《Kotlin核心编程》笔记:集合、序列与内联函数
集合的高阶函数API
map 操作
val list = listOf(1, 2, 3, 4, 5, 6)
val newList = list.map { it * 2 }
当然,在 Java 8 中,现在也能像Kotlin那样去操作集合了。
上面的方法实际上就是一个高阶函数,它接收的参数实际上就是一个函数,可能上面的写法还不是特别清晰,我们可以将上面的表达式修改如下:
val newList = list.map {el -> el * 2}
map后面的Lambda表达式其实就是一个带有一个参数的匿名函数。我们也可以在map方法中这样调用一个函数:
fun foo(bar: Int) = bar * 2
val newList = list.map {foo(it)}
使用map方法之后,会产出一个新的集合,并且集合的大小与原集合一样。通过使用map方法,我们就免去了for语句,而且也不用再去定义一些中间变量了。
对集合进行筛选:filter、count
val mStudents = students.filter {it.sex == "m"}
该方法与map类似,也是接收一个函数,只是该函数的返回值类型必须是Boolean。该函数的作用就是判断集合中的每一项是否满足某个条件,如果满足,filter方法就会将该项插入新的列表中,最终就得到了一个满足给定条件的新列表。调用filter之后产生的新列表是原来列表的子集。
具有过滤功能的方法还有以下这些:
filterNot,用来过滤掉满足条件的元素。filterNot方法与filter方法的作用相反,当传入的条件一样时,会得到相反的结果。filterNotNull,用来过滤掉值为null元素。count,统计满足条件的元素的个数。
val countMStudent = students.count {it.sex == "m"}
val countMStudent = students.filter {it.sex == "m"}.size
求和:sumBy、sum、fold、reduce
sum
val scoreTotal = students.sumBy {it.score}
sum:对数值类型的列表进行求和sum与sumBy类似,也是一个比较常见的求和API,但是它只能对一些数值类型的列表进行求和。
val a = listOf(1, 2, 3, 4, 5)
val b = listOf(1.1, 2.5, 3.0, 4.5)
val aTotal = a.sum()
val bTotal = b.sum()
也可以用sumBy:
val aTotal = a.sumBy {it}
val bTotal = b.sumBy {it}
fold
它的源码:
public inline fun <T, R> Iterable<T>.fold(initial: R, operation: (acc: R, T) ->
var accumulator = initial
for (element in this) accumulator = operation(accumulator, element)
return accumulator
}
可以看到,fold方法需要接收两个参数,第1个参数initial通常称为初始值,第2个参数operation是一个函数。通过for语句来遍历集合中的每个元素,每次都会调用operation函数,而该函数的参数有两个,一个是上一次调用该函数的结果(初始值为initial),另外一个则是当前遍历到的集合元素。简单来说就是:每次遍历都调用operation函数,然后将产生的结果作为参数提供给下一次遍历。
val scoreTotal = students.fold(0) { accumulator, student -> accumulator + student.score }
通过上面方式我们同样能得到所有学生的总分。在上面的代码中,fold方法接收一个初始值0,然后接收了一个函数,也就是后面的Lambda表达式。
{ accumulator, student -> accumulator + student.score }
上面的函数有两个参数,第1个参数为每次执行该函数后的返回结果,第2个参数为学生列表中的某个元素。我们通过让前一次执行之后的结果与当前遍历的学生的分数相加,就实现了求和的操作。其实就是累加操作。
同样地,我们还可以进行累乘操作:
val list = listOf(1,2,3,4,5)
list.fold(1) { mul, item -> mul * item }
>>> 120
fold很好地利用了递归的思想。
reduce方法和fold非常相似,唯一的区别就是reduce方法没有初始值。我们同样来看看reduce方法的源码:
public inline fun <S, T : S> Iterable<T>.reduce(operation: (acc: S, T) -> S): S {
val iterator = this.iterator()
if (!iterator.hasNext()) throw UnsupportedOperationException("Empty collection can't be reduced.")
var accumulator: S = iterator.next()
while (iterator.hasNext()) {
accumulator = operation(accumulator, iterator.next())
}
return accumulator
}
可以发现,reduce方法只接收一个参数,该参数为一个函数。具体的实现方式也与fold类似,不同的是当要遍历的集合为空时,会抛出一个异常。因为没有初始值,所以默认的初始值是集合中的第1个元素。采用reduce方法同样能实现上面的求和操作:
val scoreTotal = students.reduce { accumulator, student -> accumulator + student.score }
reduce方法和fold方法相似,当我们不需要初始值的时候可以采用reduce方法。
分组:groupBy
Kotlin给我们提供了一个groupBy方法。那么如果要对学生列表中的元素按照性别进行分组的话,我们就可以这样去做:
students.groupBy { it.sex }
返回的结果数据结构的类型为Map<String, List<Student>>,其中有两个分组,一个是性别男对应的分组,一个是性别女对应的分组。
扁平化——处理嵌套集合:flatMap、flatten
有时候我们希望嵌套集合中各个元素能够被拿出来,然后组成一个只有这些元素的集合,就像这样:
val list = listOf(listOf(jilen, shaw, lisa), listOf(yison, pan), listOf(jack))
val newList = listOf(jilen, shaw, lisa, yison, pan, jack)
可以通过flatten实现:
list.flatten()
假如我们并不是想直接得到一个扁平化之后的集合,而是希望将子集合中的元素“ 加工” 一下,然后返回一个“ 加工” 之后的集合。
比如我们要得到一个由姓名组成的列表,应该如何去做呢?
Kotlin还给我们提供了一个方法——flatMap,可以用它实现这个需求:
list.flatMap {it.map{it.name}}
>>> [Jilen, Shaw, Lisa, Yison, Pan, Jack]
flatMap接收了一个函数,该函数的返回值是一个列表,一个由学生姓名组成的列表。
通过flatten和map也可以实现flatMap的功能:
list.flatten().map {it.name}
通过这个例子你会发现,flatMap好像就是先将列表进行flatten操作然后再进行map操作,那如果现在需要从学生列表中取出学生的爱好,然后将这些爱好组成一个列表。先看看使用flatten和map怎么去做:
students.map {it.hobbies}.flatten()
然后使用flatMap实现:
students.flatMap {it.hobbies}
通过这个例子我们又发现,flatMap是先将列表进行map操作然后再进行flatten操作的,而且这个例子中使用flatMap要更加简洁。
flatMap的源码:
public inline fun <T, R> Iterable<T>.flatMap(transform: (T) -> Iterable<R>): List<R> {
return flatMapTo(ArrayList<R>(), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.flatMapTo(destination: C, transform: (T) -> Iterable<R>): C {
for (element in this) {
val list = transform(element)
destination.addAll(list)
}
return destination
}
transform函数接收一个参数(该参数一般为嵌套列表中的某个子列表),返回值为一个列表。
比如我们前面用flatMap获取爱好列表时:
{it.hobbies}
// 上面的表达式等价于:
{it -> it.hobbies}
在flatMap中调用了一个flatMapTo方法,它接收两个参数,一个参数为一个列表,该列表为一个空的列表,另外?个参数为一个函数,该函数的返回值为一个序列。
flatMapTo的实现很简单,首先遍历集合中的元素,然后将每个元素传入函数transform中得到一个列表,然后将这个列表中的所有元素添加到空列表destination中,这样最终就得到了?个经过transform函数处理过的扁平化列表。
flatMap其实可以看作由flatten和map进行组合之后的方法,组合方式根据具体情况来定。当我们仅仅需要对一个集合进行扁平化操作的时候,使用flatten就可以了;如果需要对其中的元素进行一些“ 加工”,那我们可以考虑使用flatMap。
集合的继承关系
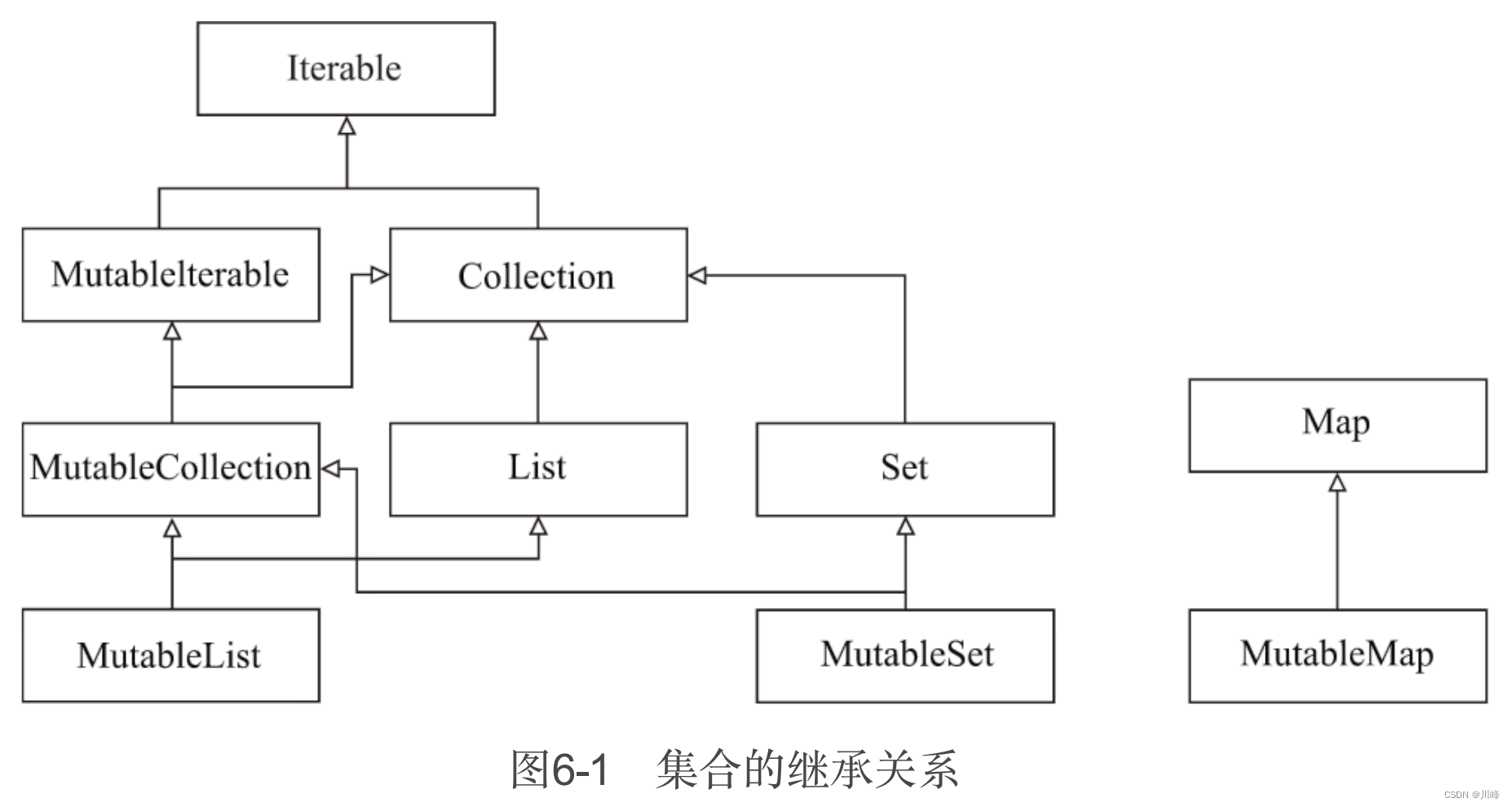
Iterable为Kotlin集合库的顶层接口。我们可以发现,每一个集合都分为两种,一种为带Mutable前缀的,另一种则是不带的。比如我们常见的列表就分为MutableList和List,List实现了Collection接口,MutableList实现了MutableCollection和List(MutableList表示可变的List,而List则表示只读的List)。
其实Kotlin的集合都是以Java的集合库为基础来构建的,只是Kotlin通过扩展函数增强了它。
List:有序的可重复的线性列表,List中的元素也是可以重复的。Set:不可重复的集合,Set常用的具体实现有两种,分别为HashSet和TreeSet。HashSet是用Hash散列来存放数据的,不能保证元素的有序性;而TreeSet的底层结构是二叉树,它能保证元素的有序性。在不指定Set的具体实现时,我们一般说Set是无序的。
listOf(1, 2, 3, 4, 4, 5, 5)
>>> [1, 2, 3, 4, 4, 5, 5]
setOf(1, 2, 3, 4, 4, 5, 5)
>>> [1, 2, 3, 4, 5]
Map:Kotlin中的Map与其他集合有点不同,它没有实现Iterable或者Collection。Map用来表示键值对元素集合,比如:
mapOf(1 to 1, 2 to 2, 3 to 3)
>>> {1=1, 2=2, 3=3}
在Map中的键值对,键是不能重复的。
可变集合与只读集合
尽管Kotlin的集合是基于Java构建的,但是在这一点上Kotlin选择了另辟蹊径,Kotlin将集合分成了可变集合与只读集合。比如我们常见的集合列表就分为MutableList和List。Kotlin的集合中暂时还没有不可变集合,我们只能将其称为只读集合。
可变集合:可变集合都会有一个修饰前缀“ Mutable”,比如MutableList。这里的改变是指改变集合中的元素。
val list = mutableListOf(1, 2, 3, 4, 5)
我们将集合中的第1个元素修改为0:
val list = mutableListOf(1, 2, 3, 4, 5)
list[0] = 0
>>> [0, 2, 3, 4, 5]
只读集合:只读集合中的元素在一般情况下是不可修改的,比如listOf()创建的list去修改list[0]=0会报错。因为这实际上就是调用了set方法,但是Kotlin的只读集合中是没有这个方法的。
Kotlin的可变集合与只读集合的区别其实就是,Kotlin将可变集合中的修改、添加、删除等?法移除之后,原来的可变集合就变成了只读集合。
也就是说,只读集合中只有?些可以用来“ 读” 的方法,比如获取集合的大小、遍历集合等。
这样做的好处是可以让代码看上去更容易理解,并且在某种程度上也能使代码更加安全。
比如,我们实现一个将a列表中的元素添加到b列表中的方法:
fun merge(a: List<Int>, b: MutableList<Int>) {
for (item in a) {
b.add(item)
}
}
可以发现,a列表仅仅只是遍历一下,而真正发生改变的是b列表。这样做的好处是,我们很容易就知道函数mergeList不会修改a,因为a是只读的,而函数很可能会修改列表b。
然而,我们并不能说只读列表就是无法被改变的。在Kotlin中,我们将List称为只读列表而不是可变列表是有原因的,因为在某些情况下只读列表确实是可以被改变的,比如:
val writeList: MutableList<Int> = mutableListOf(1,2,3,4)
val readList: List<Int> = writeList
>>> readList [1,2,3,4]
在上面的代码中,我们首先定义了一个可变列表writeList,然后我们又定义了一个只读列表readList,该列表与writeList指向了同一个集合对象,因为MutableList是List的子类,所以我们是可以这样去做的。我们现在修改这个集合:
writeList[0] = 0
>>> readList [0,2,3,4]
可以发现只读列表readList发生了改变,就是说在这种情况下我们是可以修改只读集合的。所以我们只能说只读列表在某些情况下是安全的,但是它并不总是安全的。
另外,由于kotlin和Java是兼容的,可以互相调用的,而在Java中是不区分只读集合与可变集合的,这就很容易出现修改只读集合的情况。
比如,当我们在Kotlin中调用下面这个bar方法的时候:
fun bar(list: List<Int>) {
foo(list)
}
而这里调用的这个foo方法是用Java的代码定义的:
public static List<Int> foo(List<Int> list) = {
for (int i = 0; i < list.size(); i++) {
list[i] = list[i] * 2;
}
return list;
}
所以传入bar方法中的list就会被foo方法改变:
val list = listOf(1, 2, 3, 4)
bar(list)
println(list)
>>> [2, 4, 6, 8]
所以,当我们与Java进行互操作的时候就要考虑到这种情况。
序列集合 Sequence
list.asSequence().filter{ it > 2 }.map{ it * 2 }.toList()
这里首先通过asSequence()方法将一个列表转换为序列,然后在这个序列上进行相应的操作,最后通过toList()分发将序列转换为列表。
在Kotlin中,序列中元素的求值是惰性的,这就意味着在利用序列进行链式求值的时候,不需要像操作普通集合那样,每进行一次求值操作,就产生一个新的集合保存中间数据。
那么惰性又是什么意思呢?先来看看它的定义:
- 在编程语言理论中,惰性求值(LazyEvaluation)表示一种在需要时才进行求值的计算方式。在使用惰性求值的时候,表达式在它被绑定到变量之后不会立即求值,而是在该值被取用时才去求值。通过这种方式,不仅能得到性能上的提升,还有?个最重要的好处就是它可以构造出一个无限的数据类型。
通过上面的定义我们可以简单归纳出惰性求值的两个好处,一个是优化性能,另一个就是能够构造出无限的数据类型。
序列的工作方式
Kotlin中序列的操作就分为两类,一类是中间操作,另一类则为末端操作。
上面的代码中,filter {it > 2}.map {it * 2} 这类操作称为中间操作,toList()这?类操作将序列转换为了List,我们将这类操作称作为末端操作。
中间操作:在对普通集合进行链式操作的时候,有些操作会产生中间集合,当用这类操作来对序列进行求值的时候,它们就被称为中间操作,比如上面的filter和map。每一次中间操作返回的都是一个序列,产生的新序列内部知道如何去变换原来序列中的元素。中间操作都是采用惰性求值的。
比如:
list.asSequence()
.filter {
println("filter($it)")
it > 2
}
.map {
println("map($it)")
it * 2
}
运行上面代码之后,会发现其中的println方法根本就没有被执行,这说明filter方法和map方法的执行被延迟了,这就是惰性求值的体现。
惰性求值也被称为延迟求值,惰性求值仅仅在该值被需要的时候才会真正去求值。那么这个“ 被需要” 的状态该怎么去触发呢?这就需要另外一个操作了——末端操作。
末端操作:在对集合进行操作的时候,大部分情况下,我们只在意结果,而不是中间过程。末端操作就是一个返回结果的操作,它的返回值不能是序列,必须是一个明确的结果,比如列表、数字、对象等。末端操作一般都放在链式操作的末尾,在执行末端操作的时候,会去触发中间操作的延迟计算,也就是将“ 被需要” 这个状态打开了。
我们给上面的例子加上末端操作符:
list.asSequence()
.filter {
println("filter($it)")
it > 2
}
.map {
println("map($it)")
it * 2
}
.toList()
结果:
filter(1)
filter(2)
filter(3)
map(3)
filter(4)
map(4)
filter(5)
map(5)
[6,8,10]
可以看到,所有的中间操作都被执行了。仔细看看上面的结果,我们可以发现一些有趣的地方。作为对比,我们先来看看上面的操作如果不用序列而用列表来实现会有什么不同之处:
list.filter {
println("filter($it)")
it > 2
}
.map {
println("map($it)")
it * 2
}
结果:
filter(1)
filter(2)
filter(3)
filter(4)
filter(5)
map(3)
map(4)
map(5)
[6,8,10]
我们可以发现,普通集合在进行链式操作的时候会先在list上调用filter,然后产生一个结果列表,接下来map就在这个结果列表上进行操作。
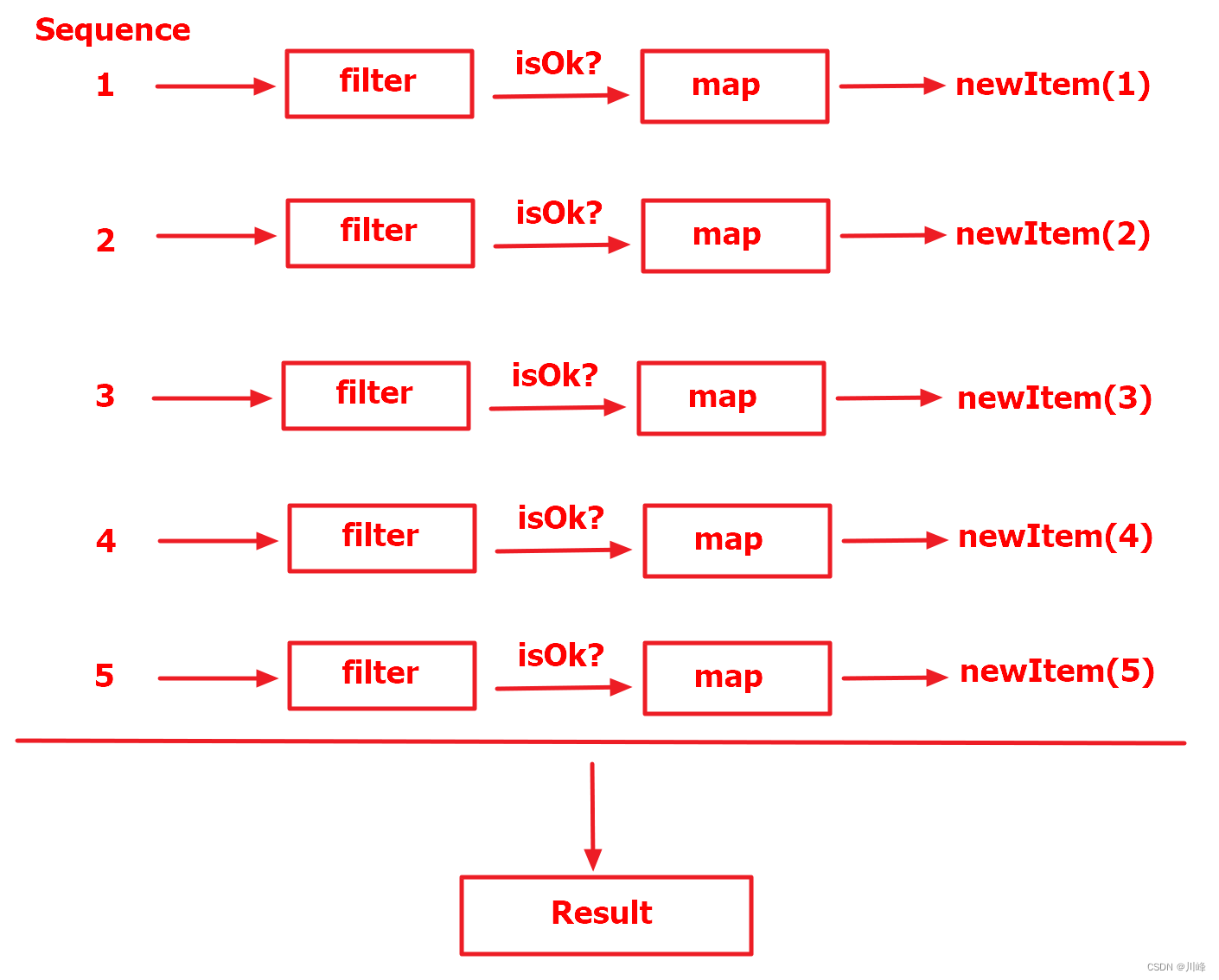
而序列则不一样,序列在执行链式操作的时候,会将所有的操作都应用在一个元素上,也就是说,第 1 个元素执行完所有的操作之后,第 2 个元素再去执行所有的操作,以此类推。
反映到我们这个例子上面,就是第 1 个元素执执行了filter之后再去执行map,然后第 2 个元素也是这样。
Sequence操作过程示意图如下:
List操作过程示意图如下:
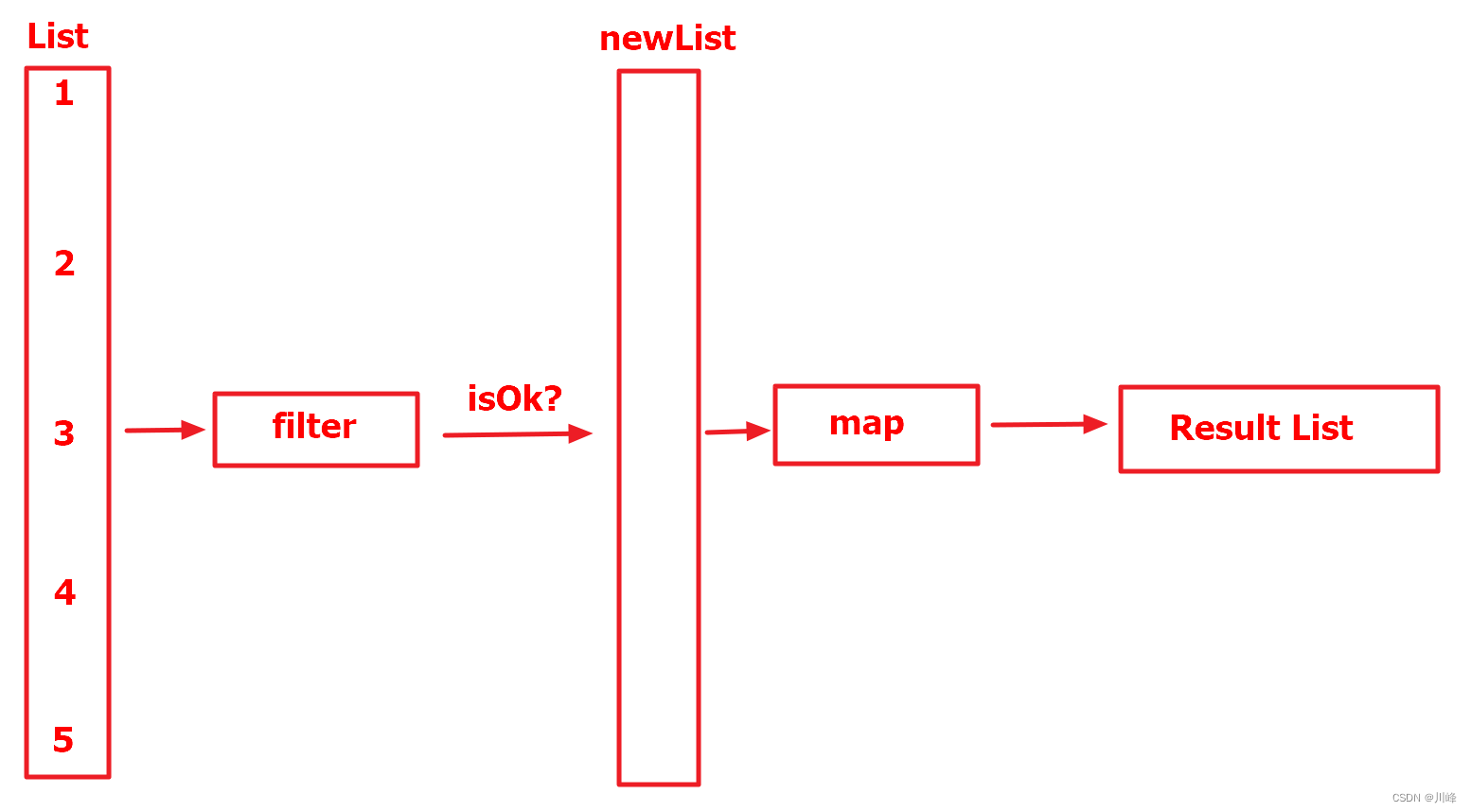
通过上面序列的返回结果我们还能发现,由于列表中的元素 1、2 没有满足 filter 操作中大于 2 的条件,所以接下来的map操作就不会去执行了。所以当我们使用序列的时候,如果filter和map的位置是可以互换的话,应该优先使用filter,这样会减少一部分开销。
创建无限序列
在Kotlin也给我们提供了这样?个generateSequence方法,去创建无限的数列:
val naturalNumList = generateSequence(0) { it + 1}
上面创建了一个自然数序列,它的后一个数永远是前一个数加1的结果。
我们知道序列是惰性求值的,所以上面创建的序列是不会把所有的自然数都列举出来的,只有在我们调用一个末端操作的时候,才去列举我们所需要的列表。比如我们要从这个自然数列表中取出前 10 个自然数:
naturalNumList.takeWhile {it <= 9}.toList()
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
关于无限数列这一点,我们不能将一个无限的数据结构通过穷举的方式呈现出来,而只是实现了一种表示无限的状态而已,让我们在使用时感觉它就是无限的。
序列 与 Java 8 Stream 对比
序列看上去就和Java 8中的流(Stream)比较类似:
students.stream().filter (it -> it.sex == "m").collect(toList());
但是相比于 Kotlin,Java 的这种操作方式还是有些烦琐,因为如果要对集合使用这种 API,就必须先将集合转换为stream,操作完成之后,还要将stream转换为List,这种操作有点类似于 Kotlin 的序列。这是因为 Java 8 的流和 Kotlin 中的序列一样,也是惰性求值的,这就意味着 Java 8 的流也是存在中间操作和末端操作的(事实也确实如此),所以必须通过上面的一系列转换才行。
Stream 是一次性的:与 Kotlin 的序列不同,Java 8 中的流是一次性的。也就是说,如果我们创建了一个 Stream,我们只能在这个 Stream 上遍历一次。这就和迭代器很相似,当你遍历完成之后,这个流就相当于被消费掉了,你必须再创建一个新的 Stream 才能再遍历一次。
Stream<Student> studentsStream = students.stream();
studentsStream.filter (it -> it.sex == "m").collect(toList());
studentsStream.filter (it -> it.sex == "f").collect(toList());
Stream 能够并行处理数据:Java 8 中的 Stream 能够在多核架构上并行地进行流的处理。只需要将stream换成paralleStream即可。
students.paralleStream().filter (it -> it.sex == "m").collect(toList());
并行处理数据这一特性是 Kotlin 的序列目前还没有实现的地方,如果我们需要用到处理多线程的集合还需要依赖 Java。
内联函数
优化 Lambda 开销
Kotlin 在集合 API 中大量使用了 Lambda,这使得我们在对集合进行操作的时候优雅了许多。但是这种方式的代价就是,在 Kotlin 中使用 Lambda 表达式会带来一些额外的开销。
在 Kotlin 中每声明一个 Lambda 表达式,就会在字节码中产生一个匿名类。该匿名类包含了一个invoke方法,作为 Lambda 的调用方法,每次调用的时候,还会创建一个新的匿名类对象。可想而知,Lambda 语法虽然简洁,但是额外增加的开销也不少。Kotlin 要在 Android 中引入 Lambda 语法,必须采用某种方法来优化 Lambda 带来的额外开销,也就是内联函数。
Java 中的 invokedynamic
Kotlin 中的内联函数显得有点尴尬,因为它之所以被设计出来,主要是为了优化 Kotlin 支持 Lambda 表达式之后所带来的开销。然而,在 Java 中我们却似乎并不需要特别关注这个问题,因为在 Java 7 之后,JVM 引入了一种叫作 invokedynamic 的技术,它会自动帮助我们做 Lambda 优化。
与 Kotlin 这种在编译期通过硬编码生成 Lambda 转换类的机制不同,Java 在 SE 7 之后通过 invokedynamic 技术实现了在运行期才产生相应的翻译代码。在 invokedynamic 被首次调用的时候,就会触发产生一个匿名类来替换中间码,后续的调用会直接采用这个匿名类的代码。这种做法的好处主要体现在:
- 由于具体的转换实现是在运行时产生的,在字节码中能看到的只有一个固定的
invokedynamic,所以需要静态生成的类的个数及字节码大小都显著减少; - 与编译时写死在字节码中的策略不同,利用
invokedynamic可以把实际的翻译策略隐藏在 JDK 库的实现,这极大提高了灵活性,在确保向后兼容性的同时,后期可以继续对翻译策略不断优化升级; - JVM 天然支持了针对该方式的 Lambda 表达式的翻译和优化,这也意味着开发者在书写 Lambda 表达式的同时,可以完全不用关心这个问题,这极大地提升了开发的体验。
invokedynamic 固然不错,但 Kotlin 不支持它的理由似乎也很充分。我们有足够的理由相信,其最大的原因是 Kotlin 在一开始就需要兼容 Android 最主流的 Java 版本 SE 6,这导致它无法通过 invokedynamic 来解决 Android 平台的 Lambda 开销问题。
因此,作为另一种主流的解决方案,Kotlin 拥抱了内联函数,在 C++、C# 等语言中也支持这种特性。
简单来说,我们可以用inline关键字来修饰函数,这些函数就成为了内联函数。它们的函数体在编译期被嵌入每一个被调用的地方,以减少额外生成的匿名类数,以及函数执行的时间开销。
所以如果你想在用 Kotlin 开发 Android 时获得尽可能良好的性能支持,以及控制匿名类的生成数量,就有必要来学习下内联函数的相关语法。
fun main() {
foo {
println("dive into Kotlin...")
}
}
fun foo(block: () -> Unit) {
println("before block")
block()
println("end block")
}
这里声明了一个高阶函数foo,可以接收一个类型为 () -> Unit 的 Lambda,然后在main函数中调用它。
以下是通过字节码反编译的相关 Java 代码:
public static final void main(@NotNull String[] args) {
Intrinsics.checkNotNullParameter(args, "args");
foo((Function0)null.INSTANCE);
}
public static final void foo(@NotNull Function0 block) {
Intrinsics.checkNotNullParameter(block, "block");
String var1 = "before block";
System.out.println(var1);
block.invoke(); // 调用 invoke() 方法执行 Lambda
var1 = "end block";
System.out.println(var1);
}
如我们所知,调用foo就会产生一个Function0类型的block类,然后通过invoke方法来执行,这会增加额外的生成类和调用开销。
现在,我们给foo函数加上inline修饰符,如下:
inline fun foo(block: () -> Unit) {
println("before block")
block()
println("end block")
}
再来看看相应的 Java 代码:
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
String var1 = "before block";
System.out.println(var1);
// block函数体在这里开始粘贴
String var2 = "dive into Kotlin...";
System.out.println(var2);
// block函数体在这里结束粘贴
var1 = "end block";
System.out.println(var1);
}
public static final void foo(@NotNull Function0 block) {
Intrinsics.checkParameterIsNotNull(block, "block");
String var2 = "before block";
System.out.println(var2);
block.invoke();
var2 = "end block";
System.out.println(var2);
}
果然,foo函数体代码及被调用的 Lambda 代码都粘贴到了相应调用的位置。试想下,如果这是一个工程中公共的方法,或者被嵌套在一个循环调用的逻辑体中,这个方法势必会被调用很多次。通过inline的语法,我们可以彻底消除这种额外调用,从而节约了开销。
内联函数典型的一个应用场景就是Kotlin的集合类。如果你看过Kotlin的集合类API文档或者源码实现就会发现,集合函数式API,如map、filter都被定义成内联函数,如:
inline fun <T, R> Array<out T>.map(transform: (T) -> R): List<R> {
val destination = ArrayList<R>(size)
for (element in this) {
destination.add(transform(element))
}
return destination
}
inline fun <T> Array<out T>.filter(predicate: (T) -> Boolean): List<T> {
val destination = ArrayList<T>()
for (element in this) {
if (predicate(element)) {
destination.add(element)
}
}
return destination
}
这个很容易理解,由于这些方法都接收Lambda作为参数,同时都需要对集合元素进行遍历操作,所以把相应的实现进行内联无疑是非常适合的。
内联函数不是万能的
以下情况我们应避免使用内联函数:
- 由于 JVM 对普通的函数已经能够根据实际情况智能地判断是否进行内联优化,所以我们并不需要对其实使用 Kotlin 的
inline语法,那只会让字节码变得更加复杂; - 尽量避免对具有大量函数体的函数进行内联,这样会导致过多的字节码数量;
- 一旦一个函数被定义为内联函数,便不能获取闭包类的私有成员,除非你把它们声明为
internal。
noinline:避免参数被内联
如果在一个函数的开头加上inline修饰符,那么它的函数体及 Lambda 参数都会被内联。然而现实中的情况比较复杂,有一种可能是函数需要接收多个参数,但我们只想对其中部分 Lambda 参数内联,其他的则不内联,这个又该如何处理呢?
解决这个问题也很简单,Kotlin 在引入 inline 的同时,也新增了 noinline 关键字,我们可以把它加在不想要内联的参数开头,该参数便不会具有内联的效果。我们再来修改下上述的例子,然后再应用noinline:
fun main() {
foo({
println("I am inlined...")
}, {
printIn("I am not inlined...")
})
}
inline fun foo(block1: () -> Unit, noinline block2: () -> Unit) {
println("before block")
block1()
block2()
println("end block")
}
同样的方法,再来看看反编译的 Java 版本:
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
Function0 block2$iv = (Function0)null.INSTANCE;
String var2 = "before block";
System.out.println(var2);
// block1被内联了
String var3 = "I am inlined...";
System.out.println(var3);
// block2还是原样
block2$iv.invoke();
var2 = "end block";
System.out.println(var2);
}
public static final void foo(@NotNull Function0 block1, @NotNull Function0 block2) {
Intrinsics.checkParameterIsNotNull(block1, "block1");
Intrinsics.checkParameterIsNotNull(block2, "block2");
String var3 = "before block";
System.out.println(var3);
block1.invoke();
block2.invoke();
var3 = "end block";
System.out.println(var3);
}
可以看出,foo函数中的block2参数在带上noinline之后,反编译后的Java代码中并没有将其函数体代码在调用处进行替换。
非局部返回
Kotlin 中的内联函数除了优化 Lambda 开销之外,还带来了其他方面的特效,典型的就是非局部返回和具体化参数类型。我们先来看下 Kotlin 如何支持非局部返回。
以下是我们常见的局部返回的例子:
fun main() {
foo()
}
fun localReturn() {
return
}
fun foo() {
println("before local return")
localReturn()
println("after local return")
return
}
运行结果:
before local return
after local return
正如我们所熟知的,localReturn执行后,其函数体中的return只会在该函数的局部生效,所以localReturn()之后的println函数依旧生效。
我们再把这个函数换成 Lambda 表达式的版本:
fun main() {
foo { return }
}
fun foo(returning: () -> Unit) {
println("before local return")
returning()
println("after local return")
return
}
运行结果:
Error:(2, 11) Kotlin: 'return' is not allowed here
编译器会直接报错,就是说在 Kotlin 中,正常情况下 Lambda 表达式不允许存在 return 关键字。这时候,内联函数又可以排上用场了。我们把 foo 进行内联后再试试看:
fun main() {
foo { return }
}
inline fun foo(returning: () -> Unit) {
println("before local return")
returning()
println("after local return")
return
}
运行结果:
before local return
编译通过了,结果也符合我们的预期,因为内联函数foo的函数体及参数 Lambda 会直接替代具体的调用,所以实际产生的代码中,return相当于是直接暴露在main函数中,所以returning()之后的代码自然不会被执行。这个也就是所谓的非局部返回。
使用 @ 标签实现 Lambda 非局部返回
另外一种等效的方式,是通过标签利用@符号来实现 Lambda 非局部返回。
同样以上的例子,我们可以在不声明inline修饰符的情况下,这么做来实现相同的效果:
fun main() {
foo { return@foo }
}
fun foo(returning: () -> Unit) {
println("before local return")
returning()
println("after local return")
return
}
运行结果:
before local return
非局部返回尤其在循环控制中显得特别有用,比如 Kotlin 的 forEach 接口,它接收的就是一个 Lambda 参数,由于它也是一个内联函数,所以我们可以直接在它调用的 Lambda 中执行 return 退出上一层的程序。
fun hasZeros(list: List<Int>): Boolean {
list.forEach {
if (it == 0) return true // 直接返回 hasZeros 函数结果
}
return false
}
试想一下,如果 inline 函数不支持非局部返回,那么上面这种代码将不能保证正常的逻辑。
crossinline
虽然非局部返回虽然在某些场合下非常有用,但可能也存在危险。因为有时候,我们内联的函数所接收的 Lambda 参数常常来自于上下文其他地方。为了避免带有return的 Lambda 参数对主调用流程产生破坏,我们还可以使用crossinline关键字来修饰该参数,从而杜绝此类风险。就像这样:
fun main() {
foo { return }
}
inline fun foo(crossinline returning: () -> Unit) {
println("before local return")
returning()
println("after local return")
return
}
运行结果:
Error:(2, 11) Kotlin: 'return' is not allowed here
reified 具体化参数类型
除了非局部返回之外,内联函数还可以帮助Kotlin实现具体化参数类型。
Kotlin与Java一样,由于运行时的类型擦除,我们并不能直接获取一个参数的类型。然而,由于内联函数会直接在字节码中生成相应的函数体实现,这种情况下我们反而可以获得参数的具体类型。我们可以用reified修饰符来实现这一效果。
fun main() {
getType<Int>()
}
inline fun <reified T> getType() {
print(T::class)
}
运行结果:
class kotlin.Int
这个特性在 Android 开发中也格外有用。比如在 Java 中,当我们要调用startActivity时,通常需要把具体的目标Activity类作为一个参数。在 Kotlin 中,我们可以用 reified 来进行简化:
inline fun <reified T : Activity> Activity.startActivity() {
startActivity(Intent(this, T::class.java))
}
这样我们进行跳转Activity就非常方便了:
startActivity<DetailActivity>()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!