一篇关于大模型在信息抽取(实体识别、关系抽取、事件抽取)的研究进展综述
信息提取(IE)旨在从普通自然语言文本中提取结构化知识(如实体、关系和事件)。最近,生成式大型语言模型(LLMs)展现了在文本理解和生成方面的卓越能力,使得它们能够广泛应用于各种领域和任务。因此,已经有许多研究致力于利用LLMs的能力,为信息提取任务提供可行的解决方案。为了全面系统地回顾和探索LLMs在信息提取任务中的应用,本研究对这一领域的最新进展进行了调查。
首先,我们进行了广泛的概述,将这些研究按照不同的信息提取子任务和学习范式进行分类。然后,我们对最先进的方法进行了实证分析,并发现了使用LLMs进行信息提取任务的新趋势。基于这些全面的调查,我们识别了一些有前景的研究方向和技术,这些值得在未来的研究中进一步探索。
此外,我们还维护了一个公共存储库,并不断更新相关资源。您可以通过访问以下网址获取这些资源:https://github.com/quqxui/Awesome-LLM4IE-Papers。
https://arxiv.org/pdf/2312.17617.pdf
https://github.com/quqxui/Awesome-LLM4IE-Papers
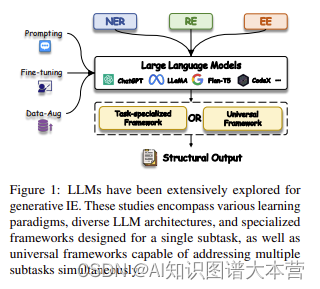
近年来,大语言模型(LLMs)在自然语言处理领域取得了显著的成果,尤其是在生成式信息抽取任务上表现出色。本文对LLMs在生成式信息抽取领域的最新研究进行了全面梳理,旨在为研究者提供一个系统性的回顾和探讨。
核心观点:
-
生成式信息抽取任务包括命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)。这些任务可以通过不同的学习范式(如监督微调、少样本学习、零样本学习等)来利用LLMs的能力。
-
LLMs在各个子任务上均取得了显著的成果,例如在NER、RE和EE任务上,LLMs已经超越了传统的判别式方法,并且在多任务学习和跨领域迁移方面具有很强的潜力。
算法原理:
-
在生成式信息抽取任务中,LLMs通过最大化条件概率来生成结构化信息。给定输入文本、提示和目标抽取序列,LLMs的目标是自动回归地生成目标序列。
-
LLMs可以通过不同的学习范式来进行训练和优化。例如,在监督微调中,LLMs通过在有标签数据上进行微调来提高性能;在少样本学习中,LLMs利用少量示例进行训练;在零样本学习中,LLMs仅依赖于上下文示例或指令来抽取信息。
结论:
-
LLMs在生成式信息抽取任务上具有巨大的潜力,已经在各个子任务上取得了显著的成果。然而,目前的研究仍存在一些挑战,如模型可解释性、计算资源消耗等。
-
未来的研究方向包括:(1)探索更有效的学习范式以提高LLMs在生成式信息抽取任务上的性能;(2)设计更通用的框架,以便在多任务学习和跨领域迁移中充分发挥LLMs的优势;(3)关注特定领域的应用,如医学、科学等,以推动实际应用场景中的技术创新。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 操作系统【协程与线程的区别】
- 自己搭建远程桌面服务器-RustDesk(小白版)
- 代码随想录算法训练营第三天 |203.移除链表元素,707.设计链表,206.反转链表
- DotPlot | 重绘点图,指定cell type的颜色
- Grind75第8天 | 278.第一个错误的版本、33.搜索旋转排序数组、981.基于时间的键值存储
- 代码随想录算法训练营第24天 | 理论基础 77. 组合
- 使用pandas按照商品和下单人统计下单数据
- 如何选择合适的建筑模板:专家建议与案例分享
- 【SpringCloud笔记】(8)服务网关之GateWay
- 云服务器ECS搭建个人项目