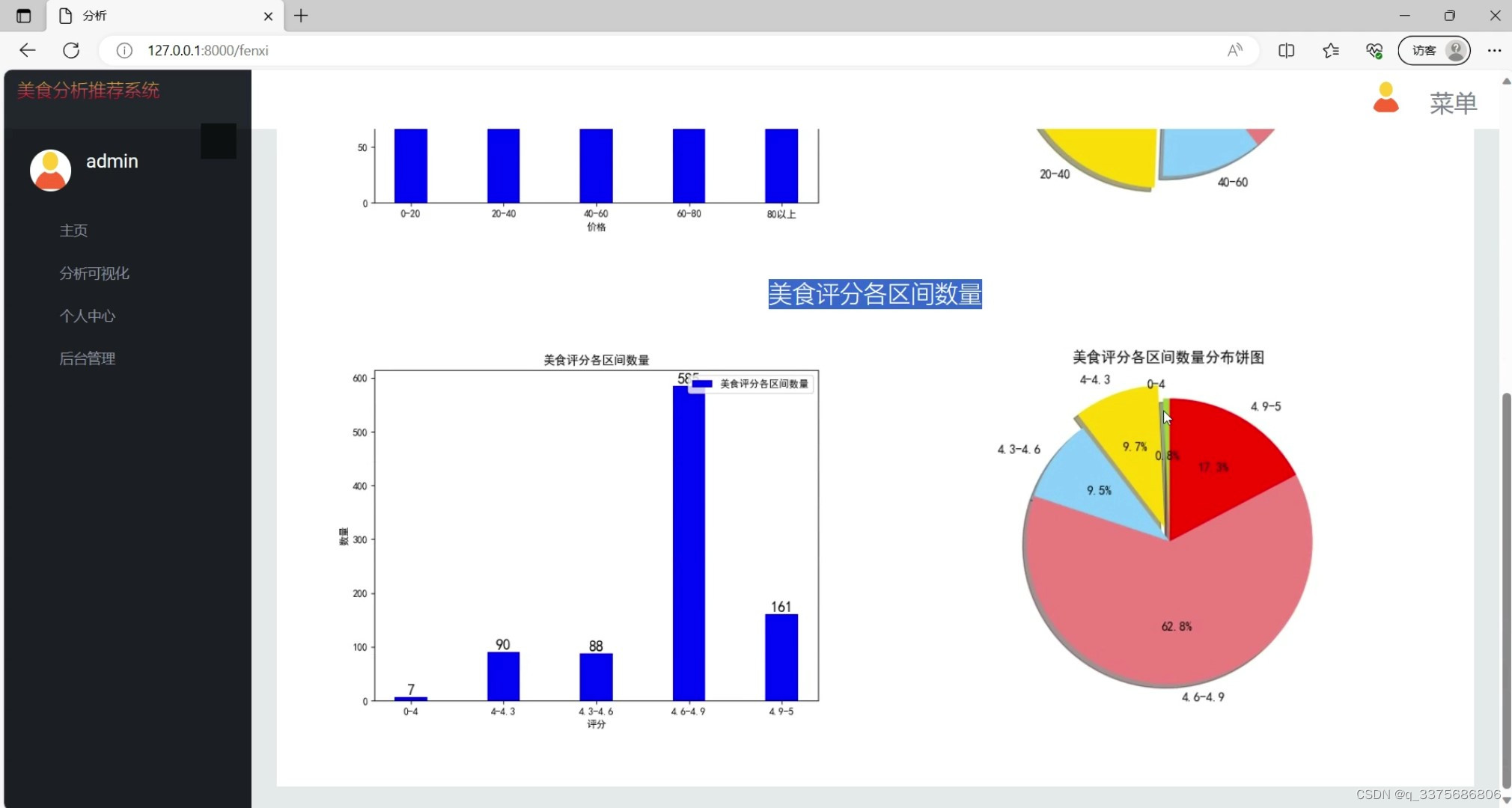
(3)美食数据
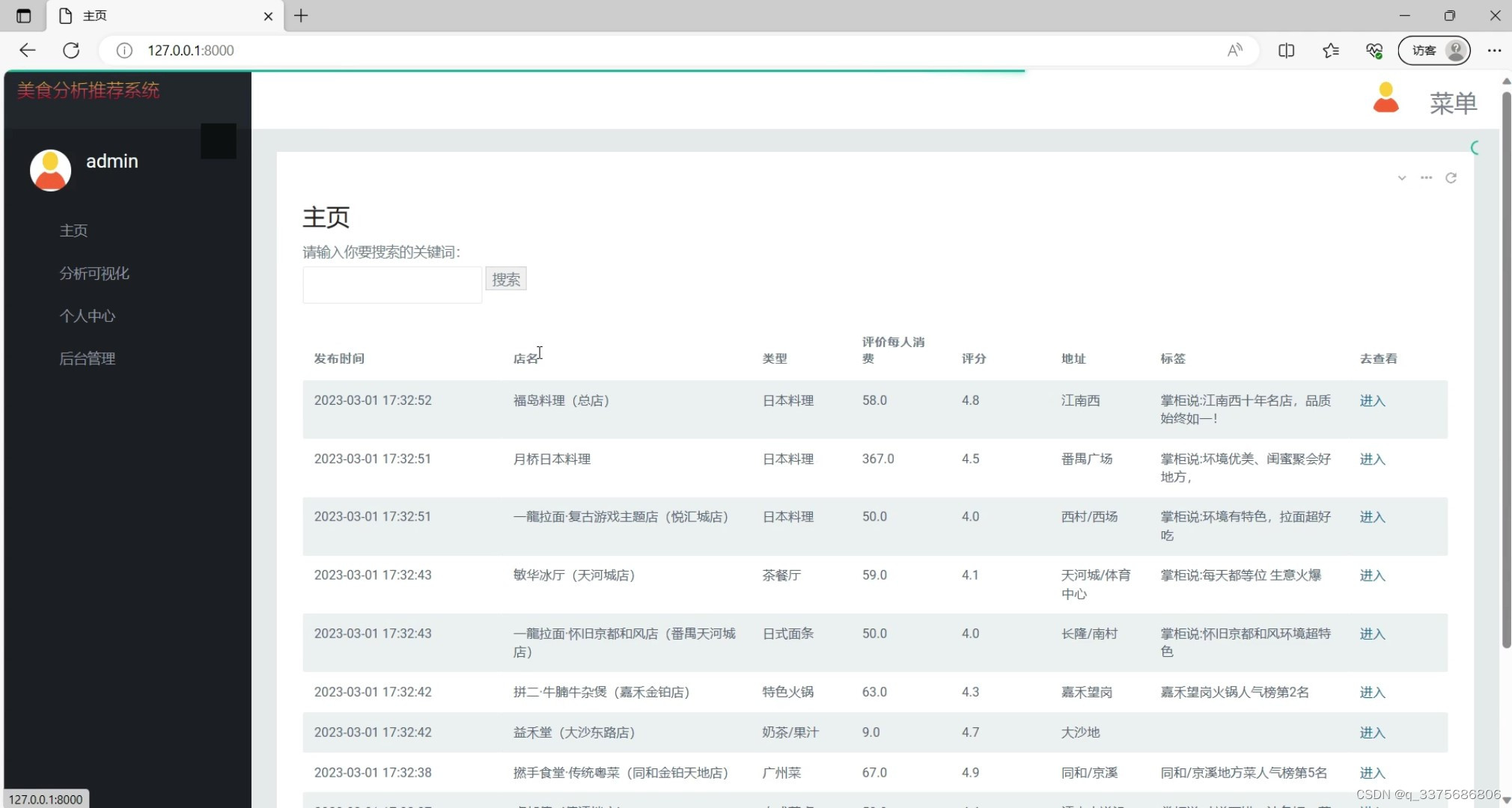
(4)美食推荐
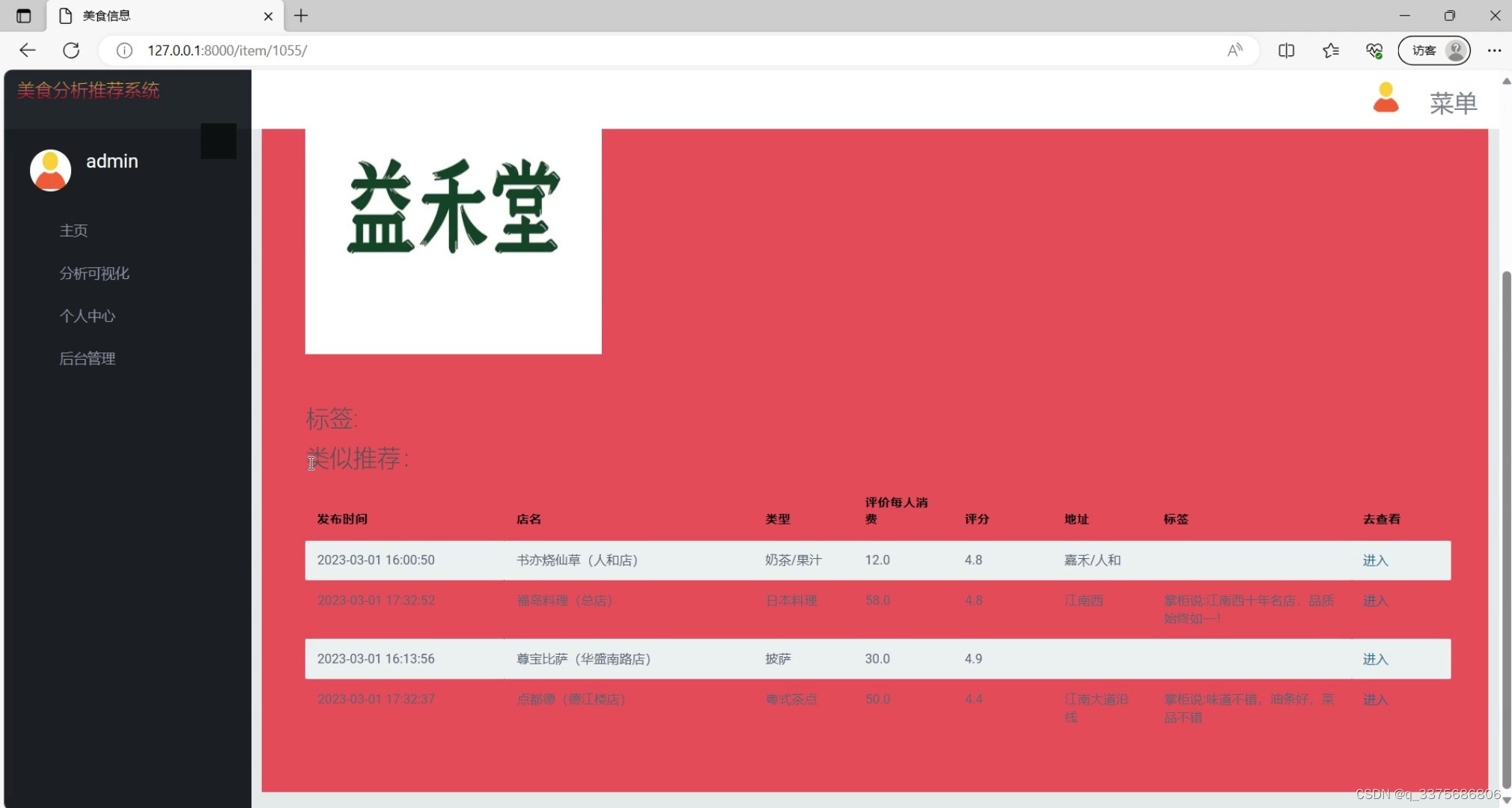
(5)美食推荐2
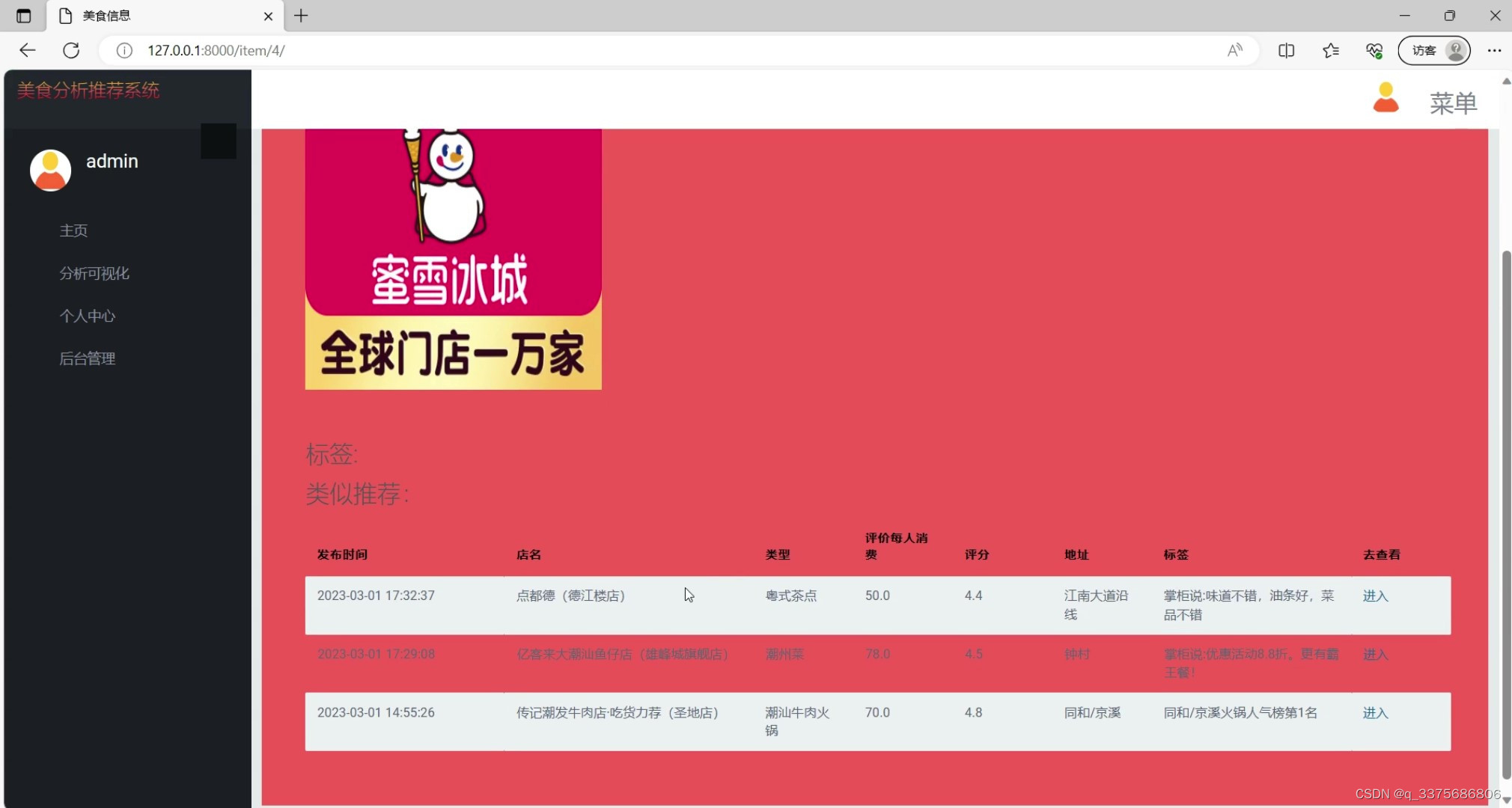
(6)后台数据管理
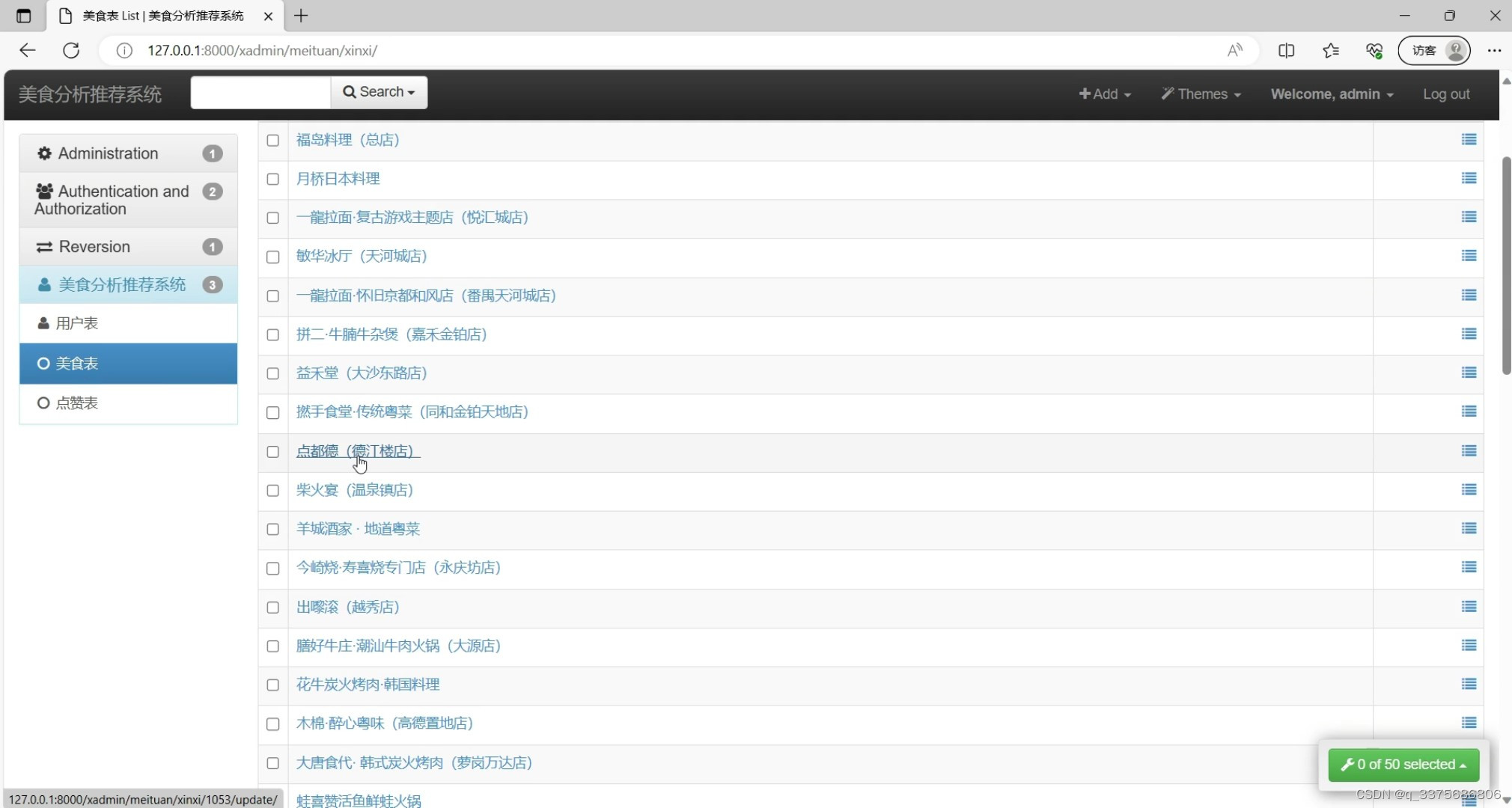
3、项目说明
美食推荐系统是基于协同过滤推荐算法的应用程序,旨在为用户提供个性化的美食推荐。系统使用Python语言和Django框架进行开发,并结合Echarts可视化库和HTML技术,实现了用户界面和推荐结果的展示。
该系统的核心是协同过滤推荐算法。该算法基于用户的历史行为和其他用户的行为进行分析,通过计算用户之间的相似度,为用户推荐他可能喜欢的美食。具体而言,系统会根据用户的历史评分数据和浏览记录,找到与用户兴趣相似的其他用户,然后根据这些用户的评分数据,推荐给用户他们喜欢的美食。
在系统的实现过程中,使用了Python语言和Django框架来构建后端逻辑和用户界面。Python是一种简洁、易学且功能强大的编程语言,适合用于开发推荐系统。Django框架是一个高效、灵活的Web开发框架,可以帮助开发者快速构建Web应用程序。
为了更好地展示推荐结果,系统使用了Echarts可视化库。Echarts是一款基于JavaScript的可视化库,可以轻松地创建各种交互式图表和数据展示效果。通过使用Echarts,系统可以将推荐结果以图表的形式展示给用户,提供更直观、易于理解的推荐结果。
最后,为了实现用户界面,系统采用了HTML技术。HTML是一种用于构建Web页面的标记语言,可以定义页面的结构和内容。通过使用HTML,系统可以创建用户友好的界面,使用户可以方便地浏览和使用美食推荐系统。
综上所述,该美食推荐系统使用了Python语言、Django框架、协同过滤推荐算法、Echarts可视化和HTML技术,为用户提供个性化的美食推荐,并通过图表展示推荐结果,提升用户体验。
4、核心代码
# coding=utf-8
from math import sqrt,pow
import operator
import random
class UserCf():
def __init__(self,data):
self.data=data
def getItems(self,username1,username2):
return self.data[username1],self.data[username2]
def pearson(self,user1,user2):
sumXY=0.0;
n=0;
sumX=0.0;
sumY=0.0;
sumX2=0.0;
sumY2=0.0;
try:
for movie1,score1 in user1.items():
if movie1 in user2.keys():
n+=1;
sumXY+=score1*user2[movie1]
sumX+=score1;
sumY+=user2[movie1]
sumX2+=pow(score1,2)
sumY2+=pow(user2[movie1],2)
molecule=sumXY-(sumX*sumY)/n;
denominator=sqrt((sumX2-pow(sumX,2)/n)*(sumY2-pow(sumY,2)/n))
r=molecule/denominator
except Exception as e:
print("异常信息:",e)
return None
return r
def test1(self,user1,user2):
# 取出两位用户评论过的美食和评分
user1_data = self.data[user1]
user2_data = self.data[user2]
distance = 0
common = {}
# 找到两位用户都评论过的美食
for key in user1_data.keys():
if key in user2_data.keys():
common[key] = 1
if len(common) == 0:
return 0 # 如果没有共同评论过的美食,则返回0
n = len(common) # 共同美食数目
print(n, common)
##计算评分和
sum1 = sum([float(user1_data[movie]) for movie in common])
print(sum1)
sum2 = sum([float(user2_data[movie]) for movie in common])
print(sum2)
##计算评分平方和
sum1Sq = sum([pow(float(user1_data[movie]), 2) for movie in common])
sum2Sq = sum([pow(float(user2_data[movie]), 2) for movie in common])
##计算乘积和
PSum = sum([float(user1_data[it]) * float(user2_data[it]) for it in common])
print(PSum)
##计算相关系数
num = PSum - (sum1 * sum2 / n)
print(num)
den = sqrt((sum1Sq - pow(sum1, 2) / n) * (sum2Sq - pow(sum2, 2) / n))
if den == 0:
return 0
r = num / den
print(111111)
print(r)
return r
def nearstUser(self,username,n=1):
distances={};
for otherUser,items in self.data.items():
if otherUser not in username:
print(otherUser)
distance=self.pearson(self.data[username],self.data[otherUser])
if distance is None:
continue
distances[otherUser]=distance
print(distances)
sortedDistance=sorted(distances.items(),key=operator.itemgetter(1),reverse=True);
print("排序后的用户为:",sortedDistance)
return sortedDistance[:n]
def recomand(self,username,n=1):
recommand={};
for user,score in dict(self.nearstUser(username,n)).items():
print("推荐的用户:",(user,score))
for movies,scores in self.data[user].items():
if movies not in self.data[username].keys():
print("%s为该用户推荐的:%s"%(user,movies))
if movies not in recommand.keys():
recommand[movies]=scores
return sorted(recommand.items(),key=operator.itemgetter(1),reverse=True)
def Euclidean(self,user1, user2):
# 取出两位用户评论过的美食和评分
user1_data = self.data[user1]
user2_data = self.data[user2]
distance = 0
# 找到两位用户都评论过的美食,并计算欧式距离
for key in user1_data.keys():
if key in user2_data.keys():
# 注意,distance越大表示两者越相似
distance += pow(float(user1_data[key]) - float(user2_data[key]), 2)
return 1 / (1 + sqrt(distance)) # 这里返回值越小,相似度越大
# 计算某个用户与其他用户的相似度
def top10_simliar(self,userID):
res = []
for userid in self.data.keys():
# 排除与自己计算相似度
if not userid == userID:
simliar = self.Euclidean(userID, userid)
res.append((userid, simliar))
res.sort(key=lambda val: val[1])
return res[:4]
# 根据用户推荐美食给其他人
def recommend(self,user):
# 相似度最高的用户
top_sim_user = self.top10_simliar(user)[0][0]
print(top_sim_user)
# 相似度最高的用户的观影记录
items = self.data[top_sim_user]
recommendations = []
# 筛选出该用户未观看的美食并添加到列表中
for item in items.keys():
if item not in self.data[user].keys():
recommendations.append((item, items[item]))
recommendations.sort(key=lambda val: val[1], reverse=True) # 按照评分排序
# 返回评分最高的10部美食
if len(recommendations) == 1:
recommendations = []
lists = []
for key,value in self.data.items():
for keys,values in value.items():
lists.append((keys,values))
for i in range(4):
recommendations.append(random.choice(lists))
recommendations = list(set(recommendations))
return recommendations[:10]
if __name__=='__main__':
# print(users)
userCf=UserCf(data=users)
# recommandList=userCf.recomand('root', 2)
# print("最终推荐:%s"%recommandList)
r = userCf.recommend('root')
print(r)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/q_3375686806/article/details/135686621
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 30、商城系统(十二):性能调优:Jmeter压测,jvisualvm性能监控,nginx动静分离,堆溢出解决方案
- 青少年CTF-qsnctf-Web-eval
- 字符串匹配的殿堂级算法:KMP算法详解(Java实现版)
- 动态规划汇总
- 【方差分析原理简介】
- 【Git】git的分支管理
- 微信小程序开发系列-10组件间通信01
- 2024年【G2电站锅炉司炉】考试报名及G2电站锅炉司炉复审考试
- (超详细)3-YOLOV5改进-添加SE注意力机制
- 毫无基础的人如何入门 Python ?