ZK高可用架构涉及常用功能整理
ZK高可用架构涉及常用功能整理
探讨zk的系统架构以及以及整体常用的命令和系统分析,本文主要探讨高可用版本的zk集群,并基于日常工作中的沉淀进行思考和整理。更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. zk的高可用系统架构和相关组件
zk在产品设计上,面对的存储数据量比较小,一台zk机器就能够满足数据的存储需求,因此在集群的架构设计上,使用镜像模式进行数据高可用,通过ZAB 协议进行选举leader,从而满足集群的高可用和数据一致性要求。
zk的系统架构如下

zk的数据模型,呈现树形,类似linux的文件目录系统。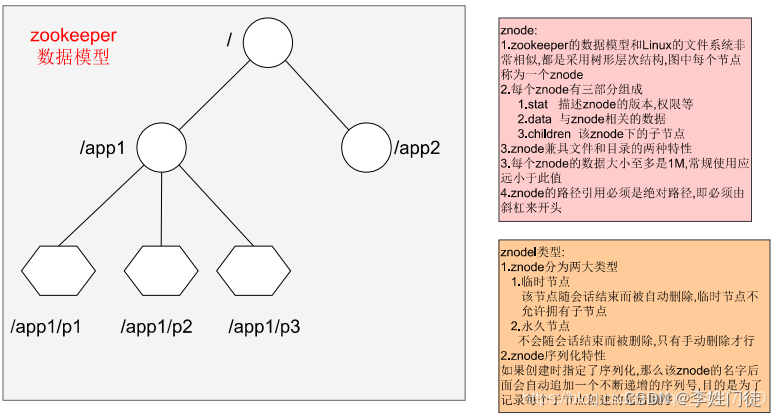
相关核心的组件和角色作用如下
| 角色 | 数量 | 角色作用 | 备注 |
|---|---|---|---|
| Leader | 有且必须只有1个 | 它会发起并维护与各Follwer及Observer间的心跳,所有的写操作必须要通过Leader完成再由Leader将写操作广播给其它服务器 | 通过内部选举选择出leader |
| Follower | 多个 | 会响应Leader的心跳,可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票 | 和Observer统称为Learner |
| Observer | 多个 | 作用跟Follow相同,但是没有投票权 | 和Follower统称为Learner |

1.1 Quorum机制
Quorum机制(有效个数)模式:指分布式系统的每一次修改都要在大多数(超过半数)实例上通过来确定修改通过。
产生Quorum机制(有效个数)的背景如下:
分布式系统的LC矛盾
在一个分布式存储系统中,用户请求会发到一个实例上。通常在一个实例上面执行的修改,需要复制到其他的实例上,这样可以保证在原实例挂了的情况下,用户依然可以看到这个修改。这就涉及到一个问题,究竟复制到多少个其他实例上之后,用户请求才会返回成功呢?如果复制的实例个数过多,那么请求响应时间就会更长;如果复制的实例过少,则这个修改可能会丢失。取得这个平衡性很重要,这也是分布式 PACELC 中的 L(Latency) 与 C(Consistency) 的取舍。
解决方案
当一个修改,被集群中的大部分节点(假设个数为N)通过之后,这个修改也就被这个集群所接受。这个 N 就是有效个数。假设集群数量为 n,那么 N = n/2 + 1.例如 n = 5,则 N = 3,从而应运而生Quorum机制(有效个数)
1.2 ZAB协议
ZooKeeper为了保证集群中各个节点读写数据的一致性和可用性,设计并实现了ZAB协议,ZAB全称是ZooKeeper Atomic Broadcast,也就是ZooKeeper原子广播协议。这种协议支持崩溃恢复,并基于主从模式,同一时刻只有一个Leader,所有的写操作都由Leader节点主导完成,而读操作可通过任意节点完成,因此ZooKeeper读性能远好于写性能,更适合读多写少的场景。一旦Leader节点宕机,ZAB协议的崩溃恢复机制能自动从Follower节点中重新选出一个合适的替代者,即新的Leader,该过程即为领导选举。领导选举过程,是ZAB协议中最为重要和复杂的过程
2. zk的核心参数
2.1 常规配置
zoo.cfg配置
cat /data/zookeeper-3.4.14/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=16
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=8
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper-3.4.14/data
dataLogDir=/data/zookeeper-3.4.14/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=10000
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=50
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
# 配置允许删除临时数据
extendedTypesEnabled=true
# https://issues.apache.org/jira/plugins/servlet/mobile#issue/ZOOKEEPER-2164。
cnxTimeout=20000
# Add default super user to zookeeper for administration.
# if you want the passwd. please contact to administration.
DigestAuthenticationProvider.superDigest=super:2bS8Usm0IRIIwal5O1c6meW8uxI=
server.1=xx.xx.xx.xx:2888:3888
server.2=xx.xx.xx.xx:2888:3888
server.3=xx.xx.xx.xx:2888:3888
myid配置
# cat /data/zookeeper-3.4.14/data/myid
1
不同的zk节点,配置对应的myid,配置依据来自zoo.cfg中的server.x配置
2.2 特殊优化配置
根据经验,可以增加zoo.cfg的管理账号
# fix the bug that 3888 listener will lost when network down and check_zk.sh restart the server
quorumListenOnAllIPs=true
# Add default super user to zookeeper for administration.
# if you want the passwd. please contact to administration.
DigestAuthenticationProvider.superDigest=super:2bS8Usm0IRIIwal5O1c6meW8uxI=
3. zk常用命令
利用zk安装包中自带的zkCli.sh命令,能够链接到zk中,并进行相关的操作
# 连接本地zk
./zkCli.sh
# 远程连接zk
./zkCli.sh -server xx.xx.xx.xx:2181
3.1 常用基础命令
整理日常操作zk常用的命令,便于针对zk的文件操作
1, ls 列出当前节点下的子节点
[zk: 127.0.0.1:2181(CONNECTED) 28] ls -R /
/
/node1
/zk
/zookeeper
/node1/node1.1
/node1/node1.2
/zookeeper/config
/zookeeper/quota
[zk: 127.0.0.1:2181(CONNECTED) 29]
2, stat 列出节点状态
[zk: 127.0.0.1:2181(CONNECTED) 29] stat /
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0xc
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 3
3,get 获取节点内容和节点状态
[zk: 127.0.0.1:2181(CONNECTED) 35] get /zk
jiang1234
4,create 创建永久节点
[zk: 127.0.0.1:2181(CONNECTED) 39] create /node_1 node-data
Created /node_1
5, 创建临时节点 &session过期临时节点删除
# 创建临时节点
[zk: 127.0.0.1:2181(CONNECTED) 40] create -e /czk/tmp temp-data
Created /czk/tmp
# 要求先配置 extendedTypesEnabled=true
# 创建带ttl的临时节点
create -t 10 /zkttl
# 10s后再ls就看不到创建的目录
ls /zkttl

6, 创建顺序节点
[zk: 127.0.0.1:2181(CONNECTED) 46] ls /czk
[tmp]
[zk: 127.0.0.1:2181(CONNECTED) 47] create -s /czk/sec seq
Created /czk/sec0000000001
[zk: 127.0.0.1:2181(CONNECTED) 48] create -s /czk/sec seq
Created /czk/sec0000000002
[zk: 127.0.0.1:2181(CONNECTED) 49] ls /czk
[sec0000000001, sec0000000002, tmp]
[zk: 127.0.0.1:2181(CONNECTED) 50]
7,set 设置数据:
[zk: 127.0.0.1:2181(CONNECTED) 50] get /czk
czk-data
[zk: 127.0.0.1:2181(CONNECTED) 51] set /czk czk-data2
[zk: 127.0.0.1:2181(CONNECTED) 52] get /czk
czk-data2
8,delete 删除目录
[zk: 127.0.0.1:2181(CONNECTED) 57] ls /czk
[sec0000000001, sec0000000002, tmp]
[zk: 127.0.0.1:2181(CONNECTED) 58] delete /czk/sec000000001
Node does not exist: /czk/sec000000001
[zk: 127.0.0.1:2181(CONNECTED) 59] ls /czk
[sec0000000001, sec0000000002, tmp]
[zk: 127.0.0.1:2181(CONNECTED) 60] delete /czk/sec0000000001
[zk: 127.0.0.1:2181(CONNECTED) 61] ls /czk
[sec0000000002, tmp]
3.2 常用运维命令
用于日常运维命令,便于进行服务运维,提升系统稳定性。
1, 服务启停
# 启动ZK服务
sh bin/zkServer.sh start
# 查看ZK服务状态
sh bin/zkServer.sh status
# 停止ZK服务
sh bin/zkServer.sh stop
# 重启ZK服务
sh bin/zkServer.sh restart
2, 检查zk集群的状态
#!/usr/bin/python
# -*- coding: utf-8 -*-
import json
import logging
import os
import random
import subprocess
import sys
import time
import datetime
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
logfile = "log_" + os.path.basename(sys.argv[0]).split(".")[0].split(".")[0] + ".log"
working_path = sys.path[0] + os.path.sep
log_path = "./"
log_level = logging.DEBUG
# 检查zk集群状态
zk_ips = []
zk_port = 2181
zoo_conf = "/data/zookeeper-3.4.14/conf/zoo.cfg"
def getlogger(name, path_file_name):
logger = logging.getLogger(name)
if len(logger.handlers) == 0:
logger.setLevel(log_level)
fh = logging.FileHandler(path_file_name, encoding='utf-8')
formatter = logging.Formatter('%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
if name != "file":
console = logging.StreamHandler()
console.setLevel(log_level)
formatter = logging.Formatter('%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
console.setFormatter(formatter)
logger.addHandler(console)
return logger
if not os.path.exists(log_path):
os.makedirs(log_path)
logger = getlogger("default", log_path + logfile)
file_logger = getlogger("file", log_path + logfile)
def run_shell(cmd, stderr2out=True):
p = None
if stderr2out:
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True, stderr=subprocess.STDOUT)
else:
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
out, err = p.communicate()
if logger:
logger.debug('running:%s,output:\n%s' % (cmd, out))
return p.returncode, out
def get_zoo_server_list(conf_path):
server_list = []
(status, output) = run_shell("cat " + zoo_conf)
if status != 0:
return server_list
lines = output.split("\n")
for line in lines:
if "server." in line and "#" not in line:
tmp = line.split("=")
if len(tmp) != 2:
continue
host = tmp[1].split(":")[0]
server_list.append(host)
return server_list
def main():
result = []
all_ips = []
all_ips = get_zoo_server_list(zoo_conf)
all_ips = all_ips + zk_ips
for ip in all_ips:
(status, output) = run_shell("echo mntr|nc -w 3 " + ip + " " + str(zk_port))
ip_result = {"conn": ip + ":" + str(zk_port), "result": None, "server_state": None}
if status != 0:
ip_result["result"] = "dead:conn " + ip + ":" + str(zk_port) + " failed."
else:
server_info = output.split("\n")
for info in server_info:
if "zk_server_state" in info:
ip_result["server_state"] = info.split("\t")[-1]
if ip_result["server_state"] is None:
ip_result["result"] = "dead:zk role failed."
else:
ip_result["result"] = "alive"
result.append(ip_result)
# 输出结果
print("=================result=================")
for ip_result in result:
print(json.dumps(ip_result))
if len(all_ips) == 0:
print("get server empty from " + zoo_conf + ",and zk_ips empty.")
if __name__ == '__main__':
main()
4. 事务性
4.1 数据写流程
zk的数据写流程,整体流程如下。
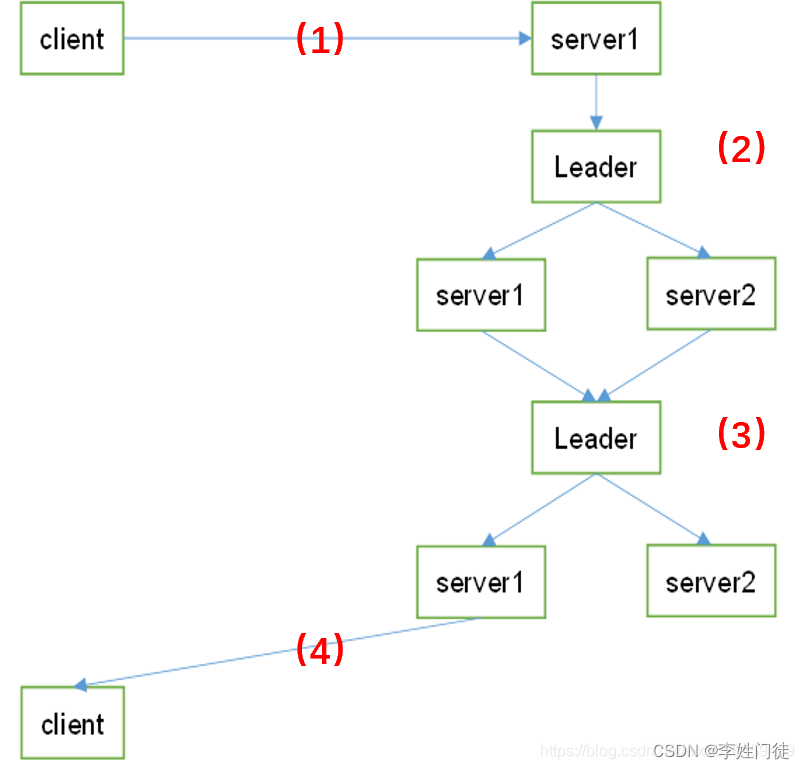
- Client向Zookeeper的server1发送一个写请求,客户端写数据到服务器1上;
- 如果server1不是Leader,那么server1会把接收到的写请求转发给Leader;然后Leader会将写请求转发给每个server;
- server1和server2负责写数据,并且两个Follower的写入数据是一致的,保存相同的数据副本;
- server1和server2写数据成功后,通知Leader;
- 当Leader收到集群半数以上的节点写成功的消息后,说明该写操作执行成功;
- 因为client访问的是server1,所以Leader会告知server1集群中数据写成功;
- 被访问的server1进一步通知client数据写成功,这时,客户端就知道整个写操作成功了。
4.2 数据读流程
相比写数据流程,读数据流程就简单得多;因为每台server中数据一致性都一样,所以随便访问哪台server读数据就行;没有写数据流程中请求转发、数据同步、成功通知这些步骤。
5. 疑问和思考
5.1 zk不擅长处理哪些场景?
zk擅长处理kv小量数据(v一般不能超过1M),基于zk进行分布式锁、选主、服务发现等均有比较好的应用和实践。但是zk不擅长处理大量数据的存储,通常需要注意不能在zk路径下写入过多数据,通常znode的目录数量应当控制在20M以内,单个zk节点的数据存储不应该超过10G,否则可能会由于zk存储了过多的数据而导致服务异常。
6. 参考文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!