MySQL代码笔记

欢迎来到Cefler的博客😁
🕌博客主页:那个传说中的man的主页
🏠个人专栏:题目解析
🌎推荐文章:题目大解析(3)

目录
👉🏻表的增删查改
创建表格,插入信息,删除和查看表
CREATE DATABASE `sql_tutorial`;#创建资料库
SHOW DATABASES;
DROP DATABASE `sql_tutorial`;
USE `sql_tutorial`;
CREATE TABLE `student`(
`student_id` INT PRIMARY KEY AUTO_INCREMENT, #AUTO_INCREMENT自动增加
`name` VARCHAR(20) NOT NULL, # NOT NULL 即不能为空
`major` VARCHAR(20) UNIQUE DEFAULT '语文' #UNIQUE值不能重复,DEFAULT默认缺省值
#PRIMARY KEY设置方式还可以为PRIMARY KEY(`student_id`)
);
DESCRIBE `student`;#查看表格
DROP TABLE `student`;#删除表格
ALTER TABLE `student` ADD gpa DECIMAL(3,2);#增添表格信息
ALTER TABLE `student` DROP COLUMN gpa;#删除表格部分信息
#给表格插入信息
INSERT INTO `student` VALUES(1,"小白",'历史');
INSERT INTO `student`(`student_id`,`name`,`major`) VALUES(2,"小绿",'数学');#自主选择添加顺序
INSERT INTO `student`(`student_id`,`name`) VALUES(3,"小黄");
INSERT INTO `student`(`name`) VALUES("小黑");
#查询表格资料
SELECT * FROM `student`;
修改信息
#修改表格资料
UPDATE `student`
SET `major` = "物理" #可用逗号分隔更改多个
WHERE `major` = "语文";#WHERE可指定不同可定位信息;可用OR分隔,指定多个
删除信息
#删除信息
DELETE FROM `student`
WHERE `student_id` <2 #可用AND指定多个定位信息,比如WHERE `student_id` = 2 AND `major` = "语文"指名道姓去定位

DELETE FROM `student`;#删除全部信息
获取资料(SELECT)
SELECT `student_id`,`major` FROM `student` #获取student_id和major
ORDER BY `student_id`;#按照id排序;如果想要降序则在后面加上DESC,我们没有写的时候默认是ASC升序
#排序也可用逗号分隔指定多个信息,但有优先级,会先按照第一个定位信息排序,而后再按第二个定位信息排序,依次往后
SELECT `student_id`,`major` FROM `student`
LIMIT 3;#只返回前三位信息
SELECT *FROM `student`
WHERE `major` = IN("化学","生物","语文");#相当于多个OR
👉🏻创建公司资料库
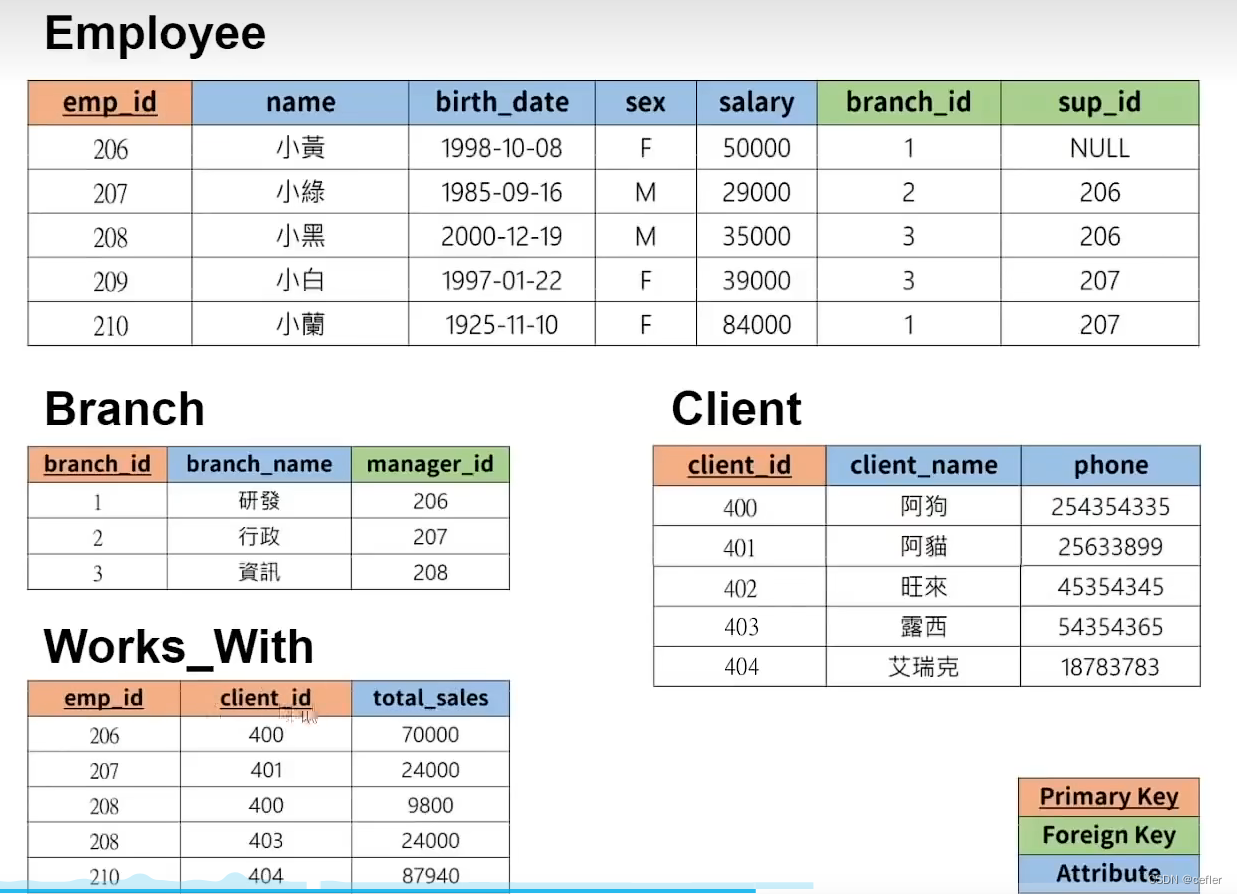
创建表
CREATE TABLE `employee`(
`emp_id` INT PRIMARY KEY,
`name` VARCHAR(20),
`birth_date` DATE,
`sex` VARCHAR(1),
`salary` INT,
`branch_id` INT,
`sup_id` INT
);
CREATE TABLE `branch`(
`branch_id` INT PRIMARY KEY,
`branch_name` VARCHAR(20),
`manager_id` INT,
FOREIGN KEY(`manager_id`) REFERENCES `employee`(`emp_id`) ON DELETE SET NULL
);
CREATE TABLE `client`(
`client_id` INT PRIMARY KEY,
`client_name` VARCHAR(20),
`phone` VARCHAR(20)
);
CREATE TABLE `works_with`(
`emp_id` INT,
`clinet_id` INT,
`total_sales` INT,
PRIMARY KEY(`emp_id`,`clinet_id`),
FOREIGN KEY (`emp_id`) REFERENCES `employee`(`emp_id`) ON DELETE CASCADE,
FOREIGN KEY(`clinet_id`) REFERENCES `client`(`client_id`) ON DELETE CASCADE
);
添加FOREIGN KEY
ALTER TABLE `employee`
ADD FOREIGN KEY(`branch_id`)
REFERENCES `branch`(`branch_id`)
ON DELETE SET NULL;
ALTER TABLE `employee`
ADD FOREIGN KEY(`sup_id`)
REFERENCES `employee`(`emp_id`)
ON DELETE SET NULL;
添加表信息
##branch
INSERT INTO `branch` VALUES(1,"研发",NULL);
INSERT INTO `branch` VALUES(2,"行政",NULL);
INSERT INTO `branch` VALUES(3,"资讯",NULL);
##employee
INSERT INTO `employee` VALUES(206,"小黄","1998-10-08",'F',50000,1,NULL);
INSERT INTO `employee` VALUES(207,"小缘","1985-09-16",'M',29000,2,206);
INSERT INTO `employee` VALUES(208,"小黑","2000-12-19",'M',35000,3,206);
INSERT INTO `employee` VALUES(209,"小白","1997-01-22",'F',39000,3,207);
INSERT INTO `employee` VALUES(210,"小绿","1925-11-10",'F',84000,1,207);
## 修改branch中manager_id的值
UPDATE `branch`
SET `manager_id` = 208
WHERE `branch_id` = 3;
##client
INSERT INTO `client` VALUES(400,"阿狗","254354335");
INSERT INTO `client` VALUES(401,"阿猫","25633899");
INSERT INTO `client` VALUES(402,"旺财","45354345");
INSERT INTO `client` VALUES(403,"露西","54354365");
INSERT INTO `client` VALUES(404,"艾瑞克","18783783");
##works_with
INSERT INTO `works_with` VALUES(206,400,"70000");
INSERT INTO `works_with` VALUES(207,401,"24000");
INSERT INTO `works_with` VALUES(208,402,"9800");
INSERT INTO `works_with` VALUES(209,403,"24000");
INSERT INTO `works_with` VALUES(210,404,"87940");
DROP TABLE `works_with`
练习测试
-- 1.取得所有员工资料
SELECT * FROM `employee`;
-- 2.取得所有客户资料alter
SELECT * FROM `client`;
-- 3.按薪水低到高取得员工资料
SELECT * FROM `employee`
ORDER BY `salary`;
-- 4.取得薪水前3高的员工
SELECT * FROM `employee`
ORDER BY `salary` DESC
LIMIT 3;
-- 5.取得所有员工的名字
SELECT `name` FROM `employee`;
SELECT DISTINCT `name` FROM `employee`;## DISTINCT会将重复项去除
👉🏻聚合函数
常见方法
MySQL提供了多种聚合函数,用于对数据进行汇总和计算。以下是一些常用的 MySQL 聚合函数:
-
COUNT(): 统计行数或非NULL值的数量。
SELECT COUNT(*) FROM table_name; -
SUM(): 计算数值列的总和。
SELECT SUM(column_name) FROM table_name; -
AVG(): 计算数值列的平均值。
SELECT AVG(column_name) FROM table_name; -
MAX(): 返回数值列的最大值。
SELECT MAX(column_name) FROM table_name; -
MIN(): 返回数值列的最小值。
SELECT MIN(column_name) FROM table_name; -
GROUP_CONCAT(): 将组内的值连接为一个字符串。
SELECT GROUP_CONCAT(column_name) FROM table_name GROUP BY group_column; -
GROUP BY: 对结果集进行分组,并对每个组应用聚合函数。
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name; -
HAVING: 在 GROUP BY 子句中使用,过滤分组后的结果。
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1;
这些聚合函数通常与 SELECT 语句的其他部分一起使用,以提供有关数据集的统计信息。请注意,在使用 GROUP BY 时,必须在 SELECT 子句中包含所有未在聚合函数中使用的非聚合列。
练习测试
-- 1.取得员工人数
SELECT COUNT(*) FROM `employee`;
-- 2.取得所有出生于 1970-01-01- 之后的女性员工人数
SELECT COUNT(*) FROM `employee`
WHERE `birth_date`>"1970-01-01" AND `sex` = "F";
-- 3.取得所有员工的平均薪水
SELECT AVG(`salary`) FROM `employee`;
-- 4.取得所有员工薪水的总和
SELECT SUM(`salary`) FROM `employee`;
-- 5.取得薪水最高的员工
SELECT MAX(`salary`) FROM `employee`;
-- 5.取得薪水最低的员工
SELECT MIN(`salary`) FROM `employee`;
👉🏻通配符
在 MySQL 中,通配符(Wildcard)是用于模糊匹配的特殊字符,主要用于在查询中进行模糊搜索或过滤。以下是一些常用的通配符:
-
百分号(%): 表示零个或多个字符。可以与 LIKE 操作符一起使用,用于模糊匹配字符串。
SELECT * FROM table_name WHERE column_name LIKE 'abc%';这将匹配以 “abc” 开头的所有字符串。
-
下划线(_): 表示单个字符。同样可以与 LIKE 操作符一起使用,用于匹配单个字符的位置。
SELECT * FROM table_name WHERE column_name LIKE 'a_c';这将匹配 “abc”、“adc”、“aec” 等。
-
方括号([]): 用于指定一个字符集,匹配括号中任意一个字符。
SELECT * FROM table_name WHERE column_name LIKE 'a[bc]d';这将匹配 “abd” 和 “acd”。
-
脱字符(^): 用于指定一个不在字符集中的字符。
SELECT * FROM table_name WHERE column_name LIKE 'a[^bc]d';这将匹配 “aed”,但不匹配 “abd” 和 “acd”。
通配符主要用于模糊查询,使得可以灵活地根据特定的模式来检索数据。需要注意的是,使用通配符可能会导致较慢的查询,特别是在大型数据集上,因此应谨慎使用。
练习测试
#通配符
-- 1.取得电话尾号是335的客户
SELECT * FROM `client`
WHERE `phone` LIKE "%335";
-- 2.取得姓艾的客户
SELECT * FROM `client`
WHERE `client_name` LIKE "艾%";
-- 3.取得生日在12月的员工
SELECT * FROM `employee`
WHERE `birth_date` LIKE "_____12%";
👉🏻Union
UNION 是 MySQL 中用于合并两个或多个 SELECT 语句的操作符。它用于将两个或多个结果集合并成一个结果集,并去除重复的行。以下是 UNION 的基本语法:
SELECT column1, column2, ...
FROM table1
WHERE condition
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition;
注意以下几点:
-
UNION连接的 SELECT 语句必须包含相同数量的列,并且相应的列的数据类型必须相同或兼容。 -
结果集中的列名是由第一个 SELECT 语句中的列名确定的。
-
UNION默认会去除重复的行。如果希望保留重复行,可以使用UNION ALL。
示例:
-- 例子:合并两个表的结果,并去除重复行
SELECT employee_id, employee_name FROM employees
UNION
SELECT contractor_id, contractor_name FROM contractors;
如果需要对合并后的结果进行排序,可以将 UNION 子句包装在一个外部的 SELECT 语句,并在外部 SELECT 中使用 ORDER BY:
-- 例子:合并两个表的结果,按照 employee_id 升序排序
SELECT * FROM (
SELECT employee_id, employee_name FROM employees
UNION
SELECT contractor_id, contractor_name FROM contractors
) AS combined_result
ORDER BY employee_id;
总体而言,UNION 是用于合并结果集的强大工具,可以在需要从多个表中检索数据并合并结果时使用。
练习测试
#Union
-- 1.员工名字 Union 客户名字
SELECT `name`
FROM `employee`
UNION
SELECT `client_name`
FROM `client` ;
-- 2.员工id + 员工名字 union 客户id + 客户名字
SELECT `emp_id`,`name`
FROM `employee`
UNION
SELECT `client_id`,`client_name`
FROM `client`;
-- 3.员工薪水 union 销售金额
SELECT `salary`
FROM `employee`
UNION
SELECT `total_sales`
FROM `works_with`
👉🏻Join
JOIN 是 SQL 中用于在两个或多个表之间建立关联关系的操作符。通过 JOIN,可以将符合指定条件的行从不同的表中联合起来,形成一个包含来自多个表的结果集。在 MySQL 中,有几种不同类型的 JOIN,包括 INNER JOIN、LEFT JOIN(或 LEFT OUTER JOIN)、RIGHT JOIN(或 RIGHT OUTER JOIN)、和 FULL JOIN(或 FULL OUTER JOIN)。
以下是这些 JOIN 的基本介绍:
-
INNER JOIN: 返回两个表中满足连接条件的行。如果某一行在一个表中没有匹配的行,那么该行不会出现在结果中。
SELECT * FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name; -
LEFT JOIN(LEFT OUTER JOIN): 返回左表中的所有行,以及右表中满足连接条件的行。如果右表中没有匹配的行,将会以 NULL 值填充。
SELECT * FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name; -
RIGHT JOIN(RIGHT OUTER JOIN): 返回右表中的所有行,以及左表中满足连接条件的行。如果左表中没有匹配的行,将会以 NULL 值填充。
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name; -
FULL JOIN(FULL OUTER JOIN): 返回左右两个表中的所有行,无论是否满足连接条件。如果某一行在一个表中没有匹配的行,将会以 NULL 值填充。
SELECT * FROM table1 FULL JOIN table2 ON table1.column_name = table2.column_name;
JOIN 的关键在于指定连接条件,即 ON 后面的条件。连接条件通常是两个表中相同或相似的列。JOIN 是在处理大型数据库中的关系型数据时非常常见的操作,它允许在查询中引用多个表的数据,使得复杂的查询成为可能。
测试练习
#join
-- 取得所有部门经理的名字
SELECT `emp_id`,`name`,`branch_name`
FROM `employee`
JOIN `branch`
ON `emp_id` = `manager_id`
👉🏻子查询
在 MySQL 中,子查询是指嵌套在其他 SQL 查询中的查询语句。子查询可以嵌套在 SELECT、FROM、WHERE 或 HAVING 子句中,用于获取更复杂的查询结果。下面是一些常见类型的子查询和示例:
-
在 SELECT 子句中使用子查询:
- 用于在主查询的 SELECT 子句中计算某个值。
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value FROM table1;
- 用于在主查询的 SELECT 子句中计算某个值。
-
在 FROM 子句中使用子查询:
- 用于将子查询的结果作为表进行处理,供主查询使用。
SELECT column1 FROM (SELECT column1 FROM table1 WHERE condition) AS subquery_table;
- 用于将子查询的结果作为表进行处理,供主查询使用。
-
在 WHERE 子句中使用子查询:
- 用于根据子查询的结果过滤主查询的结果。
SELECT column1 FROM table1 WHERE column2 = (SELECT MAX(column2) FROM table1);
- 用于根据子查询的结果过滤主查询的结果。
-
在 HAVING 子句中使用子查询:
- 用于在聚合查询中过滤分组后的结果。
SELECT column1, COUNT(*) FROM table1 GROUP BY column1 HAVING COUNT(*) > (SELECT AVG(count_column) FROM counts);
- 用于在聚合查询中过滤分组后的结果。
-
使用 EXISTS 子查询:
- 用于检查子查询是否返回任何行,通常与主查询中的条件一起使用。
SELECT column1 FROM table1 WHERE EXISTS (SELECT * FROM table2 WHERE table2.column1 = table1.column1);
- 用于检查子查询是否返回任何行,通常与主查询中的条件一起使用。
-
使用 IN 子查询:
- 用于检查某个列的值是否在子查询的结果集中。
SELECT column1 FROM table1 WHERE column1 IN (SELECT column1 FROM table2 WHERE condition);
- 用于检查某个列的值是否在子查询的结果集中。
-
使用 ANY 或 ALL 子查询:
- 用于与比较运算符一起使用,比较子查询的结果与主查询的结果。
SELECT column1 FROM table1 WHERE column2 > ANY (SELECT column2 FROM table2 WHERE condition);
- 用于与比较运算符一起使用,比较子查询的结果与主查询的结果。
子查询提供了一种灵活的方式来构建复杂的查询,它可以根据主查询的结果动态地生成子查询的条件。然而,需要注意的是,过度使用子查询可能会影响查询性能,因此在使用时应该谨慎。
练习测试
#subquery 子查询
-- 1.找出研发部门的经理名字
SELECT `name`
FROM `employee`
WHERE `emp_id` = (
SELECT `manager_id`
FROM `branch`
WHERE `branch_name` = "研发"
);
-- 2.找出一位客户销售金额超过50000的员工名字
SELECT `name`
FROM `employee`
WHERE `emp_id` IN (
SELECT `emp_id`
FROM `works_with`
WHERE `total_sales` >50000
);##这里用IN是因为返回的结果有多个
👉🏻ON 和DELETE
在 MySQL 中,ON 和 DELETE 分别用于连接表达式和删除数据。
-
ON:
ON关键字通常用于JOIN操作,用于指定连接两个表的条件。在INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL JOIN中,ON用于指定连接条件。例如:
上述查询中的SELECT * FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;ON子句指定了两个表之间的连接条件,即table1.column_name等于table2.column_name。
-
DELETE:
DELETE语句用于从表中删除行。可以使用WHERE子句指定删除的条件,也可以删除整个表中的所有行。例如:
上述语句将从表DELETE FROM table_name WHERE condition;table_name中删除满足条件condition的行。如果省略WHERE子句,将删除表中的所有行。要小心使用DELETE语句,确保删除的数据是符合预期的。
注意:在使用 DELETE 时,请确保谨慎操作,尤其是在生产环境中,因为该操作将永久性地从表中删除数据。在执行 DELETE 之前,最好先做好备份,并确保删除的条件是正确的,以防止误删除。
ON DELETE SET NULL
ON DELETE SET NULL 是 MySQL 中定义外键时用于指定在父表中删除关联行时,子表中对应的外键列的处理方式之一。具体说来,这是一种外键约束的操作,用于设置在父表中删除关联行后,子表中对应的外键列的值将被设为 NULL。
以下是一个简单的例子,演示如何在创建表时定义带有 ON DELETE SET NULL 的外键:
-- 创建父表
CREATE TABLE parent_table (
parent_id INT PRIMARY KEY
);
-- 创建子表,定义外键,并设置 ON DELETE SET NULL
CREATE TABLE child_table (
child_id INT PRIMARY KEY,
parent_id INT,
FOREIGN KEY (parent_id) REFERENCES parent_table(parent_id) ON DELETE SET NULL
);
在上述例子中,child_table 表包含一个外键 parent_id,它引用了 parent_table 表的主键 parent_id。并且在定义外键时,使用了 ON DELETE SET NULL 来指定当 parent_table 表中的关联行被删除时,child_table 表中的相应外键列 parent_id 将被设为 NULL。
这样,如果在 parent_table 表中删除了某行,那么与该行相关联的 child_table 表中的 parent_id 将被设置为 NULL。这可以用于处理一对多关系中的级联删除操作,保持数据的一致性。
ON DELETE CASCADE
ON DELETE CASCADE 是 MySQL 中定义外键时用于指定在父表中删除关联行时,子表中对应的外键行将会被级联删除的操作。具体说来,这是一种外键约束的操作,用于设置在父表中删除关联行后,子表中对应的外键行也将被删除。
以下是一个简单的例子,演示如何在创建表时定义带有 ON DELETE CASCADE 的外键:
-- 创建父表
CREATE TABLE parent_table (
parent_id INT PRIMARY KEY
);
-- 创建子表,定义外键,并设置 ON DELETE CASCADE
CREATE TABLE child_table (
child_id INT PRIMARY KEY,
parent_id INT,
FOREIGN KEY (parent_id) REFERENCES parent_table(parent_id) ON DELETE CASCADE
);
在上述例子中,child_table 表包含一个外键 parent_id,它引用了 parent_table 表的主键 parent_id。并且在定义外键时,使用了 ON DELETE CASCADE 来指定当 parent_table 表中的关联行被删除时,child_table 表中的相应外键行也将被级联删除。
这样,如果在 parent_table 表中删除了某行,那么与该行相关联的 child_table 表中的对应行也会被删除。这种级联删除的设置通常用于维护一对多关系中的数据完整性,确保删除父表中的记录时,相关的子表中的记录也能被自动删除。
如上便是本期的所有内容了,如果喜欢并觉得有帮助的话,希望可以博个点赞+收藏+关注🌹🌹🌹?? 🧡 💛,学海无涯苦作舟,愿与君一起共勉成长


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FPGA 查找表的用途和内部功能
- ts相关笔记(extends、infer、Pick、Omit)
- 一文3000字从0到1使用JMeter进行压力测试!
- CSS的三大特性
- 本地安装运行LLM(大型语言模型)
- 高标准农田建设项目主要内容
- C语言中关于指针的理解
- node.js——如何安装并管理node.js多个版本进行开发,看这一篇文章就够了!!!
- 数据结构学习笔记——查找算法中的树形查找(红黑树)
- macos 打开终端提示 You have new mail. 去除方法